- 데이콘 대회
월간 데이콘 뉴스 토픽 분류 AI 경진대회
https://dacon.io/competitions/official/235747/overview/description
라이브러리 로드
import pandas as pd
import numpy as pd
import os, platform데이터 로드
base_path = "data/klue/"
def file_exist_check(base_path):
if os.path.exists(f"{base_path}train_data.csv"):
print(f"{base_path} 경로에 파일이 이미 있음")
return
if platform.system() == "Linux":
print(f"파일을 다운로드 하고 {base_path} 경로에 압축을 해제함")
!wget https://bit.ly/dacon-klue-open-zip
if not os.path.exists(base_path):
os.makedirs(base_path)
!unzip dacon-klue-open-zip -d data/klue
else:
print(f"""https://dacon.io/competitions/official/235747/data 에서 다운로드 하고
실습 경로 {base_path}에 옮겨주세요.""")
return
file_exist_check(base_path)
>>>>
data/klue/ 경로에 파일이 이미 있음학습, 예측 데이터셋
train = pd.read_csv(f"{base_path}train_data.csv")
test = pd.read_csv(f"{base_path}test_data.csv")
train.shape, test.shape
>>>>
((45654, 3), (9131, 2))
# 토픽
toeic = pd.read_csv(f"{base_path}topic_dict.csv")
topic
>>>>
topic topic_idx
0 IT과학 0
1 경제 1
2 사회 2
3 생활문화 3
4 세계 4
5 스포츠 5
6 정치 6문자 전처리
import re
def preprocessing(text):
# 한글, 영문, 숫자만 남기고 모두 제거
text = re.sub('[^가-힣ㄱ-ㅎㅏ-ㅣa-zA-Z0-9]', " ", text)
# 중복 생성된 공백값 제거
text = re.sub('[\s]+', " ", text)
# 영문자를 소문자로
text = text.lower()
return text- tqdm 으로 전처리 진행 상태 표시
import tqdm import tqdm
tqdm.pandas()
# map을 통해 전처리 일괄 적용
train['title'] = train['title'].prograss_map(preprocessing)
test['title'] = test['title'].prograss_map(preprocessing)
>>>>
100%|█ █ █ █ █ █ █ █ █ █| 45654/45654 [00:00<00:00, 123267.94it/s]
100%|█ █ █ █ █ █ █ █ █ █| 9131/9131 [00:00<00:00, 127339.31it/s]형태소 분석
- Hannanum
- Kkma
- Komoran
- Mecab
- Okt
📌 형태소(morpheme) : 뜻을 가진 가장 작은 말의 단위
- 자립 형태소 : 접사, 어미, 조사와 상관없이 자립하여 사용할 수 있는 형태소
- 의존 형태소 : 다른 형태소와 결합하여 사용되는 형태소, 접사, 어미, 조사 어간 등
문장 : 김언어는 자연어 처리 공부를 하였다.
- 자립 형태소 : 김언어, 자연어, 처리, 공부
- 의존 형태소 : -은, -를, 하-, -였, -다
✅ 한국어에서는 단어 토큰화는 형태소 토큰화를 수행해야 함.
- Kkma
small_text = '버스의 운행시간을 문의합니다. 어?!'
from konlpy.tag import Kkma
kkma = Kkma()
print(kkma.morphs(u'공부를 하면할수록 모르는게 많다는 것을 알게 됩니다.'))
print(kkma.nouns(u'공부를 하면할수록 모르는게 많다는 것을 알게 됩니다.'))
>>>>
['공부', '를', '하', '면', '하', 'ㄹ수록', '모르', '는', '것', '이', '많', '다는', '것', '을', '알', '게', '되', 'ㅂ니다', '.']
['공부']
print(kkma.pos(u'공부를 하면할수록 모르는게 많다는 것을 알게 됩니다.'))
>>>>
[('공부', 'NNG'), ('를', 'JKO'), ('하', 'VV'), ('면', 'ECE'), ('하', 'VV'), ('ㄹ수록', 'ECD'), ('모르', 'VV'), ('는', 'ETD'), ('것', 'NNB'), ('이', 'JKS'), ('많', 'VA'), ('다는', 'ETD'), ('것', 'NNB'), ('을', 'JKO'), ('알', 'VV'), ('게', 'ECD'), ('되', 'VV'), ('ㅂ니다', 'EFN'), ('.', 'SF')]
print(kkma.nouns(small_text))
print(kkma.pos(small_text))
>>>>
['버스', '운행', '운행시간', '시간', '문의']
[('버스', 'NNG'), ('의', 'JKG'), ('운행', 'NNG'), ('시간', 'NNG'), ('을', 'JKO'), ('문의', 'NNG'), ('하', 'VV'), ('ㅂ니다', 'EFN'), ('.', 'SF'), ('어', 'VV'), ('어', 'ECS'), ('?', 'SF'), ('!', 'SF')]- PeCab
from pecab import PeCab
pecab = PeCab()
pecab.pos("밖에 날씨가 정말 춥다. 이런 날 호떡이 땡긴다.")
>>>>
[('밖', 'NNG'),
('에', 'JKB'),
('날씨', 'NNG'),
('가', 'JKS'),
('정말', 'MAG'),
('춥', 'VA'),
('다', 'EF'),
('.', 'SF'),
('이런', 'MM'),
('날', 'NNG'),
('호떡', 'NNG'),
('이', 'JKS'),
('땡', 'MAG'),
('긴다', 'VV+EF'),
('.', 'SF')]어간 추출(stemming)
어간 추출 & 표제어 표기법(Lemmatization)
✅ 차이점
- 어간 추출은 단어 형식을 의미가 있거나 무의미할 수 있는 줄기로 축소
- 표제어 표기법은 단어 형식을 언어학적으로 유효한 의미로 축소
➡️ 어간 추출은 원형을 잃을 수 있지만, 표제어 표기법은 원형 보존
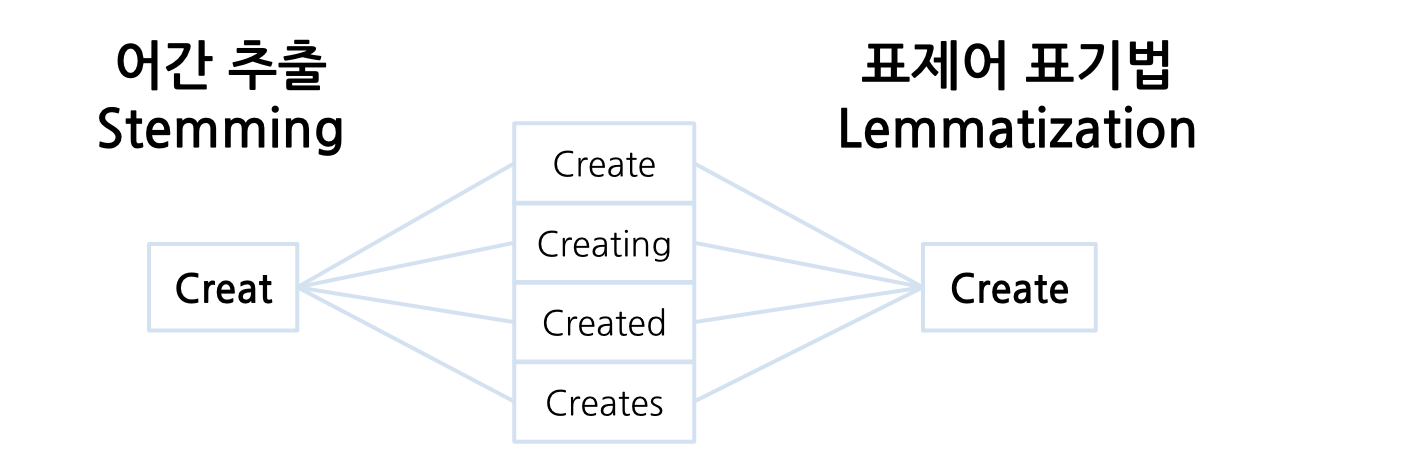
- Okt
- stemming 기능 제공 : 동사원형
from konlpy.tag import Okt
okt = Okt()
print(okt.pos('나는 치킨을 먹었다."))
print(okt.pos('나는 치킨을 먹었다.", stem=True))
>>>>
[('나', 'Noun'), ('는', 'Josa'), ('치킨', 'Noun'), ('을', 'Josa'), ('먹었다', 'Verb'), ('.', 'Punctuation')]
[('나', 'Noun'), ('는', 'Josa'), ('치킨', 'Noun'), ('을', 'Josa'), ('먹다', 'Verb'), ('.', 'Punctuation')]- 전체 텍스트에 적용하기 위한 함수
- 형태소 분석기 (Okt)
- ['Josa', 'Eomi', 'Punctuation'] 조사, 어미, 구두점 제거
def okt_clean(text):
clean_text = []
pos_text = okt.pos(text, norm=True, stem=True)
for word in pos_text:
if word[1] not in ['Josa', 'Eomi', 'Punctuation']:
clean_text.append(word[0])
return " ".join(clean_text)
print(okt_clean('오늘 뭐 먹을까?')
print(okt_clean('내일 날씨도 추울까?')
>>>>
오늘 뭐 먹다
내일 날씨 추다- 문자열 전처리를 정규화 한다고 표현
- 정규화 해주면 불필요하게 희소한 행렬이 생성되는 것 방지하고 같은 의미 묶기 가능
- 학습 속도가 너무 느려지는 것을 방지
train['title'] = train['title'].progress_map(okt_clean)
test['title'] = test['title'].progress_map(okt_clean)
>>>>
100%|█ █ █ █ █ █ █ █ █ █| 45654/45654 [02:08<00:00, 355.10it/s]
100%|█ █ █ █ █ █ █ █ █ █| 9131/9131 [00:23<00:00, 393.99it/s]불용어 제거
def remove_stopwords(text):
tokens = text.split(" ")
stops = [ '합니다', '하는', '할', '하고', '한다',
'그리고', '입니다', '그', '등', '이런', '및','제', '더']
meaningful_words = [w for w in tokens if not w in stops]
return ' '.join(meaningful_words)train['title'] = train['title'].map(remove_stopwords)
test['title'] = test['title'].map(remove_stopwords)
train['title']
>>>>
0 인천 핀란드 항공기 결항 휴가 철 여행객 분통
1 실리콘밸리 넘어서다 구글 15조원 들이다 전역 거점 화
2 이란 외무 긴장 완화 해결 책 미국 경제 전쟁 멈추다 것
3 nyt 클린턴 측근 기업 특수 관계 조명 공과 사 맞다 물리다 종합
4 시진핑 트럼프 중미 무역 협상 조속 타결 희망학습, 예측 데이터셋 만들기
X_train_text = train['title']
X_test_text = test['title']
X_train_text.shape, X_test_text.shape
>>>>
((45654,), (9131,))
label_name = 'topic_idx'
y_train = train[label_name]
y_train.head(2)
>>>>
0 4
1 4
Name: topic_idx, dtype: int64벡터화
- 머신러닝, 딥러닝 알고리즘 수치 계산을 위해 문자를 숫자로 변경
TF-IDF
- TfidfVectorizer
- fit 으로 변환할 어휘 학습 (train 데이터만)
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfvect = TfidfVectorizer()
tfiefvect.fit(X_train_text)
# transform -> 열 (columns, 어휘)의 수가 같은지 확인
X_train = tfidfvect.transform(X_train_text)
X_test = tfidfvect.transform(X_test_text)
X_train.shape, X_test.shape
>>>>
((45654, 28605), (9131, 28605))모델
- DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=42)cross validation
from sklearn.model_selection import cross_val_predict
y_predict = cross_val_predict(model, X_train, y_train, cv=3, n_jobs=-1, verbose=1)
y_predict[:5]
>>>>
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 2 concurrent workers.
[Parallel(n_jobs=-1)]: Done 3 out of 3 | elapsed: 37.0s finished
array([2, 0, 4, 6, 4])
score = (y_train == y_predict).mean()
>>>>
0.6957112191702808학습과 예측
y_test_predict = model.fit(X_train, y_train).predict(X_test)
y_test_predict[:5]
>>>>
array([1, 3, 4, 2, 3])정답값 로드
submit = pd.read_csv(f"{base_path}sample_submission.csv")
submit.head()
>>>>
index topic_idx
0 45654 0
1 45655 0
2 45656 0
3 45657 0
4 45658 0
# 정답값 측정을 위한 y_test_predict 변수 할당
submit['topic_idx'] = y_test_predict
submit
>>>>
index topic_idx
0 45654 1
1 45655 3
2 45656 4
3 45657 2
4 45658 3
file_name = f"{base_path}submit_{score}.csv"
file_name
>>>>
'data/klue/submit_0.6957112191702808.csv'
submit.to_csv(file_name, index=False)
pd.read_csv(file_name)
- 데이콘 제출


Ⓓ🅰️🅣🄰 ♡♥︎