1. 트랜잭션 코드의 분리
- 문제 : 트랜잭션 기술에 독립적으로 만들었지만, 아직도 비즈니스 로직에 트랜잭션 코드가 있다.
1.1 메서드 분리

upgradeLevels()특징- 두 가지 종류로 구분되어 있는 코드 : 트랜잭션 경계설정 코드와 비즈니스 로직으로 구분되어 있다.
- 독립적인 코드 : 트랜잭션 경계설정 코드와 비즈니스 로직 코드 간에 서로 주고받는 정보가 없다.
- 비즈니스 로직 코드에서 직접 DB를 사용하지 않기 때문에, 트랜잭션 준비 과정에서 만들어진 DB 커넥션 정보 등을 직접 참조할 필요가 없기 때문이다.
- 이 메서드에서 시작된 트랜잭션 정보는 트랜잭션 동기화 방법을 통해 DAO가 알아서 활용한다.
- 즉, 성격이 다른 두 개의 메서드로 분리하자.
비즈니스 로직 담당 코드를 메서드로 추출

1.2 DI를 이용한 클래스의 분리
-
문제
트랜잭션을 담당하는 기술적인 코드가 여전히UserService안에 있다. -
해결
적어도UserService에서는 안보이게 트랜잭션 코드를 클래스 밖으로 뽑아내자
1.2.1 DI 적용을 이용한 트랜잭션 분리
-
문제
UserService는 현재 클래스로 되어 있으니 다른 코드에서 사용한다면UserService클래스를 직접 참조하게 된다. 그런데 트랜잭션 코드를 밖으로 빼버리면,UserService클래스를 직접 사용하는 클라이언트 코드에서는 트랜잭션 기능이 빠진UserService를 사용하게 될 것이다. -
해결
DI를 사용하여 간접적으로 사용하면 된다. DI를 통해 실제 사용할 오브젝트의 클래스 정체는 감춘 채 인터페이스를 통해 간접으로 접근하는 것이다.
1. 결합도를 낮게 만든다.
현재 구조는 UserService 클래스와 사용 클라이언트 간의 관계가 강한 결합도로 고정되어 있다.
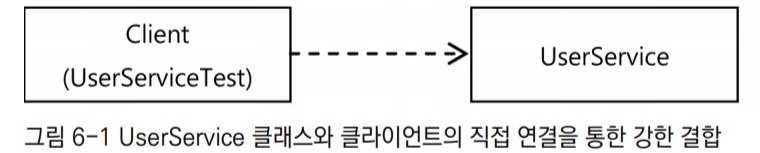
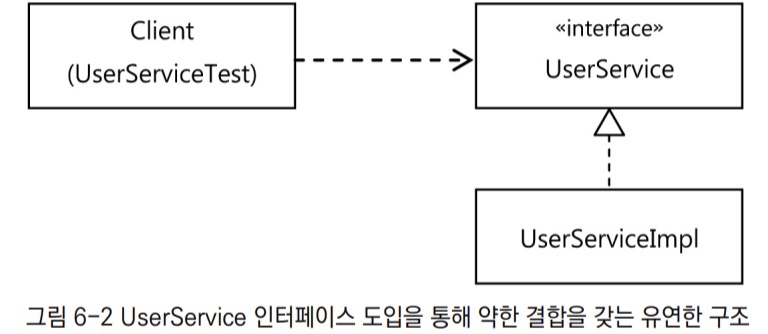
그래서 UserService를 인터페이스로 만들고 기존 코드는 UserService 인터페이스의 구현 클래스를 만들어넣도록 한다. 그러면 클라이언트와 결합이 약해지고, 유연한 확장이 가능해진다.
2. 두 개의 구현 클래스를 동시에 이용한다.
지금 문제는 UserService에는 순수하게 비즈니스 로직을 담고 있는 코드만 놔두고 트랜잭션 경계설정을 담당하는 코드를 외부로 빼내려는 것인데, 하지만 클라이언트가 UserService의 기능을 제대로 이용하려면 트랜잭션이 적용돼야 한다.
보통 이렇게 인터페이스를 이용해 구현 클래스를 클라이언트에 노출하지 않고 런타임 시에 DI를 통해 적용하는 방법을 쓰는 이유는, 일반적으로 구현 클래스를 바꿔가면서 사용하기 위해서다. 보통 한 번에 한 가지 클래스를 선택해서 적용하도록 되어있지만, 한 번에 두 개의 인터페이스 구현 클래스를 동시에 이용할 수도 있다.
먼저 UserService를 구현한 또 다른 구현 클래스를 만든다. 이 클래스는 사용자 관리 로직을 담고 있는 구현 클래스인 UserServiceImpl을 대신하기 위해 만든 게 아닌, 단지 트랜잭션의 경계설정 책임을 맡고 있을 뿐이다. 그리고 비즈니스 로직을 담고 있는 또 다른 UserService 구현 클래스에 실제적인 로직 처리 작업을 위임하는 것이다. 그 위임을 위한 호출 작업 이전과 이후에 적절한 트랜잭션 경계를 설정해주면, 클라이언트 입장에서는 기대하는 동작이 일어날 것이다.
1.2.2 UserService 인터페이스 도입
- 구현 방법
- 기존
UserService클래스를UserServiceImpl로 이름을 변경한다. - 클라이언트가 사용할 로직을 담은 핵심 메서드만
UserService인터페이스로 만든 후UserServiceImpl이 구현하도록 만든다.

UserServiceImpl에서 트랜잭션 관련 코드를 모두 제거한다. 앞에서upgradeLevelsInternal()로 분리했던 코드는 다시 원래대로upgradeLevels()에 넣는다.

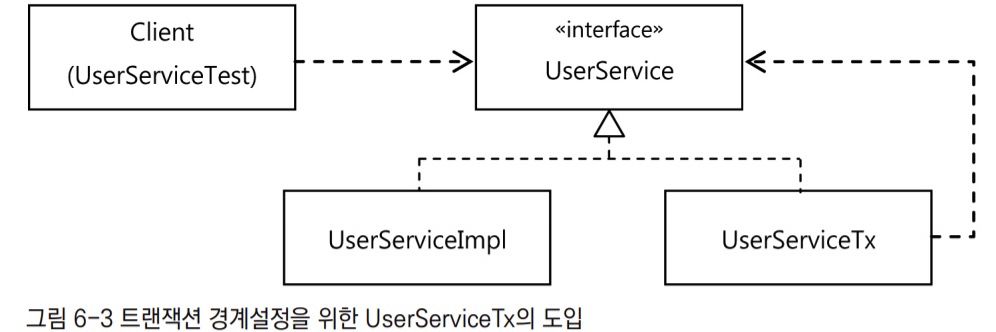
1.2.3 분리된 트랜잭션 기능
- 구현 기능
비즈니스 트랜잭션 처리를 담은UserServiceTx를 만들자. UserServiceTx는 기본적으로UserService를 구현하게 만든다.UserServiceTx는 비즈니스 로직을 전혀 갖지 않고 다른UserService구현 오브젝트에 기능을 위임한다. 이를 위해UserService오브젝트를 DI 받을 수 있도록 만든다.

UserServiceTx에 트랜잭션의 경계설정이라는 부가적인 작업을 부여해준다. 트랜잭션 매니저를 DI로 받아뒀다가 트랜잭션 안에서 동작하도록 만들어줘야 하는 메서드 호출의 전과 후에 필요한 트랜잭션 경계설정 API를 사용해주면 된다.

1.2.4 트랜잭션 적용을 위한 DI 설정
변경 부분
설정파일을 수정한다.
- 클라이언트가
UserService인터페이스를 통해 사용자 관리 로직을 이용하려고 할 때 먼저 트랜잭션을 담당하는 오브젝트가 사용돼서 트랜잭션에 관련된 작업을 진행해주고, 실제 사용자 관리 로직을 담은 오브젝트가 이후에 호출돼서 비즈니스 로직에 관련된 작업을 수행하도록 만든다.- 스프링의 DI 설정에 의해 만들어질 빈 오브젝트와 그 의존관계

- 스프링의 DI 설정에 의해 만들어질 빈 오브젝트와 그 의존관계
- 기존에 있던 빈의 프로퍼티 정보를 분리한다.

userService빈이 의존하고 있던transactionManager는UserServiceTx의 빈이 의존하게 한다.mailSender는 `UserServiceImpl 빈이 의존하게 한다.- 클라이언트는
UserServiceTx빈을 호출해서 사용하도록userService의 대표적인 빈 아이디는UserServiceTx클래스로 정의된 빈에게 부여해준다. userService빈은UserServiceImpl클래스로 정의되는, 아이디가userServiceImpl인 빈을 DI하게 만든다.
1.2.5 트랜잭션 분리에 따른 테스트 수정
@Autowired
기존에 UserService 클래스 타입의 빈을 @Autowired로 가져다가 사용했다. 우리가 수정한 스프링의 설정파일에는 UserService라는 인터페이스 타입을 가진 두 개의 빈이 존재한다. @Autowired는 기본적으로 타입을 이요해 빈을 찾지만 만약 타입으로 하나의 빈을 결정할 수 없는 경우에는 필드 이름을 이용해 빈을 찾는다.
따라서 UserServiceTest에서 다음과 같은 userService 변수를 설정해두면 아이디가 `userService인 빈이 주입될 것이다.
@Autowired UserService userService;UserServiceImpl
UserServiceTest는 UserServiceImpl 클래스로 정의된 빈도 가져와야 한다. 일반적인 UserService 기능의 테스트에서는 UserService 인터페이스를 통해 결과를 확인하는 것으로 충분하다. 그런데 앞 장에서 만든 MailSender 목 오브젝트를 이용한 테스트에서는 테스트에서 직접 MailSender를 DI 해줘야 할 필요가 있었다. MailSender를 DI 해줄 대상을 구체적으로 알고 있어야 하기 때문에 UserServiceImpl 클래스의 오브젝트를 가져올 필요가 있다.
개발자가 자신이 작성한 코드를 검증하기 위한 테스트인만큼 내부 구조를 잘 알고 있는 채로 테스트를 만드는 것에는 문제가 없다. 단순히
UserService의 기능을 테스트할 때는 구체적인 클래스 정보를 굳이 테스트에 노출하지 않는 편이 낫겠지만, 이렇게 목 오브젝트를 이용해 수동 DI를 적용하는 테스트라면 어떤 클래스의 오브젝트인지 분명하게 알 필요가 있다.
따라서 다음과 같이 UserServiceImpl 클래스 타입의 변수를 선언하고 @Autowired를 지정해서 해당 클래스로 만들어진 빈을 주입받도록 한다. 또한 upgradeLevels() 테스트 메서드에서 MailSender의 목 오브젝트를 설정해주는 건 이제 UserService 인터페이스를 통해선 불가능하기 때문에 userServiceImpl 빈에 해줘야 한다.

upgradeAllOrNothing()와 TestUserService
이 테스트는 사실 트랜잭션 기술이 바르게 적용됐는지를 홝인하기 위해 만든 일종의 학습 테스트기 때문에 직접 테스트용 확장 클래스도 만들고 수동 DI도 적용하고 한 만큼, 바뀐 구조를 모두 반영해주는 작업이 필요하다.
이젠 TestUserService가 트랜잭션 기능은 빠진 UserServiceImpl을 상속하도록 해야 한다. 트랜잭션 롤백의 확인을 위해 강제로 예외를 발생시킬 위치가 UserServiceImpl에 있기 때문이다. 그렇다고 이 오브젝트를 가지고 테스트해버리면, 트랜잭션이 빠져버려서 트랜잭션 테스트가 정상적으로 되지 않는다. 그래서 TestUserService 오브젝트를 UserServiceTx 오브젝트에 수동 DI시킨 후에 트랜잭션 기능까지 포함된 UserServiceTx의 메서드를 호출하면서 테스트를 수행하도록 해야 한다.
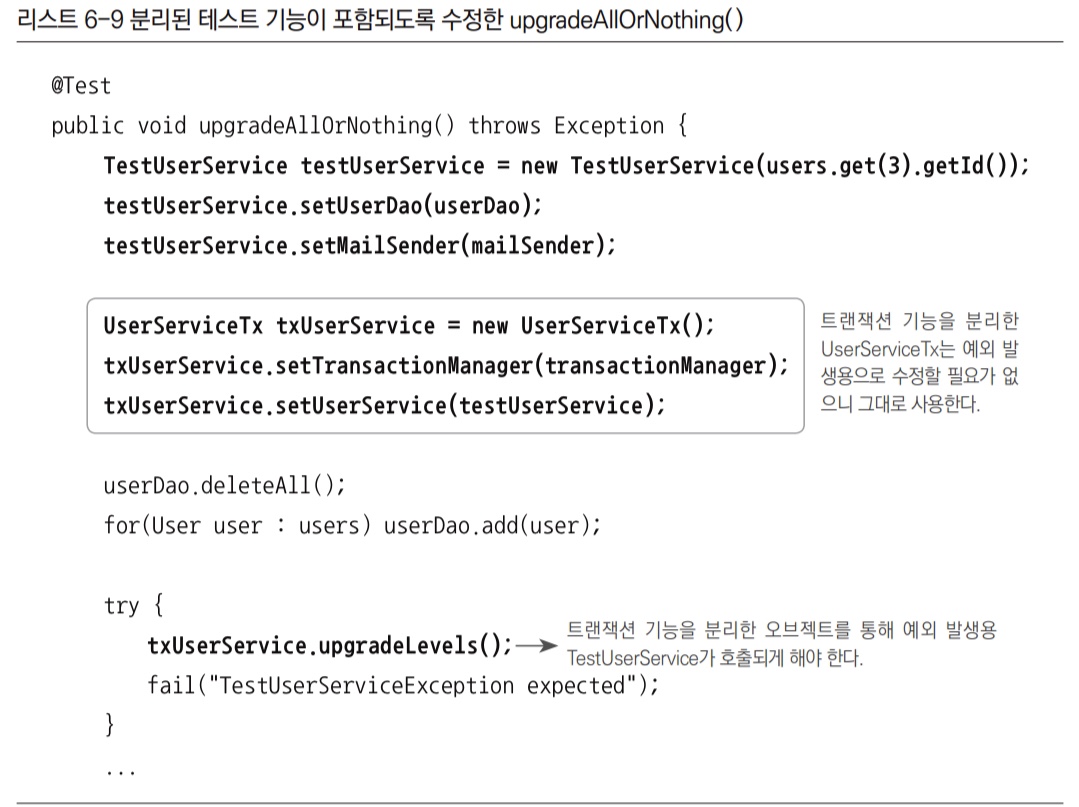
또한, 트랜잭션 테스트용으로 특별히 정의한 TestUserService 클래스는 이제 UserServiceimpl 클래스를 상속하도록 바꿔주면 된다.
static class TestUserService extends UserServiceImpl {1.2.6 트랜잭션 경계설정 코드 분리의 장점
- 비즈니스 로직을 담당하고 있는
UserServiceImpl의 코드를 작성할 때, 트랜잭션과 같은 기술적인 내용에는 전혀 신경 쓰지 않아도 된다. 트랜잭션의 적용이 필요한지도 신경 쓰지 않아도 된다. 트랜잭션은 DI를 이용해UserServiceTx와 같은 트랜잭션 기능을 가진 오브젝트가 먼저 실행되도록 만들기만 하면 된다. - 비즈니스 로직에 대한 테스트를 손쉽게 만들어낼 수 있다.
2. 고립된 단위 테스트
가장 편하고 좋은 테스트 방법은 가능한 한 작은 단위로 쪼개서 테스트하는 것이다.
작은 단위의 테스트는 테스트가 실패했을 때 그 원인을 찾기 쉽다. 또한, 테스트 단위가 작아야 테스트의 의도나 내용이 분명해지고, 만들기도 쉬워진다.
하지만 작은 단위로 테스트하고 싶어도 그럴 수 없는 경우가 많다. 테스트 대상이 다른 오브젝트와 환경에 의존하고 있다면 작은 단위의 테스트가 주는 장점을 얻기 힘들다.
2.1 복잡한 의존관계 속의 테스트
UserService는 굉장히 간단한 기능만을 갖고 있지만, UserService의 구현 클래스들이 동작하려면 세 가지 타입의 의존 오브젝트가 필요하다. UserDao 타입의 오브젝트를 통해 DB와 데이터를 주고받아야 하고, MailSender를 구현한 오브젝트를 이용해 메일을 발송해야 한다. 또, 트랜잭션 처리를 위해 PlatformTransactionManager와 커뮤니케이션이 필요하다.
UserService를 분리하기 전의 테스트가 동작하는 모습
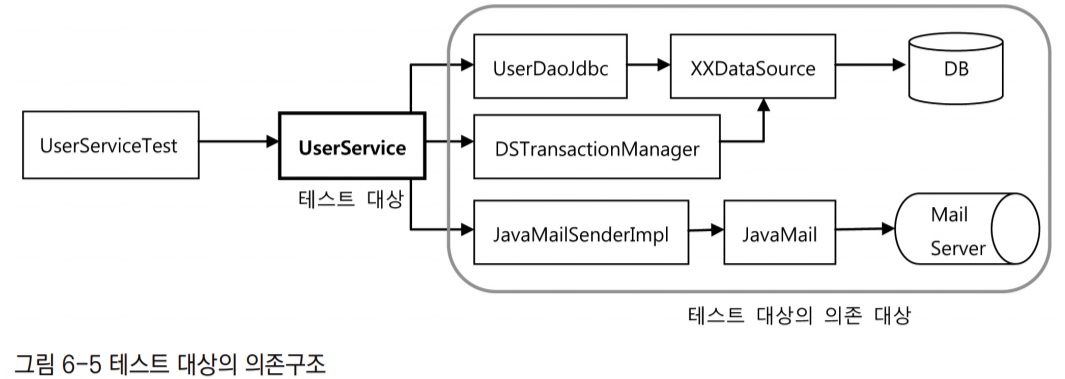
UserServiceTest의 문제점
UserServiceTest가 테스트하고자 하는 대상인 UserService는 사용자 정보를 관리하는 비즈니스 로직의 구현 코드다. 따라서 UserService의 코드에 따라 성공하거나 실패하면 된다. 따라서 테스트의 단위는 UserService 클래스여야 한다.
하지만 UserService는 UserDao, TransactionManager, MailSender라는 세 가지 의존관계를 갖고 있다. 따라서 그 세 가지 의존관계를 갖는 오브젝트들이 테스트가 진행되는 동안에 같이 실행된다. 더 큰 문제는 그 세 가지 의존 오브젝트도 자신의 코드만 실행하고 마는 것이 아니라는 점이다.
JDBC를 이용해 UserDao를 구현한 UserDaoJdbc는 DataSource이 구현 클래스와 DB 드라이버, 그리고 DB 서버까지의 네트워크 통신과 DB 서버 자체 그리고 그 안에 정의된 테이블에 모두 의존하고 있다.
트랜잭션 매니저는 DataSource 방식이라 데이터 소스 구현에만 의존하고 있지만, JTA였다면 JTA 구현 오브젝트와 WAS 서버의 트랜잭션 서비스에까지 의존하고 있을 것이다. 메일도 앞에서 살펴본 것처럼 메일 서버의 셋업 상태에까지 모두 의존하고 있다. 메일도 메일 서버의 셋업 상태에까지 모두 의존하고 있다.
따라서 UserService를 테스트하는 것처럼 보이지만 사실 그 뒤에 존재하는 훨씬 더 많은 오브젝트와 환경, 서비스, 서버, 네트워크까지 함께 테스트하는 셈이 된다. 그래서 UserService라는 테스트 대상이 테스트 단위인 것처럼 보이지만 사실 그 뒤의 의존관계를 따라 등장하는 오브젝트와 서비스, 환경 등이 모두 합쳐져 테스트 대상이 되는 것이다.
따라서 이런 경우의 테스트는 준비하기 힘들고, 환경이 조금이라도 달라지면 동일한 테스트 결과를 내지 못할 수도 있으며, 수행 속도는 느리고 그에 따라 테스트를 작성하고 실행하는 빈도가 점차로 떨어질 것이 분명하다.
2.2 테스트 대상 오브젝트 고립시키기
그래서 테스트의 대상이 환경이나, 외부 서버, 다른 클래스의 코드에 종속되고 영향받지 않도록 고립시킬 필요가 있다. 테스트를 의존 대상으로부터 분리해서 고립시키는 방법은 테스트를 위한 대역을 사용하는 것이다. MailSender에는 이미 DummyMailSender라는 테스트 스텁을 적용했다. 또 테스트 대역이 테스트 검증에도 참여할 수 있도록, 특별히 만든 MockMailSender라는 목 오브젝트도 사용해봤다.
2.2.1 테스트를 위한 UserServiceImpl 고립
UserServiceImpl에서 트랜잭션 코드를 독립시켰기 때문에 PlatformTransactionManager은 적용할 필요가 없다. 이렇게 고립된 테스트가 가능하도록 UserService를 재구성해보면 밑의 구조가 된다. 이제 UserServiceImpl에 대한 테스트가 진행될 때 사전에 테스트를 위해 준비된 동작만 하도록 만든 두 개의 목 오브젝트에만 의존하는, 완벽하게 고립된 테스트 대상으로 만들 수 있다.
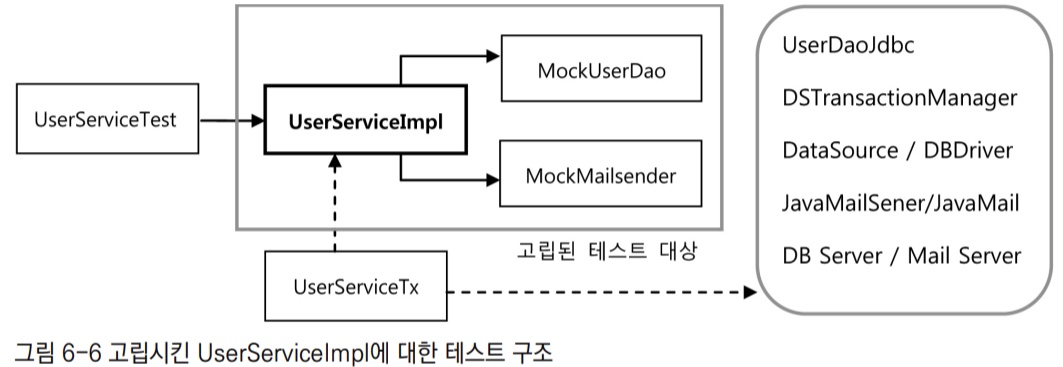
UserDao는 단지 테스트 대상의 코드가 정상 수행되도록 도와주기만 하는 스텁이 아니라, 부가적인 검증 기능까지 가진 목 오브젝트로 만들었다. 그 이유는 고립된 환경에서 동작하는 upgradeLevels()의 테스트 결과를 검증할 방법이 필요하기 때문이다.
UserServiceImpl의 upgradeLevels() 메서드는 void형이기 때문에 메서드를 실행하고 그 결과를 받아서 검증하는 것은 아예 불가능하다. upgradeLevels()는 DAO를 통해 필요한 정보를 가져와, 일정한 작업을 수행하고 그 결과를 다시 DAO를 통해 DB에 반영한다. 따라서 그 코드의 동작이 바르게 됐는지 확인하려면 결과가 남아있는 DB를 직접 확인할 수 밖에 없다.
그런데 의존 오브젝트나 외부 서비스에 의존하지 않는 고립된 테스트 방식으로 만든 UserServiceImpl은 아무리 그 기능이 수행돼도 그 결과가 DB 등을 통해서 남지 않는다. 이럴 땐 테스트 대상인 UserServiceImpl과 그 협력 오브젝트인 UserDao에게 어떤 요청을 했는지를 확인하는 작업이 필요하다. 테스트 중에 DB에 결과가 반영되지는 않았지만, UserDao의 update() 메서드를 호출하는 것을 확인할 수 있다면, 결국 DB에 그 결과가 반영될 것이라고 결론을 내릴 수 있기 때문이다. UserDao와 같은 역할을 하면서 UserServiceImpl과의 사이에서 주고받은 정보를 저장해뒀다가, 테스트의 검증에 사용할 수 있게 하는 목 오브젝트를 만들 필요가 있다.
2.2.2 고립된 단위 테스트 활용
고립된 단위 테스트 방법을 UserServiceTest의 upgradeLevels() 테스트에 적용해보자.
기존 테스트 코드의 구성을 자세히 살펴보자.

이 테스트는 다섯 단계의 작업으로 구성된다.
- 테스트 실행 중에
UserDao를 통해 가져올 테스트용 정보를 DB에 넣는다.UserDao는 결국 DB를 이용해 정보를 가져오기 때문에 최후의 의존 대상이 DB에 직접 정보를 넣어줘야 한다. - 메일 발송 여부를 확인하기 위해
MailSender목 오브젝트를 DI 해준다. - 실제 테스트 대상인
userService의 메서드를 실행한다. - 결과가 DB에 반영됐는지 확인하기 위해서
UserDao를 이용해 DB에서 데이터를 가져와 결과를 확인한다. - 목 오브젝트를 통해
UserService에 의한 메일 발송이 있었는지를 확인하면 된다.
테스트 작업을 분류해보면 처음 두 가지는 UserService의 upgradeLevels() 메서드가 실행되는 동안에 사용하는 의존 오브젝트가 테스트의 목적에 맞게 동작하도록 준비하는 과정이다. 첫 번째 작업은 의존관계를 따라 마지막에 등장하는 DB를 준비하는 것인 반면에, 두 번째는 테스트를 의존 오브젝트와 서버 등에서 고립시키도록 테스트만을 위한 목 오브젝트를 준비한다는 점이 다르다.
네 번째와 다섯 번째는 테스트 대상 코드를 실행한 후에 결과를 확인하는 작업이다. 네 번째는 의존관계를 따라 결국 최종 결과가 반영된 DB의 내용을 확인하는 방법인 반면, 다섯 번째는 메일 서버까지 갈 필요 없이 목 오브젝트를 통해 upgradeLevels() 메서드가 실행되는 중에 메일 발송 요청이 나간 적이 있는지만 확인하도록 되어 있다.
2.2.3 UserDao 목 오브젝트
이제 실제 UserDao와 DB까지 직접 의존하고 있는 첫 번째와 네 번째의 테스트 방식도 목 오브젝트를 만들어서 적용해보자.
목 오브젝트는 기본적으로 스텁과 같은 방식으로 테스트 대상을 통해 사용될 때 필요한 기능을 지원해줘야 한다.


UserSeriviceImpl의 코드를 살펴보면 upgradeLevels() 메서드와 그 사용 메서드에서 UserDao를 사용하는 경우는 두 가지다.
userDao.getAll()은 레벨 업그레이드 후보가 될 사용자의 목록을 받아온다.
- 이 메서드 기능을 지원하기 위해서 테스트용
UserDao에는 DB에서 읽어온 것처럼 미리 준비된 사용자 목록을 제공해줘야 한다.
userDao.update(user)의 호출은 리턴 값이 없다.
- 따라서 테스트용 UserDao가 특별히 미리 준비해둘 것은 없다. 테스트가 진행되도록 하기 위해서라면 빈 메서드로 만들어도 된다.
- 하지만
update()메서드의 사용은upgradeLevels()의 핵심 로직인 '전체 사용자 중에서 업그레이드 대상자는 레벨을 변경해준다'에서 '변경'에 해당하는 부분을 검증할 수 있는 중요한 기능이기도 하다. 업그레이드를 통해 레벨이 변경된 사용자는 DB에 반영되도록userDao의update()에 전달돼야 하기 때문이다.
그래서 getAll()에 대해서는 스텁으로서, update()에 대해서는 목 오브젝트로서 동작하는 UserDao 타입의 테스트 대역이 필요하다.
클래스 이름을 MockUserDao라고 하고, UserServiceTest 전용일 테니 역시 스태틱 내부 클래스로 만들면 편리하다. 물론 따로 클래스 파일을 두고 만들어도 상관없다.
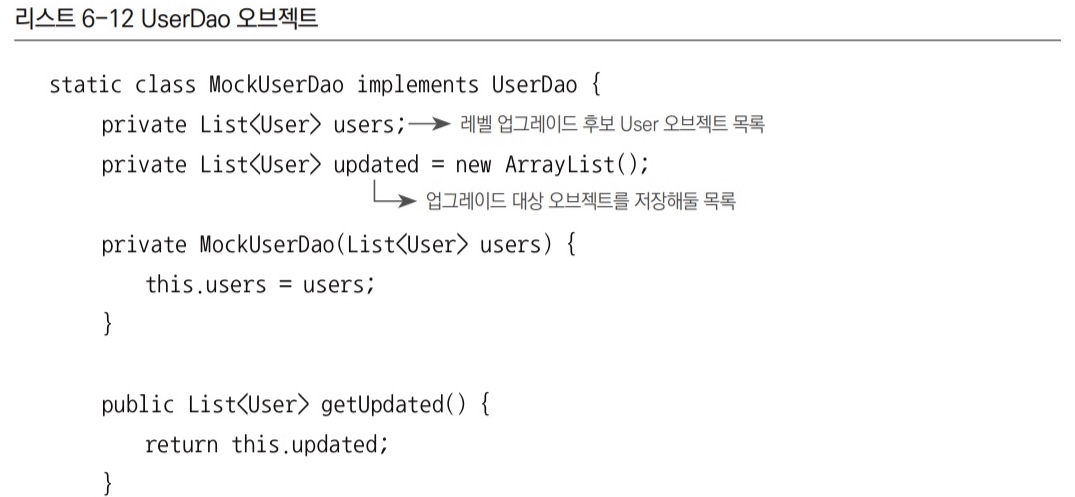

MockUserDao
UserDao구현 클래스를 대신해야 하니UserDao인터페이스를 구현해야 한다.
upgradeLevels()테스트 중 사용할 것은getAll()과update()뿐이고, 사용하지 않을 메서드도 구현해줘야 한다면UnsupportedOperationException을 던지도록 만드는 편이 좋다.
그냥 빈 채로 두거나null을 리턴하게 해도 문제는 없지만, 실수로 사용될 위험이 있으므로 지원하지 않는 기능이라는 예외가 발생하도록 만드는 게 좋다.- `MockUserDao에는 두 개의 User 타입 리스트를 정의해둔다.
- 하나는 생성자를 통해 전달받은 사용자 목록을 저장해뒀다가,
getAll()메서드가 호출되면 DB에서 가져온 것처럼 돌려주는 용도다.
목 오브젝트를 사용하지 않을 때는 일일이 DB에 저장했다가 다시 가져와야 했지만,MockUserDao는 미리 준비된 테스트용 리스트를 메모리에 갖고 있다가 돌려주기만 하면 된다. - 다른 하나는
update()메서드를 실행하면서 넘겨준 업그레이드 대상User오브젝트를 저장해뒀다가 검증을 위해 돌려주기 위한 것이다.
upgradeLevels()메서드가 실행되는 동안 업그레이드 대상으로 선정된 사용자가 어떤 것인지 확인하는 데 쓰인다.

이전의 테스트의 대상은 스프링 컨테이너에서 @Autowired를 통해 가져온 UserService 타입의 빈이었다. 컨테이너에서 가져온 UserService 오브젝트는 DI를 통해서 많은 의존 오브젝트와 서비스, 외부 환경에 의존하고 있었지만, 이제는 완전히 고립돼서 테스트만을 위해 독립적으로 동작하는 테스트 대상을 사용할 것이기 때문에 스프링 컨테이너에서 빈을 가져올 필요가 없다.
upgradeLevels()에 MockUserDao 적용
- 먼저 테스트하고 싶은 로직을 담은 클래스인
UserServiceimpl의 오브젝트를 직접 생성한다.
UserServiceTest내의 다른 테스트들이 아직 스프링으로부터 가져온 빈을 가지고 테스트하기 때문에 테스트 클래스의 설정은 그대로 뒀지만upgradeLevels()테스트만 있었다면 스프링의 테스트 컨텍스트를 이용하기 위해 도입한@ExtendsWith등은 제거할 수 있다. - 준비해둔
MockUserDao,MockMailSender오브젝트를 사용하도록 수동 DI를 해준다. - 테스트 대상인
UserServiceImpl오브젝트의 메서드를 실행시킨다.
MockUserDao가 의존 오브젝트로 DI 되어 있으므로 미리 준비해둔 사용자 목록을 받을 것이고, 로직에 따라 업그레이드 대상을 선정해서 레벨 변경 후MockUserDao의update()메서드를 호출하게 된다. - 검증한다.
- 검증할 사항 :
UserServiceImpl은UserDao의update()를 이용해 몇 명의 사용자 정보를 DB에 수정하려고 했는지, 그 사용자들이 누구인지, 어떤 레벨로 변경됐는지 MockUserDao오브젝트로부터update()가 호출될 때 전달받은 사용자 목록을 가져온다. 호출될 때마다 저장해둔 사용자 목록이 있을 것이다.
2.2.4 테스트 수행 성능의 향상
add()와 upgradeAllOrNothing()은 여전히 DB까지 연동하는 의존 대상이 모두 포함된 테스트다. DB를 이용하는 테스트와 목 오브젝트만을 이용하는 테스트의 수행시간을 비교해보면 후자가 1밀리초 정도로 굉장히 짧다.
이유가 무엇일까?
그것은 UserServiceImpl와 테스트를 도와주는 두 개의 목 오브젝트 외에는 사용자 관리 로직을 검증하는 데 직접적으로 필요하지 않은 의존 오브젝트와 서비스를 모두 제거한 덕분이다. 만약 DB에서 복잡한 방법으로 대량의 데이터를 조합해 가져오는 SQL을 가진 DAO를 사용하고, 진행 과정에서 수많은 DB 업데이트나 등록이 일어나는 테스트라면 테스트 수행시간은 훨씬 큰 차이를 보일 것이다.
2.3 단위 테스트와 통합 테스트
단위 테스트의 단위는 정하기 나름이다. 중요한 것은 하나의 단위에 초점을 맞춘 테스트라는 점이다. 단위 테스트라는 용어를 사용할 때는 그 의미를 명확히 할 필요가 있다.
이 책에서는 앞으로 '테스트 대상 클래스를 목 오브젝트 등의 테스트 대역을 이용해 의존 오브젝트나 외부의 리소스를 사용하지 않도록 고립시켜서 테스트하는 것'을 단위 테스트라고 부르겠다.
반면에 두 개 이상의, 성격이나 계층이 다른 오브젝트가 연동하도록 만들어 테스트하거나, 또는 외부의 DB나 파일, 서비스 등의 리소스가 참여하는 테스트는 통합 테스트라고 부르겠다. 통합 테스트란 두 개 이상의 단위가 결합해서 동작하면서 테스트가 수행되는 것이라고 보면 된다. 스프링의 테스트 컨텍스트 프레임워크를 이용해서 컨텍스트에서 생성되고 DI된 오브젝트를 테스트하는 것도 통합 테스트다.
단위 테스트와 통합 테스트 결정 방법 가이드라인
- 항상 단위 테스트를 먼저 고려한다.
- 하나의 클래스나 성격과 목적이 같은 긴밀한 클래스 몇 개를 모아서 외부와의 의존관계를 모두 차단하고 필요에 따라 스텁이나 목 오브젝트 등의 테스트 대역을 이용하도록 테스트를 만든다. 단위 테스트는 테스트 작성도 간단하고 실행 속도도 빠르며 테스트 대상 외의 코드나 환경으로부터 테스트 결과에 영향을 받지도 않기 때문에 가장 빠른 시간에 효과적인 테스트를 작성하기에 유리하다.
- 외부 리소스를 사용해야만 가능한 테스트는 통합 테스트로 만든다.
- 단위 테스트로 만들기가 어려운 코드도 있다. 대표적인 게 DAO다. DAO는 그 자체로 로직을 담고 있기보다는 DB를 통해 로직을 수행하는 인터페이스와 같은 역할을 한다. SQL을 JDBC를 통해 실행하는 코드만으로는 고립된 테스트를 작성하기가 힘들다. 작성한다고 해도 가치가 없는 경우가 대부분이다. 따라서 DAO는 DB까지 연동하는 테스트로 만드는 편이 효과적이다. DB를 사용하는 테스트는 DB에 테스트 데이터를 준비하고 DB에 직접 확인을 하는 등의 부가적인 작업이 필요하다.
- DAO 테스트는 DB라는 외부 리소스를 사용하기 때문에 통합 테스트로 분류된다. 하지만 코드에서 보자면 하나의 기능 단위를 테스트하는 것이기도 하다. DAO를 테스트를 통해 충분히 검증해두면, DAO를 이용하는 코드는 DAO 역할을 스텁이나 목 오브젝트로 대체해서 테스트할 수 있다. 이후에 실제 DAO와 연동했을 때도 바르게 동작하리라고 확신할 수 있다. 물론 각각의 단위 테스트가 성공했더라도 여러 개의 단위를 연결해서 테스트하면 오류가 발생할 수도 있다. 하지만 충분한 단위 테스트를 거친다면 통합 테스트에서 오류가 발생할 확률도 줄어들고 발생한다고 하더라도 쉽게 처리할 수 있다.
- 여러 개의 단위가 의존관계를 가지고 동작할 때를 위한 통합 테스트는 필요하다. 다만, 단위 테스트를 충분히 거쳤다면 통합 테스트의 부담은 상대적으로 줄어든다.
- 단위 테스트를 만들기가 너무 복잡하다고 판단되는 코드는 처음부터 통합 테스트를 고려해본다. 이때도 통합 테스트에 참여하는 코드 중에서 가능한 한 많은 부분을 미리 단위 테스트로 검증해두는 게 유리하다.
- 스프링 테스트 컨텍스트 프레임워크를 이용하는 테스트는 통합 테스트다. 가능하면 스프링의 지원 없이 직접 코드 레벨의 DI를 사용하면서 단위 테스트를 하는 게 좋겠지만 스프링의 설정 자체도 테스트 대상이고, 스프링을 이용해 좀 더 추상적인 레벨에서 테스트해야 할 경우도 종종 있다. 이럴 땐 스프링 테스트 컨텍스트 프레임워크를 이용해 통합 테스트를 작성한다.
그 외
- 테스트는 코드가 작성되고 빠르게 진행되는 편이 좋다.
- 테스트를 먼저 만들어두는 TDD는 코드를 만들자마자 바로 테스트가 가능하다는 장점이 있다.
- 코드를 만들고 나서 오랜 시간이 지난 뒤에 작성하는 테스트는 테스트 대상 코드에 대한 이해가 떨어지기 때문에 불완전해지기 쉽게 작성하기도 번거롭다.
- 코드를 작성하면서 테스트는 어떻게 만들 수 있을까를 생각해보는 것은 좋은 습관이다.
테스트가 없으면 과감하게 리팩토링할 엄두를 내지 못할 것이고 코드의 품질은 점점 떨어지고 유연성과 확장성을 잃어갈지 모른다.
2.4 목 프레임워크
단위 테스트를 만들기 위해서는 스텁이나 목 오브젝트의 사용이 필수적이다. 의존관계가 없는 단순한 클래스나 세부 로직을 검증하기 위해 메서드 단위로 테스트할 때가 아니라면, 대부분 의존 오브젝트를 필요로 하는 코드를 테스트하게 되기 때문이다.
단위 테스트가 가장 우선시해야 할 테스트 방법이지만 작성이 번거롭다. 특히 목 오브젝트를 만들 때, 테스트에서는 사용하지 않는 인터페이스도 모두 일일이 구현해줘야 한다는 점이 큰 짐이다. 검증 기능이 있는 목 오브젝트로 만들려면, 메서드의 호출 내용을 저장했다가 이를 다시 불러오는 것도 귀찮은 일이다. 특히 테스트 메서드별로 다른 검증 기능이 필요하다면, 같은 의존 인터페이스를 구현한 여러 개의 목 클래스를 선언해줘야 한다. 다행히도, 편리하게 작성하도록 도와주는 다양한 목 오브젝트 지원 프레임워크가 있다.
2.4.1 Mockito 프레임워크
Mockito와 같은 목 프레임워크의 특징은 목 클래스를 일일이 준비해둘 필요가 없다는 점이다. 간단한 메서드 호출만으로 다이내믹하게 특정 인터페이스를 구현한 테스트용 목 오브젝트를 만들 수 있다.
적용 방법
UserDao인터페이스를 구현한 테스트용 목 오브젝트는 Mockito의 스태틱 메서드를 한 번 호출해주면 만들어진다.
UserDao mockUserDao = mock(UserDao.class);- 이렇게 만들어진 목 오브젝트는 아직 아무런 기능이 없다. 여기에 먼저
getAll()메서드가 불려올 때 사용자 목록을 리턴하도록 스텁 기능을 추가해줘야 한다.
when(mockUserDao.getAll()).thenReturn(this.users);mockUserDao.getAll()이 호출됐을 때(when),users리스트를 리턴해주라(thenReturn)는 선언이다.- 이렇게 정의한 후에는
mockUserDao의getAll()메서드가 호출되면users리스트가 자동으로 리턴될 것이다.
- 다음은
update()호출이 있었는지를 검증한다.
Mockito를 통해 만들어진 목 오브젝트는 메서드의 호출과 관련된 모든 내용을 자동으로 저장해두고, 이를 간단한 메서드로 검증할 수 있게 해준다.
테스트를 진행하는 동안mockUserDao의update()메서드가 두 번 호출됐는지 확인하고 싶다면, 다음과 같은 검증 코드를 넣어주면 된다.
verify(mockUserDao, times(2)).update(any(User.class));User타입의 오브젝트를 파라미터로 받으며update()메서드가 두 번 호출됐는지(times(2)) 확인하라(verify)는 것이다.
Mockito 목 오브젝트 사용방법
Mockito 목 오브젝트는 다음의 네 단계를 거쳐서 사용하면 된다. 두 번째와 네 번째는 각각 필요할 경우에만 사용할 수 있다.
- 인터페이스를 이용해 목 오브젝트를 만든다.
- 목 오브젝트가 리턴할 값이 있으면 이를 지정해준다. 메서드가 호출되면 예외를 강제로 던지게 만들 수도 있다.
- 테스트 대상 오브젝트에 DI 해서 목 오브젝트가 테스트 중에 사용되도록 만든다.
- 테스트 대상 오브젝트를 사용한 후에 목 오브젝트의 특정 메서드가 호출됐는지, 어떤 값을 가지고 몇 번 호출됐는지를 검증한다.
특별한 기능을 가진 목 오브젝트를 만들어야 하는 경우가 아니라면 거의 대부분의 단위 테스트에서 필요한 목 오브젝트는 Mockito를 사용하는 것으로 충분한다.
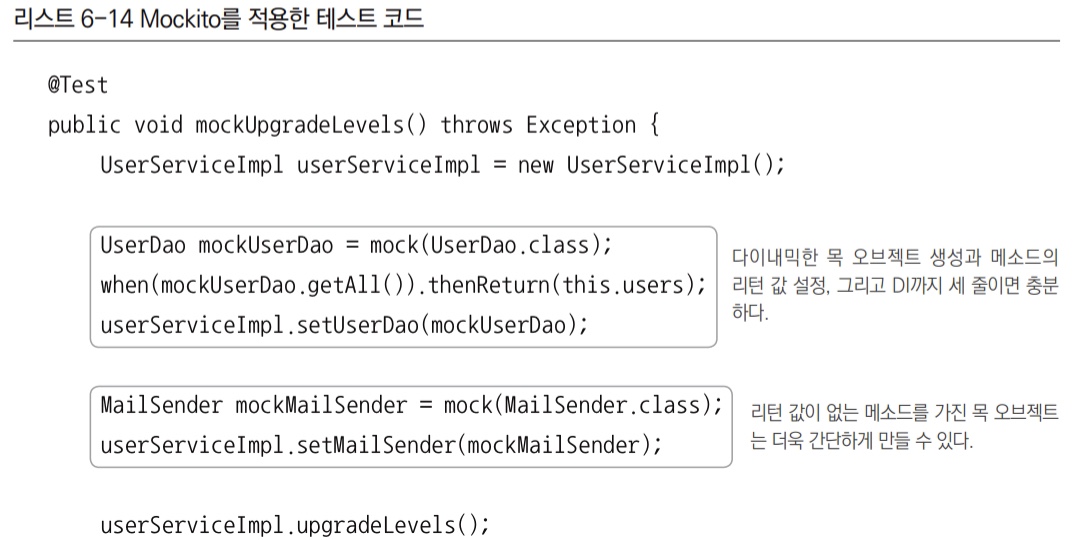
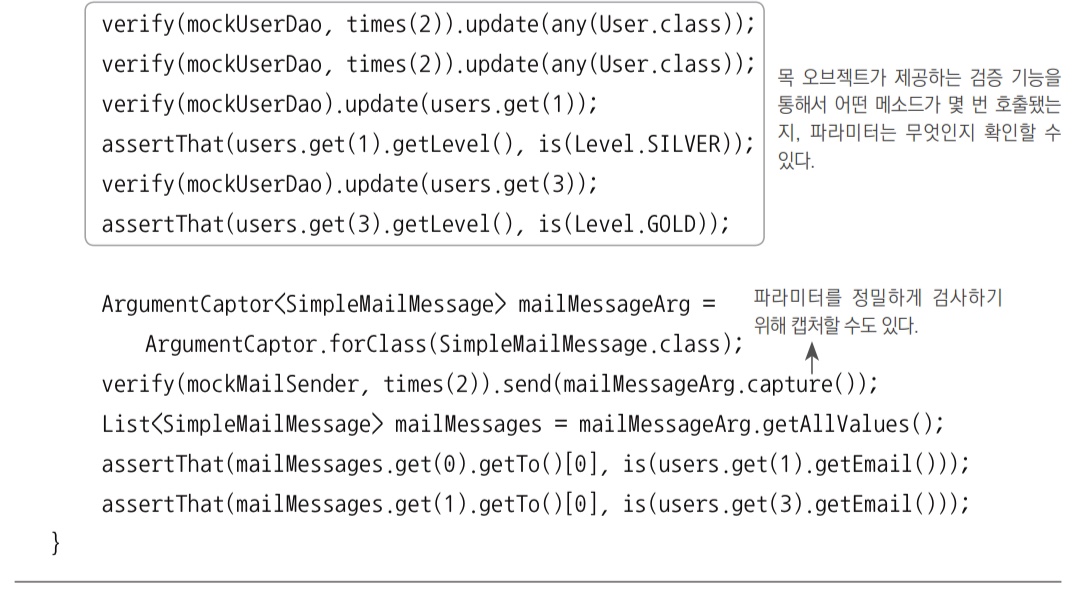
1. UserDao의 목 오브젝트를 생성하고 getAll()이 호출됐을 때의 리턴 값을 설정해준 뒤에 테스트 대상에 DI 해준다.
- 즉, Mockito를 이용해 간단히 목 오브젝트를 생성해서 DI 해주면 된다. 간단한 코드 몇 줄로 목 오브젝트의 준비가 끝난다.
- DI를 마친
userServiceImpl오브젝트는 이제 고립된 테스트가 가능해졌다.
userServiceImpl메서드가 실행되는 동안 DI 해준 목 오브젝트의 메서드가 호출되면 자동으로 호출 기록이 남겨진다.getAll()처럼 미리 설정해둔 리턴 값이 있는 경우에는 그 값을 그대로 리턴해주기도 한다.- 목 오브젝트의 메서드가 어떻게 호출됐는지를 검증해보자.
times()는 메서드 호출 횟수를 검증해준다.any()를 사용하면 파라미터의 내용은 무시하고 호출 횟수만 확인할 수 있다.verify()는 목 오브젝트가 호출됐을 때의 파라미터를 하나씩 점검한다.
- 각각 오브젝트는 확인했지만 레벨의 변화는 파라미터의 직접 비교로는 직접 확인이 되지 않는다. 따라서
getAll()을 통해 전달했던User목록의 내용을 가지고 레벨이 변경됐는지 직접 확인해야 한다. MailSender의 경우는ArgumentCaptor라는 것을 사용해서 실제MailSender목 오브젝트에 전달된 파라미터를 가져와 내용을 검증하는 방법을 사용했다. 파라미터를 직접 비교하기보다는 파라미터의 내부 정보를 확인해야 하는 경우에
Mockito는 지금까지 나온 목 오브젝트 방식을 지원하는 프레임워크 중에서 가장 사용하기 편리한 기능을 갖고 있다. 스프링을 사용한다면 단위 테스트를 만들어야 할 테고, 단위 테스트를 만든다면 목 오브젝트는 자주 필요하다. 따라서 Mockito와 같은 목 오브젝트 지원 프레임워크는 익숙하게 사용할 수 있도록 학습해두자 .
3. 다이내믹 프록시와 팩토리 빈
3.1 프록시와 프록시 패턴, 데코레이터 패턴
단순히 확장성을 고려해서 한 가지 기능을 분리한다면 전형적인 전략 패턴을 사용하면 된다. 트랜잭션 기능에는 추상화 작업을 통해 이미 전략 패턴이 적용되어 있다. 하지만 트랜잭션의 기능의 구체적인 구현 코드는 제거했을지라도 위임을 통해 기능을 사용하는 코드는 핵심 코드와 함께 남아 있다.

트랜잭션이라는 기능을 사용자 관리 비즈니스 로직과는 성격이 다르기 때문에 아예 그 적용 사실 자체를 밖으로 분리할 수 있다. 부가기능 전부를 핵심 코드가 담긴 클래스에서 독립시킬 수 있다. 이 방법을 이용해 UserServiceTx를 만들었고, UserServiceImpl에는 트랜잭션 관련 코드가 하나도 남지 않게 됐다.

이렇게 분리된 부가기능을 담은 클래스는 '부가기능 외의 나머지 모든 기능은 원래 핵심기능을 가진 클래스로 위임해줘야 한다'는 중요한 특징이 있다. 핵심기능은 부가기능을 가진 클래스의 존재 자체를 모른다. 따라서 부가기능이 핵심기능을 사용하는 구조가 되는 것이다.
문제는 이렇게 구성했더라도 클라이언트가 핵심기능을 가진 클래스를 직접 사용해버리면 부가기능이 적용될 기회가 없다는 점이다. 그래서 부가기능은 마치 자신이 핵심기능을 사용하도록 만들어야 한다. 그러기 위해서 클라이언트는 인터페이스를 통해서만 핵심기능을 사용하게 하고, 부가기능 자신도 같은 인터페이스를 구현한 뒤에 자신이 그 사이에 끼어들어야 한다. 그러면 클라이언트는 인터페이스만 보고 사용하기 때문에 자신은 핵심기능을 가진 클래스를 사용할 것이라고 기대하지만, 사실은 부가기능을 통해 핵심기능을 이용하게 되는 것이다.

프록시와 타깃
부가기능 코드에서는 핵심기능으로 요청을 위임해주는 과정에서 자신이 가진 부가적인 기능을 적용해줄 수 있다. 이렇게 마치 자신이 클라이언트가 사용하려고 하는 실제 대상인 것처럼 위장해서 클라이언트의 요청을 받아주는 것을 대리자, 대리인과 같은 역할을 한다고 해서 프록시라고 부른다. 그리고 프록시를 통해 최종적으로 요청을 위임받아 처리하는 실제 오브젝트를 타깃(target) 또는 실체(real object)라고 부른다.

- 클라이언트가 프록시를 통해 타깃을 사용하는 구조를 보여주고 있다.
프록시의 특징
- 타깃과 같은 인터페이스를 구현했다는 것과 프록시가 타깃을 제어할 수 있는 위치에 있다.
- 프록시는 사용목적에 따라 두 가지로 구분할 수 있다.
- 목적1 : 클라이언트가 타깃에 접근하는 방법을 제어하기 위해서
- 목적2 : 타깃에 부가적인 기능을 부여해주기 위해서
- 두 가지 모두 대리 오브젝트라는 개념의 프록시를 두고 사용한다는 점은 동일하지만, 목적에 따라서 디자인 패턴에서는 다른 패턴으로 구분한다.
3.1.1 데코레이터 패턴
데코레이터 패턴은 타깃에 부가적인 기능을 런타임 시 다이내믹하게 부여해주기 위해 프록시를 사용하는 패턴을 말한다. 다이내믹하게 기능을 부가한다는 의미는 컴파일 시점, 즉 코드상에서는 어떤 방법과 순서로 프록시와 타깃이 연결되어 사용되는지 정해져 있지 않다는 뜻이다.
데코레이터 패턴에서는 프록시가 꼭 한 개로 제한되지 않는다. 프록시가 직접 타깃을 사용하도록 고정시킬 필요도 없다. 이를 위해 데코레이터 패턴에서는 같은 인터페이스를 구현한 타겟과 여러 개의 프록시를 사용할 수 있다. 프록시가 여러 개인 만큼 순서를 정해서 단계적으로 위임하는 구조로 만들면 된다.
프록시로서 동작하는 각 데코레이터는 위임하는 대상에도 인터페이스로 접근하기 때문에 자신이 최종 타깃으로 위임하는지, 아니면 다음 단계의 데코레이터 프록시로 위임하는지 알지 못한다. 그래서 데코레이터의 다음 위임 대상은 인터페이스로 선언하고 생성자나 수정자 메서드를 통해 위임 대상을 외부에서 런타임 시에 주입받을 수 있도록 만들어야 한다.
UserService 인터페이스를 구현한 타깃인 UserServiceImpl에 트랜잭션 부가기능을 제공해주는 UserServiceTx를 추가한 것도 데코레이터 패턴을 적용한 것이라고 볼 수 있다. 이 경우는 수정자 메서드를 이용해 데코레이터인 UserServiceTx에 위임할 타깃인 UserServiceImpl을 주입해줬다.
인터페이스를 통한 데코레이터 정의와 런타임 시의 다이내믹한 구성 방법은 스프링의 DI를 이용하면 아주 편리하다. 데코레이터 빈의 프로퍼티로 같은 인터페이스를 구현한 다른 데코레이터 또는 타깃 빈을 설정하면 된다.
스프링 설정파일을 보면, UserServiceTx 클래스로 선언된 userService 빈은 데코레이터다. UserServiceTx는 UserService 타입의 오브젝트를 DI 받아서 기능은 위임하지만, 그 과정에서 트랜잭션 경계설정 기능을 부여해준다. 현재는 UserServiceImpl 클래스로 선언된 타깃 빈이 DI를 통해 데코레이터인 userService 빈에 주입되도록 설정되어 있다. 다이내믹한 부가기능의 부여라는 데코레이터 패턴의 전형적인 적용 예다.
데코레이터 패턴은 인터페이스를 통해 위임하는 방식이기 때문에 어느 데코레이터에서 타깃으로 연결될지 코드 레벨에선 미리 알 수 없다. UserServiceTx도 UserService라는 인터페이스를 통해 다음 오브젝트로 위임하도록 되어 있지 UserServiceImpl이라는 특정 클래스로 위임하도록 되어 있지 않다. 데코레이터 패턴은 타깃의 코드를 손대지 않고, 클라이언트가 호출하는 방법도 변경하지 않은 채로 새로운 기능을 추가할 때 유용한 방법이다.
3.1.2 프록시 패턴
디자인 패턴에서 말하는 프록시 패턴은 프록시를 사용하는 방법 중에서 타깃에 대한 접근 방법을 제어하려는 목적을 가진 경우를 가리킨다.
- 특징
- 프록시 패턴의 프록시는 타깃의 기능을 확장하거나 추가하지 않는다. 대신 클라이언트가 타깃에 접근하는 방식을 변경해준다.
- 타깃 오브젝트에 대한 레퍼런스가 미리 필요한 경우엔, 프록시 패턴을 적용하면 된다.
- 클라이언트에게 타깃에 대한 레퍼런스를 넘겨야 하는데, 실제 타깃 오브젝트를 만드는 대신 프록시를 넘겨주는 것이다. 타깃 오브젝트를 생성하기가 복잡하거나 당장 필요하지 않은 경우에는 꼭 필요한 시점까지 오브젝트를 생성하지 않는 편이 좋기 때문이다.
- 그리고 프록시의 메서드를 통해 타깃을 사용하려고 시도하면, 그때 프록시가 타깃 오브젝트를 생성하고 요청을 위임해주는 식이다.
- 프록시 패턴을 사용하기 좋은 경우
- 만약 레퍼런스는 갖고 있지만 끝까지 사용하지 않거나, 많은 작업이 진행된 후에 사용되는 경우
프록시를 통해 생성을 최대한 늦춤으로써 얻는 장점이 많다. - 원격 오브젝트를 이용하는 경우
RMI나 EJB, 또는 각종 리모팅 기술을 이용해 다른 서버에 존재하는 오브젝트를 사용해야 한다면, 원격 오브젝트에 대한 프록시를 만들어두고, 클라이언트는 마치 로컬에 존재하는 오브젝트를 쓰는 것처럼 프록시를 사용하게 할 수 있다. 프록시는 클라이언트의 요청을 받으면 네트워크를 통해 원격의 오브젝트를 실행하고 결과를 받아서 클라이언트에게 돌려준다. - 특별한 상황에서 타깃에 대한 접근권한을 제어하는 경우
수정 가능한 오브젝트가 있는데, 특정 레이어로 넘어가서는 읽기전용으로만 강제해야 한다고 하자. 이럴 때는 오브젝트의 프록시를 만들어서, 프록시의 특정 메서드를 사용하려고 하면 접근이 불가능하다고 예외를 발생시키면 된다.
- 만약 레퍼런스는 갖고 있지만 끝까지 사용하지 않거나, 많은 작업이 진행된 후에 사용되는 경우
프록시 패턴은 타깃의 기능 자체에는 관여하지 않으면서 접근하는 방법을 제어해주는 프록시를 이용하는 것이다. 구조적으로는 데코레이터와 유사하지만, 프록시는 코드에서 자신이 만들거나 접근할 타깃 클래스 정보를 알고 있는 경우가 많다. 생성을 지연하는 프록시라면 구체적인 생성 방법을 알아야 하기 때문에 타깃 클래스에 대한 직접적인 정보를 알아야 한다. 물론 인터페이스를 통해 위임하도록 만들 수도 있다. 인터페이스를 통해 다음 호출 대상으로 접근하면 그 사이에 다른 폭시나 데코레이터가 계속 추가될 수 있기 때문이다.
📌 책에서는 앞으로 타깃과 동일한 인터페이스를 구현하고 클라이언트와 타깃 사이에 존재하면서 기능의 부가 또는 접근 제어를 담당하는 오브젝트를 모두 프록시라고 부를 것이다.
3.2 다이내믹 프록시
자바에는
java.lang.reflect패키지 안에 프록시를 손쉽게 만들 수 있도록 지원해주는 클래스들이 있다. 매번 프록시 클래스를 정의하지 않고도 몇 가지 API를 이용해 프록시처럼 동작하는 오브젝트를 다이내믹하게 생성하는 것이다.
3.2.1 프록시의 구성과 프록시 작성의 문제점
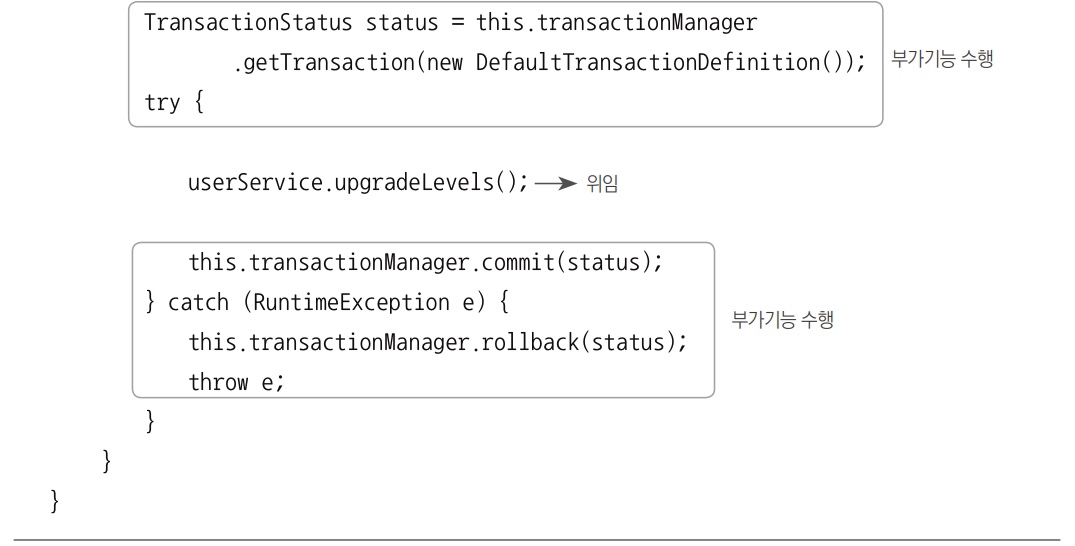
프록시는 두 가지 기능으로 구성된다.
- 위임 : 타깃과 같은 메서드를 구현하고 있다가 메서드가 호출되면 타깃 오브젝트로 위임한다.
- 부가작업 : 지정된 요청에 대해서는 부가기능을 수행한다.
UserTx 코드에서 이 두 가지 기능을 구분해보자.

UserServiceTx 코드는 UserService 인터페이스를 구현하고 타깃으로 요청을 위임하는 트랜잭션 부가기능을 수행하는 코드로 구분할 수 있다.
프록시를 만들기 번거로운 이유
- 코드 작성의 번거로움 : 타깃의 인터페이스를 구현하고 위임하는 코드를 작성하기 번거롭다. 부가기능이 필요 없는 메서드도 구현해서 타깃으로 위임하는 코드를 일일이 만들어줘야 한다.
- 이 문제에 유용한 것이 바로 JDK의 다이내믹 프록시다.
- 코드의 중복 : 부가기능 코드가 중복될 가능성이 많다. 트랜잭션 외에도 프록시를 활용할 만한 부가기능, 접근제어 기능을 일반적인 성격을 띤 것들이 많다. 따라서 다양한 타깃 클래스와 메서드에 중복돼서 나타날 가능성이 높다.
- 중복 코드를 분리해서 어떻게든 해결해보면 될 것이다.
3.2.2 리플렉션
리플렉션은 자바의 코드 자체를 추상화해서 접근하도록 만든 것이다. 다이내믹 프록시는 리플렉션 기능을 이용해서 프록시를 만들어준다.
예
String name = "Spring";이 스트링의 길이는 String 클래스의 length() 메서드를 호출해서 알 수 있다. 일반적인 사용 방법은 .length() 같이 직접 메서드를 호출하는 코드로 만드는 것이다.
📌 자바의 클래스
자바의 모든 클래스는 그 클래스 자체의 구성정보를 담은Class타입의 오브젝트를 하나씩 갖고 있다.클래스이름.class라고 하거나 오브젝트의getClass()메서드를 호출하면 클래스 정보를 담은Class타입의 오브젝트를 가져올 수 있다. 클래스 오브젝트를 이용하면 클래스 코드에 대한 메타정보를 가져오거나 오브젝트를 조작할 수 있다.
리플렉션 API 중에서 메서드에 대한 정의를 담은 Method라는 인터페이스를 이용해 메서드를 호출할 수 있다. String 클래스의 정보를 담은 Class 타입의 정보는 String.class 또는 스트링 오브젝트가 있으면 name.getClass()로 가져올 수 있다. 그리고 이 클래스 정보에서 특정 이름을 가진 메서드 정보를 가져올 수 있다.
String의 length() 메서드는 다음과 같이 하면 된다.
Method lengMethod = String.class.getMethod("length");스트링이 가진 메서드 중에서 "length"라는 이름을 갖고 있고, 파라미터는 없는 메서드의 정보를 가져오는 것이다. java.lang.reflect.Method 인터페이스는 메서드에 대한 정보뿐 아니라, 이를 이용해 특정 오브젝트의 메서드를 실행시킬 수도 있다. Method 인터페이스에 정의된 invoke() 메서드를 사용하면 된다. invoke() 메서드는 메서드를 실행시킬 대상 오브젝트(obj)와 파라미터 목록(args)을 받아서 메서드를 호출한 뒤에 그 결과를 Object 타입으로 돌려준다.
public Object invoke(Object obj, Object... args)이를 이용해 length() 메서드를 다음과 같이 실행할 수 있다.
int length = lengthMethod.invoke(name); // int length = name.length();3.2.3 프록시 클래스
다이내믹 프록시를 이용한 프록시를 만들어보자.
- 프록시를 적용할 간단한 타깃 클래스와 인터페이스를 정의한다.


Hello인터페이스를 통해HelloTarget오브젝트를 사용하는 클라이언트 역할을 하는 간단한 테스트를 만든다.


Hello인터페이스를 구현한 프록시를 만든다.HelloUppercase프록시에는 데코레이터 패턴을 적용해서 타깃인HelloTarget에 부가기능을 추가하겠다.
- 프록시는 Hello 인터페이스를 구현하고,
Hello타입의 타깃 오브젝트를 맏아서 저장해둔다. Hello인터페이스 구현 메서드에서는 타깃 오브젝트의 메서드를 호출한 뒤에 결과를 대문자로 바꿔주는 부가기능을 적용하고 리턴한다.- 위임과 기능 부가라는 두 가지 프록시의 기능을 모두 처리하는 전형적인 프록시 클래스다.

HelloUppercase프록시 테스트를 만든다.

이 프록시는 프록시 적용의 일반적인 문제점 두 가지를 모두 갖고 있다. 인터페이스의 모든 메서드를 구현해 위임하도록 코드를 만들어야 하며, 부가기능이 모든 메서드에 중복돼서 나타난다.
3.2.4 다이내믹 프록시 적용
클래스로 만든 프록시인 HelloUppercase를 다이내믹 프록시를 이용해 만들어보자.
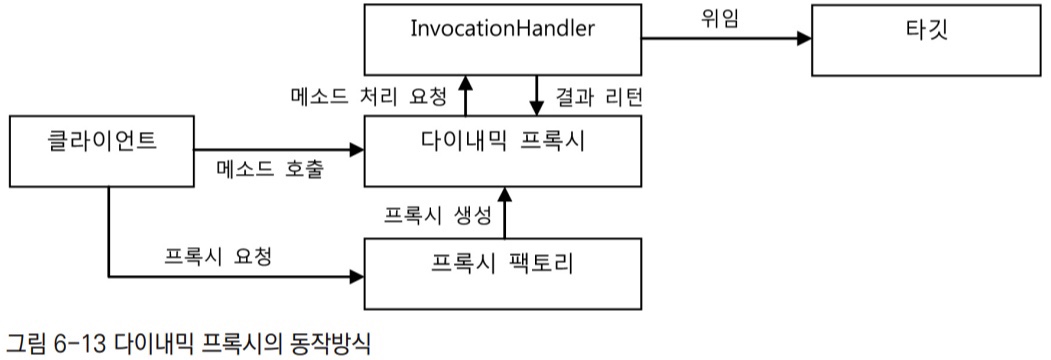
다이내믹 프록시는 프록시 팩토리에 의해 런타임 시 다이내믹하게 만들어지는 오브젝트다. 다이내믹 프록시 오브젝트는 타깃의 인터페이스와 같은 타입으로 만들어진다. 클라이언트는 다이내믹 프록시 오브젝트를 타깃 인터페이스를 통해 사용할 수 있다. 프록시 팩토리에게 인터페이스 정보만 제공해주면 해당 인터페이스를 구현한 클래스의 오브젝트를 자동으로 만들어준다.
다이내믹 프록시가 인터페이스 구현 클래스의 오브젝트는 만들어주지만, 프록시로서 필요한 부가기능 제공 코드는 직접 작성해야 한다. 부가기능은 프록시 오브젝트와 독립적으로 InvocationHandler를 구현한 오브젝트에 담는다. InvocationHandler 인터페이스는 invoke() 메서드 한 개만 가진 간단한 인터페이스다.
public Object invoke(Object proxy, Method method, Object[] args)invoke() 메서드는 리플렉션의 Method 인터페이스를 파라미터로 받는다. 메서드를 호출할 때 전달되는 파라미터도 args로 받는다. 다이내믹 프록시 오브젝트는 클라이언트의 모든 요청을 리플렉션 정보로 변환해서 InvocationHandler 구현 오브젝트의 invoke() 메서드로 넘기는 것이다. 타깃 인터페이스의 모든 메서드 요청이 하나의 메서드로 집중되기 때문에 중복되는 기능을 효과적으로 제공할 수 있다.
리플렉션으로 메서드와 파라미터 정보를 모두 갖고 있으므로 타깃 오브젝트의 메서드를 호출하게 할 수도 있다. InvocationHandler 구현 오브젝트가 타깃 오브젝트 레퍼런스를 갖고 있다면 리플렉션을 이용해 간단히 위임 코드를 만들어낼 수 있다.
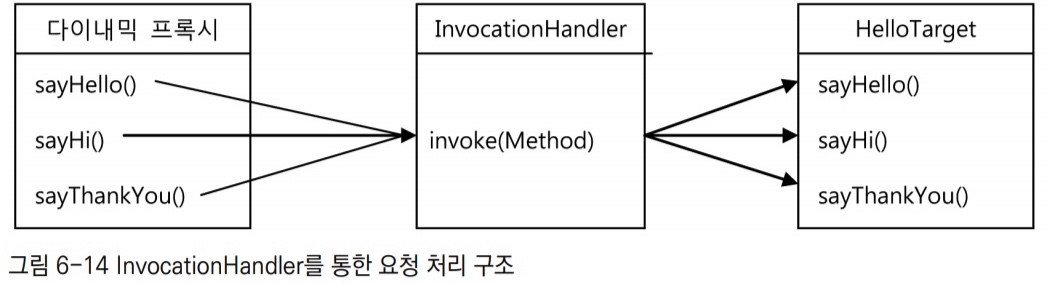
다이내믹 프록시 오브젝트와 InvocationHandler 오브젝트, 타깃 오브젝트 사이의 메서드 호출 과정
예
- 먼저 다이내믹 프록시로부터 메서드 호출 정보를 받아서 처리하는
InvocationHandler를 만든다.

- 모든 요청을 타깃에 위임하면서 리턴 값을 대문자로 바꿔주는 부가기능을 가진
InvocationHandler구현 클래스다. - 다이내믹 프록시로부터 요청을 전달받으려면
InvocationHandler를 구현해야 한다. - 다이내믹 프록시가 클라이언트로부터 받는 모든 요청은
invoke()메서드로 전달된다. - 다이내믹 프록시를 통해 요청이 전달되면 리플렉션 API를 이용해 타깃 오브젝트의 메서드를 호출한다.
- 타깃 오브젝트의 메서드 호출이 끝났으면 프록시가 제공하려는 부가기능을 수행하고 결과를 리턴한다.
- 리턴된 값은 다이내믹 프록시가 받아서 최종적으로 클라이언트에게 전달될 것이다.
- 이
InvocationHandler를 사용하고Hello인터페이스를 구현하는 프록시를 만든다.

- 다이내믹 프록시의 생성은
Proxy클래스의newProxyInstance()스태틱 팩토리 메서드를 이용하면 된다. - 첫 번째 파라미터는 클래스 로더를 제공해야 한다.
다이내믹 프록시가 정의되는 클래스 로더를 지정하는 것이다. - 두 번째 파라미터는 다이내믹 프록시가 구현해야 할 인터페이스다.
다이내믹 프록시는 한 번에 하나 이상의 인터페이스를 구현할 수도 있기 때문에 인터페이스의 배열을 사용한다. - 마지막 파라미터는 부가기능과 위임 관련 코드를 담고 있는
InvocationHandler구현 오브젝트를 제공해야 한다.
- 이제
UppercaseHandler를 사용하는Hello인터페이스를 구현한 다이내믹 프록시가 만들어졌으니Hello인터페이스를 통해서 사용하면 된다.
newProxyInstance()에 의해 만들어지는 다이내믹 프록시 오브젝트는Hello인터페이스를 구현한 클래스의 오브젝트이기 때문에Hello타입으로 캐스팅이 가능하다.
3.2.5 다이내믹 프록시의 확장
- 다이내믹 프록시 방식은 구현한 인터페이스의 메서드의 개수가 늘어나도 전혀 손댈 게 없다. 다이내믹 프록시가 만들어질 때 추가된 메서드가 자동으로 포함될 것이고, 부가기능은
invoke()메서드에서 처리되기 때문이다. InvocationHandler방식은 타깃의 종류에 상관없이 적용이 가능하다.
어차피 리플렉션의Method인터페이스를 이용해 타깃의 메서드를 호출하는 것이기 때문이다. 어떤 종류의 인터페이스를 구현한 타깃이든 상관없이 재사용할 수 있다.
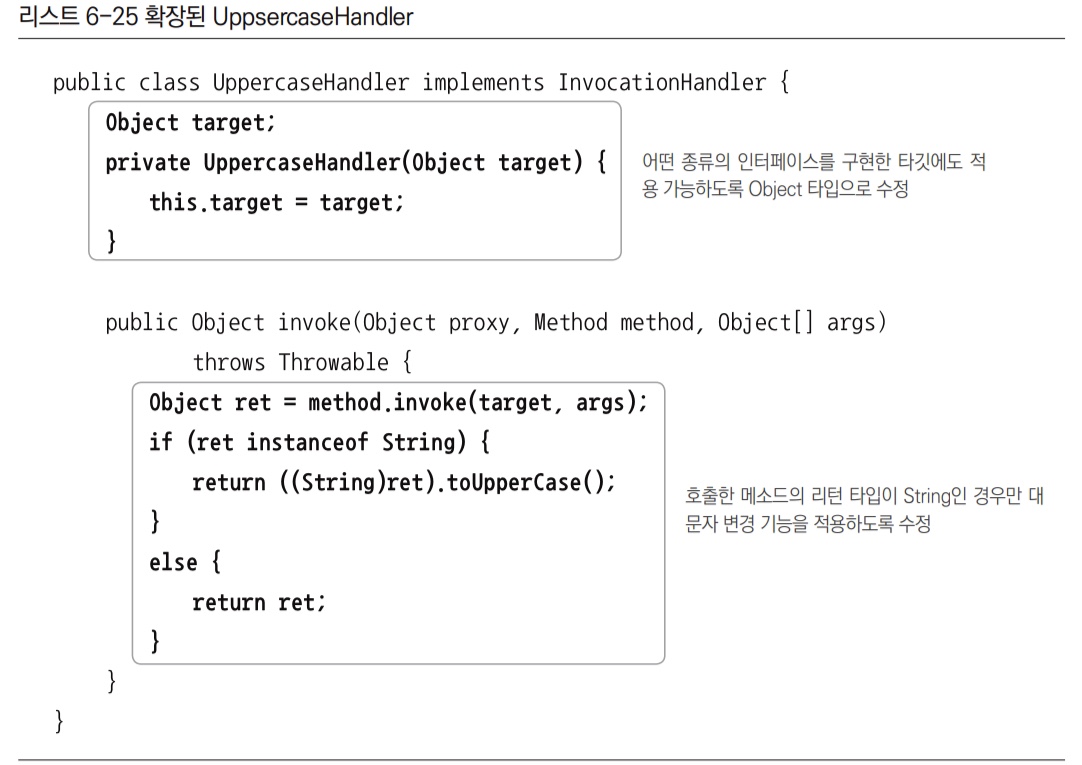
메서드를 선별해서 부가기능을 적용하는 InvocationHandler
InvocationHandler는 단일 메서드에서 모든 요청을 처리하기 때문에 어떤 메서드에 어떤 기능을 적용할지를 선택하는 과정이 필요할 수도 있다. 호출하는 메서드의 이름, 파라미터의 개수와 타입, 리턴 타입 등의 정보를 가지고 부가적인 기능을 적용할 메서드를 선택할 수 있다.

3.3 다이내믹 프록시를 이용한 트랜잭션 부가기능
UserServiceTx를 다이내믹 프록시 방식으로 변경해보자.
트랜잭션이 필요한 클래스와 메서드가 증가하면 UserServiceTx처럼 프록시 클래스를 일일이 구현하는 것은 큰 부담이다. 따라서 트랜잭션 부가기능을 제공하는 다이내믹 프록시를 만들어 적용하는 방법이 효율적이다.
3.3.1 트랜잭션 InvocationHandler
트랜잭션 부가기능을 가진 핸들러를 만든다.


setTarget()- 요청을 위임할 타깃을 DI로 제공받도록 한다.
- 타깃을 저장할 변수는
Object로 선언했다. 따라서UserServiceImpl외에 트랜잭션 적용이 필요한 어떤 타깃 오브젝트에도 적용할 수 있다.
setTransactionManager()UserServiceTx와 마찬가지로 트랜잭션 추상화 인터페이스인PlatformTransactionManager를 DI 받도록 한다.
setPattern()- 타깃 오브젝트의 모든 메서드에 무조건 트랜잭션이 적용되지 않도록 트랜잭션을 적용할 메서드 이름의 패턴을 DI 받는다.
- 간단히 메서드 이름의 시작 부분을 비교할 수 있게 만들었다.
invoke()- 타깃 오브젝트의 모든 메서드가 아닌 선별적으로 적용할 것이므로 적용할 대상을 선별하는 작업을 먼저 진행한다.
- DI 받은 이름 패턴으로 시작되는 이름을 가진 메서드인지 확인한다.
- 패턴과 일치하는 이름을 가진 메서드라면 트랜잭션을 적용하는 메서드를 호출하고, 아니라면 부가기능 없이 타깃 오브젝트의 메서드를 호출해서 결과를 리턴하게 한다.
UserServiceTx와 InvocationHandler의 차이점
트랜잭션을 적용하면서 타깃 오브젝트의 메서드를 호출하는 것은 UserServiceTx에서와 동일하지만, 롤백을 적용하기 위한 예외는 RuntimeException 대신에 InvocationTargetException을 잡도록 해야 한다는 점은 다르다.
리플렉션 메서드인 Method.invoke()를 이용해 타깃 오브젝트의 메서드를 호출할 때는 타깃 오브젝트에서 발생하는 예외가 InvocationTargetException으로 한 번 포장돼서 전달된다. 따라서 일단 InvocationTargetException으로 받은 후 getTargetException() 메서드로 중첩되어 있는 예외를 가져와야 한다.
3.3.2 TransactionHandler와 다이내믹 프록시를 이용하는 테스트
upgradeAllOrNothing()은 UserServiceTx를 프록시로 사용했을 때 트랜잭션 기능이 동작하는지 확인하는 테스트였기 때문에 TransactionHandler를 이용하는 다이내믹 프록시를 사용하도록 수정한다.

UserServiceTx 오브젝트 대신 TransactionHandler를 만들고 타깃 오브젝트와 트랜잭션 매니저, 메서드 패턴을 주입해준다. 이렇게 준비된 TransactionHandler 오브젝트를 이용해 UserService 타입의 다이내믹 프록시를 생성한다.
3.4 다이내믹 프록시를 위한 팩토리 빈
이제 TransactionHandler와 다이내믹 프록시를 스프링의 DI를 통해 사용할 수 있도록 하자. 하지만 DI의 대상이 되는 다이내믹 프록시 오브젝트는 일반적인 스프링의 빈으로는 등록할 방법이 없다. 스프링의 빈은 기본적으로 클래스 이름과 프로퍼티로 정의된다. 스프링은 지정된 클래스 이름을 가지고 리플렉션을 이용해서 해당 클래스의 오브젝트를 만든다. 클래스의 이름을 갖고 있다면 다음과 같이 새로운 오브젝트를 생성할 수 있다. Class의 newInstance() 메서드는 해당 클래스의 파라미터가 없는 생성자를 호출하고, 그 결과 생성되는 오브젝트를 돌려주는 리플렉션 API다.
Date now = (Date) Class.forName("java.util.Date").newInstance();스프링은 내부적으로 리플렉션 API를 이용해서 빈 정의에 나오는 클래스 이름을 가지고 빈 오브젝트를 생성한다. 문제는 다이내믹 프록시 오브젝트는 이런 식으로 프록시 오브젝트가 생성되지 않는다. 클래스 자체도 내부적으로 다이내믹하게 새로 정의해서 사용하기 때문에 사실 다이내믹 프록시 오브젝트의 클래스가 어떤 것인지 알 수도 없다. 따라서 사전에 프록시 오브젝트의 클래스 정보를 미리 알아내서 스프링의 빈에 정의할 방법이 없다. 다이내믹 프록시 Proxy 클래스의 newProxyInstance()라는 스태틱 팩토리 메서드를 통해서만 만들 수 있다.
3.4.1 팩토리 빈
스프링은 클래스 정보를 가지고 디폴트 생성자를 통해 오브젝트를 만드는 방법 외에도 빈을 만들 수 있는 여러 가지 방법을 제공한다. 대표적으로 팩토리 빈을 이용한 빈 생성 방법을 들 수 있다. 팩토리 빈이란 스프링을 대신해서 오브젝트의 생성로직을 담당하도록 만들어진 특별한 빈을 말한다.
팩토리 빈을 만드는 방법 중 가장 간단한 방법은 스프링의 FactoryBean이라는 인터페이스를 구현하는 것이다. FactoryBean 인터페이스는 세 가지 메서드로 구성되어 있다.

FactoryBean 인터페이스를 구현한 클래스를 스프링의 빈으로 등록하면 팩토리 빈으로 동작한다.
팩토리 빈의 동작원리에 대한 학습 테스트

- 먼저 스프링에서 빈 오브젝트로 만들어 사용하고 싶은 클래스를 하나 정의해보자.
Message클래스는 생성자를 통해 오브젝트를 만들 수 없고, 반드시newMessage()라는 스태틱 메서드를 사용해야 한다. 따라서 이 클래스를 직접 스프링 빈으로 등록해서 사용할 수 없다.
📌
private생성자와 리플렉션
사실 스프링은private생성자를 가진 클래스도 빈으로 등록해주면 리플렉션을 이용해 오브젝트를 만들어준다. 리플렉션은private으로 선언된 접근 규약을 위반할 수 있는 강력한 기능이 있기 때문이다. 하지만 생성자를private으로 만들었다는 것은 스태틱 메서드를 통해 오브젝트가 만들어져야 하는 중요한 이유가 있기 때문이므로 이를 무시하고 오브젝트를 강제로 생성하면 위험하다. 일반적으로private생성자를 가진 클래스를 빈으로 등록하는 일은 권장되지 않으며, 등록하더라도 빈 오브젝트가 바르게 동작하지 않을 가능성이 있으니 주의해야 한다.
Message클래스의 오브젝트를 생성해주는 팩토리 빈 클래스를 만들어보자.
FactoryBean인터페이스를 구현해서 만들면 된다.
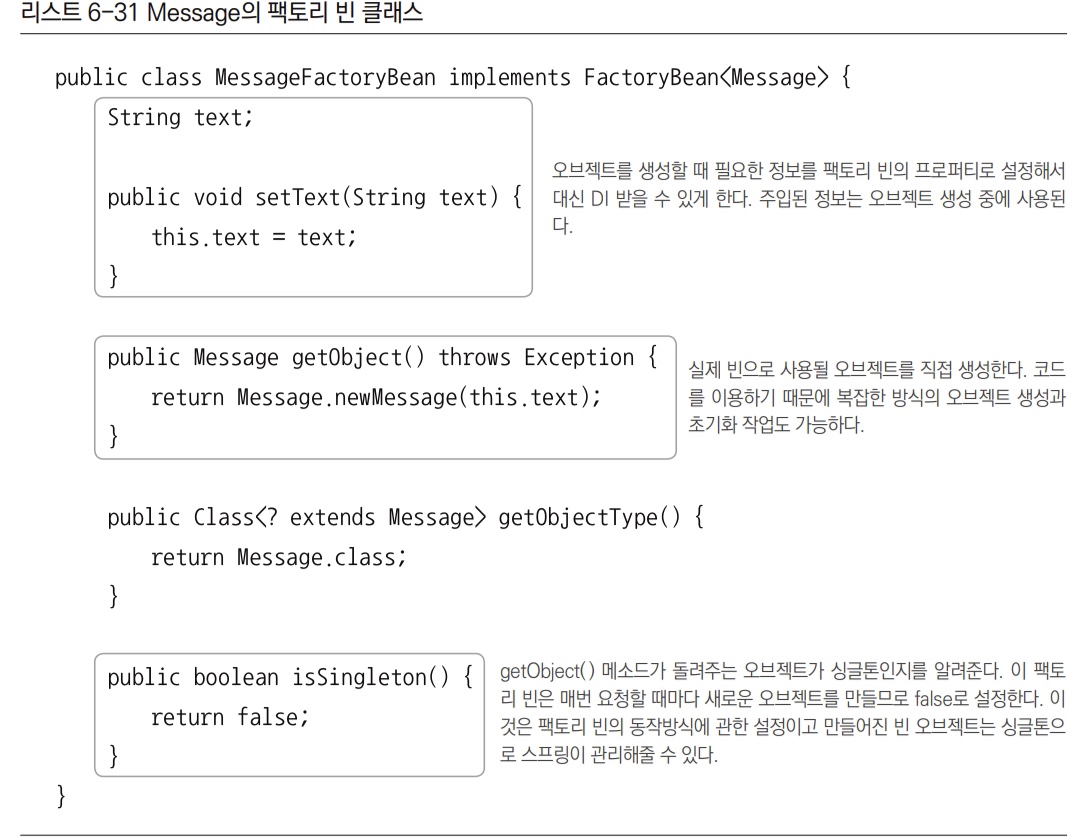
팩토리 빈은 전형적인 팩토리 메서드를 가진 오브젝트다. 스프링은 FactoryBean 인터페이스를 구현한 클래스가 빈의 클래스로 지정되면, 팩토리 빈 클래스의 오브젝트의 getObject() 메서드를 이용해 오브젝트를 가져오고, 이를 빈 오브젝트로 사용한다. 빈의 클래스로 등록된 팩토리 빈은 빈 오브젝트를 생성하는 과정에서만 사용될 뿐이다.
3.4.2 팩토리 빈의 설정 방법

팩토리 빈과 일반 빈
팩토리 빈도 id와 class 애트리뷰트를 사용해 빈의 아이디와 클래스를 지정한다는 면에서는 차이가 없다.
하지만 Message 빈의 타입은 MessageFactoryBean의 getObjectType() 메서드가 돌려주는 타입으로 결정된다. 즉, message 빈 오브젝트의 타입이 class 애트리뷰트에 정의된 MessageFactoryBean이 아니라 Message 타입이다. 또, getObject() 메서드가 생성해주는 오브젝트가 message 빈의 오브젝트가 된다.
팩토리 빈 테스트
- 위의 설정파일 :
FactoryBeanTest-context.xml
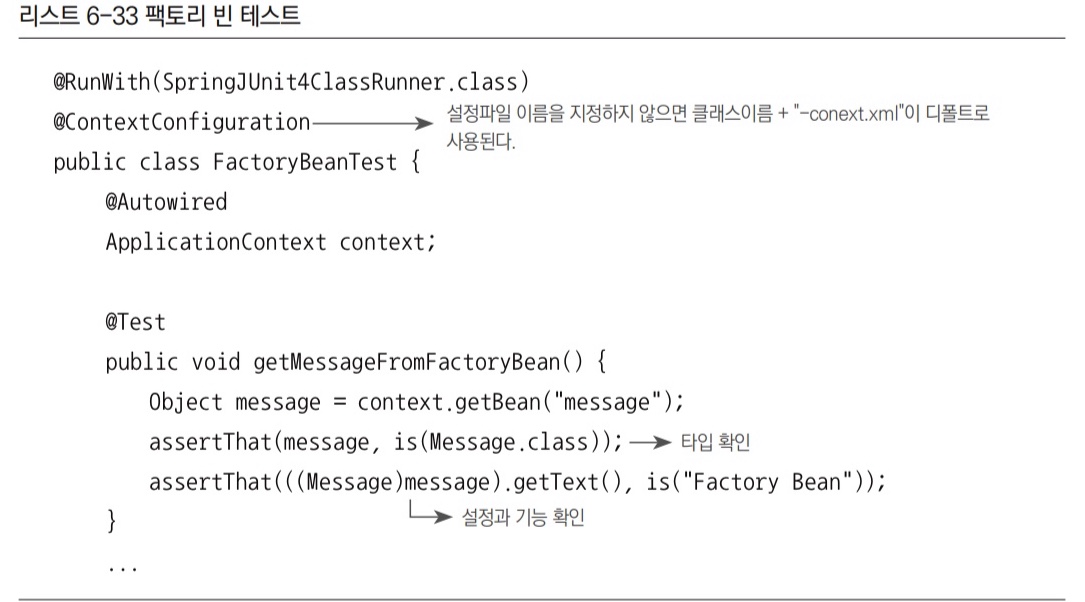
- 학습 테스트를 작성하는 시점엔 message 빈의 타입이 무엇인지 확실치 않으므로 @Autowired의 타입 자동와이어링으로 `message 빈을 가져오는 대신 ApplicationContext를 이용해 getBean() 메서드를 사용한다.
getBean()메서드는 빈의 타입을 지정하지 않으면Object타입으로 리턴한다.
- 빈의 타입을 확인해보자.
message빈 설정의class애트리뷰트는MessageFactoryBean이다.- 하지만
getBean()이 리턴한 오브젝트는Message타입이어야 한다.
- 기능을 확인해보자.
MessageFactoryBean을 통해text프로퍼티의 값이 바르게 주입됐는지 점검한다.
이로써 FactoryBean 인터페이스를 구현한 클래스를 스프링 빈으로 만들어두면 getObject()라는 메서드가 생성해주는 오브젝트가 실제 빈의 오브젝트로 대치된다는 사실을 알 수 있다.
📌 팩토리 빈 가져오기
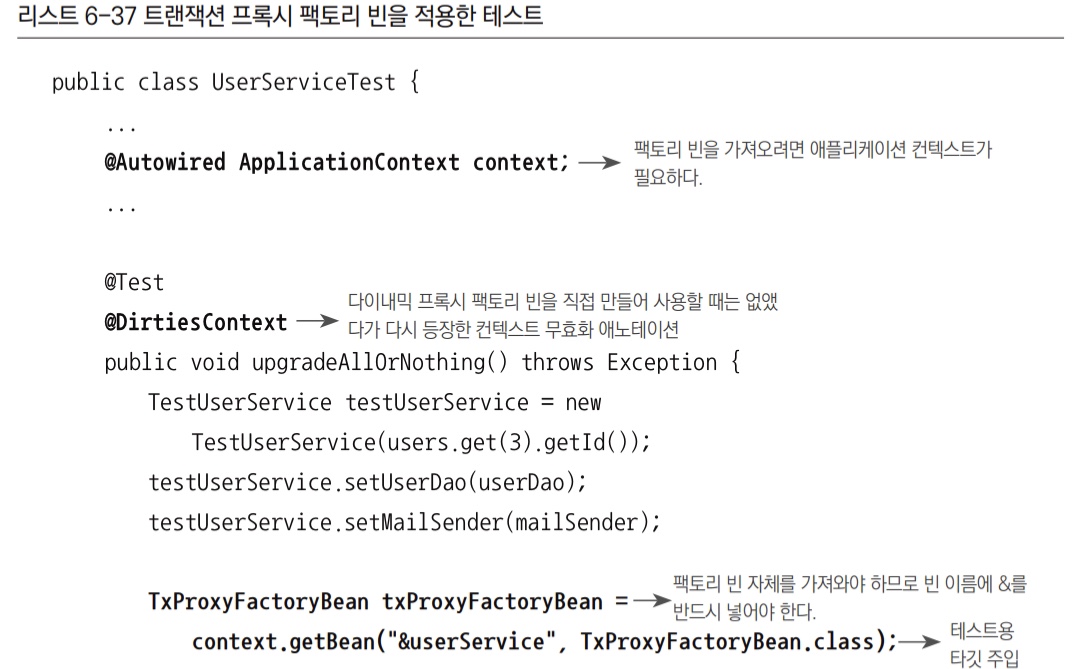
팩토리 빈이 만들어주는 빈 오브젝트가 아닌 팩토리 빈 자체를 가져오고 싶을 땐 빈 이름 앞에 '&'를 붙여주면 된다.

3.4.3 다이내믹 프록시를 만들어주는 팩토리 빈
Proxy의 newProxyInstance() 메서드를 통해서만 생성이 가능한 다이내믹 프록시 오브젝트는 팩토리 빈을 사용하면 스프링의 빈으로 만들어줄 수 있다. 팩토리 빈의 getObject() 메서드에 다이내믹 프록시 오브젝트를 만들어주는 코드를 넣으면 된다.
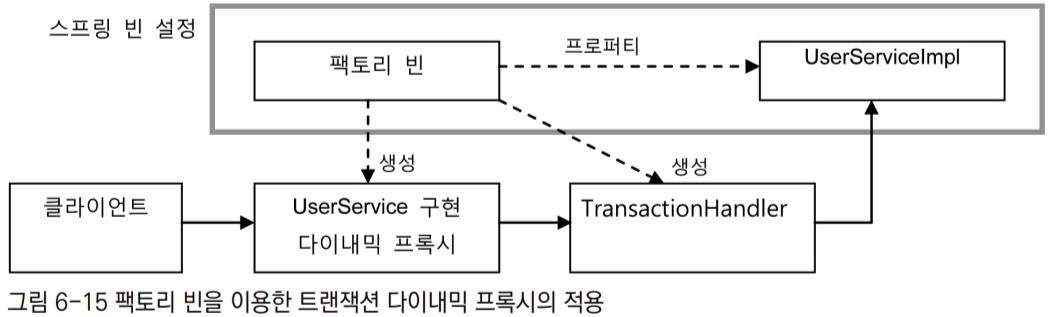
- 스프링 빈에는 팩토리 빈과
UserServiceImpl만 빈으로 등록한다. - 팩토리 빈은 다이내믹 프록시가 위임할 타깃 오브젝트인
UserServiceImpl에 대한 레퍼런스를 프로퍼티를 통해 DI를 받아둔다.- 다이내믹 프록시와 함께 생성할
TransactionHandler에게 타깃 오브젝트를 전달해줘야 한다.
- 다이내믹 프록시와 함께 생성할
- 다이내믹 프록시나
TransactionHandler를 만들 때 필요한 정보는 팩토리 빈의 프로퍼티로 설정해뒀다가 다이내믹 프록시를 만들면서 전달해줘야 한다.
3.4.4 트랜잭션 프록시 팩토리 빈


- 팩토리 빈이 만드는 다이내믹 프록시는 구현 인터페이스나, 타깃의 종류에 제한이 없다.
따라서 트랜잭션 부가기능이 필요한 오브젝트를 위한 프록시를 만들 때 언제나 재사용이 가능하다. 설정이 다른 여러 개의TxProxyFactoryBean빈을 등록하면 된다.

- 트랜잭션 부가기능이 필요한 빈이 추가될 때마다 이와 같은 빈 설정만 추가해주면 된다.
serviceInterface는Class타입이다.Class타입은value를 이용해 클래스 또는 인터페이스의 이름을 넣어주면 된다.- 스프링은 수정자 메서드의 파라미터의 타입을 확인해서 프로퍼티의 타입이
Class인 경우는value로 설정한 이름을 가진Class오브젝트로 자동 변환해준다.
3.4.5 트랜잭션 프록시 팩토리 빈 테스트
UserServiceTest의 메서드
add()
@Autowired로 가져온userService빈을 사용하기 때문에TxProxyFactoryBean팩토리 빈이 생성하는 다이내믹 프록시를 통해UserService기능을 사용하게 된다.- 트랜잭션이 적용되지 않는 메서드이므로 다이내믹 프록시를 거쳐도 단순 위임 방식으로만 동작한다.
upgradeLevels(),mockUpgradeLevels()
- 목 오브젝트를 이용해 비즈니스 로직에 대한 단위 테스트로 만들었으니 트랜잭션과는 무관하다.
upgradeAllOrNothing()
- 현재
- 수동 DI를 통해 직접 다이내믹 프록시를 만들어 사용하여 팩토리 빈이 적용되지 않는다.
- 예외 발생 시 트랜잭션이 롤백됨을 확인하려면 테스트 메서드에서 비즈니스 로직 코드를 수정한
TestUserService오브젝트를 타깃 오브젝트로 대신 사용해야 한다.
- 문제
TransactionHandler와 다이내믹 프록시 오브젝트를 직접 만들어서 테스트했을 때는 타깃 오브젝트를 바꾸기가 쉬웠는데, 이제는 스프링 빈에서 생성되는 프록시 오브젝트에 대해 테스트를 해야 한다.TransactionHandler는TxProxyFactoryBean내부에서 만들어져 다이내믹 프록시 생성에 사용될 뿐 별도로 참조할 방법이 없다. 따라서 이미 스프링 빈으로 만들어진 트랜잭션 프록시 오브젝트의 타깃을 변경하긴 어렵다.
- 해결
TxProxyFactoryBean의 트랜잭션을 지원하는 프록시를 바르게 만들어주는지를 확인하는 게 목적이므로 빈으로 등록된TxProxyFactoryBean을 직접 가져와서 프록시를 만든다.- 스프링 빈으로 등록된
TxProxyFactoryBean을 가져와서target프로퍼티를 재구성해준 뒤에 다시 프록시 오브젝트를 생성하도록 요청한다. - 컨텍스트의 설정을 변경하기는 하지만 어차피 트랜잭션 기능에 대한 학습 테스트로 특별히 만든 것이므로
@DirtiesContext를 등록하고 넘어가자.
3.5 프록시 팩토리 빈 방식의 장점과 한계
3.5.1 프록시 팩토리 빈의 재사용
TransactionHandler를 이용하는 다이내믹 프록시를 생성해주는 TxProxyFactoryBean은 코드의 수정 없이도 다양한 클래스에 적용할 수 있다. 타깃 오브젝트에 맞는 프로퍼티 정보를 설정해서 빈으로 등록해주기만 하면 된다. 하나 이상의 TxProxyFactoryBean을 동시에 빈으로 등록해도 상관없다. 팩토리 빈이기 때문에 각 빈의 타입은 타깃 인터페이스와 일치한다.
설정을 변경하기 전과 후의 오브젝트 관계
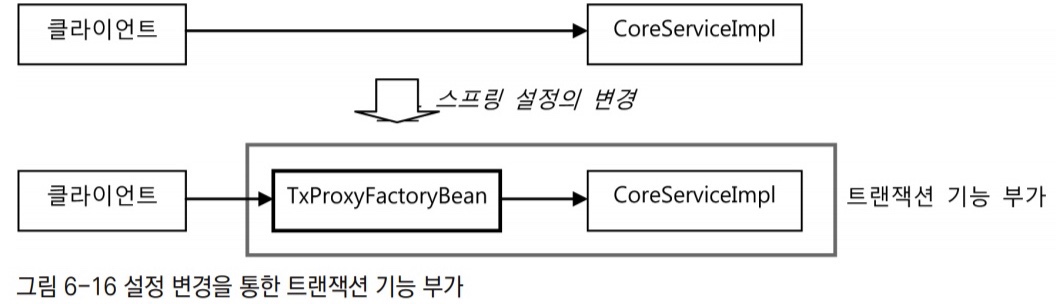
- 처음엔 트랜잭션이 적용되지 않은, 비즈니스 로직만 가진
CoreServiceImpl클래스의 빈만 존재한다. - 프록시 팩토리 빈의 설정을 추가한 후엔
CoreServiceImpl의 모든 메서드에 트랜잭션 기능이 적용됐다.
3.5.2 프록시 팩토리 빈 방식의 장점
앞에서 데코레이터 패턴이 적용된 프록시를 사용하는 데에 두 가지 문제점(코드 작성의 번거로움, 코드 중복)이 있다고 했다. 프록시 팩토리 빈은 이 두 가지 문제를 해결해준다.
1. 코드 작성의 번거로움
다이내믹 프록시를 이용하면 타깃 인터페이스를 구현하는 클래스를 일일이 만드는 번거로움이 없어진다.
2. 코드 중복
하나의 핸들러 메서드를 구현하는 것만으로도 수많은 메서드에 부가기능을 부여해줄 수 있으니 부가기능 코드의 중복 문제도 사라진다. 다이내믹 프록시에 팩토리 빈을 이용한 DI까지 더해주면 번거로운 다이내믹 프록시 생성 코드도 제거할 수 있다. DI 설정만으로 다양한 타깃 오브젝트에 적용도 가능하다.
3.5.3 프록시 팩토리 빈의 한계
-
한 번에 여러 개의 클래스에 공통적인 부가기능 제공하는 것
프록시를 통해 타깃에 부가기능을 제공하는 것은 메서드 단위로 일어나는 일이다. 하나의 클래스 안에 존재하는 여러 개의 메서드에 부가기능을 한 번에 제공하는 건 가능했다. 하지만 하나의 타깃 오브젝트에만 부여되는 부가기능이 아니라, 많은 클래스의 메서드에 적용할 필요가 있다면 비슷한 프록시 팩토리 빈의 설정이 중복되는 것은 불가피하다. -
하나의 타깃에 여러 개의 부가기능을 적용하는 것
하나의 타깃에 여러 개의 부가기능을 적용하려고 할 때, 적용 대상인 서비스 클래스가 몇백 개 된다면 프록시 팩토리 빈 설정이 부가기능의 개수만큼 따라 붙어야 한다. -
TransactionHandler오브젝트가 프록시 팩토리 빈 개수만큼 만들어지는 것
TransactionHandler는 타깃 오브젝트를 프로퍼티로 갖고 있다. 따라서 타깃 오브젝트만 달라져도 새로운TransactionHandler오브젝트를 만들어야 한다.TransactionHandler는 다이내믹 프록시처럼 굳이 팩토리 빈에서 만들지 않아도 되고, 스스로 빈으로 등록될 수도 있다. 그래서 타깃 오브젝트가 다르면 타깃 오브젝트 개수만큼 다른 빈으로 등록해야 하고 그만큼 많은 오브젝트가 생겨날 것이다. 타깃 오브젝트 외의 설정이 필요하다면 같은 설정이 중복돼서 많은 빈에 나타날 수 있다.
4. 스프링의 프록시 팩토리 빈
4.1 ProxyFactoryBean
스프링은 서비스 추상화를 프록시 기술에도 적용하여, 일관된 방법으로 프록시를 만들 수 있게 도와주는 추상 레이어를 제공한다. 생성된 프록시는 스프링의 빈으로 등록돼야 한다. 스프링은 프록시 오브젝트를 생성해주는 기술을 추상화한 팩토리 빈을 제공해준다.
스프링의 ProxyFactoryBean은 프록시를 생성해서 빈 오브젝트로 등록하게 해주는 팩토리 빈이다. 순수하게 프록시를 생성하는 작업만 담당하고 프록시를 통해 제공해줄 부가기능은 별고의 빈에 둘 수 있다.
ProxyFactoryBean이 생성하는 프록시에서 사용할 부가기능은 MethodInterceptor 인터페이스를 구현해서 만든다. MethodInterceptor는 InvocationHandler와 비슷하지만, InvocationHandler의 invoke() 메서드는 타깃 오브젝트에 대한 정보를 제공하지 않는다. 따라서 타깃은 InvocationHandler를 구현한 클래스가 직접 알고 있어야 한다. 반면에 MethodInterceptor의 invoke() 메서드는 ProxyFactoryBean으로부터 타깃 오브젝트에 대한 정보까지 함께 제공받는다. 그래서 MethodInterceptor는 타깃 오브젝트에 상관없이 독립적으로 만들어질 수 있다. 따라서 MethodInterceptor 오브젝트는 타깃이 다른 여러 프록시에서 함께 사용할 수 있고, 싱글톤 빈으로 등록 가능하다.
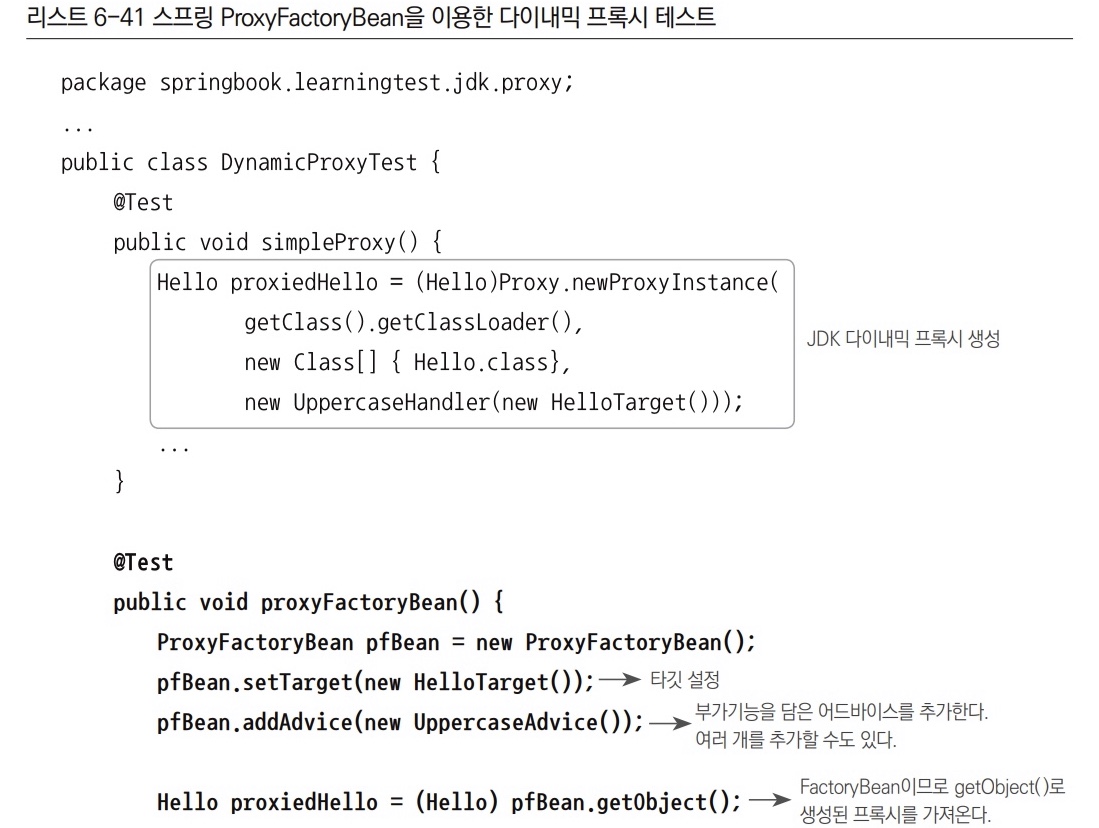

4.1.1 어드바이스: 타깃이 필요 없는 순수한 부가기능
MethodInterceptor
InvocationHandler를 구현했을 때와 달리 MethodInterceptor에는 타깃 오브젝트가 등장하지 않는다. MethodInterceptor로는 메서드 정보와 함께 타깃 오브젝트가 담긴 MethodInvocation 오브젝트가 전달된다. MethodInvocation은 일종의 콜백 오브젝트로, proceed() 메서드를 실행하면 타깃 오브젝트의 메서드를 내부적으로 실행해주는 기능이 있다. MethodInvocation 구현 클래스는 일종의 공유 가능한 템플릿처럼 동작하는 것이다. ProxyFactoryBean은 작은 단위의 템플릿/콜백 구조를 응용해서 적용했기 때문에 템플릿 역할을 하는 MethodInvocation을 싱글톤으로 두고 공유할 수 있다.
addAdvice()
ProxyFactoryBean에 이 MethodInterceptor를 설정해줄 때는 수정자 메서드 대신 addAdvice()라는 메서드를 사용한다. 이 메서드를 통해 ProxyFactoryBean에 여러 개의 MethodInterceptor를 추가할 수 있다. ProxyFactoryBean 하나만으로 여러 개의 부가기능을 제공해주는 프록시를 만들 수 있다.
또한, MethodInterceptor는 Advice 인터페이스를 상속하고 있는 서브인터페이스다. 그래서 MethodInterceptor 오브젝트를 추가하는 메서드 이름이 addMethodInterceptor가 아닌 addAdvice이다. 이렇게 MethodInterceptor처럼 타깃 오브젝트에 적용하는 부가기능을 담은 오브젝트를 스프링에서는 어드바이스(advice)라고 부른다.
인터페이스 자동 구현
다이내믹 프록시에선 인터페이스를 제공받아야 다이내믹 오브젝트의 타입을 결정할 수 있었지만, ProxyFactoryBean은 인터페이스 타입을 제공받지도 않고 인터페이스를 구현한 프록시를 만들어낼 수 있다. ProxyFactoryBean은 인터페이스 자동검출 기능을 사용해 타깃 오브젝트가 구현하고 있는 인터페이스 정보를 알아낸다. 그리고 알아낸 타깃 오브젝트가 구현하고 있는 모든 인터페이스를 동일하게 구현하는 프록시를 만들어준다. 타깃 오브젝트가 구현하는 인터페이스 중에서 일부만 프록시에 적용하기를 원한다면 인터페이스 정보를 직접 제공해줘도 된다. ProxyFactoryBean도 setInterfaces() 메서드를 통해 구현해야 할 인터페이스를 지정할 수 있다.
ProxyFactoryBean은 기본적으로 JDK가 제공하는 다이내믹 프록시를 만들어준다. 경우에 따라서는 CGLib이라고 하는 오픈소스 바이트코드 생성 프레임워크를 이용해 프록시를 만들기도 한다.
4.1.2 포인트컷: 부가기능 적용 대상 메서드 선정 방법
기존에 InvocationHandler를 직접 구현했을 때는 부가기능 적용 외에도 메서드의 이름을 가지고 부가기능 적용 대상 메서드를 선정하는 것이 있었다. MethodInterceptor 오브젝는 타깃 정보를 갖고 있지 않도록 만들었고, 그 덕분에 스프링의 싱글톤 빈으로 등록할 수 있었다. 그런데 트랜잭션 적용 메서드 패턴은 프록시마다 다를 수 있기 때문에 여러 프록시가 공유하는 MethodInterceptor에 특정 프록시에만 적용되는 패턴을 넣으면 문제가 된다.
이 문제는 코드 분리로 해결할 수 있다. MethodInterceptor는 InvocationHandler와 다르게 프록시가 클라이언트로부터 받는 요청을 일일이 전달받을 필요는 없다. MethodInterceptor에는 재사용 가능한 순수한 부가기능 제공 코드만 남겨주는 대신, 프록시에 부가기능 적용 메서드를 선택하는 기능을 넣는다. 물론 프록시의 핵심 가치는 타깃을 대신해서 클라이언트의 요청을 받아 처리하는 오브젝트로서의 존재 자체이므로, 메서드를 선별하는 기능은 프록시로부터 다시 분리하는 편이 낫다. 메서드를 선정하는 일도 일종의 교환 가능한 알고리즘이므로 전략 패턴을 적용할 수 있기 때문이다.
기존 JDK 다이내믹 프록시를 이용한 방식
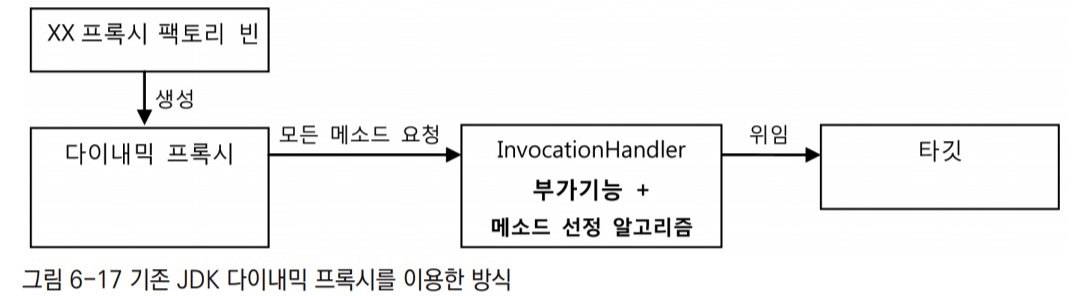
- 기존 방식도 다이내믹 프록시와 부가기능을 분리할 수 있고, 부가기능 적용 대상 메서드를 선정할 수 있게 되어 있다.
- 문제는 부가기능을 가진
InvocationHandler가 타깃과 메서드 선정 알고리즘 코드에 의존하고 있어서, 타깃이 다르고 메서드 선정 방식이 다르다면InvocationHandler오브젝트를 여러 프록시가 공유할 수 없다. - 타깃과 메서드 선정 알고리즘은 DI를 통해 분리할 수는 있지만 한번 빈으로 구성된
InvocationHandler오브젝트는, 오브젝트 차원에서 특정 타깃을 위한 프록시에 제한된다는 뜻이다. 그래서InvocationHandler를 따로 빈으로 등록하지 않고TxProxyFactoryBean내부에서 매번 생성하도록 만들었던 것이다. - 따라서 타깃 변경과 메서드 선정 알고리즘 변경 같은 확장이 필요하면 팩토리 빈 내의 프록시 생성코드를 직접 변경해야 한다. 결국 확장에는 유연하지 못한, OCP 원칙을 잘 지키지 못하는 구조다.
스프링 ProxyFactoryBean을 이용한 방식
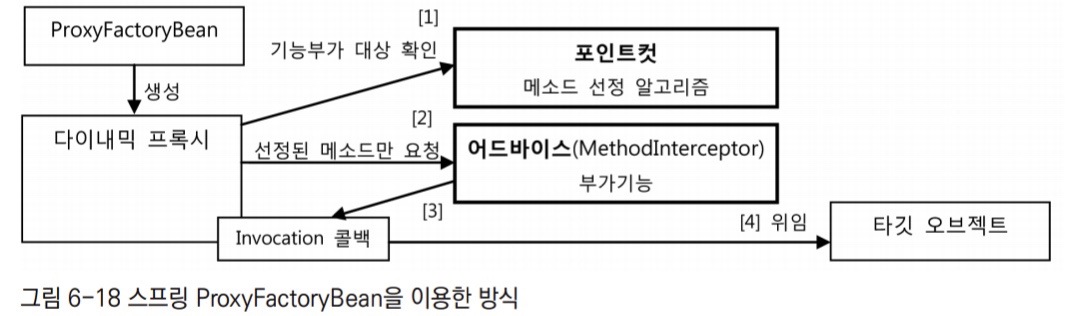
- 이 방식은 두 가지 확장 기능인 부가기능(Advice)과 메서드 선정 알고리즘(Pointcut)을 활용하는 유연한 구조를 제공한다.
- 스프링은 부가기능을 제공하는 오브젝트를 어드바이스라고 부르고, 메서드 선정 알고리즘을 담은 오브젝트를 포인트컷이라고 부른다.
- 어드바이스와 포인트컷은 모두 프록시에 DI로 주입돼서 사용된다. 두 가지 모두 여러 프록시에서 공유가 가능하도록 만들어지기 때문에 스프링의 싱글톤 빈으로 등록이 가능하다.
- 프록시는 클라이언트로부터 요청을 받으면 먼저 포인트컷에게 부가기능을 부여할 메서드인지 확인해달라고 요청한다. 포인트컷은
Pointcut인터페이스를 구현하면 된다. 프록시는 포인트컷으로부터 부가기능을 적용할 대상 메서드인지 확인받으면,MethodInterceptor타입의 어드바이스를 호출한다. - 어드바이스는 JDK의 다이내믹 프록시의
InvocationHandler와 달리 직접 타깃을 호출하지 않는다. 자신이 공유돼야 하므로 타깃 정보라는 상태를 가질 수 없다. 따라서 타깃에 직접 의존하지 않도록 일종의 템플릿 구조로 설계되어 있다. - 어드바이스가 부가기능을 부여하는 중에 타깃 메서드의 호출이 필요하면 프록시로부터 전달받은
MethodInvocation타입 콜백 오브젝트의proceed()메서드를 호출해주기만 하면 된다. - 실제 위임 대상인 타깃 오브젝트의 레퍼런스를 갖고 있고, 이를 이용해 타깃 메서드를 직접 호출하는 것은 프록시가 메서드 호출에 따라 만드는
Invocation콜백의 역할이다.- 재사용 가능한 기능을 만들어두고 바뀌는 부분(콜백 오브젝트와 메서드 호출정보)만 외부에서 주입해서 이를 작업 흐름(부가기능 부여) 중에 사용하도록 하는 전형적인 템플릿/콜백 구조다.
- 어드바이스가 일종의 템플릿이 되고 타깃을 호출하는 기능을 갖고 있는
MethodInvocation오브젝트가 콜백이 되는 것이다. - 템플릿은 한 번 만들면 재사용이 가능하고 여러 빈이 공유해서 사용할 수 있듯이, 어드바이스도 독립적인 싱글톤 빈으로 등록하게 DI를 주입해서 여러 프록시가 사용하도록 만들 수 있다.
- 프록시로부터 어드바이스와 독립시키고 DI를 사용하게 한 것은 전형적인 전략 패턴 구조다. 덕분에 여러 프록시가 공유해서 사용할 수도 있고, 또 구체적인 부가기능 방식이나 메서드 선정 알고리즘이 바뀌면 구현 클래스만 바꿔서 설정에 넣어주면 된다.
- 프록시와
ProxyFactoryBean등의 변경 없이도 기능을 자유롭게 확장할 수 있는 OCP를 충실히 지키는 구조가 되는 것이다.
- 프록시와
어드바이스와 포인트컷을 적용한 ProxyFactoryBean 학습 테스트

- 어드바이스 :
MethodInterceptor로 만든 어드바이스 - 포인트컷 : 이름 패턴을 이용해 메서드를 선정하는 포인트컷 - 스프링이 제공하는
NameMatchMethodPointcut - 포인트컷이 필요없을 때는
ProxyFactoryBean의addAdvice()메서드를 호출해서 어드바이스만 등록하면 되지만, 포인트컷을 함께 등록할 때는 어드바이스와 포인트컷을Advisor타입으로 묶어서addAdvisor()메서드를 호출해야 한다.ProxyFactoryBean에는 여러 개의 어드바이스와 포인트컷이 추가될 수 있기 때문이다.- 이렇게 어드바이스와 포인트컷을 묶은 오브젝트를 어드바이저라고 부른다.
어드바이저 = 포인트컷(메서드 선정 알고리즘) + 어드바이스(부가기능)
4.2 ProxyFactoryBean 적용
JDK 다이내믹 프록시의 구조를 그대로 이용해서 만들었던 TxProxyFactoryBean을 스프링이 제공하는 ProxyFactoryBean을 이용하도록 수정해보자.
4.2.1 TransactionAdvice
- 어드바이스는
MethodInterceptor라는Advice서브인터페이스를 구현해서 만든다. - JDK 다이내믹 프록시 방식으로 만든
TransactionHandler의 코드에서 타깃과 메서드 선정 부분을 제거해주면 된다. - 타깃 메서드가 던지는 예외도
InvocationTargetException으로 포장되서 오지 않기 때문에 그대로 잡아서 처리하면 된다.

4.2.2 스프링 XML 설정파일
- 어드바이스 등록
- 트랜잭션 기능 적용을 위해
transactionManager만 DI 해준다.

- 트랜잭션 기능 적용을 위해
- 포인트컷 등록
- 트랜잭션 적용 메서드 선정을 위한 포인트컷 빈을 등록한다.
- 스프링이 제공하는 포인트컷 클래스를 사용할 것이므로 빈 설정만 만들어준다.
- 메서드 이름 패턴은 'upgrade'로 시작하는 모든 메서드를 선택하도록 만든다.
mappedName프로퍼티에 넣어준다.

- 어드바이저 등록
- 생성자로 넣어줘도 되고, 프로퍼티를 이용해 DI 해도 된다.

- 생성자로 넣어줘도 되고, 프로퍼티를 이용해 DI 해도 된다.
ProxyFactoryBean등록- 프로퍼티에 타깃 빈과 어드바이저 빈을 지정해준다.
- 어드바이저의 프로퍼티 이름이 advisor가 아닌 이유는 어드바이스와 어드바이저를 혼합해서 설정할 수 있도록 하기 위해서다. 그래서
property태그의ref애트리뷰트를 통한 설정 대신list와value태그를 통해 여러 개의 값을 넣을 수 있도록 하고 있다. - value 태그에는 어드바이스 또는 어드바이저로 설정한 빈의 아이디를 넣으면 된다.
- 만약 타깃의 모든 메서드에 적용해도 좋기 때문에 포인트컷의 적용이 필요 없다면
transactionAdvice라고 넣을 수 있다.


4.2.3 테스트
- 순수하게
UserService가 제공하는 기능의 테스트가 목적인 테스트는 수정 X
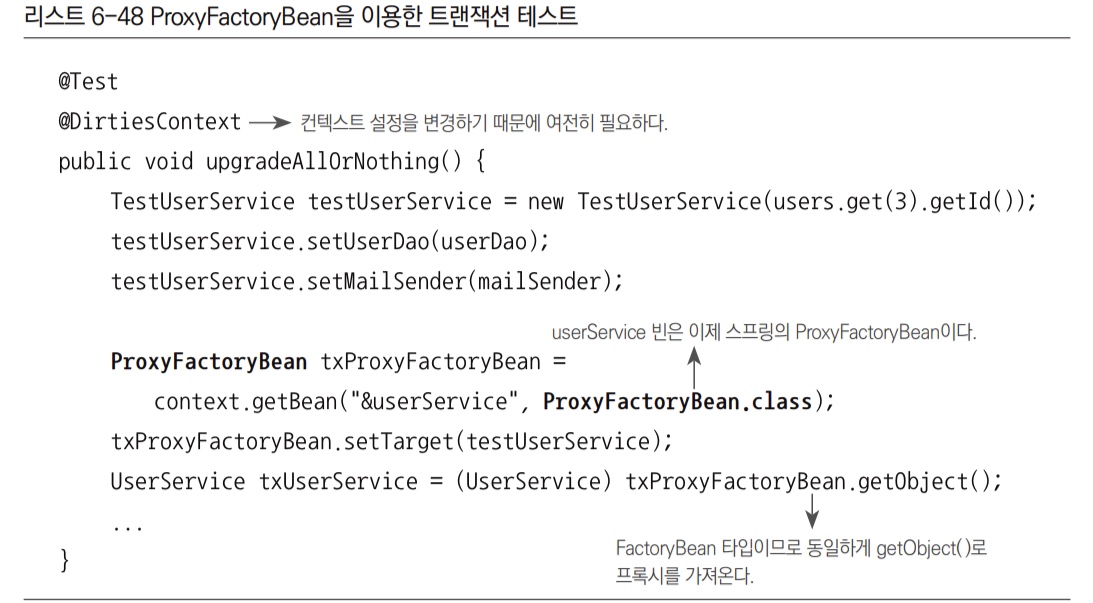
프록시 구현이나 설정 방식이 어떤 것이든 상관없이UserService를 구현한userService빈을 가져다 사용하거나, 트랜잭션 따위는 신경 쓰지 않고 고립된 테스트로 만들면 되기 때문이다. upgradeAllOrNothing()수정- 스프링의
ProxyFactoryBean도 팩토리 빈이므로 기존의TxProxyFactoryBean과 같은 방법으로 테스트할 수 있다. - 팩토리 빈을 직접 가져올 때 캐스팅할 타입만
ProxyFactoryBean으로 변경해준다.
- 스프링의
4.2.4 어드바이스와 포인트컷의 재사용
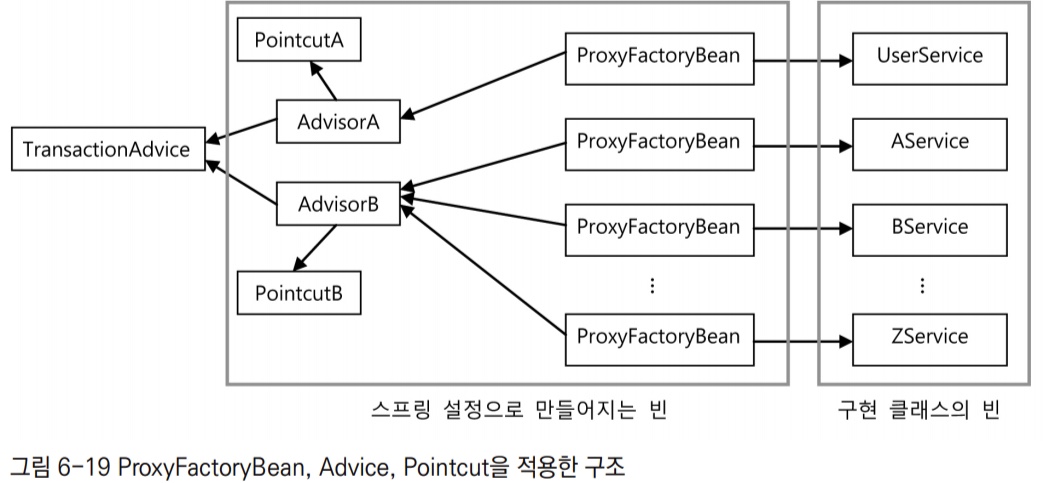
ProxyFactoryBean은 스프링의 DI와 템플릿/콜백 패턴, 서비스 추상화 등의 기법이 모두 적용된 것이다. 그 덕분에 독립적이며, 여러 프록시가 공유할 수 있는 어드바이스와 포인트컷으로 확장 기능을 분리할 수 있었다. 새로운 비즈니스 로직을 담은 서비스 클래스가 만들어져도 이미 만들어둔 TransactionAdvice를 그대로 재사용할 수 있다. 메서드의 선정을 위한 포인트컷이 필요하면 이름 패턴만 지정해서 ProxyFactoryBean에 등록해주면 된다.
ProxyFactoryBean을 이용해서 많은 수의 서비스 빈에게 트랜잭션 부가 기능을 적용했을 때의 구조다. 트랜잭션 부가기능을 담은 TransactionAdvice는 하나만 만들어서 싱글톤 빈으로 등록해주면, DI 설정을 통해 모든 서비스에 적용 가능하다. 메서드 선정 방식이 달라지는 경우만 포인트컷의 설정을 따로 등록하고 어드바이저로 조합해서 적용해주면 된다.
5. 스프링 AOP
지금까지 작업의 목표는 비즈니스 로직에 반복적으로 등장해야만 했던 트랜잭션 코드를 깔끔하고 효과적으로 분리해내는 것이다. 이렇게 분리해낸 트랜잭션 코드는 부가기능을 적용한 후에도 기존 설계와 코드에는 영향을 주지 않는, 투명한 부가기능 형태로 제공돼야 한다.
5.1 자동 프록시 생성
프록시 팩토리 빈 방식의 접근 방법의 두 가지 문제 중에 부가기능이 타깃 오브젝트마다 새로 만들어지는 문제는 스프링 ProxyFactoryBean의 어드바이스를 통해 해결했다. 하지만 부가기능의 적용이 필요한 타깃 오브젝트마다 거의 비슷한 내용의 ProxyFactoryBean 빈 설정정보를 추가해주는 부분이 남아있다. 새로운 타깃이 등장했다고 코드를 손댈 필요는 없어졌지만, 설정은 매번 복사해서 붙이고 target 프로퍼티의 내용을 수정해줘야 한다.
5.1.1 중복 문제의 접근 방법
지금까지의 반복적이고 기계적인 코드에 대한 해결책
1. 전략 패턴과 DI 적용
JDBC API를 사용하는 DAO 코드에서 메서드마다 try/catch/finally 블록으로 구성된 비슷한 코드가 반복해서 나타났다. 이 코드는 바뀌지 않는 부분과 바뀌는 부분을 구분해서 분리하고, 템플릿과 콜백, 클라이언트로 나누는 방법을 통해 해결했다.
2. 런타임 코드 자동생성 기법 이용
반복적인 위임 코드가 필요한 프록시 클래스 코드에서 타깃 오브젝트로의 위임 코드와 부가기능 적용을 위한 코드가 프록시가 구현해야 하는 모든 인터페이스 메서드마다 반복적으로 필요했다. 이는 다이내믹 프록시를 이용해서 해결했다. JDK의 다이내믹 프록시는 특정 인터페이스를 구현한 오브젝트에 대해서 프록시 역할을 해주는 클래스를 런타임 시 내부적으로 만들어준다.
변하지 않는 타깃으로의 위임과 부가기능 적용 여부 판단이라는 부분은 코드 생성 기법을 이용하는 다이내믹 프록시 기술에 맡기고, 변하는 부가기능 코드는 별도로 만들어서 다이내믹 프록시 생성 팩토리에 DI로 제공하는 방법을 사용한 것이다. 의미 있는 부가기능 로직인 트랜잭션 경계설정은 코드로 만들게 하고, 기게적인 코드인 타깃 인터페이스 구현과 위임, 부가기능 연동 부분은 자동생성하게 한 것이다.
5.1.2 빈 후처리기를 이용한 자동 프록시 생성기
스프링은 OCP의 가장 중요한 요소인 유연한 확장이라는 개념을 스프링 컨테이너 자신에게도 다양한 방법으로 적용하고 있다. 스프링은 컨테이너로서 제공하는 기능 중에서 변하지 않는 핵심적인 부분에는 대부분 확장할 수 있도록 확장 포인트를 제공해준다.
그 중 BeanPostProcessor 인터페이스를 구현해서 만드는 빈 후처리기가 있다. 빈 후처리기는 스프링 빈 오브젝트로 만들어지고 난 후에, 빈 오브젝트를 다시 가공할 수 있게 해준다.
DefaultAdvisorAutoProxyCreator
- 스프링이 제공하는 빈 후처리기이자, 어드바이저를 이용한 자동 프록시 생성기이다.
- 빈 후처리기를 스프링에 적용하는 방법은 빈 후처리기 자체를 빈으로 등록하는 것이다.
- 스프링은 빈 후처리기가 빈으로 등록되어 있으면 빈 오브젝트가 생성될 때마다 빈 후처리기에 보내서 후처리 작업을 요청한다.
- 빈 후처리기는 빈 오브젝트의 프로퍼티를 강제로 수정할 수도 있고 별도의 초기화 작업을 수행할 수도 있다. 심지어 만들어진 빈 오브젝트 자체를 바꿔치기할 수도 있다.
따라서 스프링이 설정을 참고해서 만든 오브젝트가 아닌 다른 오브젝트를 빈으로 등록시키는 것이 가능하다. - 이를 이용하면 스프링이 생성하는 빈 오브젝트의 일부를 프록시로 포장하고, 프록시를 빈으로 대신 등록할 수도 있다. 이것이 자동 프록시 생성 빈 후처리기다.
빈 후처리기를 이용한 자동 프록시 생성 방법
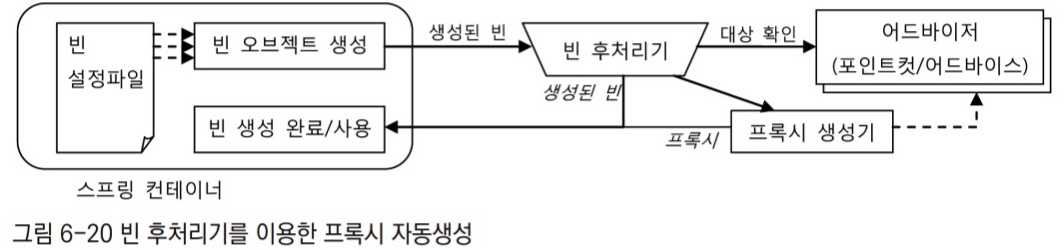
1. DefaultAdvisorAutoProxyCreator 빈 후처리기가 등록되어 있으면 스프링은 빈 오브젝트를 만들 때마다 후처리기에게 빈을 보낸다.
2. DefaultAdvisorAutoProxyCreator는 빈으로 등록된 모든 어드바이저 내의 포인트컷을 이용해 전달받은 빈이 프록시 적용 대상인지 확인한다.
3. 프록시 적용 대상이면 그때는 내장된 프록시 생성기에게 현재 빈에 대한 프록시를 만들게 하고, 만들어진 프록시에 어드바이저를 연결해준다.
4. 빈 후처리기는 프록시가 생성되면 원래 컨테이너가 전달해준 빈 오브젝트 대신 프록시 오브젝트를 컨테이너에게 돌려준다.
5. 컨테이너느 최종적으로 빈 후처리기가 돌려준 오브젝트를 빈으로 등록하고 사용한다.
적용할 빈을 선정하는 로직이 추가된 포인트컷이 담긴 어드바이저를 등록하고 빈 후처리기를 사용하면 일일이 ProxyFactoryBean 빈을 등록하지 않아도 타깃 오브젝트에 자동으로 프록시가 적용되게 할 수 있다.
5.1.3 확장된 포인트컷
지금까지 포인트컷이란 타깃 오브젝트의 메서드 중에서 어떤 메서드에 부가기능을 적용할지를 선정해주는 역할을 한다고 했다. 사실 포인트컷은 클래스 필터와 메서드 매처 두 가지를 돌려주는 메서드를 갖고 있다. Pointcut 인터페이스를 보면, 실제 포인트컷의 선별 로직은 이 두 가지 타입의 오브젝트에 담겨 있다.
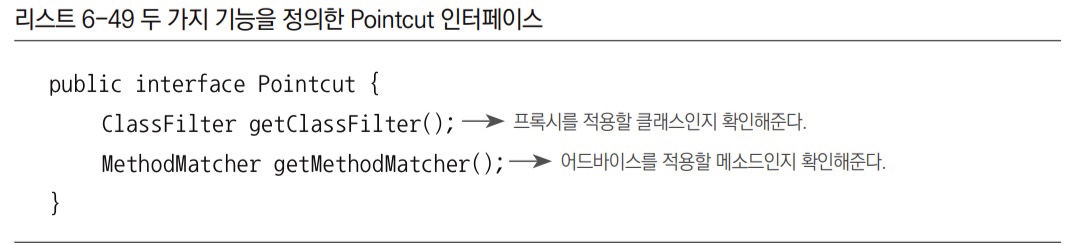
- 지금까지는
MethodMatcher라는 메서드를 선별하는 기능만 사용해왔다. - 기존에 사용한
NameMatchMethodPointcut은 메서드 선별 기능만 가진 특별한 포인트컷이다. - 메서드만 선별한다는 건 클래스 필터는 모든 클래스를 다 받아주도록 만들어져 있다. 즉, 클래스의 종류는 상관없이 메서드만 판별한다.
- Pointcut 선정 기능을 모두 적용한다면, 먼저 프록시를 적용할 클래스인지 판단하고 나서, 적용 대상 클래스인 경우에는 어드바이스를 적용할 메서드인지 확인하는 식으로 동작한다.
- 모든 빈에 대해 프록시 자동 적용 대상을 선별해야 하는 빈 후처리기인
DefaultAdvisorAutoProxyCreator는 클래스와 메서드 선정 알고리즘을 모두 갖고 있는 포인트컷과 어드바이스가 결합되어 있는 어드바이저가 등록되어 있어야 한다.
5.1.4 포인트컷 테스트
변경 사항
- 앞서 사용한
NameMatchMethodPointcut클래스를 확장해서 클래스도 고를 수 있도록 하자. - 프록시 적용 후보 클래스를 여러 개 만들어두고 이 포인트컷을 적용한
ProxyFactoryBean으로 프록시를 만들도록 해서 과연 어드바이스가 적용되는지 확인하자.

- 포인트컷
NameMatchMethodPointcut을 내부 익명 클래스 방식으로 확장해서 만들었다.- 원래 모든 클래스를 다 받아주는 클래스 필터를 리턴하던
getClassFilter()를 오버라이드해서 이름이HelloT로 시작하는 클래스만을 선정해주는 필터로 만들었다.
- 테스트
- 세 클래스 모두
elloTarget클래스를 상속해 클래스 이름만 다르게 한다. 이 세 개의 클래스에 모두 동일한 포인트컷을 적용했다. - 세 클래스를 포인트컷을 적용할 타깃 오브젝트로 각각 등록하고 각 메서드에 대해 어드바이스 적용 여부를 확인한다.
- 메서드 선정기준으로만 보면 두 개의 메서드에는 어드바이스를 적용하고 마지막 것은 적용되지 않아야 한다.
HelloWorld클래스는 클래스 필터를 통과하지 못한다.- 클래스 필터를 통과하지 못하는 클래스로 만든 타깃 오브젝트는 모든 메서드에 어드바이스가 적용되지 않는다.
- 포인트 컷이 클래스 필터까지 동작해서 클래스를 걸러버리면 아무리 프록시를 적용했다고 해도 부가기능은 전혀 제공되지 않는다는 점을 주의하자.
- 세 클래스 모두
5.2 efaultAdvisorAutoProxyCreator의 적용
5.2.1 클래스 필터를 적용한 포인트컷 작성
메서드 이름만 비교하던 NameMatchMethodPointcut을 상속해서 프로퍼티로 주어진 이름 패턴을 가지고 클래스 이름을 비교하는 ClassFilter를 추가하도록 만들 것이다.

5.2.2 어드바이저를 이용하는 자동 프록시 생성기 등록
-
자동 프록시 생성기인
DefaultAdvisorAutoProxyCreator- 등록된 빈 중에서
Advisor인터페이스를 구현한 것을 모두 찾는다. - 그리고 생성되는 모든 빈에 대해 어드바이저의 포인트컷을 적용해보면서 프록시 적용 대상을 선정한다.
- 빈 클래스가 프록시 선정 대상이라면 프록시를 만들어 원래 빈 오브젝트와 바꿔치기한다.
- 원래 빈 오브젝트는 프록쉬 뒤에 연결돼서 프록시를 통해서만 접근 가능하게 바뀌는 것이다.
- 따라서 타깃 빈에 의존한다고 정의한 다른 빈들은 프록시 오브젝트를 대신 DI 받게 될 것이다.
- 등록된 빈 중에서
-
DefaultAdvisorAutoProxyCreator등록하는 법
<bean class=
"org.springframework.aop.framework.autoproxy.DefaultAdvisorAutoProxyCreator" />5.2.3 포인트컷 등록
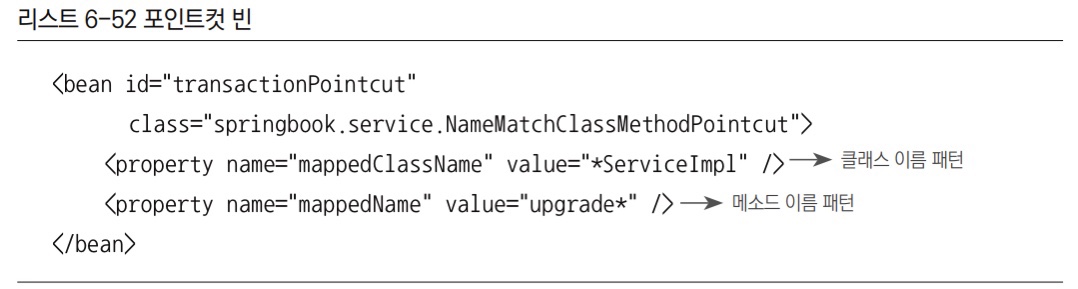
- 포인트컷 변경 사항
- 기존의 포인트컷 설정을 삭제하고 클래스 필터 지원 포인트컷을 빈으로 새로 등록한다.
ServiceImpl로 이름이 끝나는 클래스와upgrade로 시작하는 메서드를 선정해주는 포인트컷이다.
5.2.4 어드바이스와 어드바이저
- 어드바이스 변경 사항
- 기존의 어드바이스와 어드바이저 빈의 설정은 수정할 게 없다.
- 하지만 어드바이저로서 사용되는 방법이 바뀌었다.
- 기존 :
ProxyFactoryBean으로 등록한 빈에서처럼 어드바이저를 명시적으로 DI 하는 빈은 존재하지 않는다. - 변경 : 어드바이저를 이용하는 자동 프록시 생성기인
DefaultAdvisorAutoProxyCreator에 의해 자동수집되고, 프록시 대상 선정 과정에 참여하며, 자동생성된 프록시에 다이내믹하게 DI돼서 동작하는 어드바이저가 된다.
- 기존 :
5.2.5 ProxyFactoryBean 제거와 서비스 빈의 원상복구
- 프록시 팩토리 변경 사항
- 더 이상 명시적인 프록시 팩토리 빈을 등록하지 않기 때문에
ProxyFactoryBean타입의 빈은 삭제한다. - 이제
UserService와 관련된 빈 설정은userService빈 하나면 된다.
- 더 이상 명시적인 프록시 팩토리 빈을 등록하지 않기 때문에

5.2.6 자동 프록시 생성기를 사용하는 테스트
테스트 확인 사항
@Autowired를 통해 컨텍스트에서 가져오는UserService타입 오브젝트는UserServiceImpl이 아닌 트랜잭션이 적용된 프록시여야 한다.
테스트 수정 사항
- 기존
upgradeAllOrNothing()테스트 코드에서 사용한 방법은 한계가 있다.- 지금까지는 어떻게든 설정파일에는 정상적인 경우의 빈 설정만을 두고 롤백을 일으키는 예외상황에 대한 테스트는 테스트 코드에서 빈을 가져와 수동 DI로 구성을 바꿔서 사용했다.
- 자동 프록시 생성기를 적용한 후엔 더 이상 가져올
ProxyFactoryBean같은 팩토리 빈이 존재하지 않는다. 자동 프록시 생성기가 프록시를 만들어줬기 때문에 프록시 오브젝트만 남아있다. - 자동 프록시 생성기는 스프링 컨테이너에 종속적인 기법이기 때문에 예외상황을 위한 테스트 대상도 빈으로 등록해줄 필요가 있다.
- 강제 예외 발생용
TestUserService클래스를 직접 빈으로 등록하자.- 문제
TestUserService가UserServiceTest클래스의 내부에 정의된 스태틱 클래스이다.- 포인트컷이 트랜잭션 어드바이스를 적용해주는 대상 클래스의 이름 패턴이
*ServiceImpl이어서 빈으로 등록해도 포인트컷이 프록시 적용 대상으로 선정해주지 않는다.
- 해결
- 스태틱 멤버 클래스는 빈으로 등록하는 데 아무 문제가 없다.
- 특정 테스트 클래스에서만 사용되는 클래스는 스태틱 멤버 클래스로 정의하는 것이 편리하다.
- 클래스 이름을
TestUserServiceImpl로 변경한다. - 클래스를 테스트 코드에서 생성하는 것이 아니기 때문에 예외를 발생시킬 대상인 네 번째 사용자 아이드를 클래스에 넣어버리자. 살짝 테스트 정보의 중복이 발생하긴 한다.
- 트랜잭션 테스트용 예외 발생 클래스

TestUserServiceImpl을 빈으로 등록

- 스태틱 멤버 클래스는 빈으로 등록할 때 $를 사용해 클래스 이름을 지정해준다.
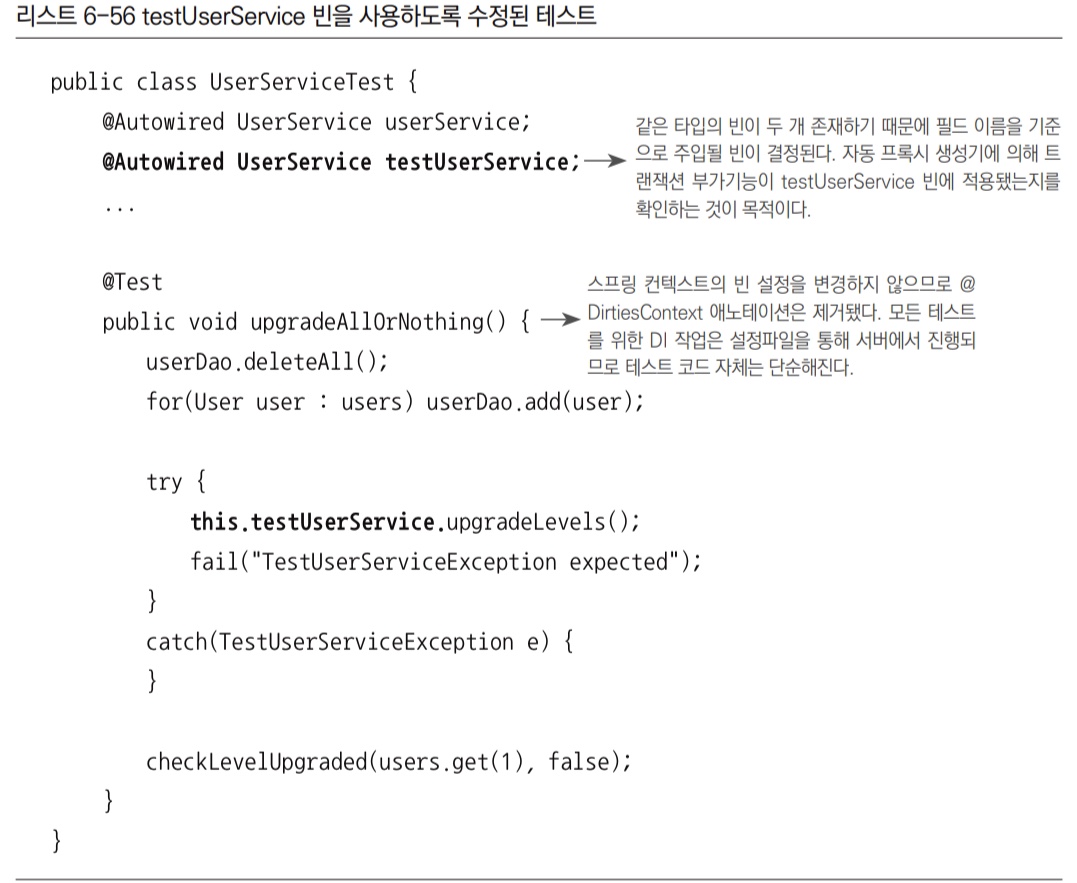
<bean>태그에parent애트리뷰트를 사용하면 다른 빈 설정의 내용을 상속받을 수 있다. 클래스는 물론이고 프로퍼티 설정도 모두 상속받고, 오버라이드도 가능하다.UserServiceImpl의 기능을 그대로 가져오고 일부 기능만 테스트에 맞게 수정해서 사용한 것이다.userService빈의 설정을 상속받은 뒤 클래스만 변경했다. DI를 위한 프로퍼티 설정은userService빈의 프로퍼티를 그대로 상속받는다.
upgradeAllOrNothing()테스트를 새로 추가한testUserService빈을 사용하도록 수정한다.testUserService빈도@Autowired로 가져오면 된다. 단,userService빈과 타입이 중복되므로 변수 이름을 빈 이름과 일치시켜줘야 한다.
5.2.7 자동생성 프록시 확인
지금까지 트랜잭션 어드바이스를 적용한 프록시 자동생성기를 빈 후처리기 메커니즘을 통해 적용했다.
확인해야 할 사항
- 트랜잭션이 필요한 빈에 트랜잭션 부가기능이 적용됐는지
- 트랜잭션이 정상적으로 커밋되는 경우에는 트랜잭션 적용 여부를 확인하기 힘들기 때문에 예외상황에서 트랜잭션이 롤백되게 함으로써 트랜잭션 적용 여부를 테스트해야 한다.
upgradeAllOrNothing()테스트를 통해 검증했다.
- 아무 빈에나 트랜잭션 부가기능이 적용된 것은 아닌지
- 프록시 자동생성기가 어드바이저 빈에 연결해둔 포인트컷의 클래스 필터가 제대로 동작해서 프록시 생성 대상을 선별하고 있는지 확인이 필요하다.
- 제대로 하려면 모든 빈을 다 가져와서 프록시로 변했는지 확인해야겠지만, 여기선 간단히 클래스 필터가 제대로 동작하는지 확인해보는 것만으로 충분할 것 같다.
- 포인트컷 빈의 클래스 이름 패턴을 변경해서 이번엔
testUserService빈에 트랜잭션이 적용되지 않게 한다. - 이 테스트도 제대로 하려면 전용 설정파일을 만들어 포인트컷을 재구성하는 등의 복잡한 과정이 필요할 텐데, 여기서는 간단히 현재 테스트 설정파일을 수정해서 확인하고 다시 원상복귀시키는 것으로 하자.
클래스 필터의 정상 동작 테스트
클래스 필터가 제대로 동작해서 프록시 생성 대상을 선별하고 있는지 테스트한다.
- 수정 사항
- 트랜잭션 포인트컷 빈의 클래스 필터용 이름 패턴인
appedClassName을 수정한다.
- 트랜잭션 포인트컷 빈의 클래스 필터용 이름 패턴인
- 테스트 사항
- 트랜잭션 테스트 대상인
TestUserServiceImpl클래스는 클래스 필터의 조건에 부합하지 않으니 트랜잭션이 적용되지 않아야 한다. - 트랜잭션이 적용되지 않았으니 트랜잭션 테스트인
upgradeAllOrNothing()이 실패해야 하고, 실패를 확인하면 다시 원상복귀시키자.
- 트랜잭션 테스트 대상인

자동생성된 프록시를 확인하는 테스트
- 수정 사항
- 컨테이너가 돌려준 서비스 빈의 타입을 확인하는 테스트를 만든다.
- 테스트 사항
DefaultAdvisorAutoProxyCreateor에 의해userService빈이 프록시로 바꿔치기 됐다면getBean("userService")로 가져온 오브젝트는TestUserService타입이 아니라 JDK의Proxy타입일 것이다.- 모드 JDK 다이내믹 프록시 방식으로 만들어지는 프록시는
Proxy클래스의 서브클래스이다.

5.3 포인트컷 표현식을 이용한 포인트컷
지금까지 작성했던 포인트컷은 메서드의 이름과 클래스의 이름 패턴을 각각 클래스 필터와 메서드 매처 오브젝트로 비교해서 선정하는 방식이었다. 일일이 클래스 필터와 메서드 매처를 구현하거나, 스프링이 제공하는 필터나 매처 클래스를 가져와 프로퍼티를 설정하는 방식이었다.
이보다 더 복잡하고 세밀한 기준을 이용해 클래스나 메서드를 선정하게 하려면? 리플렉션 API를 통해서 클래스와 메서드의 이름, 정의된 패키지, 파라미터, 리턴 값, 부여된 애노테이션, 구현한 인터페이스, 상속한 클래스 등의 정보까지 알아낼 수 있다. 하지만 리플렉션 API는 코드를 작성하기 번거롭고, 또한 리플렉션 API를 이용해 메타정보를 비교하는 방법은 조건이 달라질 때마다 포인트컷 구현 코드를 수정해야 한다.
스프링은 간단하고 효과적인 방법으로 포인트컷의 클래스나 메서드를 선정하는 알고리즘을 작성할 수 있는 방법을 제공한다. 정규식이나 JSP의 EL과 비슷한 일종의 표현식을 사용해서 포인트컷을 작성할 수 있도록 한다. 이것을 포인트컷 표현식이라고 한다.
5.3.1 포인트컷 표현식
포인트컷 표현식을 지원하는 포인트컷을 적용하려면 AspectJExpressionPointcut 클래스를 사용하면 된다. Pointcut 인터페이스를 구현해야 하는 스프링의 포인트컷은 클래스 선정을 위한 클래스 필터와 메서드 선정을 위한 메서드 매처를 제공해야 한다.
하지만 AspectJExpressionPointcut은 클래스와 메서드의 선정 알고리즘을 포인트컷 표현식을 이용해 한 번에 지정할 수 있게 해준다. 포인트컷 표현식은 자바의 RegEx 클래스가 지원하는 정규식처럼 간단한 문자열로 복잡한 선정조건을 쉽게 만들어낼 수 있는 강력한 표현식을 지원한다.
포인트컷 표현식 학습 테스트
- 포인트컷의 선정 후보가 될 클래스 두 개를 준비한다. 이 두 개의 클래스와 총 6개의 메서드를 대상으로 포인트컷 표현식을 적용해본다.
Target클래스는 총 5개의 메서드를 갖고 있다. 처음 4개는TargetInterface인터페이스에 정의된 메서드를 구현한 것이고, 마지막 메서드는Target클래스에서 정의한 것이다.

- 여러 개의 클래스 선정 기능을 확인해보기 위해 한 개의 클래스를 더 준비한다.

5.3.2 포인트컷 표현식 문법
AspectJ포인트컷 표현식은 포인트컷 지시자를 이용해 작성한다.- 포인트컷 지시자 중에서 가장 대표적으로 사용되는 것은
execution()이다. execution()지시자를 사용한 포인트컷 표현식의 문법구조
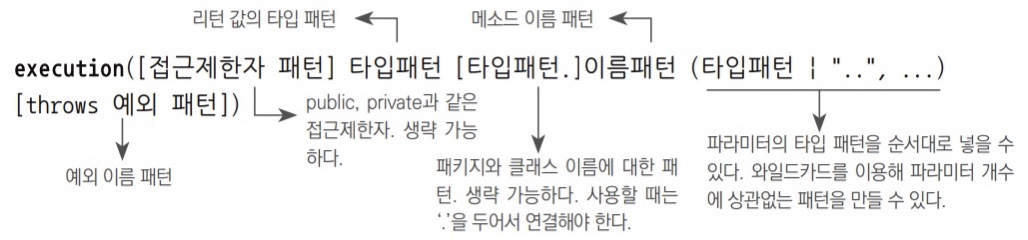
[]괄호는 옵션항목이라 생략 가능하다는 의미이고,|는 OR 조건이다.
- 리플렉션의
Method오브젝트가 제공하는 메서드의 풀 시그니처를 볼 수 있는 방법
ex)Target.minus()메서드의 풀 시그니처 보는 방법과 출력 결과System.out.println(Target.class.getMethod("minus", int.class, int.class));public int springbook.learningtest.spring.pointcut.Target.minus(int, int) throws java.lavng.RunitmeExceptionpublic: 접근제한자 (옵션)int: 리턴 값의 타입 패턴 (필수)- 반드시 하나의 타입을 지정해야 하거나 *를 써서 모든 타입을 다 선택하겠다고 해도 된다.
springbook.leargingtest.spring.point.Target: 패키지와 타입 이름을 포함한 클래스의 타입 패턴 (옵션)- 패키지 이름과 클래스 또는 인터페이스 이름에
*를 사용할 수 있다. 또..를 사용하면 한 번에 여러 개의 패키지를 선택할 수 있다.
- 패키지 이름과 클래스 또는 인터페이스 이름에
minus: 메서드 이름 패턴 (필수)- 모든 메서드를 다 선택하겠다면
*를 넣으면 된다.
- 모든 메서드를 다 선택하겠다면
(int, int): 메서드 파라미터의 타입 패턴 (필수)- 메서드 파라미터의 타입을
.로 구분하면서 순서대로 적으면 된다. - 파라미터가 없는 메서드를 지정하고 싶다면 ()로 적는다.
- 파라미터의 타입과 개수에 상관없이 모두 다 허용하는 패턴으로 만들려면
..을 넣으면 된다. ...을 이용해 뒷부분의 파라미터 조건만 생략할 수도 있다.
- 메서드 파라미터의 타입을
throws java.lang.RuntimeException: 예외 이름에 대한 타입 패턴 (옵션)- 생략이 가능하다(옵션)는 건 이 항목에 대해서는 조건을 부여하지 않는다 즉, 모든 타입을 다 허용하겠다는 의미다. 필수항목은 반드시 적어야 한다.
포인트컷 표현식 테스트
PointcutExpressionTest 테스트 클래스를 추가한다. Target 클래스의 minus() 메서드만 선정해주는 포인트컷 표현식을 만들고 이를 검증하는 테스트를 작성해보자.


1. 포인트컷 사용 준비
AspectJExpressionPointcut클래스의 오브젝트를 만들고 포인트컷 표현식을expression프로퍼티에 넣어주면 포인트컷을 사용할 준비가 된다.- 포인트컷 표현식은 메서드 시그니처를
execution()안에 넣어서 작성한다.execution()은 메서드를 실행에 대한 포인트컷이라는 의미다.
Target클래스의minus()메서드에 대해 테스트를 해본다.
- 포인트컷의 선정 방식은 클래스 필터와 메서드 매처를 각각 비교해보는 것이다. 두 가지 조건을 모두 만족시키면 해당 메서드는 포인트컷의 선정 대상이 된다.
- 포인트컷 자체가
minus()메서드의 시그니처이니 결과는true다.
Target클래스의 다른 메서드를 비교해본다.
- 클래스, 파라미터 등은 모두 통과하겠지만 메서드 이름과 예외 패턴이 포인트컷 표현식과 일치하지 않기 때문에 결과는
false다.
Bean.class의 메서드에 대해 테스트 해본다.
- 클래스부터 맞지 않으니 포인트컷 적용 결과는
false다.
5.3.3 포인트컷 표현식 테스트
메서드 시그니처를 그대로 사용한 포인트 표현식의 문법구조를 참고해 정리해보자.
이 중 옵션 항목을 생략하면 execution(int minus(int,int)) 로 간단히 만들어진다.
- ex) 리턴 값의 타입은 상관없이 minus라는 메서드 이름, 두 개의 int 파라미터를 가진 모든 메서드를 선정하는 포인트컷 표현식
- 리턴 값의 타입에 제한을 없애고 어떤 리턴 타입이든 상관없이 선정하도록 하려면
*와일드카드를 사용한다.
execution(* minus(int,int))
- 리턴 값의 타입에 제한을 없애고 어떤 리턴 타입이든 상관없이 선정하도록 하려면
- ex) 리턴 타입과 파라미터의 종류, 개수에 상관없이 minus라는 메서드 이름을 가진 모든 메서드를 선정하는 포인트컷 표현식
- 파라미터의 개수와 타입 무시하려면 () 안에
..를 넣어준다.
execution(* minus(..))
- 파라미터의 개수와 타입 무시하려면 () 안에
- ex) 리턴 타입, 파라미터, 메서드 이름에 상관없이 모든 메서드 조건을 다 허용하는 포인트컷 표현식
- 모든 선정조건을 다 없애고 모든 메서드를 다 허용하는 포인트컷이 필요하면 메서드 이름도 와일드카드로 한다.
포인트컷 표현식 테스트 보충
- 주어진 포인트컷을 이용해 특정 메서드에 대한 포인트컷을 적용해보고 결과를 확인하는 메서드를 추가한다.
- 메서드를 지정하려면 클래스와 메서드 이름, 메서드 파라미터 타입 정보가 필요하다.

pointcutMatches()메서드를 활용해 타깃으로 만든 두 클래스의 모든 메서드에 대해 포인트컷 선정 여부를 확인하는 메서드를 추가한다.
- 표현식과 6개의 메서드에 대한 예상 결과를 주면 이를 검증한다.

- 다양한 포인트컷을 만들어서 모든 메서드에 대한 포인트컷 적용 결과를 확인한다.
- 아래는 포인트컷 표현식과 그에 대한
targetCalssPointcutMatches()의 각 메서드별 포인트컷 검사 결과다.

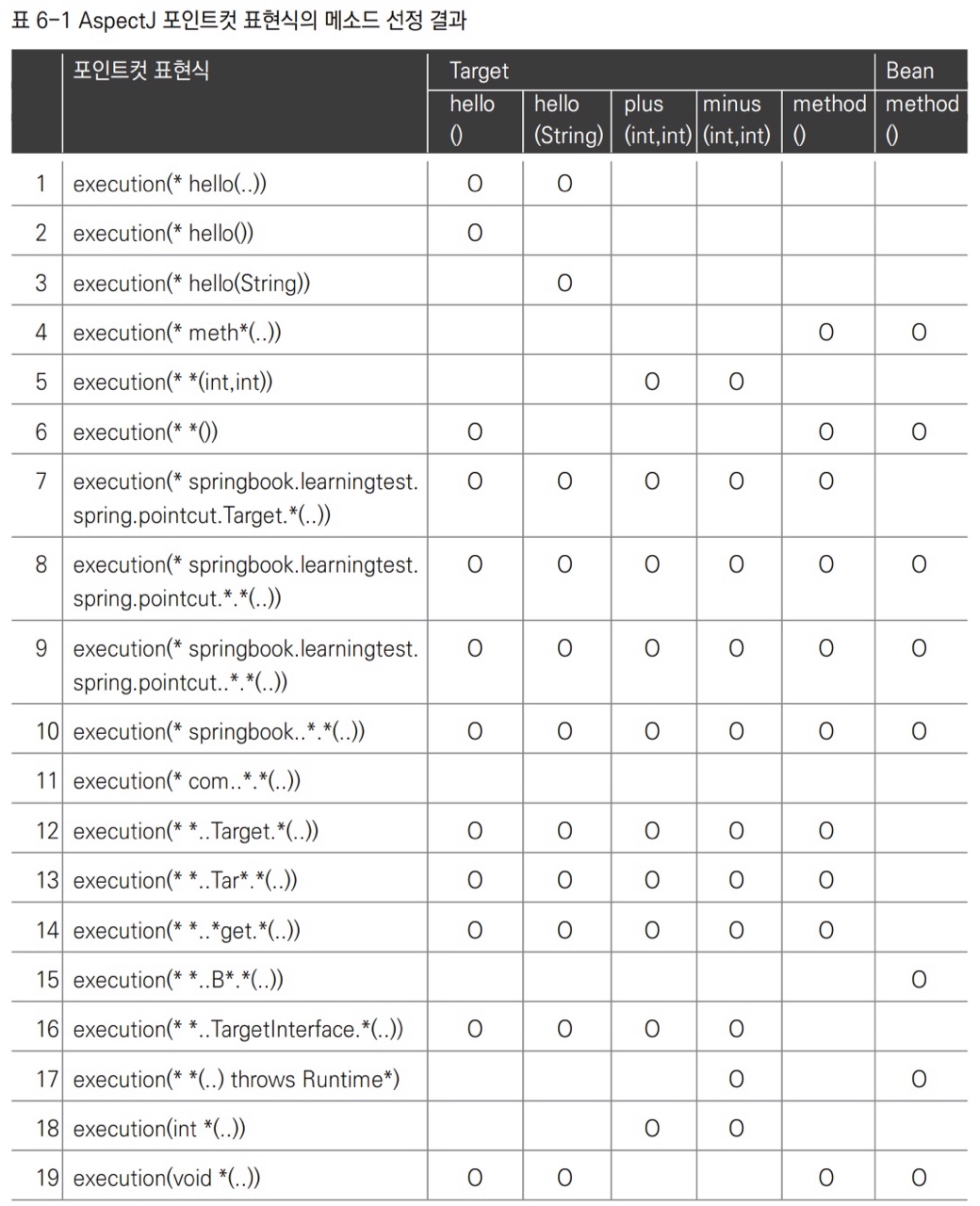
- 1 :
hello라는 이름을 가진 메서드를 선정한다. - 2 :
hello메서드 중 파라미터가 없는 것을 선정한다. - 3 :
hello메서드 중 파라미터의 개수가 한 개이며String타입인 것을 선정한다. - 4 :
meth로 시작하는 메서드를 선정한다. - 5 : 메서드 이름은 상관없고, 두 개의 정수 파라미터를 가진 메서드를 선정한다.
- 6 : 파라미터가 없는 모든 메서드를 선정한다.
- 7 :
springbook.learningtest.spring.pointcut.Target클래스의 모든 메서드를 선정한다. 클래스를 직접 지정한 것이다. - 8 :
springbook.learningtest.spring.pointcut패키지의 모든 클래스를 선정한다. 서브패키지의 클래스는 포함되지 않는다. - 9 :
springbook.learningtest.spring.pointcut패키지의 모든 서브패키지를 선정한다. - 10 :
springbook으로 시작하는 모든 패키지의 모든 서브패키지 즉, 모든 패키지의 모든 클래스를 다 지정한다. - 11 :
com으로 시작하는 모든 패키지의 모든 클래스를 다 지정한다. - 12 : 패키지에 상관없이
Target이라는 이름의 모든 클래스에 적용한다. 다른 패키지에 같은 이름의 클래스가 있어도 적용된다. - 13, 14, 15 : 클래스 이름에 와일드카드를 부여한 것이다. 모든 패키지 이름, 클래스 이름, 메서드 이름에는 와일드카드를 사용할 수 있다.
- 16 :
Target클래스가 아닌,Target클래스가 구현한TargetInterface인터페이스를 선정한다. 인터페이스를 사용하면Target클래스의 메서드 중에서 이 인터페이스를 구현한 메서드에만 포인트컷이 적용된다. - 17 :
Runtime으로 시작하는 어떤 예외라도 던지는 메서드를 선정한다. 메서드, 클래스는 상관없이 예외 선언만 확인한다. - 18, 19 : 리턴 타입으로 메서드를 선정한다.
- 빈으로 등록된 클래스의 단순한 이름만 비교했던 방식과 달리 포인트컷 표현식은 인터페이스, 슈퍼클래스의 타입도 인식해준다.
5.3.4 포인트컷 표현식을 이용하는 포인트컷 적용
포인트컷 표현식에 메서드의 시그니처를 비교하는 방식인 execution() 외에도 대표적으로 스프링에서 사용될 때 빈의 이름으로 비교하는 bean()이 있다. bean(*Service)라고 쓰면 아이디가 Service로 끝나는 모든 빈을 선택한다.
또 특정 애노테이션이 타입, 메서드, 파라미터에 적용되어 있는 것을 보고 메서드를 선정하게 하는 포인트컷도 만들 수 있다. 아래는 @Transactional이라는 애노테이션이 적용된 메서드를 선정하게 해준다.
@annotation(org.springframework.transaction.annotation.Transactional)포인트컷 표현식 적용
기존 포인트컷 빈의 프로퍼티 선언에 담긴 포인트컷 선정조건을 보자.
<property name="mappedClassName" value="*ServiceImpl" />
<property name="mappedName" value="upgrade*" />- 클래스 이름은
ServiceImpl로 끝나고 메서드 이름은upgrade로 시작하는 모든 클래스에 적용되도록 하는 표현식이다.
- 기존 포인트컷과 동일한 기준으로 메서드를 선정하는 알고리즘을 가진 포인트컷 표현식을 만든다.
execution(* *..*ServiceImpl.upgrade*(..))- 만든 포인트컷 표현식을
AspectJExpressionPointcut빈을 등록하고expression프로퍼티에 넣어주면 된다.

포인트컷 표현식을 사용하면 로직이 짧은 문자열에 담기기 때문에 클래스나 코드를 추가할 필요가 없어 코드와 설정이 모두 단순해진다. 반면에 문자열로 된 표현식이므로 런타임 시점까지 문법의 검증이나 기능 확인이 되지 않는다는 단점도 있다. 그러니 시간을 투자해서 충분히 학습하고, 다양한 테스트를 미리 만들어서 검증한 표현식을 가져다 사용하자.
포인트컷 표현식을 이용하는 포인트컷이 정확히 원하는 빈만 선정했는지 확인하는 일은 만만치 않다. 하지만 스프링 지원 툴을 사용하면 아주 간단히 포인트컷이 선정한 빈이 어떤 것인지 한눈에 확인하는 방법이 있다.
5.3.5 타입 패턴과 클래스 이름 패턴
앞에서 사용했던 단순한 클래스 이름 패턴과 포인트컷 표현식에서 사용하는 타입 패턴은 중요한 차이점이 있다. 테스트용 클래스의 이름을 다시 TestUserService라고 변경하고, 타입 패턴을 *..*ServiceImpl로 해서 테스트를 실행하면 어떻게 될까? 포인트컷 표현식에 따르면 TestUserService 클래스의 빈은 선정되지 않아야 하지만 결과는 성공한다.
그 이유는 포인트컷 표현식의 클래스 이름에 적용되는 패턴은 클래스 이름 패턴이 아니라 타입 패턴이기 때문이다. 클래스 이름은 TestUserService지만, 타입을 따져보면 TestUserService 클래스이자, 슈퍼클래스인 UserServiceImpl, 구현 인터페이스인 UserService 세 가지가 모두 적용된다.
5.4 AOP란 무엇인가?
비즈니스 로직을 담은 UserService에 트랜잭션을 적용해온 과정을 정리해보자.
5.4.1 트랜잭션 서비스 추상화
- 문제
- 트랜잭션 경계설정 코드를 비즈니스 로직을 담은 코드에 넣으면서 특정 트랜잭션 기술에 종속되는 코드가 돼버렸다.
- 트랜잭션을 처리한다는 기본적인 목적은 변하지 않더라도 그것을 어떻게 해야 한다는 구체적인 방법이 변하면, 트랜잭션과는 직접 관련이 없는 코드가 담긴 많은 클래스를 일일이 수정해야 했다.
- 해결
- 트랜잭션 적용이라는 추상적인 작업 내용은 유지한 채로 구체적인 구현 방법을 자유롭게 바꿀 수 있도록 서비스 추상화 기법을 적용했다.
- 트랜잭션 추상화란 결국 인터페이스와 DI를 통해 무엇을 하는지는 남기고, 그것을 어떻게 하는지를 분리한 것이다.
- 구체적인 구현 내용을 담은 의존 오브젝트는 런타임 시에 다이내믹하게 연결해준다는 DI를 활용한 전형적인 접근 방법이었다.
- 이 덕분에 비즈니스 로직 코드는 트랜잭션 처리에 관한 구체적인 방법과 서버환경에 종속되지 않는다.
- 트랜잭션 적용이라는 추상적인 작업 내용은 유지한 채로 구체적인 구현 방법을 자유롭게 바꿀 수 있도록 서비스 추상화 기법을 적용했다.
5.4.2 프록시와 데코레이터 패턴
- 문제
- 여전히 비즈니스 로직 코드에 트랜잭션이라는 부가적인 기능을 어디에 적용할 것인가가 노출되어 있었다.
- 트랜잭션 경계설정을 담당하는 코드의 특성 때문에 단순한 추상화와 메서드 추출 방법으로는 더 이상 제거할 방법이 없었다.
- 해결
- DI를 이용해 데코레이터 패턴을 적용했다.
- 트랜잭션을 처리하는 코드는 일종의 데코레이터에 담겨서, 클라이언트와 비즈니스 로직을 담은 타깃 클래스 사이에 존재하도록 만들었다. 그래서 클라이언트가 일종의 대리자인 프록시 역할을 하는 트랜잭션 데코레이터를 거쳐서 타깃에 접근할 수 있게 됐다.
- 클라이언트가 인터페이스와 DI를 통해 접근하도록 설계하고, 데코레이터 패턴을 적용해서, 비즈니스 로직을 담은 클래스의 코드에는 전혀 영향을 주지 않으면서 트랜잭션이라는 부가기능을 자유롭게 부여할 수 있는 구조를 만들었다.
- 이 덕분에 비즈니스 로직 코드는 트랜잭션과 같은 성격이 다른 코드로부터 자유로워졌고, 독립적으로 로직을 검증하는 고립된 단위 테스트를 만들 수도 있게 됐다.
5.4.3 다이내믹 프록시와 프록시 팩토리 빈
-
문제
- 이젠 프록시 클래스를 만드는 작업이 부담됐다.
- 비즈니스 로직 인터페이스의 모든 메서드마다 트랜잭션 기능을 부여하는 코드를 넣어야 했다. 즉, 트랜잭션 기능을 부여하지 않아도 되는 메서드조차 프록시로서 위임 기능이 필요하기 때문에 일일이 다 구현을 해줘야 했다.
-
해결
- 프록시 클래스 없이도 프록시 오브젝트를 런타임 시에 만들어주는 JDK 다이내믹 프록시 기술을 적용했다.
- 또한, 일부 메서드에만 트랜잭션을 적용해야 하는 경우에는 메서드를 선정하는 패턴 등을 이용할 수도 있었다.
- 이 덕분에 프록시 클래스 코드 작성의 부담도 덜고, 부가기능 부여 코드가 여기저기 중복돼서 나타나는 문제도 일부 해결할 수 있게 됐다.
-
또 다른 문제
- 동일한 기능의 프록시를 여러 오브젝트에 적용할 경우 오브젝트 단위로 중복이 일어나는 문제가 있었다.
-
해결
- JDK 다이내믹 프록시와 같은 프록시 기술을 추상화한 스프링의 프록시 팩토리 빈을 이용해서 다이내믹 프록시 생성 방법에 DI를 도입했다.
- 내부적으로 템플릿/콜백 패턴을 활용하는 스프링의 프록시 팩토리 빈 덕분에 부가기능을 담은 어드바이스와 부가기능 선정 알고리즘을 담은 포인트컷은 프록시에서 분리될 수 있었고 여러 프록시에서 공유해서 사용할 수 있게 됐다.
5.4.4 자동 프록시 생성 방법과 포인트컷
- 문제
- 트랜잭션 적용 대상이 되는 빈마다 일일이 프록시 팩토리 빈을 설정해줘야 한다는 부담이 있었다.
- 해결
- 스프링 컨테이너의 빈 생성 후처리 기법을 활용해 컨테이너 초기화 시점에서 자동으로 프록시를 만들어주는 방법을 도입했다.
- 프록시를 적용할 대상을 패턴을 이용해 자동으로 선정할 수 있도록, 클래스를 선정하는 기능을 담은 포인트컷을 사용했다.
- 처음엔 클래스와 메서드 선정 로직을 담은 코드를 직접 만들어서 포인트컷으로 사용했지만, 최종적으로는 포인트컷 표현식을 활용해 간단한 설정만으로 적용 대상을 쉽게 선택할 수 있게 됐다.
- 이 덕분에 트랜잭션 부가기능을 어디에 적용하는지에 대한 정보를 포인트컷이라는 독립적인 정보로 완전히 분리할 수 있었다.
5.4.6 AOP: 애스펙트 지향 프로그래밍
이러한 부가기능 모듈화 작업은 기존의 객체지향 설게 패러다임과는 구분되는 새로운 특성이 있다고 생각해서 객체지향 기술에서 주로 사용하는 오브젝트와는 다른 "애스펙트(aspect)"라고 부르기 시작했다. 애스펙트란 그 자체로 애플리케이션의 핵심기능을 담고 있지는 않지만, 애플리케이션을 구성하는 중요한 한 가지 요소이고, 핵심기능에 부가되어 의미를 갖는 특별한 모듈을 가리킨다.
애스펙트는 부가될 기능을 정의한 코드인 어드바이스와, 어드바이스를 어디에 적용할지를 결정하는 포인트컷을 함께 갖고 있다. 지금 사용하고 있는 어드바이저는 아주 단순한 형태의 애스펙트라고 볼 수 있다.
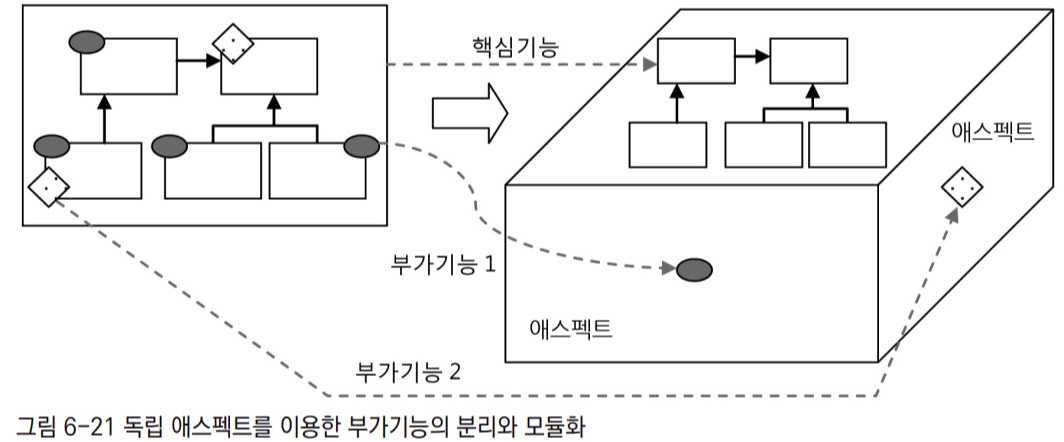
- 왼쪽 : 애스펙트로 부가기능을 분리하기 전 상태
- 핵심기능은 설계를 통해 모듈화되어 있고, 객체지향적인 장점을 잘 살릴 수 있도록 만들었지만, 부가기능이 핵심기능의 모듈에 침투해 들어가면서 설계와 코드가 모두 지저분해졌다.
- 이런 부가기능 코드는 여기저기 메서드에 흩어져 나타나고 코드는 중복된다.
- 트랜잭션 추상화까지는 적용했지만 더 이상 기존의 객체지향 설계 기법으로 해결할 수 없었다.
- 오른쪽 : 핵심기능 코드 사이에 침투한 부가기능을 독립적인 모듈인 애스펙트로 구분해냈다.
- 독립된 측면에 존재하는 애스펙트로 분리한 덕에 핵심기능은 순수하게 그 기능을 담은 코드로만 존재하고 독립적으로 살펴볼 수 있도록 구분된 면에 존재하게 된 것이다.
- 애플리케이션의 여러 다른 측면에 존재하는 부가기능은 결국 핵심기능과 함께 어우러져서 동작한다. 하나 이상의 부가기능이 핵심기능과 함께 동작할 수도 있다.
- 결국 런타임 시에는 각 부가기능 애스펙트는 자기가 필요한 위치에 다이내믹하게 참여하게 될 것이다. 하지만 설계와 개발은 다른 특성을 띤 애스펙트들을 독립적인 관점으로 작성하게 할 수 있다.
- 이렇게 애플리케이션의 핵심적인 기능에서 부가적인 기능을 분리해서 애스펙트라는 독특한 모듈로 만들어서 설계하고 개발하는 방법을 애스펙트 지향 프로그래밍 또는 AOP라고 부른다.
- AOP는 OOP의 보조적인 기술이다. 애스펙트를 분리함으로써 핵심기능을 설계하고 구현할 때 객체지향적인 가치를 지킬 수 있도록 도와주는 것이다.
- 또한, AOP는 결국 애플리케이션을 다양한 측면에서 독립적으로 모델링하고, 설계하고, 개발할 수 있도록 만들어주는 것이다. 그래서 애플리케이션을 다양한 관점에서 바라보며 개발할 수 있게 도와준다.
- 이렇게 애플리케이션을 특정한 관점을 기준으로 바라볼 수 있게 해준다는 의미에서 AOP를 관점 지향 프로그래밍이라고도 한다.
5.5. AOP 적용기술
5.5.1 프록시를 이용한 AOP
- 스프링은 IoC/DI 컨테이너와 다이내믹 프록시, 데코레이터 패턴, 프록시 패턴, 자동 프록시 생성 기법, 빈 오브젝트의 후처리 조작 기법 등의 다양한 기술을 조합해 AOP를 지원하고 있다. 그중 가장 핵심은 프록시를 이용했다는 것이다.
- 프록시로 만들어서 DI로 연결된 빈 사이에 적용해 타깃의 메서드 호출 과정에 참여해서 부가기능을 제공해주도록 만들었다.
- 따라서 스프링 AOP는 자바 기본 JDK와 스프링 컨테이너 외에는 특별한 기술이나 환경을 요구하지 않는다.
- 스프링 컨테이너인 애플리케이션 컨텍스트나 AOP는 특별한 환경이나 JVM 설정 등을 요구하지 않는다. 서버환경이라면 가장 기초적인 서블릿 컨테이너만으로도 충분하며, 원한다면 독립형 애플리케이션에서도 사용 가능하다.
- 스프링의 AOP의 부가기능을 담은 어드바이스가 적용되는 대상은 오브젝트의 메서드다. 프록시 방식을 사용했기 때문에 메서드 호출 과정에 참여해서 부가기능을 제공해주게 되어 있다.
- 어드바이스가 구현하는 MethodInterceptor 인터페이스는 다이내믹 프록시의 InvocationHandler와 마찬가지로 프록시로부터 메서드 요청정보를 전달받아서 타깃 오브젝트의 메서드를 호출한다. 타깃의 메서드를 호출하는 전후에 다양한 부가기능을 제공할 수 있다.
- 독립적으로 개발한 부가기능 모듈을 다양한 타깃 오브젝트의 메서드에 다이내믹하게 적용해주기 위해 가장 중요한 역할을 맡고 있는 게 바로 프록시다. 그래서 스프링 AOP는 프록시 방식의 AOP라고 할 수 있다.
5.5.2 바이트코드 생성과 조작을 통한 AOP
가장 강력한 AOP 프레임워크로 꼽히는 AspectJ는 프록시를 사용하지 않는 대표적인 AOP 기술이다. AspectJ는 스프링처럼 다이내믹 프록시 방식을 사용하지 않는다.
AspectJ는 프록시처럼 간접적인 방법이 아니라, 타깃 오브젝트를 뜯어고쳐서 부가기능을 직접 넣어주는 직접적인 방법을 사용한다. 타깃 오브젝트의 소스코드를 수정하진 않고, 컴파일된 타깃의 클래스 파일 자체를 수정하거나 클래스가 JVM에 로딩되는 시점을 가로채서 바이트코드를 조작하는 복잡한 방법을 사용한다. 트랜잭션 코드가 UserService 클래스에 비즈니스 로직과 함께 있었을 때처럼 만든다.
AspectJ는 프록시 방법을 놔두고 왜 컴파일된 클래스 파일 수정이나 바이트코드 조작을 하는 것일까?
-
바이트코드를 조작해서 타깃 오브젝트를 직접 수정해버리면 스프링과 같은 DI 컨테이너의 도움을 받아서 자동 프록시 생성 방식을 사용하지 않아도 AOP를 적용할 수 있기 때문이다.
스프링과 같은 컨테이너가 사용되지 않는 환경에서도 손쉽게 AOP의 적용이 가능해진다. -
프록시 방식보다 훨씬 강력하고 유연한 AOP가 가능하기 때문이다.
프록시를 AOP의 핵심 메커니즘으로 사용하면 부가기능을 부여할 대상은 클라이언트가 호출할 때 사용하는 메서드로 제한된다. 하지만 바이트코드를 직접 조작해서 AOP를 적용하면 오브젝트의 생성, 필드 값의 조회와 조작, 스태틱 초기화 등의 다양한 작업에 부가기능을 부여해줄 수 있다.
물론 대부분의 부가기능은 프록시 방식을 사용해 메서드의 호출 시점에 부여하는 것으로도 충분하다. 게다가 AspectJ 같은 고급 AOP 기술은 바이트코드 조작을 위해 JVM의 실행 옵션을 변경하거나, 별도의 바이트코드 컴파일러를 사용하거나, 특별한 클래스 로더를 사용하게 하는 등의 번거로운 작업이 필요하다. 따라서 특별한 AOP 요구사항이 생겨서 스프링의 프록시 AOP 수준을 넘어서는 기능이 필요하면, 그때 AspectJ를 사용하면 된다. 스프링 AOP를 기본적으로 사용하면서 동시에 AspectJ를 이용할 수도 있다.
5.6 AOP의 용어
AOP에서 많이 사용하는 몇 가지 용어를 살펴보자.
-
타깃
- 타깃은 부가기능을 부여할 대상이다.
- 핵심기능을 담은 클래스일 수도 있지만 경우에 따라 다른 부가기능을 제공하는 프록시 오브젝트일 수도 있다.
-
어드바이스
- 어드바이스는 타깃에게 제공할 부가기능을 담은 모듈이다.
- 어드바이스는 오브젝트로 정의하기도 하지만 메서드 레벨에서 정의할 수도 있다.
- 어드바이스의 종류
MethodInterceptor처럼 메서드 호출 과정에 전반적으로 참여하는 것- 예외가 발생했을 때만 동작하는 어드바이스처럼 메서드 호출 과정의 일부에서만 동작하는 것
-
조인 포인트(join point)
- 조인 포인트란 어드바이스가 적용될 수 있는 위치이다.
- 스프링의 프록시 AOP에서 조인 포인트는 메서드의 실행 단계뿐이다.
- 타깃 오브젝트가 구현한 인터페이스의 모든 메서드는 조인 포인트가 된다.
-
포인트컷
- 포인트컷이란 어드바이스를 적용할 조인 포인트를 선별하는 작업 또는 그 기능을 정의한 모듈을 말한다.
- 스프링 AOP의 조인 포인트는 메서드의 실행이므로 스프링의 포인트컷은 메서드를 선정하는 기능을 갖고 있다. 그래서 포인트컷 표현식은 메서드의 실행이라는 의미인
execution으로 시작하고, 메서드의 시그니처를 비교하는 방법을 주로 이용한다. - 메서드는 클래스 안에 존재하는 것이기 때문에 메서드 선정이란 결국 클래스를 선정하고 그 안의 메서드를 선정하는 과정을 거치게 된다.
-
프록시
- 클라이언트와 타깃 사이에 투명하게 존재하면서 부가기능을 제공하는 오브젝트다.
- DI를 통해 타깃 대신 클라이언트에게 주입되며, 클라이언트의 메서드 호출을 대신 받아서 타깃에 위임해주면서, 그 과정에서 부가기능을 부여한다.
- 스프링은 프록시를 이용해 AOP를 지원한다.
-
어드바이저
- 포인트컷과 어드바이스를 하나씩 갖고 있는 오브젝트다.
- 어드바이저는 어떤 부가기능(어드바이스)을 어디에(포인트컷) 전달할 것인가를 알고 있는 AOP의 가장 기본이 되는 모듈이다.
- 스프링은 자동 프록시 생성기가 어드바이저를 AOP 작업의 정보로 활용한다.
- 어드바이저는 스프링 AOP에서만 사용되는 특별한 용어이고, 일반적인 AOP에서는 사용되지 않는다.
-
애스펙트
- AOP의 기본 모듈이다.
- 한 개 또는 그 이상의 포인트컷과 어드바이스의 조합으로 만들어지며 보통 싱글톤 형태의 오브젝트로 존재한다. 따라서 클래스와 같은 모듈 정의와 오브젝트와 같은 실체(인스턴스)의 구분이 특별히 없다. 두 가지 모두 애스펙트라고 불린다.
- 스프링의 어드바이저는 아주 단순한 애스펙트라고 볼 수도 있다.
5.7 AOP 네임스페이스
스프링 AOP를 적용하기 위해 추가했던 어드바이저, 포인트컷, 자동 프록시 생성기 같은 빈들은 비즈니스 로직이나 DAO처럼 애플리케이션의 일부 기능을 담고 있는 것도 아니고, DI를 통해 애플리케이션 빈에서 사용되는 것도 아니다.
이런 빈들은 스프링 컨테이너에 의해 자동으로 인식돼서 특별한 작업을 위해 사용된다. 스프링의 프록시 방식 AOP를 적용하려면 최소한 네 가지 빈을 등록해야 한다.
- 자동 프록시 생성기
- 스프링의
DefaultAdvisorAutoProxyCreator클래스를 빈으로 등록한다. - 다른 빈을 DI 하지도 않고 자신도 DI 되지 않으며 독립적으로 존재한다. 따라서 id도 굳이 필요하지 않다.
- 애플리케이션 컨텍스트가 빈 오브젝트를 생성하는 과정에 빈 후처리기로 참여한다.
- 빈으로 등록된 어드바이저를 이용해서 프록시를 자동으로 생성하는 기능을 담당한다.
- 어드바이스
- 부가기능을 구현한 클래스를 빈으로 등록한다.
TransactionAdvice는 AOP 관련 빈 중에서 유일하게 직접 구현한 클래스를 사용한다.
- 포인트컷
- 스프링의
AspectJExpressionPointcut을 빈으로 등록하고expression프로퍼티에 포인트컷 표현식을 넣어주면 된다. 코드를 작성할 필요는 없다.
- 어드바이저
- 스프링의
DefaultPointcutAdvisor클래스를 빈으로 등록해서 사용한다. - 어드바이스와 포인트컷을 프로퍼티로 참조하는 것 외에 기능은 없다.
- 자동 프록시 생성기에 의해 자동 검색되어 사용된다.
이 중에서 부가기능을 담은 코드로 만든 어드바이스를 제외한 나머지는 모두 스프링이 직접 제공하는 클래스를 빈으로 등록하고 프로퍼티 설정만 해준 것이다.
5.7.1 AOP 네임스페이스
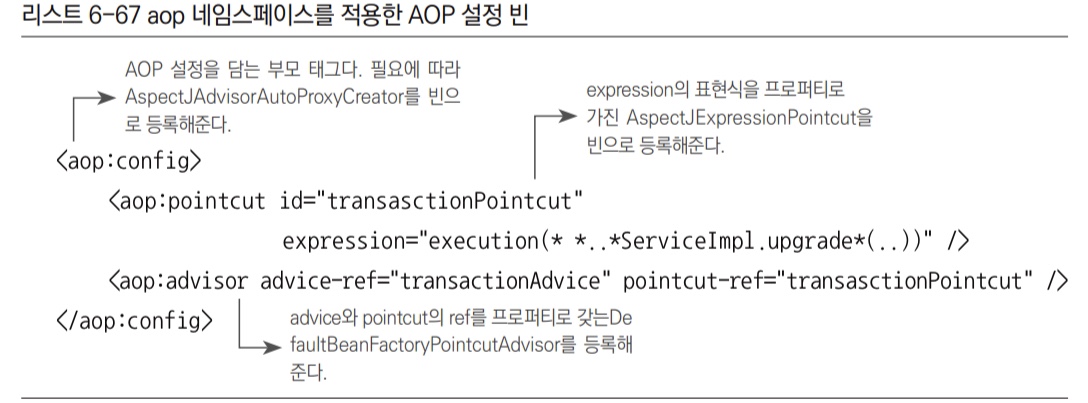
스프링에서는 AOP를 위해 기계적으로 적용하는 빈들을 간편하게 등록할 수 있도록 AOP와 관련된 태그를 정의해둔 aop 스키마를 제공한다.
aop 스키마 활용
- aop 스키마에 정의된 태그는 별도의 네임스페이스를 지정해서 디폴트 네임스페이스의
<bean>태그와 구분해서 사용할 수 있다.aop스키마에 정의된 태그를 사용하려면 설정파일에aop네임스페이스 선언을 설정파일에 추가해줘야 한다.

aop네임스페이스를 이용해 AOP 관련 빈 설정을 할 수 있다.
<aop:config>,<aop:pointcut>,<aop:advisor>세 가지 태그를 정의해두면 그에 따라 세 개의 빈이 자동으로 등록된다.- 포인트컷, 어드바이저, 자동 포인트컷 생성기 같은 특별한 기능을 가진 빈들은 별도의 스키마에 정의된 전용 태그를 사용해 정의해주면 편리하다.
- 애플리케이션을 구성하는 컴포넌트 빈과 컨테이너에 의해 사용되는 기반 기능을 지원하는 빈은 구분이 되는 것이 좋다.
- 직접 구현한 클래스로 등록한 빈인
transactionAdvice를 제외한 AOP 관련 빈들은 의미를 잘 드러내는 독립된 전용 태그를 사용하도록 권장된다.
5.7.2 어드바이저 내장 포인트컷
- AspectJ 포인트컷 표현식을 활용하는 포인트컷은 스트링으로 된 표현식을 담은
expression프로퍼티 하나만 설정해주면 사용할 수 있다. - 포인트컷은 어드바이저에 참조돼야만 사용한다. 그래서 aop 스키마의 전용 태그를 사용하는 경우에는 굳이 포인트컷을 독립적인 태그로 두고 어드바이저 태그에서 참조하는 대신 어드바이저 태그와 결합하는 방법도 가능하다.
- 포인트컷을 내장하는 경우엔
<aop:advisor>태그 하나로 두 개의 빈이 등록된다.
- 포인트컷을 내장하는 경우엔
- 하지만 하나의 포인트컷을 여러 개의 어드바이저에서 공유하려고 하는 경우엔 포인트컷을 독립적인
<aop:pointcut>태그로 등록해야 한다. - 전용 스키마를 갖는 태그는 한 번에 하나 이상의 빈을 등록할 수 있다.
<aop:advisor>처럼 애트리뷰트 설정에 따라 등록되는 빈의 개수와 종류가 달라질 수도 있다. 또한 서버환경이나 클래스패스에 존재하는 라이브러리에 따라서 등록되는 빈이 달라지는 경우도 있다.

6. 트랜잭션 속성
트랜잭션 매니저에서 트랜잭션을 가져올 때 사용한 efaultTransactionDefinition 오브젝트를 보자.
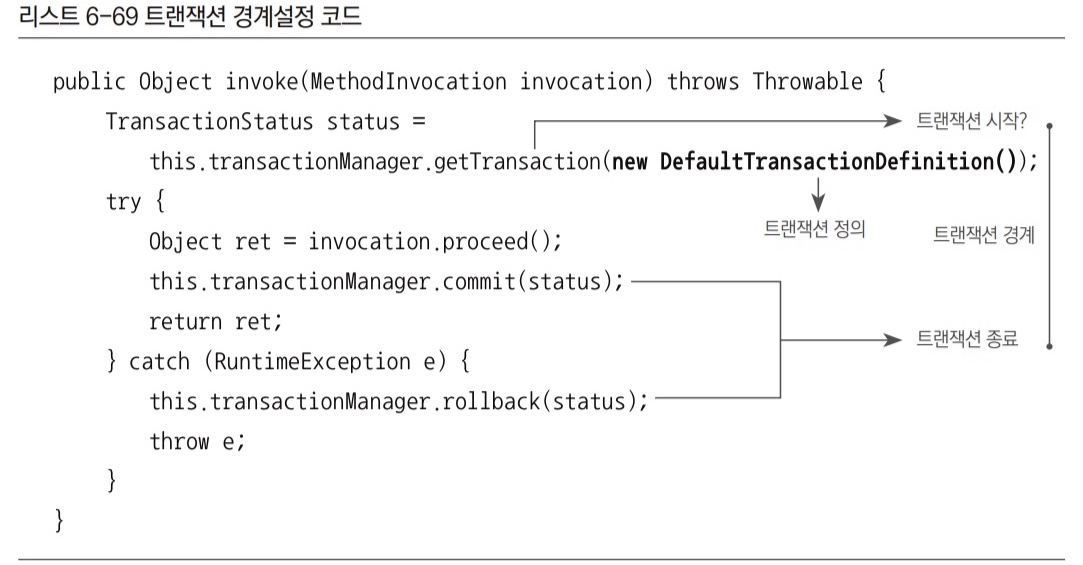
6.1 트랜잭션 정의
트랜잭션은 더 이상 쪼갤 수 없는 최소 단위의 작업이다. 따라서 트랜잭션 경계 안에서 진행된 작업은 commit()을 통해 모두 성공하든지 아니면 rollback()을 통해 모두 취소돼야 한다. 그런데 이 밖에도 트랜잭션의 동작방식을 제어할 수 있는 몇 가지 조건이 있다.
DefaultTransactionDefinition이 구현하고 있는 TransactionDefinition 인터페이스는 트랜잭션의 동작방식에 영향을 줄 수 있는 네 가지 속성을 정의하고 있다.
6.1.1 트랜잭션 전파
트랜잭션 전파(transaction propagation)란 트랜잭션의 경계에서 이미 진행 중인 트랜잭션이 있을 때 또는 없을 때 어떻게 동작할 것인가를 결정하는 방식을 말한다.
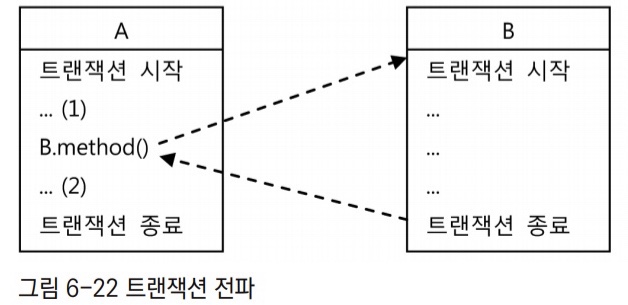
트랜잭션 전파와 같이 각각 독립적인 트랜잭션 경계를 가진 두 개의 코드가 있다고 하자. 그런데 A의 트랜잭션이 시작되고 아직 끝나지 않은 시점에서 B를 호출했다면 B의 코드는 어떤 트랜잭션 안에서 동작해야 할까?
- A에서 트랜잭션이 진행 중이라면 B의 코드는 새로운 트랜잭션을 만들지 않고 A에서 이미 시작한 트랜잭션에 참여할 수 있다.
- 이 경우 B를 호출한 작업까지 마치고 (2)의 코드를 진행하던 중에 예외가 발생하면, A와 B가 하나의 트랜잭션으로 묶여있기 때문에 A와 B의 코드에서 진행했던 모든 DB 작업이 다 취소된다.
- B의 트랜잭션을 이미 앞에서 시작한 A의 트랜잭션과 무관하게 독립적인 트랜잭션으로 만들 수 있다.
- 이 경우 B의 트랜잭션 경계를 빠져나오는 순간 B의 트랜잭션은 독자적으로 커밋 또는 롤백될 것이고, A 트랜잭션은 그에 영향을 받지 않고 진행될 것이다.
- 만약 이후에 A의 (2)에서 예외가 발생해서 A의 트랜잭션은 롤백되는 경우에라도 B에서 이미 종료된 트랜잭션의 결과에는 영향을 주지 않는다.
대표적인 트랜잭션 전파 속성
-
PROPAGATION_REQUIRED
- 가장 많이 사용되는 트랜잭션 전파 속성이다.
- 진행 중인 트랜잭션이 없으면 새로 시작하고, 이미 시작된 트랜잭션이 있으면 이에 참여한다.
- PROPAGATION_REQUIRED 트랜잭션 전파 속성을 갖는 코드는 다양한 방식으로 결합해서 하나의 트랜잭션으로 구성하기 쉽다. A와 B가 모두 PROPAGATION_REQUIRED로 선언되어 있다면, A, B, A->B, B->A와 같은 네 가지의 조합된 트랜잭션이 모두 가능하다.
- DefaultTransactionDefinition의 트랜잭션 전파 속성이다.
-
PROPAGATION_REQUIRES_NEW
- 항상 새로운 트랜잭션을 시작한다. 즉, 앞에서 시작된 트랜잭션이 있든 없든 상관없이 새로운 트랜잭션을 만들어서 독자적으로 동작하게 한다.
- 독립적인 트랜잭션이 보장돼야 하는 코드에 적용할 수 있다.
-
PROPAGATION_NOT_SUPPORTED
- 이 속성을 사용하면 트랜잭션 없이 동작하도록 만들 수 있다. 진행 중인 트랜잭션이 있어도 무시한다.
- 트랜잭션을 무시하는 속성을 두는 데는 이유가 있다.
- 트랜잭션 경계설정은 보통 AOP를 이용해 한 번에 많은 메서드에 동시에 적용하는 방법을 사용한다. 그런데 그 중에서 특별한 메서드만 트랜잭션 적용에서 제외하려면 어떻게 해야 할까?
- 물론 포인트컷을 잘 만들어서 특정 메서드가 AOP 적용 대상이 되지 않게 하는 방법도 있겠지만 포인트컷이 상당히 복잡해질 수 있다.
- 그래서 차라리 모든 메서드에 트랜잭션 AOP가 적용되게 하고, 특정 메서드의 트랜잭션 전파 속성만 PROPAGATION_NOT_SUPPORTED로 설정해서 트랜잭션 없이 동작하게 만드는 편이 낫다.
getTransaction()
- 트랜잭션 매니저를 통해 트랜잭션을 시작하려고 할 때
getTransation()이라는 메서드를 사용하는 이유는 바로 이 트랜잭션 전파 속성이 있기 때문이다. - 트랜잭션 매니저의
getTransaction()메서드는 항상 트랜잭션을 새로 시작하는 것이 아니다. - 트랜잭션 전파 속성과 현재 진행 중인 트랜잭션이 존재하는지 여부에 따라 새로운 트랜잭션을 시작할 수도 있고, 이미 진행 중인 트랜잭션에 참여하기만 할 수도 있다.
- 진행 중인 트랜잭션에 참여하는 경우는 트랜잭션 경계의 끝에서 트랜잭션을 커밋시키지도 않는다. 최초로 트랜잭션을 시작한 경계까지 정상적으로 진행돼야 비로소 커밋될 수 있다.
6.1.2 격리수준
- 모든 DB 트랜잭션은 격리수준(isolation level)을 갖고 있어야 한다.
- 서버환경에서는 여러 개의 트랜잭션이 동시에 진행될 수 있다.
- 모든 트랜잭션이 순차적으로 진행되어 다른 트랜잭션 작업에 독립적인 것이 좋겠지만, 그러면 성능이 크게 떨어진다.
- 따라서 적절하게 격리수준을 조정해서 가능한 한 많은 트랜잭션을 동시에 진행시키면서도 문제가 발생하지 않게 하는 제어가 필요하다.
- 격리수준은 기본적으로 DB에 설정되어 있지만 JDBC 드라이버나
DataSource등에서 재설정할 수 있고, 필요하다면 트랜잭션 단위로 격리수준을 조정할 수 있다. DefaultTransactionDefinition에 설정된 격리수준은ISOLATION_DEFAULT로,DataSource에 설정되어 있는 디폴트 격리수준을 그대로 따른다는 뜻이다.- 기본적으로는 DB나
DataSource에 설정된 디폴트 격리수준을 따르는 편이 좋겠지만, 특별한 작업을 수행하는 메서드의 경우는 독자적인 격리수준을 지정할 필요가 있다.
6.1.3 제한시간
- 트랜잭션을 수행하는 제한시간(timeout)를 설정할 수 있다.
DefaultTransactionDefinition의 기본 설정은 제한시간이 없는 것이다.- 제한시간은 트랜잭션을 직접 시작할 수 있는 PROPAGATION_REQUIRED나 PROPAGATION_REQUIRES_NEW와 함께 사용해야만 의미가 있다.
6.1.4 읽기전용
- 읽기전용(read only)으로 설정해두면 트랜잭션 내에서 데이터를 조작하는 시도를 막아줄 수 있다. 또한 데이터 액세스 기술에 따라서 성능이 향상될 수도 있다.
-TransactionDefinition타입 오브젝트를 사용하면 네 가지 속성을 이용해 트랜잭션의 동작방식을 제어할 수 있다.TransactionDefinition오브젝트를 생성하고 사용하는 코드는 트랜잭션 경계설정 기능을 가진TransactionAdvice다.- 트랜잭션 정의를 수정하려면 외부에서 정의된
TransactionDefinition오브젝트를 DI 받아서 사용하도록 만들면 된다. TransactionDefinition타입의 빈을 정의해두면 프로퍼티를 통해 원하는 속성을 지정해줄 수 있다.- 하지만 이 방법으로 트랜잭션 속성을 변경하면
TransactionAdvice를 사용하는 모든 트랜잭션의 속성이 한꺼번에 바뀐다는 문제가 있다.
6.2 트랜잭션 인터셉터와 트랜잭션 속성
메서드별로 다른 트랜잭션 정의를 적용하려면 어드바이스의 기능을 확장해야 한다. 메서드 이름 패턴에 따라 트랜잭션 정의가 적용되도록 만드는 것이다.
6.2.1 `TransactionInterceptor
- 스프링에선 편리하게 트랜잭션 경계설정 어드바이스로 사용할 수 있도록 만들어진
TransactionInterceptor가 존재한다. TransactionInterceptor어드바이스의 동작방식은 기존에 만들었던TransactionAdvice에서, 트랜잭션 정의를 메서드 이름 패턴을 이용해서 다르게 지정할 수 있는 방법을 추가로 제공해줄 뿐이다.TransactionInterceptor는PlatformTransactionManager와Properties타입의 두 가지 프로퍼티를 갖고 있다.Properties타입인 프로퍼티의 이름은transcationAttribute로, 트랜잭션 속성을 정의한 프로퍼티다.- 트랜잭션 속성은
TransactionDefinition의 네 가지 기본 항목에rollbackOn()메서드를 하나 더 갖고 있는TransactionAttribute인터페이스로 정의된다. rollbackOn()메서드는 어떤 예외가 발생하면 롤백을 할 것인가를 결정하는 메서드다.- 이
TransactionAttribute를 이용하면 트랜잭션 부가기능의 동작방식을 모두 제어할 수 있다.
- 트랜잭션 속성은
TransactionInterceptor와 TransactionAttribute
TransactionAdvice는RuntimeException이 발생하는 경우에만 트랜잭션을 롤백시킨다. 하지만 런타임 예외가 아닌 경우에는 트랜잭션이 제대로 처리되지 않고 메서드를 빠져나가게 되어 있다. 만약 체크 예외를 던지는 타깃에 사용한다면 문제가 될 수 있다.- 런타임 예외만이 아니라 모든 종류의 예외에 대해 트랜잭션을 롤백시키도록 해야 할까? 그래선 안 된다.
- 비즈니스 로직상의 예외 경우를 나타내기 위해 타깃 오브젝트가 체크 예외를 던지는 경우에는 DB 트랜잭션은 커밋시켜야 하기 때문이다.
- 스프링이 제공하는
TransactionInterceptor에는 기본적으로 두 가지 종류의 예외처리 방식이 있다.- 런타임 예외가 발생하면 트랜잭션은 롤백된다.
- 반면에 타깃 메서드가 런타임 예외가 아닌 체크 예외를 던지는 경우에는 이것을 예외상황으로 해석하지 않고 일종의 비즈니스 로직에 따른, 의미가 있는 리턴 방식의 한 가지로 인식해서 트랜잭션을 커밋해버린다.
- 스프링의 기본적인 예외처리 원칙에 따라 비즈니스적인 의미가 있는 예외상황에만 체크 예외를 사용하고, 그 외의 모든 복구 불가능한 순수한 예외의 경우는 런타임 예외로 포장돼서 전달하는 방식을 따른다고 가정하기 때문이다.
TransactionInterceptor의 예외처리 기본 원칙을 따르지 않는 경우가 있으면,TransactionAttribute는rollbackOn()이라는 속성을 둬서 기본 원칙과 다른 예외처리가 가능하게 해준다- 이를 활용하면 특정 체크 예외의 경우는 트랜잭션을 롤백시키고, 특정 런타임 예외에 대해서는 커밋시킬 수도 있다.
TransactionInterceptor는 이런TranscationAttribute를Properties라는 일종의 맵 타입 오브젝트로 전달받는다. 컬렉션은 메서드 패턴에 따라서 각기 다른 트랜잭션 속성을 부여할 수 있게 하기 위해서 사용한다.
6.2.2 메서드 이름 패턴을 이용한 트랜잭션 속성 지정
Properties 타입의 transactionAttibutes 프로퍼티는 메서드 패턴과 트랜잭션의 속성을 키와 값으로 갖는 컬렉션이다.
트랜잭션 속성 정의
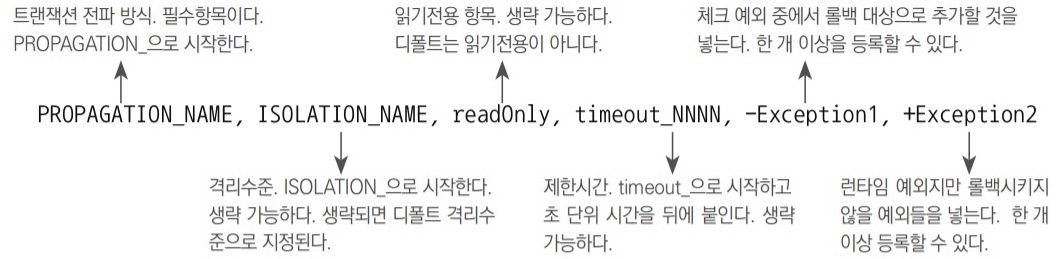
- 트랜잭션 전파 항목 제외하고 나머지는 다 생략 가능하다.
- 생략하면 모두
DefaultTransactionDefinition에 설정된 디폴트 속성이 부여된다. - 모든 항목이 구분 가능하기 때문에 순서는 바꿔도 상관없다.
- +/- 로 시작하는 건 기본 원칙을 따르지 않는 예외를 정해주는 것이다.
- 모든 런타임 예외는 롤백돼야 하지만
+XXXRuntimeException이라고 해주면 런타임 예외라도 커밋하게 만들 수 있다. - 체크 예외는 모두 커밋하는 것이 기본 처리 방식이지만 -를 붙여서 넣어주면 트랜잭션은 롤백 대상이 된다.
- 모든 런타임 예외는 롤백돼야 하지만
메서드 이름 패턴과 문자열로 된 트랜잭션 속성을 이용해 정의한 TransactionInterceptor 타입 빈

- 세 가지 메서드 이름 패턴에 대한 트랜잭션 속성이 정의되어 있다.
- 이름이
get으로 시작하는 메서드에 대한 속성
PROPAGATION_REQUIRED, 읽기전용, 시간제한 30초- 보통 읽기전용 메서드는
get또는find같은 일정한 이름으로 시작한다. 명명 규칙을 잘 정해두면 조회용 메서드의 트랜잭션은 읽기용으로 설정해서 성능을 향상시킬 수 있다. - 읽기전용이 아닌 트랜잭션 속성을 가진 메서드에서 읽기전용 속성을 가진
get으로 시작하는 메서드를 호출하면?get메서드는ROPAGATION_REQUIRED이기 때문에 다른 트랜잭션이 시작되어 있으면 그 트랜잭션에 참가한다. - 이미 DB에 쓰기 작업이 진행된 채로 읽기전용 트랜잭션 속성을 가진 작업이 뒤따르게 돼서 충돌이 일어나진 않을까? 트랜잭션 속성 중
readOnly나timeout등은 트랜잭션이 처음 시작될 때가 아니라면 적용되지 않는다. 따라서get으로 시작하는 메서드에서 트랜잭션이 시작하는 경우라면 읽기전용에 제한시간이 적용되지만 그 외의 경우에는 진행 중인 트랜잭션의 속성을 따르게 되어 있다.
upgrade로 시작하는 메서드에 대한 속성
PROPAGATION_REQUIRES_NEW,ISOLATION_SERIALIZABLEPROPAGATION_REQUIRES_NEW: 항상 독립적인 트랜잭션으로 동작한다.ISOLATION_SERIALIZABLE: 다른 동시 작업에 영향 받지 않도록 완벽하게 고립된 상태에서 트랜잭션이 동작하도록 한다.
*만 사용해서 위의 두 가지 조건에 해당하지 않는 나머지 모든 메서드에 대한 속성
- 필수항목인
PROPAGATION_REQUIRED만 지정하고 나머지는 디폴트 설정을 따르게 했다.
📌 메서드 이름이 하나 이상의 패턴과 일치하면, 메서드 이름 패턴 중에서 가장 정확히 일치하는 것이 적용된다.
6.2.3 tx 네임스페이스를 이용한 설정 방법
TransactionInterceptor 타입의 어드바이스 빈과 TransactionAttribute 타입의 속성 정보도 tx 스키마의 전용 태그를 이용해 정의할 수 있다. 트랜잭션 어드바이스도 포인트컷이나 어드바이저만큼 자주 사용되고, 애플리케이션의 컴포넌트가 아닌 컨테이너가 사용하는 기반기술 설정의 한 가지이기 때문이다.
TransactionInterceptor 빈으로 정의한 트랜잭션 어드바이스와 메서드 패턴에 따른 트랜잭션 속성 지정은 tx 스키마의 태그를 이용해 간단하게 정의할 수 있다.

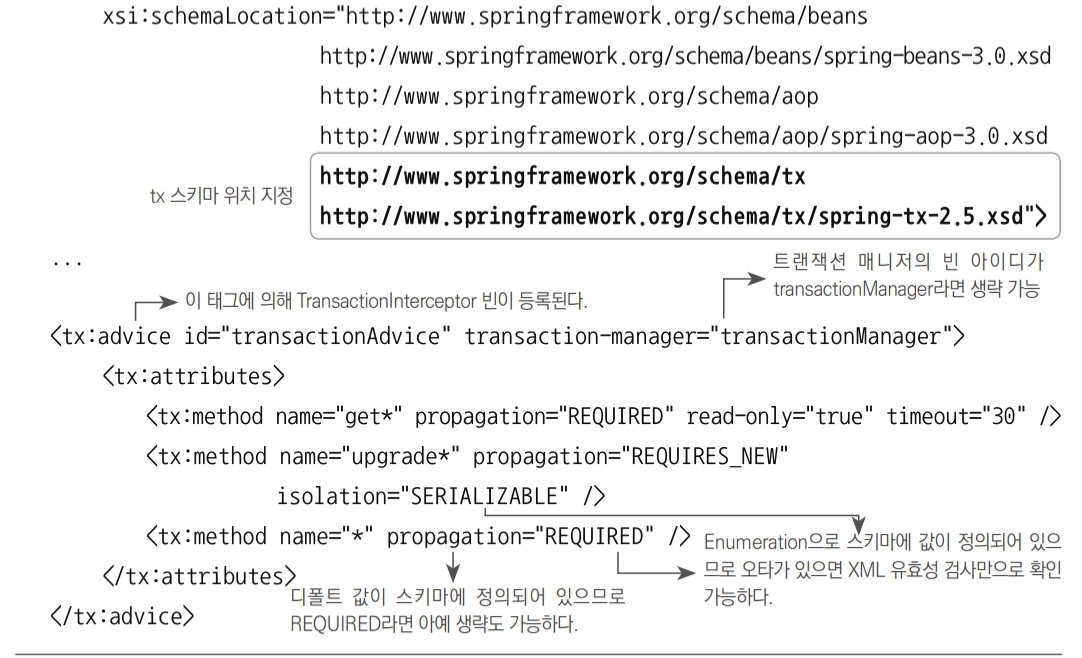
- 트랜잭션 속성이 개별 애트리뷰트를 통해 지정될 수 있으므로 설정 내용을 읽기가 좀 더 쉽고, XML 에디터의 자동완성 기능을 통해 편하게 작성할 수 있다.
- 문자열로 입력할 때 오타 문제도 XML 스키마에 미리 등록해둔 값을 통해 검증할 수 있어서 편리하다.
<bean>태그로 등록하는 경우에 비해 장점이 많아서tx스키마의 태그를 사용해 어드바이스를 등록하도록 권장한다.
6.3 포인트컷과 트랜잭션 속성의 적용 전략
- 트랜잭션 부가기능을 적용할 후보 메서드를 선정하는 작업은 포인트컷에 의해 진행된다.
- 어드바이스의 트랜잭션 전파 속성에 따라서 메서드별로 트랜잭션의 적용 방식이 결정된다.
aop와tx스키마의 전용 태그를 사용한다면 애플리케이션의 어드바이저, 어드바이스, 포인트컷 기본 설정 방법은 바뀌지 않을 것이다.expression애트리뷰트에 넣는 포인트컷 표현식과<tx:attributes>로 정의하는 트랜잭션 속성만 결정하면 된다.
포인트컷 표현식과 트랜잭션 속성을 정의할 때 따르면 좋은 몇 가지 전략을 생각해보자.
6.3.1 트랜잭션 포인트컷 표현식은 타입 패턴이나 빈 이름을 이용한다
- 일반적으로 트랜잭션을 적용할 타깃 클래스의 메서드는 모두 트랜잭션 적용 후보가 되는 것이 바람직하다.
- 비즈니스 로직을 담고 있는 클래스라면 메서드 단위까지 세밀하게 포인트컷을 정의해줄 필요는 없다.
UserService의add()메서드도 트랜잭션 적용 대상이어야 한다.- 트랜잭션 전파 방식을 생각해보면
add()는 다른 트랜잭션에 참여할 가능성이 높다. add()메서드를 보면,serDao.add()를 호출해서 사용자 정보를 DB에 추가하는 것 외에도 DB의 정보를 다루는 작업이 추가될 가능성이 높다.- 따라서
add()메서드는 트랜잭션 안에서 동작하도록 정의하는 게 바람직하다.
- 트랜잭션 전파 방식을 생각해보면
- 쓰기 작업이 없는 단순한 조회 작업만 하는 메서드에도 모두 트랜잭션을 적용하는 게 좋다.
- 조희의 경우엔 읽기전용으로 트랜잭션 속성을 설정해두면 그만큼 성능의 향상을 가져올 수 있다.
- 복잡한 조회의 경우는 제한시간을 지정해줄 수도 있고, 격리수준에 따라 조회도 반드시 트랜잭션 안에서 진행해야 할 필요가 발생하기도 한다.
- 따라서 트랜잭션용 포인트컷 표현식에는 메서드나 파리미터, 예외에 대한 패턴을 정의하지 않는 게 바람직하다.
- 트랜잭션의 경계로 삼을 클래스들이 선정됐다면, 그 클래스들이 모여 있는 패키지를 통째로 선택하거나 클래스 이름에서 일정한 패턴을 찾아서 표현식으로 만들면 된다.
- 관례적으로 비즈니스 로직 서비스를 담당하는 클래스 이름은
Service또는ServiceImpl이라고 끝나는 경우가 많은데 그런 경우라면execution(**..*ServiceImpl.*(..))과 같이 타입 패턴을 적용하는 것이 좋다. 인터페이스는 클래스에 비해 변경 빈도가 적고 일정한 패턴을 유지하기 쉽기 때문이다.
- 메서드의 시그니처를 이용한
execution()방식의 포인트컷 표현식 대신 스프링의 빈 이름을 이용하는bean()표현식을 사용하는 방법도 고려해볼 만하다.bean()표현식은 빈 이름을 기준으로 선정하기 때문에 클래스나 인터페이스 이름에 일정한 규칙을 만들기가 어려운 경우에 유용하다.- 포인트컷 표현식 자체가 간단해서 읽기 편하다는 장점도 있다.
- 빈의 아이디가
Service로 끝나는 모든 빈에 대해 트랜잭션을 적용하고 싶다면 포인트컷 표현식을bean(*Service)라고 하면 된다. 이름이 비슷한 다른 빈이 있는 경우 주의해야 한다.
- 그 외에 애노테이션을 이용한 포인트컷 표현식을 만드는 방법이 있다.
6.3.2 공통된 메서드 이름 규칙을 통해 최소한의 트랜잭션 어드바이스와 속성을 정의한다
- 실제로 하나의 애플리케이션에서 사용할 트랜잭션 속성의 종류는 다양하지 않다. 너무 다양하게 부여하면 관리만 함들어진다.
- 따라서 기준이 되는 몇 가지 트랜잭션 속성을 정의하고 그에 따라 적절한 메서드 명명 규칙을 만들어두면 하나의 어드바이스만으로 애플리케이션의 모든 서비스 빈에 트랜잭션 속성을 지정할 수 있다.
- 가끔 트랜잭션 속성의 적용 패턴이 일반적인 경우와 크게 다른 오브젝트가 존재하기도 한다. 이런 예외적인 경우는 트랜잭션 어드바이스와 포인트컷을 새롭게 추가해줄 필요가 있다.
- 가장 간단한 트랜잭션 속성 부여 방법은 모든 메서드에 대해 디폴트 속성을 지정하는 것이다. 일단 트랜잭션 속성의 종류와 메시지 패턴이 결정되지 않았으면 가장 단순한 디폴트 속성부터 하면 된다. 개발이 진행됨에 따라 단계적으로 속성을 추가해주면 된다.

- 디폴트 속성을 일괄적으로 부여한 후, 간단한 메서드 이름의 패턴을 적용해볼 수 있다.
- ex) 조회용 메서드에 대해 읽기전용 속성을 준 것이다.
get또는find와 같이 조회전용 메서드의 접두어를 정해두는 것이 좋다.

- 트랜잭션 적용 대상 클래스의 메서드는 일정한 명명 규칙을 따르게 해야 한다.
- 일반화하기에는 적당하지 않은 특별한 트랜잭션 속성이 필요한 타깃 오브젝트에 대해서는 별도의 어드바이스와 포인트컷 표현식을 사용하는 편이 좋다.
- ex) 두 개의 포인트컷과 어드바이스를 적용했다.
- 비즈니스 로직을 정의한 서비스 빈에는 기본적인 메서드 이름 패턴을 따르는 트랜잭션을 지정해둔다.
- 반면에 트랜잭션의 성격이 많이 다른 배치 작업용 클래스를 위해서는 트랜잭션 어드바이스를 별도로 정의해서 독자적인 트랜잭션 속성을 지정해준다.

6.3.3 (주의) 프록시 방식 AOP는 같은 타깃 오브젝트 내의 메서드를 호출할 때는 적용되지 않는다
- 프록시 방식의 AOP에서는 프록시를 통한 부가기능의 적용은 클라이언트로부터 호출이 일어날 때만 가능하다.
- 여기서 클라이언트는 인터페이스를 통해 타깃 오브젝트를 사용하는 다른 모든 오브젝트를 말한다.
- 반대로 타깃 오브젝트가 자기 자신의 메서드를 호출할 때는 프록시를 통한 부가기능의 적용이 일어나지 않는다.
- ex) 트랜잭션 프록시가 타깃에 적용되어 있는 경의 메서드 호출 과정
delete()와update()는 모두 트랜잭션 적용 대상인 메서드다.- [1], [3] 처럼 클라이언트로부터 메서드가 호출되면 트랜잭션 프록시를 통해 타깃 메서드로 호출이 전달되므로 트랜잭션 경계설정 부가기능이 부여될 것이다.
- [2]는 일단 타깃 오브젝트 내로 들어와서 타깃 오브젝트의 다른 메서드를 호출하는 경우에는 프록시를 거치지 않고 직접 타깃의 메서드가 호출된다.
- 만약
update()메서드에 트랜잭션 전파 속성을REQUIRES_NEW고 해놨더라도 같은 타깃 오브젝트에 있는delete()메서드를 통해update()가 호출되면 트랜잭션 전파 속성이 적용되지 않으므로REQUIRES_NEW는 무시되고 프록시의delete()메서드에서 시작한 트랜잭션에 단순하게 참여하게 될 뿐이다. - 또는 트랜잭션이 아예 적용되지 않는 타깃의 다른 메서드에서
update()가 호출된다면 그때는 트랜잭션이 없는 채로update()메서드가 실행될 것이다.
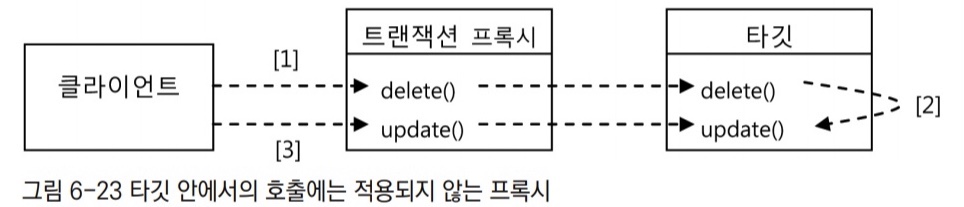
- 타깃 안에서의 호출에는 프록시가 적용되지 않는 문제를 해결할 수 있는 방법은 두 가지가 있다.
- 스프링 API를 이용해 프록시 오브젝트에 대한 레퍼런스를 가져온 뒤에 같은 오브젝트의 메서드 호출도 프록시를 이용하도록 강제하는 방법이다.
순수한 비즈니스 로직에 스프링 API와 프록시 호출 코드가 등장하기 때문에 별로 추천되지 않는다. - AspectJ와 같은 타깃의 바이트코드를 직접 조작하는 방식의 AOP 기술을 적용하는 것이다.
스프링은 프록시 기반의 AOP를 기본적으로 사용하고 있지만 필요하면 언제든지 간단한 옵션을 바꿈으로써 AspectJ 방식으로 트랜잭션 AOP가 적용되게 변경할 수 있다. 하지만 그만큼 다른 불편도 뒤따르기 때문에 꼭 필요한 경우에만 사용해야 한다.
- 스프링 API를 이용해 프록시 오브젝트에 대한 레퍼런스를 가져온 뒤에 같은 오브젝트의 메서드 호출도 프록시를 이용하도록 강제하는 방법이다.
6.4 트랜잭션 속성 적용
트랜잭션 속성과 그에 따른 트랜잭션 전략을 UserService에 적용해보자.
6.4.1 트랜잭션 경계설정의 일원화
- 일반적으로 특정 계층의 경계를 트랜잭션 경계와 일치시키는 것이 바람직하다. 비즈니스 로직을 담고 있는 서비스 계층 오브젝트의 메서드가 트랜잭션 경계를 부여하기에 가장 적절한 대상이다.
- 서비스 계층을 트랜잭션 경계로 정했다면, 테스트와 같은 특별한 이유가 아니고서는 다른 계층이나 모듈에서 DAO에 직접 접근하는 것은 차단해야 한다.
- 트랜잭션은 보통 서비스 계층의 메서드 조합을 통해 만들어지기 때문에 DAO가 제공하는 주요 기능은 서비스 계층에 위임 메서드를 만들어둘 필요가 있다.
- 안전하게 사용하려면 다른 모듈의 DAO에 접근할 때는 서비스 계층을 통해 접근하는 방법이 좋다.
ex)UserService가 아니라면UserDao에 직접 접근하지 않고UserService의 메서드를 이용하는 편이 좋다. - 순수한 조회나 간단한 수정이라면
UserService외의 서비스 계층 오브젝트에서UserDao를 직접 사용해도 상관없다. - 하지만 등록이나 수정, 삭제가 포함된 작업이라면 다른 모듈의 DAO를 직접 이용할 때 신중을 기해야 한다.
- 안전하게 사용하려면 다른 모듈의 DAO에 접근할 때는 서비스 계층을 통해 접근하는 방법이 좋다.
- 아키텍처를 단순하게 가져가면 서비스 계층과 DAO가 통합될 수도 있다.
- 비즈니스 로직이 거의 없고 단순 DB 입출력과 검색 수준의 조회가 전부라면 서비스 계층을 없애고 DAO를 트랜잭션 경계로 만드는 것이다.
- 하지만 비즈니스 로직을 독자적으로 두고 테스트하려면 서비스 계층을 만들어 사용해야 한다.
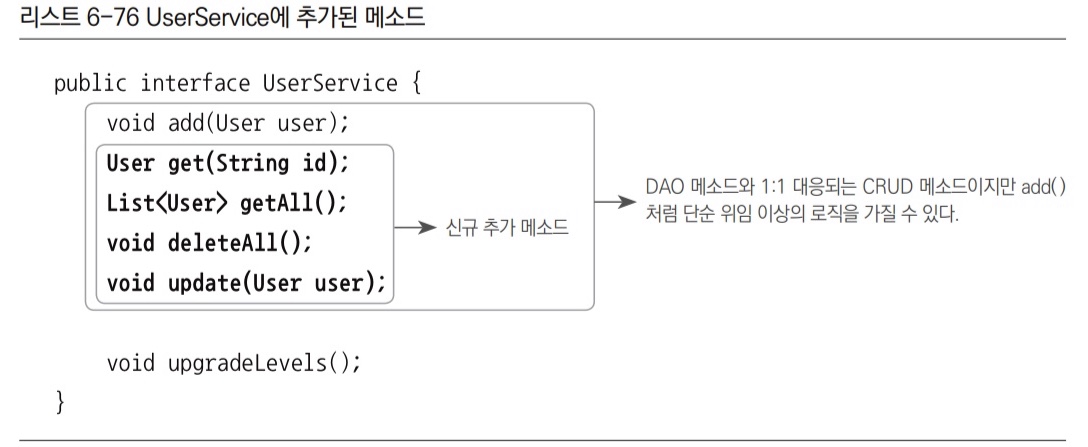
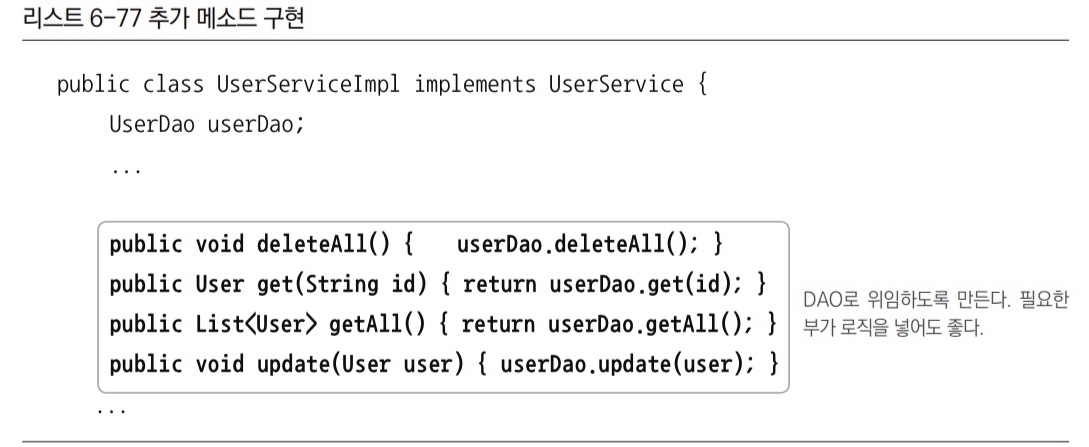
UserService 메서드 추가
UserDao인터페이스에 정의된 6개의 메서드 중 이미 서비스 계충에 부가적인 로직을 담아서 추가한add()를 제외한 나머지가UserService에 새로 추가할 후보 메서드다.- 이 중 단순히 레코드 개수를 리턴하는
getCount()를 제외하면 나머지는 독자적인 트랜잭션을 가지고 사용될 가능성이 높다. UserServiceImpl클래스에 추가된 4개의 메서드 구현 코드를 넣어준다.- 이제 모든 User 관련 데이터 조작은
UserService라는 트랜잭션 경계를 통해 진행할 경우 모두 트랜잭션을 적용할 수 있다.
6.4.2 서비스 빈에 적용되는 포인트컷 표현식 등록
upgradeLevels()에만 트랜잭션이 적용되게 했던 기존 포인트컷 표현식을 모든 비즈니스 로직의 서비스 빈에 적용되도록 수정한다.aop스키마의 태그를 이용해 포인트컷, 어드바이저를 설정하고, 표현식은 가장 단순한 빈 이름 패턴을 이용해보자.- 이제 아이디가
Service로 끝나는 모든 빈에transactionAdvice빈의 부가기능이 적용될 것이다.

6.4.3 트랜잭션 속성을 가진 트랜잭션 어드바이스 등록
TransactionAdvice클래스로 정의했던 어드바이스 빈을 TransactionInterceptor를 이용하도록 변경한다.- 메서드 패턴과 트랜잭션 속성은 가장 보편적인 방법인 get으로 시작하는 메서드는 읽기전용 속성을 두고 나머지는 디폴트 트랜잭션 속성을 따르는 것으로 설정한다.
<bean>을 이용한 어드바이스 정의

tx스키마에 정의된 태그를 이용한 어드바이스 등록
- aop 스키마 태그를 적용했으니 어디바이스도
tx스키마에 정의된 태그를 이용하도록 만드는 게 좋다. <bean>태그와 긴 클래스 이름 대신 용도를 명확히 드러내주는 태그를 사용하기 때문에 트랜잭션 어드바이스와 속성 정의가 훨씬 이해하기 쉽고 간결해해진다.

6.4.4 트랜잭션 속성 테스트
get으로 시작하는 읽기전용 속성이 true로 되어 있는 메서드를 테스트해보자.
1. TestUserService에 getAll() 메서드를 오버라이드해서 강제로 DB에 쓰기 작업을 추가한다.
getAll()은 읽기전용 트랜잭션 속성이 적용된 채로 동작해야 한다.- 트랜잭션 안에서 쓰기 시도를 하면 예외가 발생할 것이다.
- 예외 발생을 기대하는 테스트라면
@Test(expected=)를 이용하면 되긴 하지만,
아직 정확히 어떤 예외가 발생할지 모르기 때문에 테스트를 실패하는 것을 먼저 확인하고 어떤 예외가 던져졌는지 확인해 이를 다시 테스트 조건에 넣어준다.

-
UserServiceTest에 조작된getAll()을 호출하는 테스트를 만든다.

-
실패와 함께 나타나는 예외 타입을 확인해보고 테스트에 반영한다.
- 읽기전용으로 설정된 DB 커넥션에 대해 데이터를 조작하는 작업을 시도했기 때문에 예외가 발생했는지 확인해보자.
TransientDataAccessResourceException예외는 스프링의DataAccessException의 한 종류로 일시적인 예외상황을 만났을 때 발생하는 예외다.- 일시적이라는 것의 의미는 DB 쓰기 작업은 원래 정상적으로 처리돼야 함에도 일시적인 제약조건 때문에 예외를 발생시켰다는 뜻이다.

7. 애노테이션 트랜잭션 속성과 포인트컷
포인트컷 표현식과 트랜잭션 속성을 이용해 트랜잭션을 일괄적으로 적용하는 방식은 복잡한 트랜잭션 속성이 요구되지 않는 한 대부분의 상황에 잘 들어맞는다. 그런데 가끔은 클래스나 메서드에 따라 제각각 속성이 다른, 세밀하게 튜닝된 트랜잭션 속성을 적용해야 하는 경우도 있다. 이런 경우엔 메서드 이름 패턴을 이용해서 일괄적으로 트랜잭션 속성을 부여하는 방식은 적합하지 않다. 기본 속성과 다른 경우가 있을 때마다 일일이 포인트컷과 어드바이스를 새로 추가해줘야 하기 때문이다. 포인트컷 자체가 지저분해지고 설정파일도 복잡해지기 쉽다.
이런 세밀한 트랜잭션 속성의 제어가 필요한 경우를 위해 스프링에선 설정파일에서 직접 타깃에 트랜잭션 속성정보를 가진 애노테이션을 지정하는 방법을 제공한다.
7.1 트랜잭션 애노테이션
타깃에 부여할 수 있는 트랜잭션 애노테이션은 다음과 같이 정의되어 있다. 필요에 따라선 애노테이션 정의를 읽고 그 내용과 특징을 이해할 수 있도록 애노테이션의 정의에 사용되는 주요 메타애노테이션을 알고 있어야 한다.
7.1.1 @Transactional


@Transactional애노테이션의 타깃은 메서드와 타입이다. 따라서 메서드, 클래스, 인터페이스에 사용할 수 있다.@Transactional애노테이션을 트랜잭션 속성정보로 사용하도록 지정하면 스프링은@Transactional이 부여된 모든 오브젝트를 자동으로 타깃 오브젝트로 인식한다.- 이때 사용되는 포인트컷은
TransactionAttributeSourcePointcut이다. TransactionAttributeSourcePointcut은 스스로 표현식과 같은 선정기준을 갖고 있진 않다. 대신@Transactional이 타입 레벨이든 메서드 레벨이든 상관없이 부여된 빈 오브젝트를 모두 찾아서 포인트컷의 선정 결과로 돌려준다.
- 이때 사용되는 포인트컷은
@Transactional은 기본적으로 트랜잭션 속성을 정의하는 것이지만, 동시에 포인트컷의 자동등록에도 사용된다.
7.1.2 트랜잭션 속성을 이용하는 포인트컷
@Transactional 애노테이션을 사용했을 때 어드바이저의 동작방식이다.
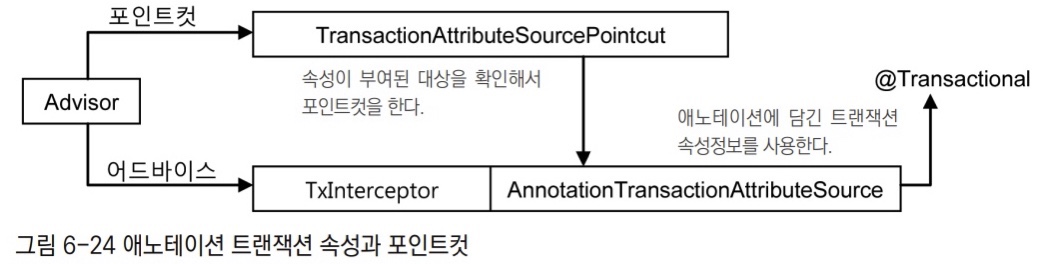
TransactionInterceptor는 메서드 이름 패턴을 통해 부여되는 일괄적인 트랜잭션 속성정보 대신@Transactional애노테이션의 엘리먼트에서 트랜잭션 속성을 가져오는AnnotationTransactionAttributeSource를 사용한다.@Transactional은 메서드마다 다르게 설정할 수 있으므로 매우 유연한 트랜잭션 속성 설정이 가능해진다.
- 동시에 포인트컷도
@Transactional을 통한 트랜잭션 속성정보를 참조하도록 만든다.@Transactional로 트랜잭션 속성이 부여된 오브젝트라면 포인트컷의 선정 대상이기도 하기 때문이다.
- 이 방식을 이용하면 포인트컷과 트랜잭션 속성을 애노테이션 하나로 지정할 수 있다.
- 트랜잭션 속성은 타입 레벨에 일괄적으로 부여할 수도 있지만, 메서드 단위로 세분화해서 트랜잭션 속성을 다르게 지정할 수도 있기 때문에 매우 세밀한 트랜잭션 속성 제어가 가능해진다.
- 트랜잭션 부가기능 적용 단위는 메서드다. 따라서 메서드마다
@Transactional을 부여하고 속성을 지정할 수 있다. - 이렇게 하면 유연한 속성 제어는 가능하겠지만 코드는 지저분해지고, 동일한 속성 정보를 가진 애노테이션을 반복적으로 메서드마다 부여해주게 될 것이다.
7.1.3 대체 정책
- 그래서 스프링은
@Transactional을 적용할 때 4단계 대체(fallback) 정책을 이용하게 해준다. - 메서드의 속성을 확인할 때 타깃 메서드, 타깃 클래스, 선언 메서드, 선언 타입(클래스, 인터페이스)의 순서에 따라
@Transactional이 적용됐는지 차례로 확인하고, 가장 먼저 발견되는 속성정보를 사용하게 하는 방법이다. - 확인 순서
- 가장 먼저 타깃의 메서드에
@Transactional이 이는지 확인한다. @Transactional이 부여되어 있다면 이를 속성으로 사용한다.- 만약 없으면 다음 대체 후보인 타깃 클래스에 부여된
@Transactional애노테이션을 찾는다. - 타깃 클래스의 메서드 레벨에는 없었지만 클래스 레벨에
@Transactional이 존재한다면 이를 메서드의 트랜잭션 속성으로 사용한다. - 이런 식으로 메서드가 선언된 타입까지 단계적으로 확인해서
@Transactional이 발견되면 적용하고, 끝까지 발견되지 않으면 해당 메서드는 트랜잭션 적용 대상이 아니라고 판단한다.
- 가장 먼저 타깃의 메서드에
대체 정책 예

- 다음과 같이 정의된 인터페이스와 구현 클래스가 있다고 하면, 구현 클래스인
ServiceImpl이 빈으로 등록됐고 그 두 개의 메서드가 트랜잭션의 적용 대상이 돼야 한다면@Transactional을 부여할 수 있는 위치는 총 6개다.
- 스프링은 트랜잭션 기능이 부여될 위치인 타깃 오브젝트의 메서드부터 시작해서
@Transactional애노테이션이 존재하는지 확인한다.
- 따라서 [5]와 [6]이
@Transactional이 위치할 수 있는 첫 번째 후보다. - 여기서 애노테이션이 발견되면 바로 애노테이션의 속성을 가져다 해당 메서드의 트랜잭션 속성으로 사용한다.
- 메서드에서
@Transactional을 발견하지 못하면, 다음은 타깃 클래스인 [4]에@Transactional이 존재하는지 확인한다.
- 이를 통해서
@Transactional이 타입 레벨, 즉 클래스에 부여되면 해당 클래스의 모든 메서드의 공통적으로 적용되는 속성이 될 수 있다. 메서드 레벨에@Transactional이 없다면 모두 클래스 레벨의 속성을 사용할 것이기 때문이다. - 메서드가 여러 개라면 클래스 레벨에
@Transactional을 부여하는 것이 편리하다. - 특정 메서드만 공통 속성을 따르지 않는다면 해당 메서드에만 추가로
@Transactional을 부여해주면 된다. - 대체 정책에서 지정한 순서에 따라서 항상 메서드에 부여된
@Transactional이 가장 우선이기 때문에@Transactional이 붙은 메서드는 클래스 레벨의 속성을 무시하고 메서드 레벨의 속성을 사용할 것이다. 반면에@Transactional을 붙이지 않은 메서드들은 클래스 레벨에 부여된 공통@Transactional을 따르게 된다.
- 타깃 클래스에서도
@Transactional을 발견하지 못하면, 스프링은 메서드가 선언된 인터페이스로 넘어간다. 인터페이스에서도 먼저 메서드를 확인한다.
- [2]와 [3]에
@Transactional이 부여됐는지 확인하고 있다면 이 속성을 적용한다.
- 인터페이스 메서드에도 없다면 인터페이스 타입 [1]의 위치에 애노테이션이 있는지 확인한다.
정리
@Transactional을 사용하면 대체 정책을 잘 활용해서 애노테이션 자체는 최소한으로 사용하면서도 세밀한 제어가 가능하다.@Transactional은 먼저 타입 레벨에 정의되고 공통 속성을 따르지 않는 메서드에 대해서만 메서드 레벨에 다시@Transactional을 부여해주는 식으로 사용해야 한다.- 기본적으로
@Transactional적용 대상은 클라이언트가 사용하는 인터페이스가 정의한 메서드이므로@Transactional도 타깃 클래스보다는 인터페이스에 두는 게 바람직하다. - 하지만 인터페이스를 사용하는 프록시 방식의 AOP가 아닌 방식으로 트랜잭션을 적용하면 인터페이스에 정의한
@Transactional은 무시되기 때문에 안전하게 타깃 클래스에@Transactional을 두는 방법을 권장한다. - 프록시 방식 AOP의 종류와 특징, 또는 비 프록시 방식 AOP의 동작원리를 잘 이해하고 있고 그에 따라
@Transactional의 적용 대상을 적절하게 변경해줄 확신이 있다면 인터페이스에@Transactional을 적용하고, 아니라면 마음 편하게 타깃 클래스와 타깃 메서드에 적용하는 편이 낫다. - 인터페이스에
@Transactional을 두면 구현 클래스가 바뀌더라도 트랜잭션 속성을 유지할 수 있다는 장점이 있다.
7.1.4 트랜잭션 애노테이션 사용을 위한 설정
@Transactional을 이용한 트랜잭션 속성을 사용하는 데 필요한 설정은 매우 간단하다.- 태그 하나에 모든 설정을 담아뒀다. 태그 하나로 트랜잭션 애노테이션을 이용하는 데 필요한 어드바이저, 어드바이스, 포인트컷, 애노테이션을 이용하는 트랜잭션 속성정보가 등록된다.
<tx:annotation-driven />7.2 트랜잭션 애노테이션 적용
@Transactional을 UserService에 적용해보자.
- 꼭 세밀한 트랜잭션 설정이 필요할 때가 아닌,
@Transactional을 이용한 트랜잭션 설정이 직관적이고 간단하다고 생각해서 사용하는 경우도 많다. - 훨씬 편리하고 코드를 이해하기도 좋지만, 트랜잭션 적용 대상을 손쉽게 파악할 수 없고, 사용 정책을 잘 만들어두지 않으면 무분별하게 사용되거나 자칫 빼먹을 위험도 있다.
- 따라서
@Transactional을 사용할 때는 실수하지 않도록 주의하고,@Transactional적용에 대한 별도의 코드 리뷰를 거칠 필요가 있다. - 일부 데이터 액세스 기술은 트랜잭션이 시작되지 않으면 아예 DAO에서 예외가 발생하기도 하지만 JDBC를 직접 사용하는 기술은 트랜잭션이 없어도 DAO가 동작할 수 있기 때문에 주의해야 한다.
tx 스키마의 <tx:attributes> 태그를 이용해 설정했던 트랜잭션 속성을 그대로 애노테이션으로 바꿔보자.

- 애노테이션을 이용할 때는 이 두 가지 속성 중에서 많이 사용되는 한 가지를 타입 레벨에 공통 속성으로 지정해주고, 나머지 속성은 개별 메서드에 적용해야 한다.
- 메서드 레벨의 속성은 메서드마다 반복돼야 하므로 속성의 종류가 두 가지 이상이고 적용 대상 메서드의 비율이 비슷하다면 메서드에 많은
@Transactional애노테이션이 반복될 수 있다. @Transactional애노테이션은USerService인터페이스에 적용한다.UserServiceImpl과TestUserService양쪽에 트랜잭션이 적용될 수 있기 때문이다.- 인터페이스 방식의 프록시를 사용하는 경우에는 인터페이스
@Transactional을 적용해도 상관없다.
UserService에는get으로 시작하지 않는 메서드가 더 많으므로 인터페이스 레벨에 디폴트 속성을 부여해주고, 읽기전용 속성을 지정할get으로 시작하는 메서드에는 읽기전용 트랜잭션 속성을 반복해서 지정해야 한다.

- 애노테이션을 이용한 트랜잭션 속성 지정은
tx스키마를 사용할 때와 마찬가지로 IDE의 자동완성 기능을 활용할 수 있고 속성을 잘못 지정한 경우 컴파일 에러가 발생해서 손쉽게 확인할 수 있다는 장점이 있다.
8. 트랜잭션 지원 테스트
8.1 선언적 트랜잭션과 트랜잭션 전파 속성
트랜잭션 전파 속성을 이용하면 트랜잭션 적용 때문에 불필요하게 코드를 중복하는 것도 피할 수 있으며, 애플리케이션을 작은 기능 단위로 쪼개서 개발할 수가 있다.
예1) 사용자 등록 로직을 담당하는 UserService의 add() 메서드
add()메서드는 트랜잭션 속성이 디폴트로 지정되어 있으므로 트랜잭션 전파 방식이 REQUIRED다.- 만약
add()메서드가 처음 호출되는 서비스 계층의 메서드라면 한 명의 사용자를 등록하는 것이 하나의 비즈니스 작업 단위가 된다. - DB 트랜잭션은 단위 업무와 일치해야 하기 때문에 이때는
add()메서드가 실행되기 전에 트랜잭션이 시작되고add()메서드를 빠져나오면 트랜잭션이 종료되는 것이 맞다.
예2) 그날의 이벤트의 신청 내역을 모아서 한 번에 처리하는 EventService의 processDailyEventRegistration() 메서드
- 처리되지 않은 이벤트 신청정보를 모두 가져와 DB에 등록하고 그에 따른 정보를 조작해주는 기능이다. 신청정보의 회원가입 항목이 체크되어 있는 경우에는 이벤트 참가자를 자동으로 사용자로 등록해줘야 한따.
- 하루치 이벤트 신청 내역을 처리하는 기능은 반드시 하나의 작업 단위로 처리돼야 한다.
- 이 메서드는 작업 중간에 사용자 등록을 할 필요가 있고, 직접
UserDao의add()메서드를 사용할 수도 있지만, 그보다UserService의add()메서드를 이용해 사용자 등록 중 처리해야 할 디폴트 레벨 설정과 같은 로직을 적용하는 것이 좋다. - 이때
UserService의add()메서드는 독자적인 트랜잭션을 시작하는 대신 이 메서드에서 시작된 트랜잭션의 일부로 참여하게 된다. 만약add()메서드 호출 뒤에 이 메서드를 종료하지 못하고 예외가 발생한 경우에는 트랜잭션이 롤백되면서UserService의add()메서드에서 등록한 사용자 정보도 취소된다. add()메서드에REQUIRED방식의 트랜잭션 전파 속성을 지정했을 때 트랜잭션이 시작되고 종료되는 경계
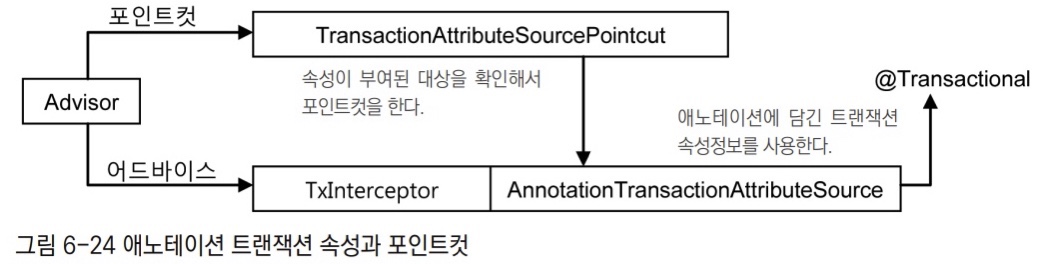
add()메서드도 스스로 트랜잭션 경계를 설정할 수 있지만, 때로는 다른 메서드에서 만들어진 트랜잭션의 경계 안에 포함된다.- 이 덕분에 사용자 등록 기능이 다양한 비즈니스 트랜잭션에서 사용되더라도 add() 메서드는 하나만 존재하면 되고 불필요한 코드 중복이 일어나지 않는다.
선언적 트랜잭션
- AOP를 이용해 코드 외부에서 트랜잭션의 기능을 부여해주고 속성을 지정할 수 있게 하는 방법을 선언적 트랜잭션이라고 한다.
- 반대로
TransactionTemplate이나 개별 데이터 기술의 트랜잭션 ÅPI를 사용해 직접 코드 안에서 사용하는 방법은 프로그램에 의한 트랜잭션이라고 한다. - 반대로
TransactionTemplate이나 개별 데이터 기술의 트랜잭션 ÅPI를 사용해 직접 코드 안에서 사용하는 방법은 프로그램에 의한 트랜잭션이라고 한다. - 스프링은 이 두 가지 방법을 모두 지원하고 있고, 특별한 경우가 아니라면 선언적 방식의 트랜잭션을 사용하는 것이 바람직하다.
- EJB의 선언적 트랜잭션
- 이런 선언적인 트랜잭션 개념은 EJB에도 있었지만, 스프링은 복잡한 EJB 컴포넌트가 아닌 평범한 자바 클래스로 만든 오브젝트에도 선언적 트랜잭션을 적용할 수 있다.
- 트랜잭션 추상화를 함께 제공하기 때문에 EJB처럼 특정 트랜잭션 기술과 환경에 종속되지도 않는다.
8.2 트랜잭션 동기화와 테스트
AOP 덕분에 프록시를 이용한 트랜잭션 부가기능을 간단하게 애플리케이션 전반에 적용할 수 있었다. 또한 스프링의 트랜잭션 추상화 덕분에 트랜잭션 기술에 상관없이 DAO에서 일어나는 작업들을 하나의 트랜잭션으로 묶어서 추상 레벨에서 관리할 수 있었다.
8.2.1 트랜잭션 매니저와 트랜잭션 동기화
- 트랜잭션 추상화 기술의 핵심은 트랜잭션 매니저와 트랜잭션 동기화다.
- 트랜잭션 매니저
PlatformTransactionManager인터페이스를 구현한 트랜잭션 매니저를 통해 구체적인 트랜잭션 기술의 종류에 상관없이 일관된 트랜잭션 제어가 가능했다. - 트랜잭션 동기화
- 트랜잭션 동기화 기술이 있었기에 시작된 트랜잭션 정보를 저장소에 보관해뒀다가 DAO에서 공유할 수 있었다.
- 또한 진행 중인 트랜잭션이 있는지 확인하고, 트랜잭션 전파 속성에 따라서 이에 참여할 수 있도록 만들어준다.
프로그램에 의한 트랜잭션 사용하는 경우 - 테스트
- 선언적 트랜잭션이 훨씬 편리하지만, 특별한 이유가 있다면 프로그램에 의한 트랜잭션 방식 즉, 트랜잭션 매니저를 이용해 트랜잭션에 참여하거나 트랜잭션을 제어하는 방법을 사용할 수도 있다.
- 스프링의 테스트 컨텍스트를 이용한 테스트에서는
@Autowired를 이용해 애플리케이션 컨텍스트에 등록된 빈을 가져와 테스트 목적으로 활용할 수 있었다. @Autowired를 사용해 트랜잭션 매니저 빈을 가져와 테스트한다.


transactionSync()테스트 메서드가 실행되는 동안 3개의 트랜잭션이 만들어졌다.UserService의 모든 메서드에 트랜잭션을 적용했으니 각 메서드가 모두 독립적인 트랜잭션 안에서 실행된다.- 테스트에서 각 메서드를 실행시킬 때는 기존에 진행 중인 트랜잭션이 없고 트랜잭션 전파 속성은 REQUIRED이니 새로운 트랜잭션이 시작된다. 그리고 그 메서드를 정상적으로 종료하는 순간 트랜잭션은 커밋되면서 종료될 것이다.
deleteAll()메서드가 실행되는 시점에서 트랜잭션이 시작됐으니 그 메서드가 끝나면 트랜잭션도 같이 종료된다. 후에 다시add()메서드가 호출되면 현재 진행 중인 트랜잭션은 없으니 마찬가지로 새로운 트랜잭션이 만들어질 것이다. 마지막add()메서드도 마찬가지다.
8.2.2 트랜잭션 매니저를 이용한 테스트용 트랜잭션 제어
❓ 이 테스트 메서드에서 만들어지는 세 개의 트랜잭션을 하나로 통합할 수는 없을까?
-
메서드를 추가해서 트랜잭션을 통합하는 경우
세 개의 메서드 모두 트랜잭션 전파 속성이REQUIRED이니 이 메서드들이 호출되기 전에 트랜잭션이 시작되게만 한다면 가능하다.UserService에 새로운 메서드는 트랜잭션 경계가 되니 새로 만든 메서드에서 시작한 트랜잭션이deleteAll()과add()메서드를 묶어서 하나의 트랜잭션 안에서 동작하게 할 것이다. -
메서드를 추가하지 않고 테스트 코드만으로 트랜잭션을 통합하는 경우
테스트 메서드에서UserService의 메서드를 호출하기 전에 트랜잭션을 미리 시작해주면 된다. 트랜잭션의 전파는 트랜잭션 매니저를 통해 트랜잭션 동기화 방식이 적용되기 때문에 가능하다. 따라서 테스트에서 트랜잭션 매니저를 이용해 트랜잭션을 시작시키고 이를 동기화해주면 된다. 테스트도 트래잭션 동기화에 참여하는 것이다.
트랜잭션을 시작하기 위해서 먼저 트랜잭션 정의를 담은 오브젝트를 만들고 이를 트랜잭션 매니저에 제공하면서 새로운 트랜잭션을 요청하면 된다.
예외처리나 롤백은 없는 무책임한 코드지만 학습 테스트라 넘어가자.
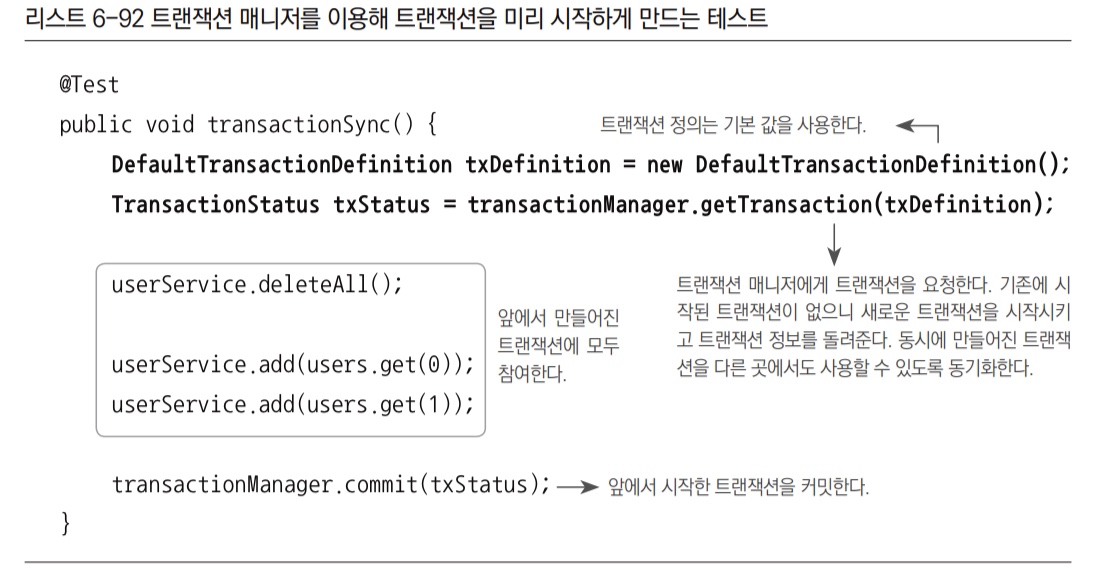
8.2.3 트랜잭션 동기화 검증
- 트랜잭션 동기화 검증 -
UserService사용
정말 이 세 개의 메서드가 테스트 코드 내에서 시작된 트랜잭션에 참여하고 있는지 증명해보자.
- 트랜잭션 속성 중에서 읽기전용과 제한시간 등은 처음 트랜잭션이 시작할 때만 적용되고 그 이후에 참여하는 메서드의 속성은 무시된다.
즉,deleteAll()의 트랜잭션 속성은 쓰기 가능으로 되어 있지만 앞에서 시작된 트랜잭션이 읽기전용이면deleteAll()의 모든 작업도 읽기전용 트랜잭션이 적용된 상태에서 진행된다. - 트랜잭션의 속성을 강제로 읽기전용으로 만들고 테스트하면 예외 발생으로 인해 실패할 것이다.
deleteAll()메서드를 호출한 곳에서TransientDataAccessResourceException예외, 메시지는Connection is read-only라고 나올 것이다. 읽기전용 트랜잭션에 대해 쓰기 작업을 했을 때 발생하는 예외다.
- 스프링의 트랜잭션 추상화가 제공하는 트랜잭션 동기화 기술과 트랜잭션 전파 속성 덕분에 테스트도 트랜잭션으로 묶을 수 있다.

- 트랜잭션 동기화 검증 - DAO 사용
이런 방법은 선언적 트랜잭션이 적용된 서비스 메서드만이 아닌JdbcTemplate과 같이 스프링이 제공하는 데이터 액세스 추상화를 적용한 DAO에도 동일하게 적용된다.
JdbcTemplate은 트랜잭션이 시작된 것이 있으면 그 트랜잭션에 자동으로 참여하고, 없으면 트랜잭션 없이 자동커밋 모드로 JDBC 작업을 수행한다.- 개념은 조금 다르지만
JdbcTemplate의 메서드 단위로 마치 트랜잭션 전파 속성이 REQUIRED인 것처럼 동작한다고 볼 수 있다. - 따라서 DAO를 직접 호출해도 동일한 결과를 얻는다.

전체 트랜잭션이 한꺼번에 롤백되는지도 확인한다.

UserService의add()작업이 테스트에서 시작한 트랜잭션에 참여하고 있으므로 테스트에서 만든 트랜잭션을 롤백하면 당연히add()작업도 롤백돼야 한다.
테스트에서의 트랜잭션 조작
테스트에서 트랜잭션을 시작하거나 조작할 수 있는 기능은 매우 유용하다.
- 테스트 코드에서 미리 트랜잭션을 시작해놓으면 직접 호출하는 DAO 메서드도 하나의 트랜잭션으로 묶을 수 있다.
- 트랜잭션 결과나 상태를 조작하면서 테스트할 수 있다.
- Hibernate 같은 ORM에서 세션에서 분리된(detached) 엔티티의 동작을 확인할 때도 유용하다.
- 테스트 메서드 안에서 트랜잭션을 여러 번 만들 수 있다.
- 트랜잭션 속성에 따라서 여러 메서드를 조합해 사용할 때 어떤 결과가 나오는지도 미리 검증 가능하다.
8.2.4 롤백 테스트
테스트 코드로 트랜잭션을 제어해서 적용할 수 있는 테스트 기법이 있다. 롤백 테스트는 테스트 내의 모든 DB 작업을 하나의 트랜잭션 안에서 동작하게 하고 테스트가 끝나면 무조건 롤백해버리는 테스트를 말한다.

- 롤백 테스트는 테스트를 진행하는 동안에 조작한 데이터를 모두 롤백하고 테스트를 시작하기 전 상태로 만들어준다.
- 롤백 테스트는 DB 작업이 포함된 테스트가 수행돼도 DB에 영향을 주지 않기 때문에 장점이 많다.
- DB를 사용하는 코드를 테스트하는 건 작성하기 힘들다. 테스트를 위해 미리 준비해둘 수 있는 공통 테스트 데이터가 있는데, DB 데이터를 수정하고 삭제하는 등의 작업을 진행하는 테스트 때문에 준비된 데이터가 바뀌면 준비한 테스트 데이터는 무용지물이 되어 이후에 실행되는 테스트에 영향을 미칠 수 있다. 결국 DB를 액세스하는 테스트를 위해선 테스트를 할 때마다 테스트 데이터를 초기화하는 작업이 필요해진다.
- 전체 테스트를 수행하기 전에 여러 테스트에서 공통적으로 필요한 사용자 정볼르 테스트 데이터로 DB에 넣어뒀다면, 롤백 테스트 덕분에 매 테스트마다 처음과 동일한 테스트 데이터로 테스트를 수행할 수 있다.
- 물론 테스트에 따라 고유한 테스트 데이터가 필요한 경우가 있다. 이때는 테스트 앞 부분에서 그에 맞게 DB를 초기화하고 테스트를 진행하면된다. 초기화한 작업까지도 모두 롤백되므로 어떤 변경을 가하든 상관없다.
- 롤백 테스트는 심지어 여러 개발자가 하나의 공용 테스트용 DB를 사용할 수 있게도 해준다. 적절한 격리수준만 보장해주면 동시에 여러 개의 테스트가 진행돼도 상관없다.
- DB에 따라 성공적인 작업이라도 트랜잭션을 롤백하면 커밋할 때보다 성능이 더 향상되기도 한다.
- MySQL에선 동일한 작업을 수행한 뒤에 롤백하는 게 커밋하는 것보다 더 빠르다.
- 하지만 DB의 트랜잭션 처리 방법에 따라 롤백이 커밋보다 더 많은 부하를 주는 경우도 있으니 단지 성능 때문에 롤백 테스트가 낫다고는 볼 수 없다.
8.3 테스트를 위한 트랜잭션 애노테이션
@Transactional애노테이션을 테스트 클래스와 메서드에도 적용할 수 있다.- 스프링의 컨텍스트 테스트 프레임워크는 애노테이션을 이용해 테스트를 편리하게 만들 수 있는 여러 가지 기능을 추가하게 해준다.
@ContextConfiguration을 클래스에 부여하면 테스트를 실행하기 전에 스프링 컨테이너를 초기화한다.@Autowired애노테이션이 붙은 필드를 통해 테스트에 필요한 빈에 자유롭게 접근할 수 있다.
8.3.1 @Transactional
- 테스트 클래스 또는 메서드에
@Transactional애노테이션을 부여해주면 테스트 메서드에 트랜잭션 경계가 자동으로 설정된다. - 이를 이용하면 테스트 내에서 진행하는 모든 트랜잭션 관련 작업을 하나로 묶어줄 수 있다.
@Transactional에는 모든 종류의 트랜잭션 속성을 지정할 수 있다.- 테스트의
@Transactional은 앞에서 테스트 메서드의 코드를 이용해 트랜잭션을 만들어 적용했던 것과 동일한 결과를 가져온다. - 테스트에서 사용하는
@Transactional은 AOP를 위한 것은 아닌, 단지 컨텍스트 테스트 프레임워크에 의해 트랜잭션을 부여해주는 용도로 쓰일 뿐이다. - 테스트의 트랜잭션 속성을 메서드 단위에 부여하면
UserService의 메서드에 적용했을 때와 마찬가지로 테스트 메서드 실행 전에 새로운 트랜잭션을 만들어주고 메서드가 종료되면 트랜잭션을 종료해준다. 당연히 메서드 안에서 실행하는deleteAll(),add()등은 테스트 메서드의 트랜잭션에 참여해서 하나의 트랜잭션으로 실행된다. @Transactional을 테스트 클래스 레벨에 부여하면 테스트 클래스의 모든 메서드에 트랜잭션이 적용된다. 각 메서드에@Transactional을 지정해서 클래스의 공통 트랜잭션과는 다른 속성을 지정할 수도 있다.- 메서드의 트랜잭션 속성이 클래스의 속성보다 우선한다.


8.3.2 @Rollback
- 테스트 메서드나 클래스에 사용하는
@Transactional은 애플리케이션의 클래스에 적용할 때와 디폴트 속성은 동일하지만, 기본적으로 트랜잭션을 강제 롤백시키도록 설정되어 있다. - 테스트 메서드 안에서 진행되는 작업을 하나의 트랜잭션으로 묶고 싶지만 강제 롤백이 아닌, 트랜잭션을 커밋시켜서 테스트에서 진행한 작업을 그대로 DB에 반영하고 싶다면
@Rollback애노테이션을 이용한다. @Rollback은 롤백 여부를 지정하는 값을 갖고 있다. 기본 값은true다.- 트랜잭션은 적용되지만 롤백을 원치 않는다면
@Rollback(false)라고 해줘야 한다.

8.3.3 @TransactionConfiguration
@Transactional은 테스트 클래스에 넣어서 모든 테스트 메서드에 일괄 적용할 수 있지만@Rollback애노테이션은 메서드 레벨에만 적용할 수 있다.- 테스트 클래스의 모든 메서드에 트랜잭션을 적용하면서 모든 트랜잭션이 롤백되지 않고 커밋되게 하려면 클래스 레벨에 부여할 수 있는
@TransactionConfiguration애노테이션을 이용한다. - 다음과 같이
@TransactionConfiguration을 사용하면 롤백에 대한 공통 속성을 지정할 수 있다. - 디폴트 롤백 속성은
false로 해두고, 테스트 메서드 중에서 일부만 롤백을 적용하고 싶으면 메서드에@Rollback을 부여해주면 된다.

8.3.4 NotTransactional과 Propagation.NEVER
- 굳이 트랜잭션이 필요없는 메서드는 어떻게 할까? 필요하지도 않은 트랜잭션이 만들어지는 것이 꺼림칙하거나 트랜잭션이 적용되면 안 되는 경우에는
@NotTransactional을 이용한다. @NotTransactional을 테스트 메서드에 부여하면 클래스 레벨의@Transactional설정을 무시하고 트랜잭션을 시작하지 않은 채로 테스트를 진행한다. 물론 테스트 안에서 호출하는 메서드에서 트랜잭션을 사용하는 데는 영향을 주지 않는다.@NotTransactional은 스프링 3.0에서 제거 대상이 됐기 때문에 개발자들은 트랜잭션 테스트와 비 트랜잭션 테스트를 아예 클래스를 구분해서 만들도록 권장한다.@NotTransactional대신@Transactional을NEVER전파 속성으로 지정해주는 방법도 있다. 마찬가지로 트랜잭션이 시작되지 않는다.
@Transactional(propagation=Propagation.NEVER)8.3.6 효과적인 DB 테스트
- 테스트 내에서 트랜잭션을 제어할 수 있는 네 가지 애노테이션을 잘 활용하면 DB가 사용되는 통합 테스트를 만들 때 매우 편리하다.
- 일반적으로 의존, 협력 오브젝트를 사용하지 않고 고립된 상태에서 테스트를 진행하는 단위 테스트와, DB 같은 외부의 리소스나 여러 계층의 클래스가 참여하는 통합 테스트는 아예 클래스를 구분해서 따로 만드는 게 좋다.
- DB가 사용되는 통합 테스트를 별도의 클래스로 만들어둔다면 기본적으로 클래스 레벨에
@Transactional을 부여해준다. DB가 사용되는 통합 테스트는 가능한 한 롤백 테스트로 만드는 게 좋다. - 애플리케이션의 모든 테스트를 한꺼번에 실행하는 빌드 스크립트 등에서 테스트에서 공통적으로 이용할 수 있는 테스트 DB를 셋업해주고, 각 테스트는 자신이 필요한 테스트 데이터를 보충해서 테스트를 진행하게 만든다.
- 테스트가 기본적으로 롤백 테스트로 되어 있다면 테스트 사이에 서로 영향을 주지 않으므로 독립적이고 자동화된 테스트로 만들기가 매우 편하다.
- 테스트는 어떤 경우에도 서로 의존하면 안 된다. 코드가 바뀌지 않는 한 어떤 순서로 진행되더라도 테스트는 일정한 결과를 내야 한다.
9. 정리
6장에선 트랜잭션 경계설정 기능을 성격이 다른 비즈니스 로직 클래스에서 분리하고 유연하게 적용할 수 있는 방법을 찾아보면서 애플리케이션에 산재해서 나타나는 부가기능을 모듈화할 수 있는 AOP 기술을 알아봤다.
- 트랜잭션 경계설정 코드를 분리해서 별도의 클래스로 만들고 비즈니스 로직 클래스와 동일한 인터페이스를 구현하면 DI의 확장 기능을 이용해 클라이언트의 변경 없이도 깔끔하게 분리된 트랜잭션 부가기능을 만들 수 있다.
- 트랜잭션처럼 환경과 외부 리소스에 영향을 받는 코드를 분리하면 비즈니스 로직에만 충실한 테스트를 만들 수 있다.
- 목 오브젝트를 활용하면 의존관계 속에 있는 오브젝트도 손쉽게 고립된 테스트로 만들 수 있다.
- DI를 이용한 트랜잭션의 분리는 데코레이터 패턴과 프록시 패턴으로 이해될 수 있다.
- 번거로운 프록시 클래스 작성은 JDK의 다이내믹 프록시를 사용하면 간단하게 만들 수 있다.
- 다이내믹 프록시는 스태틱 팩토리 메서드를 사용하기 때문에 빈으로 등록하기 번거롭다. 따라서 팩토리 빈으로 만들어야 한다. 스프링은 자동 프록시 생성 기술에 대한 추상화 서비스를 제공하는 프록시 팩토리 빈을 제공한다.
- 프록시 팩토리 빈의 설정이 반복되는 문제를 해결하기 위해 자동 프록시 생성기와 포인트컷을 활용할 수 있다. 자동 프록시 생성기는 부가기능이 담긴 어드바이스를 제공하는 프록시를 스프링 컨테이너 초기화 시점에 자동으로 만들어준다.
- 포인트컷은 AspectJ 포인트컷 표현식을 사용해서 작성하면 편리하다.
- AOP는 OOP만으로는 모듈화하기 힘든 부가기능을 효과적으로 모듈화하도록 도와주는 기술이다.
- 스프링은 자주 사용되는 AOP 설정과 트랜잭션 속성을 지정하는 데 사용할 수 있는 전용 태그를 제공한다.
- AOP를 이용해 트랜잭션 속성을 지정하는 방법에는 포인트컷 표현식과 메서드 이름 패턴을 이용하는 방법과 타깃에 직접 부여하는
@Transactional애노테이션을 사용하는 방법이 있다. @Transactional을 이용한 트랜잭션 속성을 테스트에 적용하면 손쉽게 DB를 사용하는 코드의 테스트를 만들 수 있다.
