-
Definition
user가 item에 대해 행동한(ex. 구매, 클릭, 평점 등) 데이터를 기반으로 여러 user의 관심사를 예측하는 기법
NBCF(Neighborhood-based CF)의 핵심 원리는 알고자 하는 예측 대상과 유사한 대상을 이용해 관심사를 예측하는 것이다. 이때 그 대상이 user인지, item인지에 따라 크게 두 종류로 나뉜다.
Model-based DF는 Matrix Factorization을 기반으로 실제 배포 환경에서 더 원활하게 작동할 수 있도록 발전시킨 CF이다.
-
Types
-
NBCF

위 빨간색으로 표시된 부분을 예측하고자 한다.
-
'user' based CF (UBCF)
user 기반 cf의 경우, 내가 알고자 하는 유저 B와 다른 유저들 간의 유사도를 구한 후, 유사도가 높은 유저들과 유사한 평점을 갖도록 예측한다.
직관적으로 봐도 표에서는 A가 가장 B와 유사하기 때문에 아마 B는 스타워즈도 높게 평가할 것이라고 예측할 것이다.
-
'item' based CF (IBCF)
item 기반 CF의 경우, 내가 알고자 하는 타겟에 해당하는 item 스타워즈와 다른 item들 간의 유사도를 구한 후, 유사도가 높은 item과 유사한 평점을 갖도록 예측한다.
보면 아이언맨과 헐크가 유사해 보이기 때문에 아마 스타워즈도 비슷한 추세를 갖도록 예측할 것이고 즉 B가 스타워즈를 높게 평가할 것으로 예측할 것이다.
NBCF는 위의 표처럼 유저-아이템 행렬을 만들어 유사도를 계산해야 하기 때문에 아이템이나 유저가 계속 늘어날 때에 계속 계산을 해야 하기 때문에 실제 환경에서 확장성이 떨어진다.
또 넷플릭스만 생각해보더라도 대부분의 이용자들이 시청한 컨텐츠보다 시청하지 않은 컨텐츠의 수가 훨씬 많기 때문에 sparse한 matrix가 생성된다. 즉 유사한 대상이 있기 쉽지 않기 때문에 성능이 좋지 않을 수 있다.
-
-
KNN CF
KNN은 유저 u와 유사도가 가장 높은 k명의 유저만을 이용해 평점을 예측한다.
이 때 k는 튜닝해야 할 하이퍼 파라미터이다.그럼 유사도는 어떻게 계산하며 예측 값은 어떻게 계산한다는 것일까?
-> Similarity로 이동
-
Model-based CF
NBCF는 Memory based system이다.
user-item matrix에 대해 유사도를 계산하고 예측 평점을 계산해야 하기 때문에 대용량 데이터에 대한 연산 결과를 memory에 올려두고 이를 계속 업데이트해야 한다.
이는 효율이 좋지 않을 뿐만 아니라 오히려 데이터가 증가함에도 좋지 않은 성능을 내기도 하는 결과를 보인다.
MBCF는 이미 학습된 모델을 이용해 추천하기 때문에 서빙하는 속도가 빠르고 sparsity와 scalability 문제에도 NBCF보다 일반적으로 좋은 성능을 보인다.
전체 데이터의 패턴을 학습하기 때문에 특정 이웃의 영향을 크게 받을 수 있는 NBCF에 비해 overfitting을 완화할 수 있다.
Latent Factor Model은 유저와 아이템의 관계를 잠재적 요인으로 표현하는 모델이다. PCA처럼 차원을 줄이지만 중요한 정보는 compact하게 저장한다는 원리를 유사하게 갖고 있다.
-
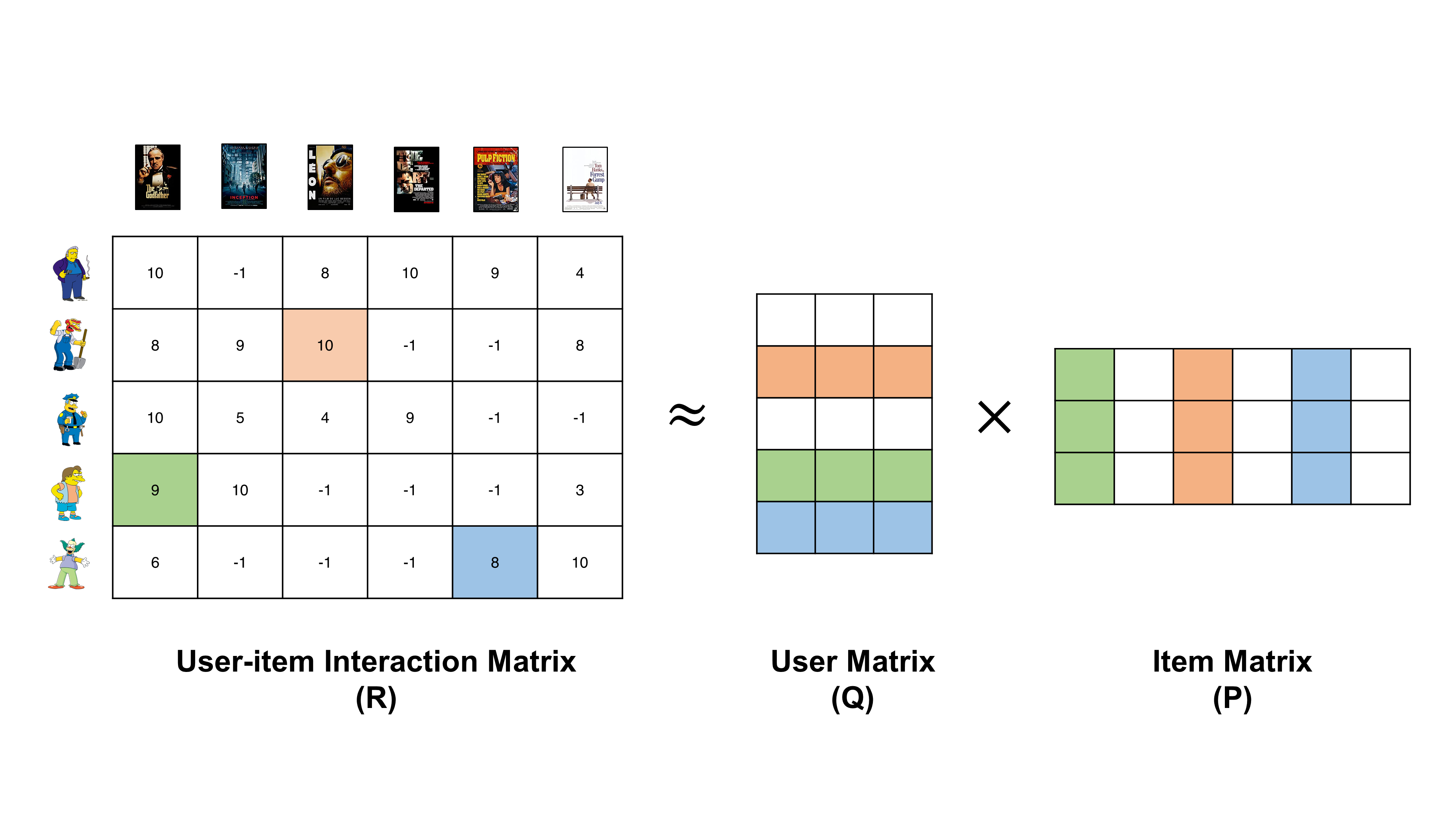
Matrix Factorization
User - item matrix()를 User, Item의 latent factor 행렬 2 가지의 곱으로 분해하는 방법이다.
분해된 2가지 행렬의 내적 곱을 통해 기존 과 유사한 을 추론하는 기법이다.
실제 rating 값(정답):
예측 rating: =objective function은 실제 평점과 예측 평점 간 예측의 오차를 최소화하는 방향으로 설계된다.
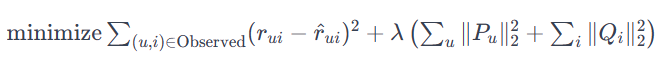
u, i는 실제로 interaction이 관측된(사용자가 실제로 평가한) 사용자와 아이템 조합을 나타낸다.
첫번째 term: 예측 에러의 제곱합을 최소화하기 위한 기본적인 항이다.
두번째 term: λ는 regularization 파라미터로써 각각의 파라미터를 업데이트할 때 학습 데이터에 대해 너무 최적화되지 않도록 방지하기 위해 존재하는 항이다.
파라미터 업데이트는 아래와 같이 일어난다.
<-
<-
bias
위의 기본 MF의 경우, 사용자별 성향(부정적, 긍정적, 극단적 등등)을 반영하지 못한다는 단점이 있다.
또 아이템에도 평가 경향성이 달라지는 것을 반영하지 못한다.이에 따라 사용자와 아이템에 대한 bias vector까지 추가하여 계산할 수 있다.
=
목적함수는 아래와 같다.
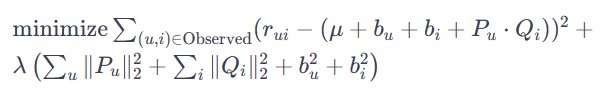
: 전체 평점의 평균
: 사용자에 대한 bias vector
: 아이템에 대한 bias vector이 경우 파라미터 업데이트는 아래와 같이 진행된다.
<-
<-
<-
<-
-
-
-
Similarity
유사도는 기본적으로 거리에 반비례하는 개념이다.
거리가 멀면 유사도가 낮고 거리가 가까우면 유사도가 높기 때문이다.일반적으로 가장 많이 사용하는 유사도 계산 수식은 4가지가 있다.
-
Mean Squared Difference Similarity
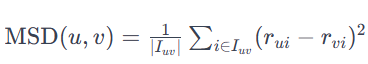
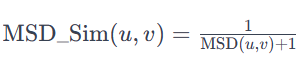
: 사용자 u와 v가 모두 평가한 아이템 집합
: 사용자 u가 아이템 i에 부여한 평점
: 사용자 v가 아이템 i에 부여한 평점MSD_Sim 수식의 분모는 MSD 값이 0이 될 경우를 방지하기 위해 1이 더해진 수식이 된다.
위 수식은 사용자 유사도 수식 기호로 쓰여져 있지만 I를 U, u, v를 아이템 2개로 바꾸어 아이템 유사도를 계산할 수도 있다.
-
Cosine Similarity
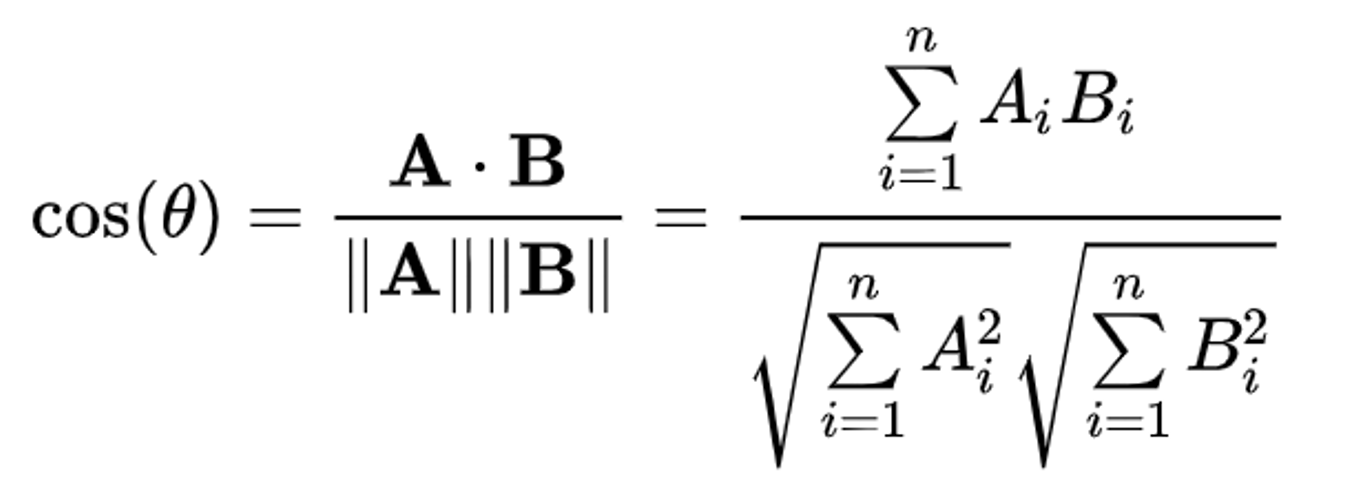
A, B는 내적을 해야 하기 때문에 차원이 같아야 한다.
따라서 1번 msd를 구할 때와 마찬가지로 두 사용자가 모두 평가한 아이템에 대해 계산해야 한다.
두 벡터의 방향이 비슷할 수록 1, 정반대일수록 -1에 가까운 결과가 나온다.
-
pearson similarity
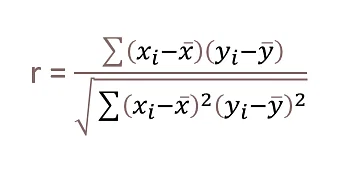
앞선 코사인 유사도의 경우 평가한 값 자체를 이용해 계산하기 때문에 사용자의 평가 성향을 반영하지 못한다.
예를 들어서, 사용자 A는 1-5 점의 다양한 값을 이용하지만 B는 보수적으로 1-3점만을 줄 수도 있다.
즉 이에 따라 평점들의 평균을 빼 줌으로써 각 벡터를 표본들의 평균으로 정규화하여 코사인 유사도를 구하는 방식이 바로 피어슨 유사도이다.
-
Jaccard Similarity
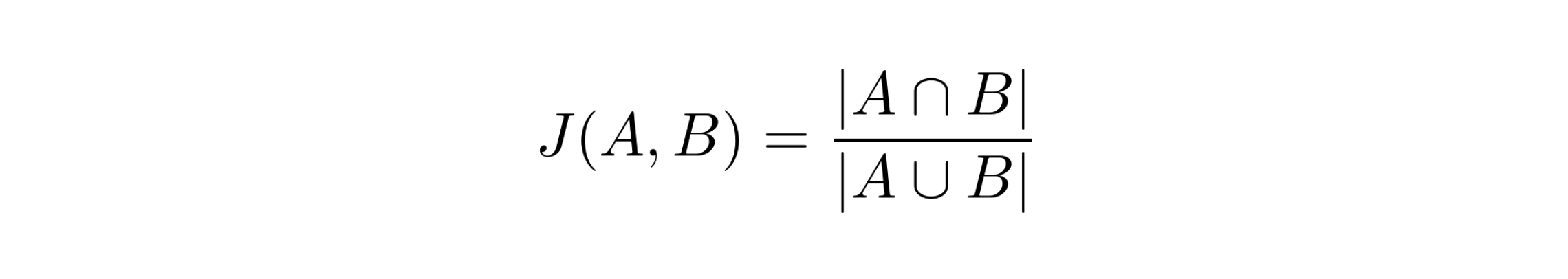
앞선 cosine, pearson 유사도의 경우 계산을 위해서는 차원이 같아야 유사도를 계산할 수 있었다.
자카드 유사도는 차원이 다르더라도 계산이 가능하도록 집합 개념을 사용한 유사도이다.
두 집합이 가진 모든 아이템 개수 중 겹치는 아이템의 개수 비율을 이용해 유사도를 정의한다.
-
-
Rating Prediction
-
average
다른 모든 유저들이 평가한 rating의 평균을 계산한다.
-
weighted average
유저 간 유사도 값을 가중치로 하여 rating의 평균을 계산한다.
-
absolute rating - average
유저와 유사한 유저들에 대해서만 rating의 단순 평균을 계산한다.
-
absolute rating - weighted average
유저와 유사한 유저들에 대해서만 유저 간 유사도 값을 가중치로 하여 rating의 평균을 낸다.
--> 이 때 앞서 이야기 한 것처럼 사람별 성향에 따른 평가 차이가 있기 때문에 이를 보정하기 위해 유저의 평점 평균을 뺀 값을 사용해 평점을 예측하기도 한다.
-
