이진논리회귀
선형회귀로 풀지 못하는것을 논리회귀로 풀어 볼수 있다.
이진클래스로 나눌수 있습니다. 0이나 1
이전 논리회귀를 한번 연습해 보도록 하겠습니다!
여러가지 데이터를 바탕으로 당뇨병에 걸릴 확률을 파악해 봅시다.
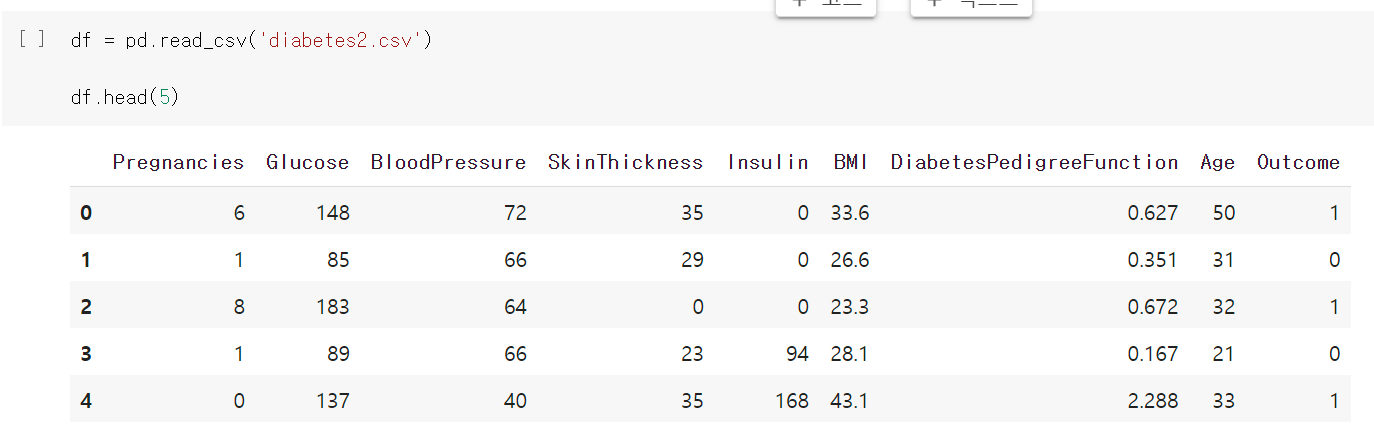
해당 csv를 불러와서 위에 5개 자료만 출력해 볼게요.
다양한 값이 나오는데 Outcome 값이 당뇨병에 걸리는 값입니다.
0이면 False 1 이면 True
df = pd.read_csv('diabetes2.csv', usecols=[
'Pregnancies',
'Glucose',
'BloodPressure',
'SkinThickness',
'Insulin',
'BMI',
'Age',
'Outcome'
])
df.head(5)원하는 값만 추출해 보도록 하겠습니다.
sns.countplot(x='Age', hue='Outcome', data=df)자료에서 원하는 값으로 그래프를 한번 그려보도록 할게요.
나이로 그려본 그래프 입니다.
x_data = df.drop(columns=['Outcome'], axis=1)
x_data = x_data.astype(np.float32)
x_data.head(5)
y_data = df[['Outcome']]
y_data = y_data.astype(np.float32)
y_data.head(5)x,y 입출력 데이터를 입력해 줍니다.
x데이터는 Outcome 컬럼만 빼주면 되고
y데이터는 Outcome 만 넣어주면 되겠죠
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)학습하기 위해서 검증데이터를 분할해 줍니다.
model = Sequential([
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.1), metrics=['acc'])
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=200 # epochs 복수형으로 쓰기!
)모델을 컴파일 하여, fit이 맞는지 학습시켜 봅니다.
epochs 은 200으로 했습니다..
러닝레이트는 0.1로 주었습니다.
metrics 는 어큐러시를 주었습니다.
loss는 바이너리 크로스엔트로피를 주었습니다.
돌려 보도록 하겠습니다.
학습 시키고 나서 어큐러시값은 60% 정도 되었고요.
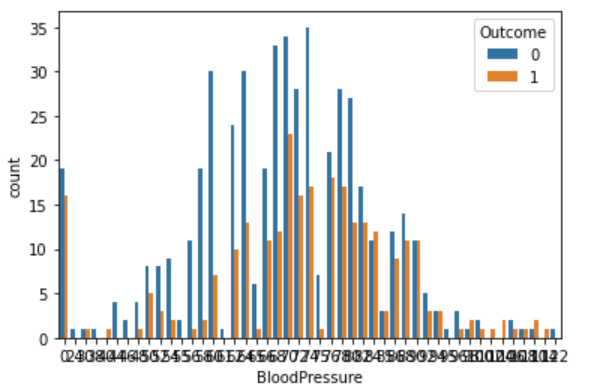
혈압으로 그래프를 그려보니 그래프가 아래처럼 나오네요.
그럼 다들 머신러닝 딥러닝 화이팅!!!!

지나가는사람