
시작
- cmd에서 sysdba 권한으로 접속
C:\Users\ptah0>sqlplus sys/.. as sysdba
SQL*Plus: Release 11.2.0.2.0 Production on 목 1월 25 10:05:11 2024
Copyright (c) 1982, 2014, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Express Edition Release 11.2.0.2.0 - 64bit Production
SQL>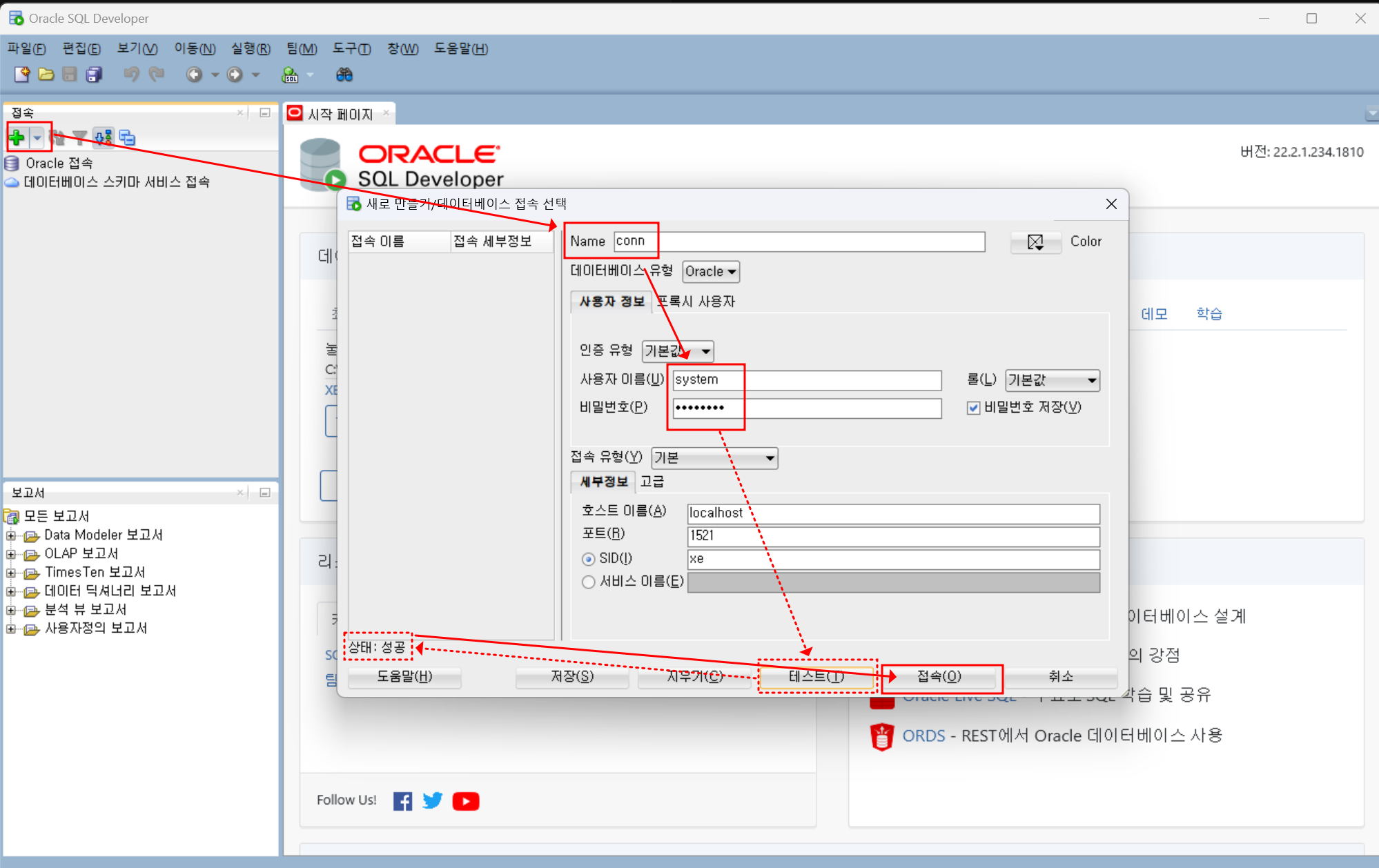
- 사원 생성 sql
-- 사원
CREATE TABLE EMP
(EMPNO NUMBER(4) NOT NULL, -- 사번 컬럼(열) 수자료형(4자리수 0 ~9999) 값 필수
ENAME VARCHAR2(10), -- 사원명 컬럼(열) 문자열(10바이트 영문숫자 1바이트 ,한글 3바이트)
JOB VARCHAR2(9),--업무
MGR NUMBER(4),--상사사번
HIREDATE DATE,--입사일 날짜형
SAL NUMBER(7, 2), --급여
COMM NUMBER(7, 2), --보너스
DEPTNO NUMBER(2));--부서번호;
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902,
TO_DATE('17-12-1980', 'DD-MM-YYYY'), 800, NULL, 20);
INSERT INTO EMP VALUES
(7499, 'ALLEN', 'SALESMAN', 7698,
TO_DATE('20-02-1981', 'DD-MM-YYYY'), 1600, 300, 30);
INSERT INTO EMP VALUES
(7521, 'WARD', 'SALESMAN', 7698,
TO_DATE('22-02-1981', 'DD-MM-YYYY'), 1250, 500, 30);
INSERT INTO EMP VALUES
(7566, 'JONES', 'MANAGER', 7839,
TO_DATE('2-08-1981', 'DD-MM-YYYY'), 2975, NULL, 20);
INSERT INTO EMP VALUES
(7654, 'MARTIN', 'SALESMAN', 7698,
TO_DATE('28-09-1981', 'DD-MM-YYYY'), 1250, 1400, 30);
INSERT INTO EMP VALUES
(7698, 'BLAKE', 'MANAGER', 7839,
TO_DATE('1-05-1981', 'DD-MM-YYYY'), 2850, NULL, 30);
INSERT INTO EMP VALUES
(7782, 'CLARK', 'MANAGER', 7839,
TO_DATE('9-06-1981', 'DD-MM-YYYY'), 2450, NULL, 10);
INSERT INTO EMP VALUES
(7788, 'SCOTT', 'ANALYST', 7566,
TO_DATE('09-12-1982', 'DD-MM-YYYY'), 3000, NULL, 20);
INSERT INTO EMP VALUES
(7839, 'KING', 'PRESIDENT', NULL,
TO_DATE('17-11-1981', 'DD-MM-YYYY'), 5000, NULL, 10);
INSERT INTO EMP VALUES
(7844, 'TURNER', 'SALESMAN', 7698,
TO_DATE('8-09-1981', 'DD-MM-YYYY'), 1500, 0, 30);
INSERT INTO EMP VALUES
(7876, 'ADAMS', 'CLERK', 7788,
TO_DATE('12-01-1983', 'DD-MM-YYYY'), 1100, NULL, 20);
INSERT INTO EMP VALUES
(7900, 'JAMES', 'CLERK', 7698,
TO_DATE('3-12-1981', 'DD-MM-YYYY'), 950, NULL, 30);
INSERT INTO EMP VALUES
(7902, 'FORD', 'ANALYST', 7566,
TO_DATE('3-12-1981', 'DD-MM-YYYY'), 3000, NULL, 20);
INSERT INTO EMP VALUES
(7934, 'MILLER', 'CLERK', 7782,
TO_DATE('23-01-1982', 'DD-MM-YYYY'), 1300, NULL, 10);
---------------------------
CREATE TABLE DEPT
(DEPTNO NUMBER(2) ,--부서번호
DNAME VARCHAR2(14),--부서명
LOC VARCHAR2(13) );--부서위치
INSERT INTO DEPT VALUES (10, 'ACCOUNTING', 'NEW YORK');--경영재무회계부;
INSERT INTO DEPT VALUES (20, 'RESEARCH', 'DALLAS');--연구부;
INSERT INTO DEPT VALUES (30, 'SALES', 'CHICAGO');--영업부;
INSERT INTO DEPT VALUES (40, 'OPERATIONS', 'BOSTON');--총무부;
CREATE TABLE BONUS
(ENAME VARCHAR2(10),
JOB VARCHAR2(9),
SAL NUMBER,
COMM NUMBER);
CREATE TABLE SALGRADE
(GRADE NUMBER,
LOSAL NUMBER,
HISAL NUMBER);
INSERT INTO SALGRADE VALUES (1, 700, 1200);
INSERT INTO SALGRADE VALUES (2, 1201, 1400);
INSERT INTO SALGRADE VALUES (3, 1401, 2000);
INSERT INTO SALGRADE VALUES (4, 2001, 3000);
INSERT INTO SALGRADE VALUES (5, 3001, 9999);
commit;
desc emp;
desc dept;
desc SALGRADE;
SELECT *
FROM emp;- 실행
전체 선택(ctrl + a) 후 실행(ctrl + Enter)
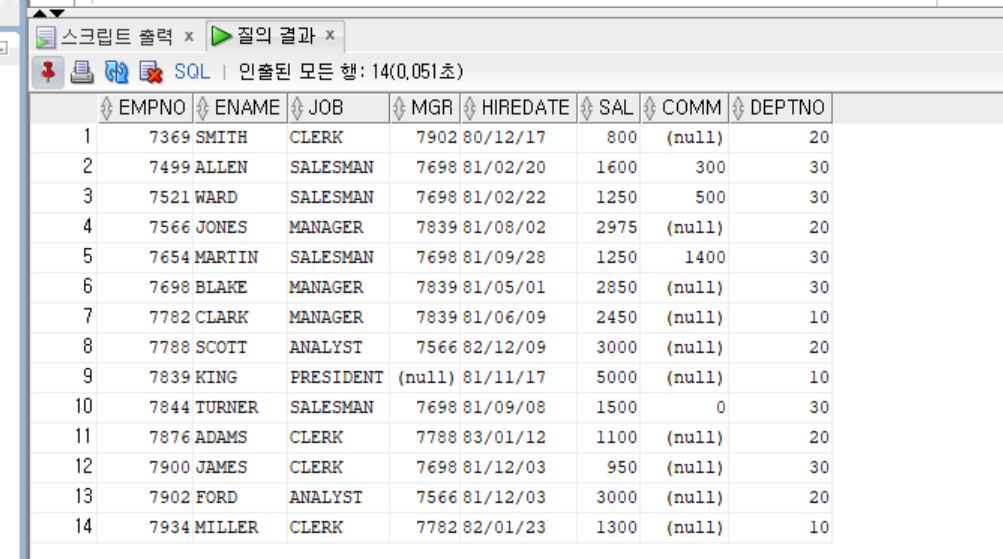
Accept Prompt
- 값 입력받기
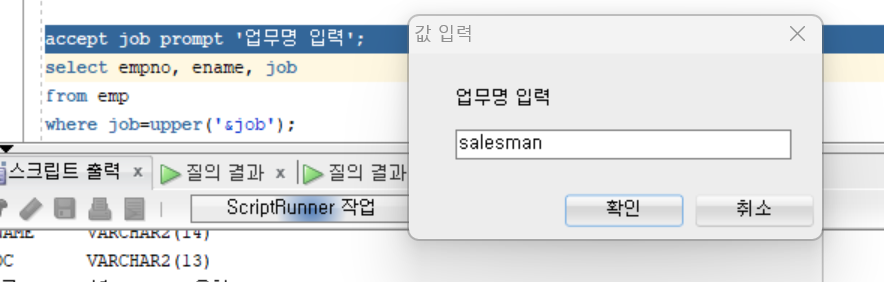
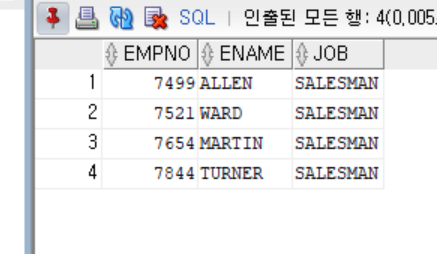
accept job prompt '업무명 입력';
select empno, ename, job
from emp
where job=upper('&job');- 결과
문자열
LENGTHB
select LENGTHB('Oracle'), LENGTHB('오라클')
from dual
;- 결과
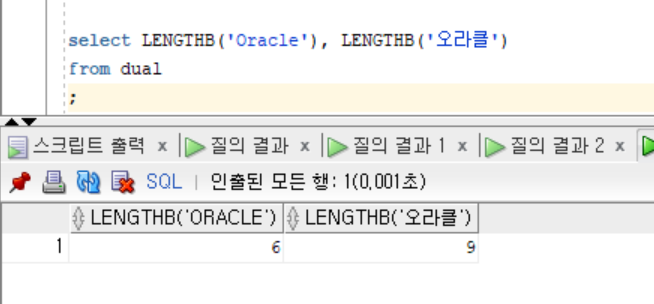
- ASCII는 각 1byte
- UTF-8은 각 3bytes
substr
- 실습1
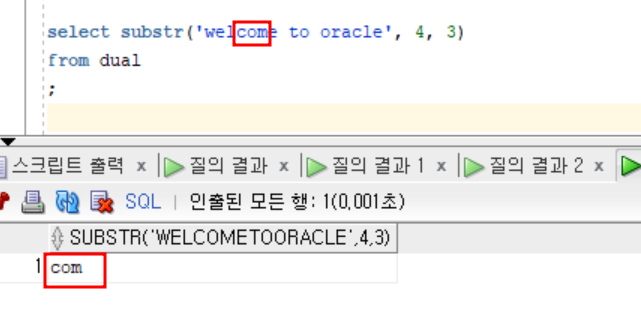
select substr('welcome to oracle', 4, 3)
from dual
;4번째 문자열 부터 문자 3개
- 실습2
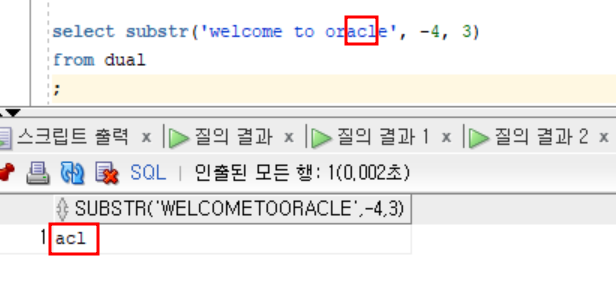
select substr('welcome to oracle', -4, 3)
from dual
;4번째 문자열부터 문자 3개
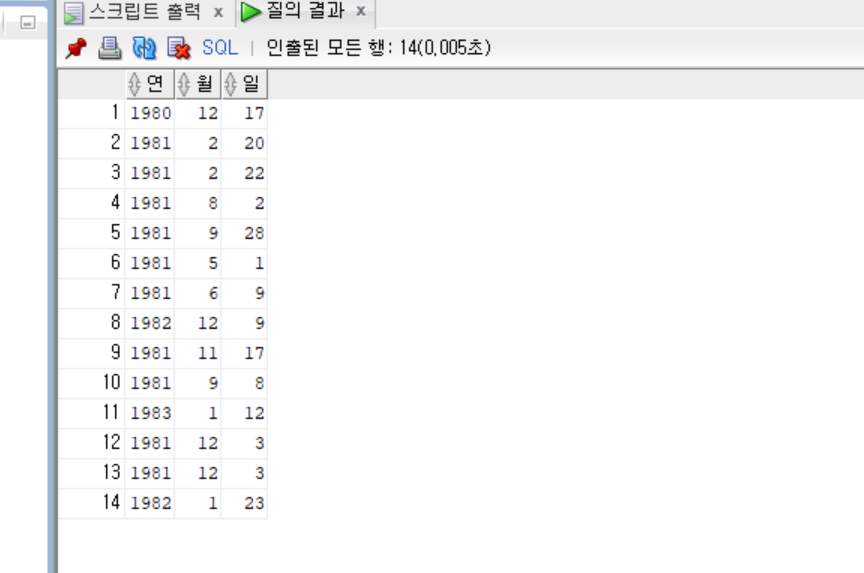
Extract
select
extract(year from hiredate) 연,
extract(month from hiredate) 월,
extract(day from hiredate) 일
from emp
;- 결과
instr
SELECT INSTR('welcome to oracle', 'o', 6, 2)
FROM dual;- 결과
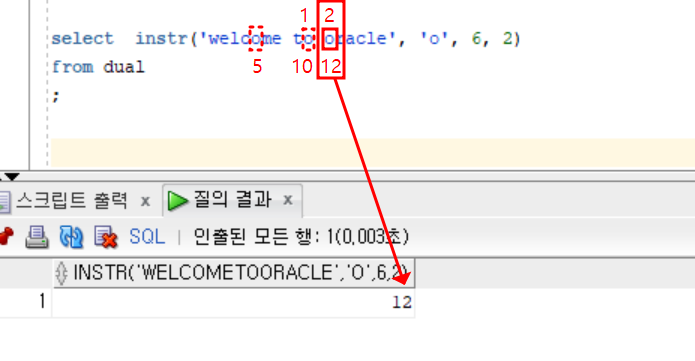
- 문자열 'welcome to oracle'에서 시작 위치 6번째 이후로 'o' 문자가 두 번째로 나타나는 위치를 찾습니다. 첫 번째 'o'는 'to'의 'o'이고, 두 번째 'o'는 'oracle'의 'o'입니다.
- 따라서, 이 쿼리의 결과는 'oracle'의 'o'가 문자열에서 차지하는 위치인 12를 반환합니다.
정규표현식
regexp_substr
- 숫자
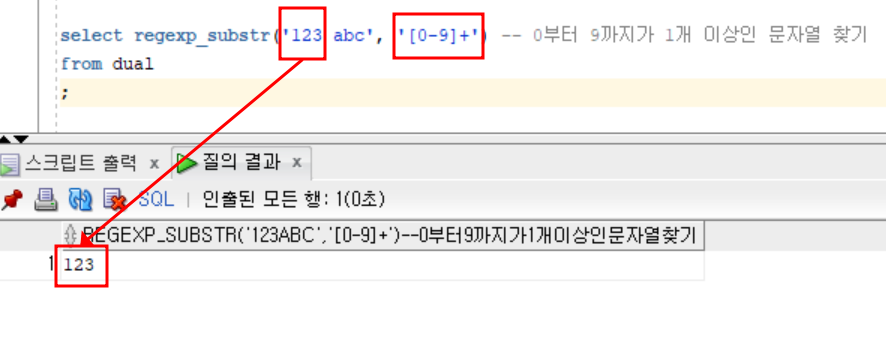
select regexp_substr('123 abc', '[0-9]+') -- 0부터 9까지가 1개 이상인 문자열 찾기
from dual
;- 결과
123- 알파벳
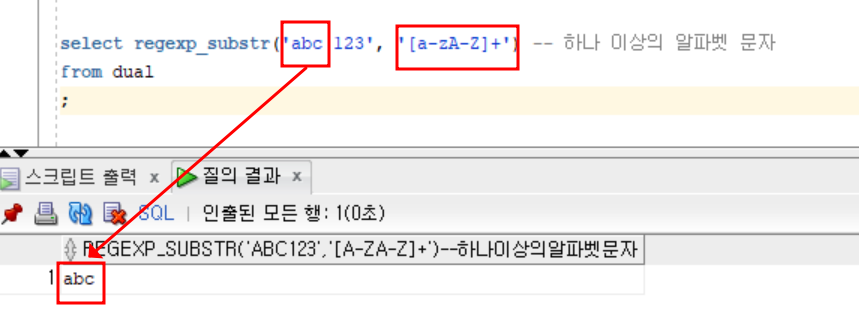
select regexp_substr('abc 123', '[a-zA-Z]+') -- 하나 이상의 알파벳 문자
from dual
;- 결과
abc - 한글
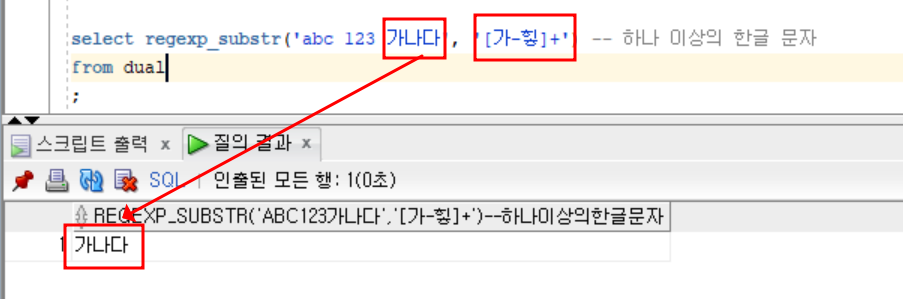
select regexp_substr('abc 123 가나다', '[가-힣]+') -- 하나 이상의 한글 문자
from dual
;- 결과
가나다TRIM
LTRIM
- 실습1
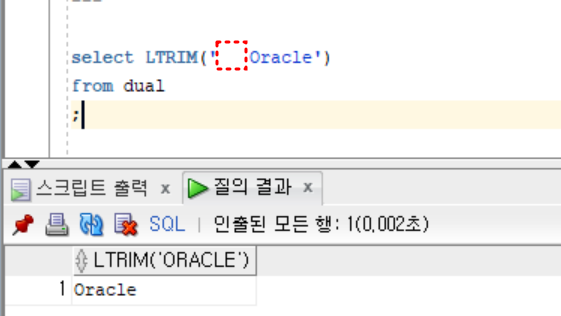
select LTRIM(' Oracle')
from dual
;- 실습2
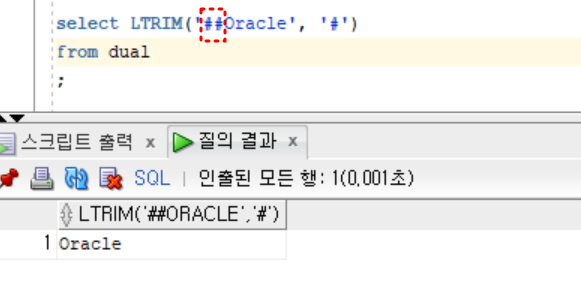
select LTRIM('##Oracle', '#')
from dual
;TRIM
- 실습1
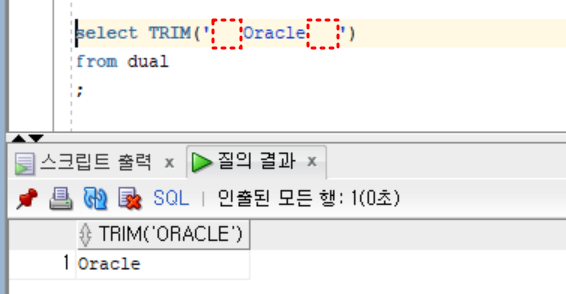
select TRIM(' Oracle ')
from dual
;- 실습2
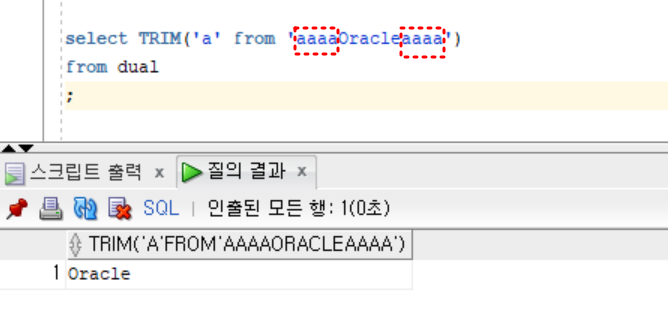
select TRIM('a' from 'aaaaOracleaaaa')
from dual
;Replace
select replace(' ora cle ', ' ', '')
from dual
;퀴즈
-- 1. 모든 사원들에게 급여의 20%를 보너스로 지불하기로 하였다. 이름, 급여, 보너스 금액을 출력하라.
-- 2. 급여가 2,000 이상인 모든 사원은 급여의 15%를 경조비로 내기로 하였다.
이름, 급여, 경조비 를 출력하라.
-- 3. 부서번호가 20인 부서의 시간당 임금을 계산하여 출력하라.
-- 단 이달의 근무일수가 12일이고, 1일 근무시간은 5시간이다.
-- 출력양식은 이름, 급여, 시간당 임금(소수이하 절삭)을 출력하라.
-- 4. 입사일이 81/04/02보다 늦고 82/12/09보다 빠른 모든 정보를 출력하라.
-- 5. 급여가 1,600보다 크고 3,000보다 작은 사원의 이름, 직업(업무), 급여를 출력하라.
-- 6. 직업이 MANAGER와 SALESMAN인 사원의 모든 정보를 출력하라.
단, 부서번호로 ASCENDING SORT 한 후 급여가 많은 사원 순으로 출력하라.
-- 7. 부서번호가 20, 30번을 제외한 모든 사원의 모든 정보를 출력하라.
-- 8. 입사일이 81년도인 사원의 모든 정보를 출력하라.
-- 9. 이름이 S로 시작하고 마지막 글자가 T인 사원의 모든 정보를 출력하라
단, 이름은 전체 5자리이다.--- Q1
select ename, sal, sal*0.2 as bonus
from emp
;
--- Q2
select ename, sal, sal*0.15 as cong
from emp
where sal >= 2000
;
--- Q3
select ename, sal, round(sal/12/5)
from emp
where deptno='20'
;
--- Q4
select *
from emp
where hiredate > '810402' and hiredate < '821209'
;
--- Q5
select ename, job, sal
from emp
where sal > 1600 and sal < 3000
;
--- Q6
select *
from emp
where job in ('MANAGER', 'SALESMAN')
order by deptno asc, sal desc
;
--- Q7
select *
from emp
where deptno not in ('20', '30')
;
--- Q8
select *
from emp
where substr(hiredate, 1, 2)='81'
;
--- Q9
select *
from emp
where ename like 'S%' and ename like '%T'
;- 이메일에서 도메인 추출
select
substr('tester@naver.com',
instr('tester@naver.com', '@') + 1,
instr('tester@naver.com', '.') - instr('tester@naver.com', '@') - 1)
from dual -
SUBSTR함수는 문자열에서 부분 문자열을 추출하는 데 사용됩니다. 이 경우에는tester@naver.com문자열에서 특정 부분을 추출합니다. -
INSTR함수는 문자열 내에 특정 문자 또는 문자열이 처음 등장하는 위치를 반환합니다. 이 쿼리에서는 두 번의INSTR호출이 사용됩니다.- 첫 번째
INSTR('tester@naver.com', '@')는 '@' 기호가 처음 등장하는 위치를 찾습니다. - 두 번째
INSTR('tester@naver.com', '.')는 '.' (점)이 처음 등장하는 위치를 찾습니다.
- 첫 번째
-
SUBSTR함수의 첫 번째 인자는 원본 문자열입니다. 두 번째 인자는 추출을 시작할 위치를 결정합니다. 여기서는 '@' 기호 다음의 문자부터 추출을 시작하므로,INSTR('tester@naver.com', '@') + 1을 사용합니다. -
SUBSTR함수의 세 번째 인자는 추출할 문자 수를 결정합니다. 여기서는 '@' 기호와 '.' 기호 사이의 문자 수를 계산하기 위해INSTR('tester@naver.com', '.') - INSTR('tester@naver.com', '@') - 1를 사용합니다. 이는 '.' 기호의 위치에서 '@' 기호의 위치를 빼고, 1을 더 빼서 '@' 바로 다음 문자부터 '.' 이전 문자까지의 길이를 계산합니다.

take a look
오늘 하루도 화이팅~!