Graph는 객체 간 관계와 같은 추상적인 개념을 효율적으로 나타낼 수 있게 해준다.
Graph 데이터에 적용 가능한 신경망을 GNN이라고 한다.
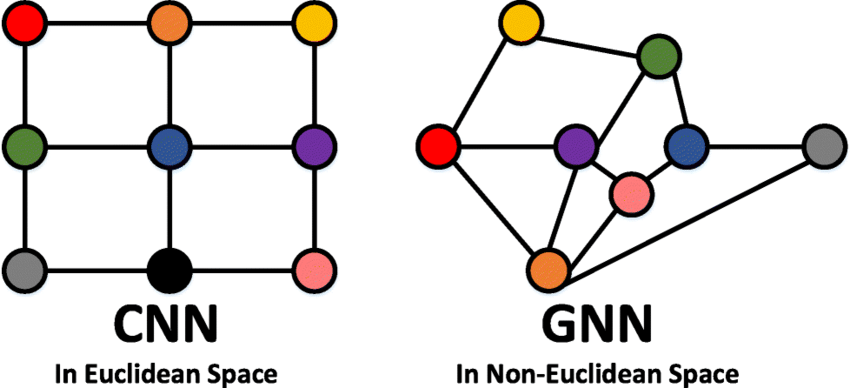
NGCF는 추천시스템에 GNN을 적용하는 게 효과적이라는 사실을 증명한 초기 논문에서 제시한 모델의 이름이다.
- Background
CF 모델의 경우 유저와 아이템 벡터를 임베딩하고 벡터로 구성된 각 유저 행렬과 아이템 행렬을 내적한 값이 실제 상호작용 값과 유사하도록 학습한다.
즉 유저 - 아이템의 상호작용 그 자체를 임베딩 단계에서는 학습하지 못하고 내적 시에만 latent factor를 추출하기 때문에 추천이 부정확해질 수 있다.
NGCF는 유저 - 아이템의 상호작용을 임베딩 단계에서부터 학습하고자 하는 모델이다.
- Structure of Model
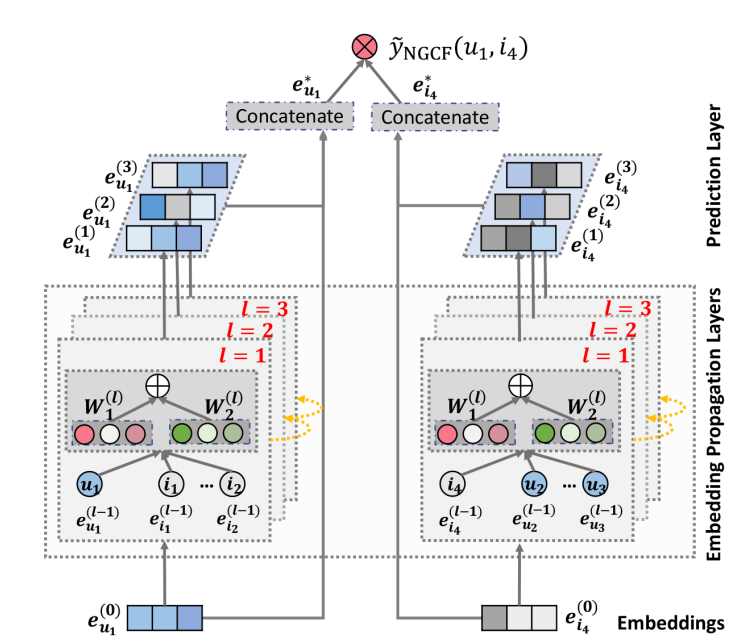
-
Embedding Layer
Input인 유저와 아이템의 one-hot encoding vector를 k차원의 임베딩으로 변환
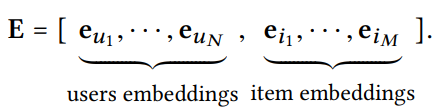
유저에 대한 임베딩과 아이템에 대한 임베딩 백터를 가로로 붙인 벡터들이 여러 개가 모여 Embedding Lookup Table이 된다.
Embedding Lookup Table은 학습 파라미터로, 처음 초기화된 이후에 학습을 하면서 업데이트된다.
-
Embedding Propagation Layers
GNN의 메시지 전달을 기반으로 유저와 아이템이 임베딩을 개선한다. 유저와 아이템 간 관련성을 높이고 상호작용 정보를 추출한다.
-
1차 전파(First-order Propagation)
유저의 아이템 소비 정보는 유저의 선호를 보여준다.
같은 아이템을 소비한 유저들은 유사한 취향을 가진다고 볼 수 있고,
비슷한 취향이라고 판단되는 그룹 내 유저가 소비한 아이템을 소비하지 않은 유저에게 아이템이 취향일 것이라고 예상할 수 있다.이러한 유사성을 임베딩을 업데이트함으로써 전파할 수 있도록 만드는 과정이 되는 것이다.
메시지는 유저와 아이템의 상호작용 정보(collaborative signal)를 담는다.
메시지 구성
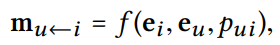
연결된 유저 - 아이템 쌍(u,i)에 대해 i에서 u로의 메시지 수식이다.
메시지 encoding 함수 f는 입력으로 임베딩 를 사용한다.: item embedding
: user embedding
: 하이퍼 파라미터(싱수)로, 각 edge에서의 메시지 전파의 정도를 조절하는 역할(regularization의 역할과 같음)
-> 학습데이터에 과적합되는 것을 방지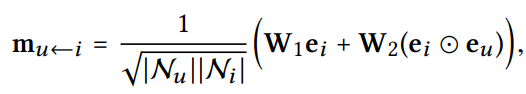
메시지를 계산하는 함수 f를 NGCF는 위와 같이 정의한다.
는 학습 파라미터 행렬이며 는 로 정의한다.signal의 크기는 점점 커지기 때문에 first-hop 이웃 노드의 수로 나누어 줌으로써 normalize하는 것이다. 즉 연결된 이웃노드가 많아질수록 해당 노드와의 상호작용은 덜 반영하게 한다. 한 사람의 특이한 취향이라기 보다는 일반적으로 인기있는 아이템이기 때문에 이러한 방식을 사용하게 된다는 의의가 있다.
은 아이템의 특성을 잘 나타내는 방향으로 학습한다고 볼 수 있고 는 유저와 아이템 간의 상호작용 정보를 잘 표현하는 방향으로 학습한다고 볼 수 있다.
메시지 집계
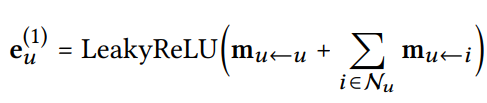
: 첫번째 embedding propagation layer를 거쳐 얻어진 user에 대한 임베딩
LeakyReLU: 양음의 모든 신호를 다룰 수 있다는 장점이 있는 활성화함수
로, user에 대한 self connection
이를 통해 user와 item의 first-hop 정보를 전파할 수 있다.
Propagation rule in Matix form
embedding 전파를 행렬로 연산하는 수식을 설명하고자 한다.
행렬로 표현하고자 하는 이유는 벡터를 하나씩 계산하는 것보다는 당연히 행렬로 한번에 계산하는 게 한 번에 여러 노드에 대한 정보를 업데이트할 수 있기 때문이다.
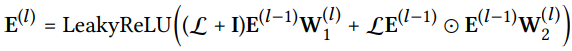
: 임베딩 행렬(행은 사용자나 아이템의 임베딩 벡터, 열은 임베딩의 각 차원), 크기는 (N+M) x d1
N: 사용자의 수, M: 아이템의 수, d1: 임베딩 차원
: 유저 - 아이템 그래프에 대한 Laplacian matrix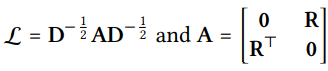
A: adjacency matrix, D: diagonal degree matrix
-
-
고차 전파(High-order Propagation)
1차 전파에서처럼 임베딩 전파 레이어를 더 쌓으면 유저 노드는 l차 이웃으로부터 전파된 메시지를 이용할 수 있다.
더 높은 차수의 연결 정보를 탐색하여 여러 층의 전파를 함으로써 더 많은 정보를 활용하여 보다 다양성 있으면서도 관계성 있는 추천이 가능해진다.
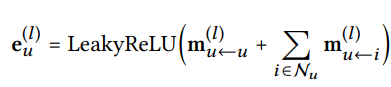
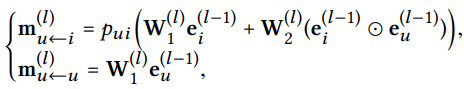
-
Prediction Layer
L개의 propagation layer로 전파를 한 이후에는 user u 한 명 당 L개의 embedding을 얻을 수 있다.
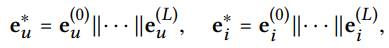
각각 다른 의미를 담고 있기 때문에 이것들을 concatenate해서 유저에 대한 final embedding을 구성하게 된다.
아이템도 마찬가지이다.
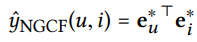
유저와 아이템 백터를 내적함으로써 최종 선호도 예측값을 계산하게 된다.
(유저와 아이템 벡터의 차원의 크기는 같음)
-
Results
embedding propagation layer의 개수가 늘어날수록 학습 데이터에 대한 모델의 성능은 높아지는 편이다.
하지만 또 계속해서 늘어나면 과적합이 일어나기 때문에 일반화의 성능이 떨어지게 된다.
일반적으로 L이 3~4개 일 때의 성능이 높게 나온다.
MF보다 빠르게 수렴하고 recall이 높게 나온다.
유저 - 아이템이 임베딩 공간에서 더 명확하게 구분된다는 장점이 있다.
