라이브러리
Beautiful soup
웹을 구성하는 <html>의 'id','class'와 같은 selector를 분석하여 변수로 사용할수 있도록 도와주는 라이브러리
Selenium
브라우저를 실행시켜 동적인 입력이 필요한 웹을 구동할수 있는 라이브러리
모듈
requests
특정사이트의 html코드가 무엇으로 구성되어있는지 모두 알려달라는 요청을 보내는것
파이썬이 외부서버에 request를 보내고자 할때 사용하는 모듈

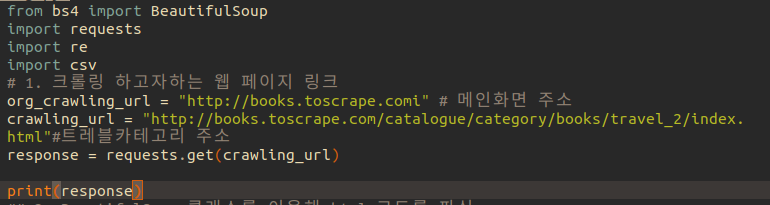
org_crawling_url 변수는 메인 웹사이트 주소를 담은것
crawling_url 변수는 books.toscape.com 의 travel 카테고리의 화면을 담은것
response=requests.get(crawling_url)은 response 변수에 requests.get 으로 트레블카테고리주소를 얻은것을 넣은것
print(response)를 합니다.

다른 터미널을 열고 위의 똑같은 파일을 python 파일이름.py 하여 열면 파이썬파일이열리고
<Response [200]> 이 뜨는것을 확인할수있다. 정상적으로 받았다는것이다.
이것을 html 텍스트 형식으로 받고싶으면
print(response)를 print(response.text)로 바꿔서 테스트해볼수있다.
그러면 아래와 같이 우리가 알고있는 html형식으로 터미널창에 뜨는것을 확인할수있다.

bs라는 변수에 response.text를 BeuatifulSoup를 이용하여 담는다.
오른쪽 'html.parser'는 html파일이 있다고 확실하게 알려주는 인자이다.
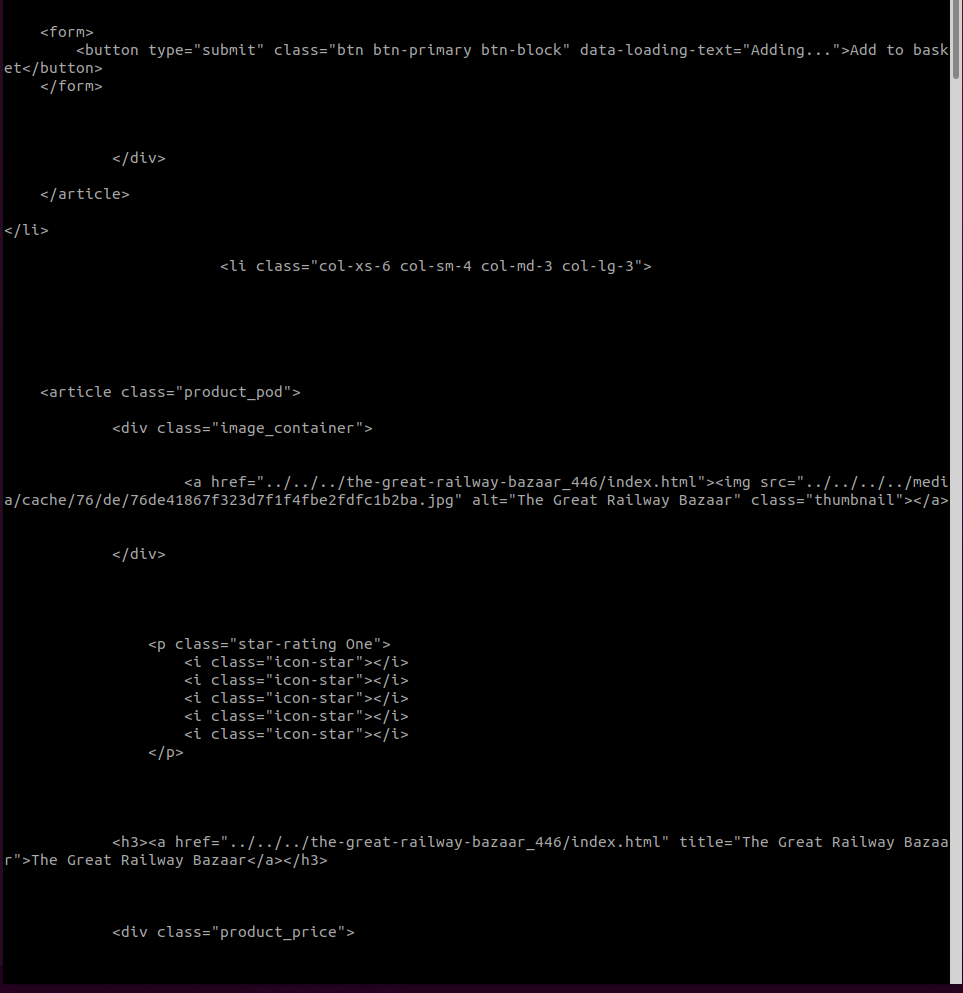
원하는 이미지에가서 개발자도구를이용하여 copy selector를하여 selector를 복사한다.

bs.select를 이용하여 복사한 selector를 이용한것이다.
bs.select는 selector를 list에 담아 표현한다.
위 이미지는 그 상태를 image_urls 변수에 담은것이다.
위의 selector를 print하면 아래와같이 나온다.
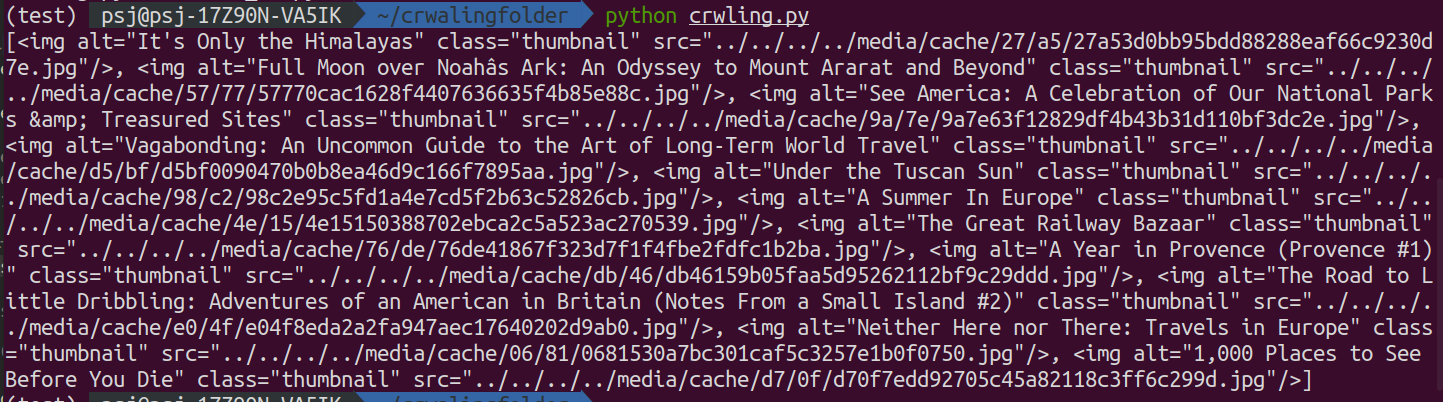
이것이 현재 image_urls 변수에 담긴 selector의 html데이터이다.
이제 우리는 for문을 이용해 여기의 첫번째이미지를 추출하기위해 첫번째 src의 이미지경로만 추출해 낼것이다.

드래그한 저 요소의 src의 경로를 추출할것이다.
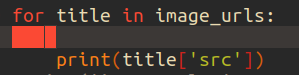
for문으로 image_urls의 요소 하나하나를 title에 담아 print(title['src'])를하면
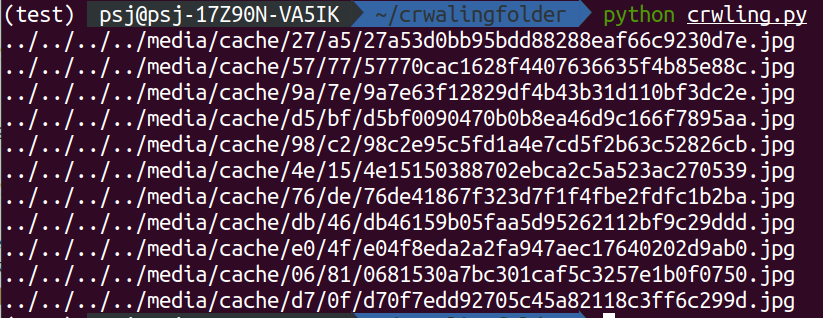
이렇게 모든 키src의 값인 경로들이 추출되게 된다.
( 궁금증? 여기서 title['src']가 키가 src인것을 이용해 딕셔너리를 이용한 값을 추출해 내는 방식인데 위의 전체경로 이미지를 보면 < >이런 태그로 덮혀져 있는데 딕셔너리식 추출이 가능한지 의문이 생길수 있다. 이것은 위에서 BeutifulSoup으로 태그를 이미 변환시켰기 때문에 딕셔너리식으로 추출이 가능한것이다.)

여기서 '/'을 기준으로 split()을 이용하면 / 를 기준으로 나뉜 요소들이 아래와같이 리스트화된다.
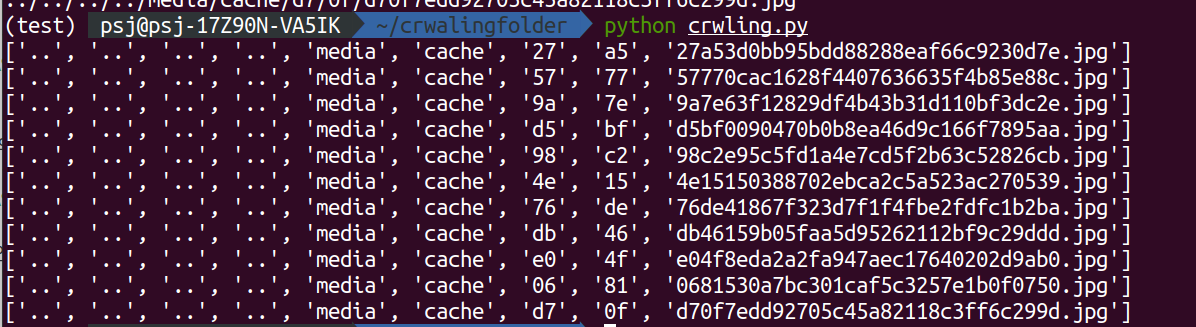
우리는 '..'을 모두 빼내어 버릴것이므로 슬라이스를 이용해 다음요소인 media부터 끝요소까지 추출해낸다.
그리고 첫번째 요소의 이미지 경로만 추출낼 것이므로 그렇게 for문을 변경한다.

그러면 아래와같이 첫번째 요소만 추출이된다.

이제 다시 남은 요소들은 인터넷경로처럼 바꿔줄것이므로 join을 이용하여 '/'를 넣어 합쳐준다.

그러면 아래와같은 결과가 나오고 타입은 str으로 변경된것을 확인할수있다.

이렇게 추출해낸 주소의 앞에 '/'를 더해주고 아래의 메인주소를 합쳐주면


최종적으로 합친 for문이다.

이렇게 전부 더해진 첫번째 이미지의 주소를 추출해낼수 있다.
