Spring Batch
배치란?
-
사전적 의미 : 일정 시간 동안 대량의 데이터를 한 번에 처리하는 방식
- 실시간 처리와 대비되는 단어
-
사용 목적 : 아주 많은 데이터를 처리하는 중간에 프로그램이 멈출 수 있는 상황 대비해 안전 장치 마련
- 예시 : 10만개의 데이터를 복잡한 join 걸어 DB간 이동 시키는 도중 프로그램이 멈춰버리면 처음부터 다시 시작할 수 없기 때문에 작업 지점을 기록
- 수작업으로 하기에는 어디에서 멈췄는지 찾고 다시 그 지점부터 시작해야 하는 단점 존재
- 결국 작업 지점을 기록하여 멈추더라도 해당 지점부터 자동으로 다시 시작하게 할 수 있게 하기 위해 배치 프레임워크 사용
-
예시로 급여 혹은 은행 이자 시스템의 경우 특정일에 지급한 이자를 지급하다 중간에 멈춘 경우 이미 지급한 사람에게도 다시 지급 하는 중복 불상사를 막아야 할때 사용
Spring Batch 구조
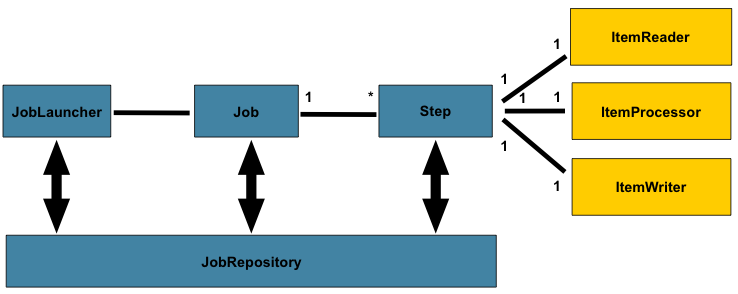
-
JobLauncher : 하나의 배치 작업(Job)을 실행 시키는 시작점
- Spring Boot Url에 달려있으면 Controller 요청하여 시작
- Cron식에 등록 -> 주기적 Job 시작
-
Job : "읽기 -> 처리 -> 쓰기" 과정을 정의한 배치 작업
- N개의 Step으로 구성
- 각 Step은 ItemReader, ItemProcessor, ItemWriter 1:1:1로 구성됨
-
JobRepository : Batch가 얼마나 했는지, 특정 일자 배치를 이미 했는지 메타 데이터에 기록하는 부분
- Meta Table에 계속 적어둠
- 작업에 실행 흐름 기록, 찾아옴 등
Job → Step → (Reader → Processor → Writer)Job
- 배치 작업 전체의 단위.
- 여러 개의 Step으로 구성되며, 실행 순서나 조건 분기(on, to 등)를 설정가능
Step
- Job 내부에서 하나의 독립적인 처리 단위를 담당.
- 보통 하나의 Step은 하나의 비즈니스 로직(예: 엑셀 읽기, DB 쓰기) 을 의미합니다.
- Step은 두가지 실행 방식이 있습니다.
| 방식 | 특징 | 사용 시점 |
|---|---|---|
| Tasklet 방식 | 단일 실행(파일 삭제, 폴더 초기화 등 단순 로직) | 전처리/후처리, 단발성 유지보수 작업, 청크가 과한 단순 로직 |
| Chunk 방식 | read → process → write 흐름을 반복, 대량 데이터 처리에 적합 | 대량 데이터 ETL, 파일/DB 배치, 재시작·커밋 단위 중요할 때 |
Step의 두가지 실행 방식
Tasklet 방식
-
Tasklet은 “한 번 수행하고 끝나는” 절차형 작업에 적합
- 예: 디렉토리 초기화, 파일 삭제/이동, 단건 API 호출 등
-
단일 실행 후 종료되며, 반복(Chunk) 개념이 없음
┌───────────────────────────────────┐
│ STEP │
│ │
│ [tasklet.execute()] │
│ ─ 단일/일괄 동작 한 번 수행 ─ │
│ (예: 폴더 정리, 파일 이동) │
│ │
└───────────────────────────────────┘Chunk-Oriented Processing
- Spring Batch의 핵심은 청크(Chunk) 단위의 반복 처리
- 예를 들어,
chunkSize = 10이면 아래와 같이 동작- 10개 아이템 read -> 10개 아이템 각각 처리 -> 10개 묶음 한번에 write -> commit
┌───────────────────────────────────┐
│ STEP │
│ │
│ ┌───────────── 청크 루프 ───────┐ │
│ │ │ │
│ │ [read] 아이템 1 │ │
│ │ [read] 아이템 2 │ │
│ │ [read] 아이템 3 │ │
│ │ ... │ │
│ │ [read] 아이템 10 │ │
│ │ │ │
│ │ [process] 아이템 1 │ │
│ │ [process] 아이템 2 │ │
│ │ ... │ │
│ │ [process] 아이템 10 │ │
│ │ │ │
│ │ [write] 10개 묶음 저장 │ │
│ │ [commit] 트랜잭션 커밋 │ │
│ └─────────────── 반복 ──────────┘ │
│ │
└───────────────────────────────────┘공식문서 의사코드
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read();
if (item != null) {
items.add(item);
}
}
List processedItems = new Arraylist();
for(Object item: items){
Object processedItem = itemProcessor.process(item);
if (processedItem != null) {
processedItems.add(processedItem);
}
}
itemWriter.write(processedItems);두 방식 비교 표
| 구분 | Tasklet | Chunk-Oriented |
|---|---|---|
| 처리 방식 | 단일 실행 | 청크 단위 반복 |
| 트랜잭션 | 한 번 수행 | chunkSize 단위 커밋 |
| 적합한 작업 | 단순/단발성 (파일정리, 초기화) | 대용량 처리 (ETL, DB↔파일) |
| 상태 저장(ExecutionContext) | 거의 불필요 | 커밋마다 업데이트 가능 |
중간 실패 시 차이점
- Tasklet: 실패하면 처음부터 다시 시작
- Chunk-Oriented: 실패한 청크의 이전 커밋 시점부터 재시작 가능
이미 처리 완료된건 어떻게 식별하지?
- 배치는 두 레벨에서 “이미 처리됨”을 식별
- Job 레벨(실행 범위 식별) -> JobParameters
- Item 레벨(개별 데이터 중복 방지) -> 비즈니스 키/쓰기 전략
Job 레벨 : JobParameters로 실행 범위 고유하게 정의
-
Spring Batch는 Job 이름 + JobParameters 조합으로 하나의 JobInstance 식별
-
“무엇을 처리할 실행”을 파라미터로 규정해야 중복 실행을 막고 재시작 올바르게 가능
-
예시
- targetDate=2025-10-01 : 처리 기준일(어제자/오늘자)
- 2025-10-01일자 작업 성공
- 이후 다시 이 날짜 파라미터 와도 작업 실행 안함
- fileName=daily_user_20251001.xlsx : 파일 단위 처리
- checksum=abc123... : 파일 내용 고유 식별(크기·해시)
- partition=shopA : 파티션/테넌트 구분
같은 Job + 동일 JobParameters로 다시 시작하면
Spring Batch는 메타 테이블에서 해당 인스턴스를 찾아 이전 커밋 지점부터 재시작하게 합니다.
- 해당 Job 내에 작업이 모두 성공한 경우 재실행 하지 않음
Item 레벨 : 비즈니스 중복 방지(멱등성) 설계
- Job 범위를 정해도 개별 레코드가 두 번 쓰이지 않도록 막는 건 도메인 설계의 역할
이것이 필수 작업일까? 하는 의문
- 어차피 Job Parameter로 중복 실행을 막아주고, Step에서 어디에서 실패했는지를 DB와 ExecutionContext로 아는데 중복 될리가 있어? 라는 생각이 들었다.
- 하지만 이런 경우도 있다. 아마 대용량을 직접 마주치면 겪을 것 같은데 발생하는 케이스는 아래와 같다.
┌──────────────────────────────────────────────┐
│ Chunk-Oriented Processing │
│ (chunkSize = 10 예시) │
├──────────────────────────────────────────────┤
│ 1) [read] 아이템 1..10 │
│ 2) [process] 아이템 1..10 │
│ 3) [write] 아이템 10개 타깃 DB에 저장 │
│ 4) [commit] 트랜잭션 커밋(✅ DB 영속) │
│ 5) [update] ExecutionContext 갱신(체크포인트)│
│ └─ ❌ 여기서 "앱 크래시" 발생 │
│ (예: 커밋 직후 ~ update 전후 크래시) │
├──────────────────────────────────────────────┤
│ 6) 재시작 (동일 Job + 동일 JobParameters) │
│ └─ 이전 실행 상태 로드: │
│ - DB: 1~10은 이미 저장(커밋 완료) │
│ - ExecutionContext: 갱신 실패 ⇒ │
│ "1~10을 아직 처리 안 한 것처럼 보임" │
│ │
│ 7) [read] 다시 아이템 1..10 │
│ 8) [process] 아이템 1..10 │
│ 9) [write] 아이템 10개 재저장 시도 │
│ └─ 결과 │
│ - 중복 INSERT 발생(UNIQUE 없으면) │
│ - or 업서트면 "무해하게 갱신" │
└──────────────────────────────────────────────┘핵심: 4)에서 커밋은 이미 끝나 DB는 영속 상태지만,
5)의 ExecutionContext 체크포인트가 갱신되지 못하면 재시작 시 같은 청크를 다시 처리하려 든다
→ 아이템 레벨 멱등성(UNIQUE+UPSERT / processed 플래그)이 없으면 중복 작업 문제 발생
대표 전략
-
비즈니스 키 기반 : upsert/merge
- 예:
INSERT ... ON DUPLICATE KEY UPDATE(MySQL),MERGE INTO(Oracle/PG) - 동일 키가 이미 있다면 갱신/무시 정책으로 중복 방지
- 예:
-
상태 컬럼 플래그
- processed=false 조건으로 읽고, 쓰기 후 processed=true로 업데이트 등
-
스냅샷/해시 비교
- 파일/레코드의 해시를 저장해 이미 본 것은 무시
-
소스 오프셋 저장(ExecutionContext)
- 파일: 현재 행 번호
- API: 마지막 id/토큰 등 오프셋 저장
→ 커밋마다 update()로 기록
-> 실습 코드에서 Excel -> table 할때 update() 메소드 오버라이드 해서 구현
-> 몇번째 행까지 읽었는지 저장해두고, 다음 읽을때는 저 지점 이후에 읽도록 세팅함
private final String CURRENT_ROW_KEY = "current.row.number";
@Override
public void update(ExecutionContext executionContext) throws ItemStreamException {
executionContext.putInt(CURRENT_ROW_KEY, currentRowNumber);
}중요: Spring Batch 메타 테이블은 “배치 엔진의 진행 상태”를 저장할 뿐,
비즈니스 중복 방지(이미 처리된 주문/유저 등)는 도메인 레벨에서 설계해야 합니다.
- 어디까지 읽었는가 = ExecutionContext
- 이미 처리했는가 = 비즈니스 키/저장소
그러면 어디까지 처리했는지 저장/복원은 어떻게하지?
- Spring Batch는 메타 테이블에 실행 이력과 상태를 자동 기록한다.
- 작업이 시작 되기 전 해당 메타 테이블에서 어디까지 작업을 했는지 정보를 불러와
ExecutionContext 에 Map 형태로 저장해두고 이후 작업에서 사용한다.
저장 위치(메타 테이블)
BATCH_JOB_INSTANCE/BATCH_JOB_EXECUTION: 잡 식별/실행 이력BATCH_STEP_EXECUTION: 스텝 실행 이력BATCH_JOB_EXECUTION_PARAMS: JobParametersBATCH_JOB_EXECUTION_CONTEXT/BATCH_STEP_EXECUTION_CONTEXT: 🔑 재시작용 상태(예: “현재 70행까지 읽음”)
언제 DB에 저장하고 / 언제 메모리에 복원해서 기록해두나?
- Step 시작 전: DB에 저장돼 있던 ExecutionContext를 역직렬화해 ItemReader/Writer 의 open(executionContext)로 전달
- 각 청크 커밋 직후: update(executionContext)가 호출되어 진행 위치 저장
- executionContext를 갱신하고 DB에 저장한다.
- 예 : 엑셀 파일에서 현재 청크에서 30번행까지 읽어서 처리 완 ->
30행까지 읽었어요 라고 executionContext에 저장 -> DB 저장- 다음 chunk read 시 31행부터 읽음
- Step 종료: close()로 자원 정리
- 재시작: 같은 Job + 같은 JobParameters 로 실행 -> 마지막 커밋 지점부터 이어감
간단 흐름
Job 실행
└─ 이전 실행 이력/Context 로드
└─ Step open() 시 전달
└─ 청크 처리(read→process→write)
└─ commit 후 update()로 현재 위치 저장그러면 저 DB 테이블을 미리 준해야겠네?
- 그렇다 준비해야한다!
- Spring Batch에서는 다양한 DB에 맞는 DDL을 미리 준비해뒀고,
yml이나 properties 설정에 따라서 자동으로 생성해주기도 수동으로 생성하기도 해야한다.
설정 옵션
spring:
batch:
jdbc:
initialize-schema: always # embedded | always | never-
(MySQL 등 비-임베디드면 'always'가 편리. 운영은 보통 never)
-
embedded: H2/HSQL/Derby 같은 임베디드 DB에서만 스키마 스크립트 실행 -
always: 항상 스키마 스크립트 실행(없으면 생성). 기존 테이블을 드롭하지는 않음 -
never: 직접 스키마를 준비(DDL 수동 적용/마이그레이션 도구 사용) -
운영에서는 보통 never(또는 마이그레이션 툴로 관리), 로컬/테스트에서는 always 로 설정하는 편
- always로 하려했으나, DDL 할 권한이 없는 계정이면 예외 발생
- 실행 시 스키마 체크/DDL 쿼리를 실행하기 때문에, 약간의 부하 (매번).
- 잘못된 스크립트가 포함돼 있을 경우 운영 DB에 예상치 못한 변경이 될 위험 등
Spring Batch 영속성별 구현법
- JDBC, MongoDB 등 유튜브 영상에서 다룬 JPA가 아닌 다른 저장소 및 인터페이스별 배치 구현 가능
- Processor : DB 및 인터페이스에 상관 없어 생략
JDBC
JDBC의 Reader
- cursor 방식과 paging 방식으로 나뉨
- cursor(JdbcCursorItemReader) : DB 자체의 cursor를 사용하여 전체 테이블에서 cursor가 한 칸씩 이동하며 데이터를 가져옴
- paging(JdbcPagingItemReader) : 데이터 테이블에서 묶음 단위로 데이터를 가져오는 방식으로 SQL 구문 생성 시 offset과 limit을 배치단에서 자동 조합하여 쿼리 생성
JDBC의 Writer
- JdbcBatchItemWriter 이용
MongoDB
-
MongoTemplate 이용하여 Reader, Writer 구현
다른 sample 예시
- spring batch 공식 repo
- sample 경로로 들어가면 jpa, jdbc, mongodb, amqp, file 등 방식에 대해 reader, processor, writer 방식 sample 존재
빠르게 구현체에 대한 쿼리를 만드는 방법
- Reader나 Writer를 작성할 때 해당 인터페이스에 대한 예시 메소드를 복사하여 GPT에 넣은 후 테이블에 대한 특정 쿼리를 날리고 싶다 하면 알맞은 구현 만들어 줌
(베이스가 되는 구현 샘플, 테이블 제공하면 보다 정확한 구현 제공)
배치에서 데이터를 읽는 Reader
- 배치에서 가장 중요한 부분은 Reader, 현재까지 실행한 부분을 메타데이터에 저장해야하고 처리한 부분은 스킵해야 되기 때문
- 스프링 배치에서 다양한 Reader 구현체를 제공하지만 원하는 구현체가 없는 경우 직접 작성해야 함
- 기본적 Reader 인터페이스에 대한 Reader를 구현하는 방법
ItemStreamReader
- ItemStream + ItemReader 두개 상속
- ItemStream : 현재 상태를 관리하고 초기화 할 수 있는 인터페이스
- ItemReader : 배치마다 반복되는 데이터를 읽어들이는 인터페이스
public interface ItemStreamReader<T> extends ItemStream, ItemReader<T> {
}ItemReader
- 배치 작업 시 데이터를 읽어들일 수 있는 메서드 정의됨
read(): 배치 작업 시 데이터를 읽기 위한 부분으로 하나의 데이터를 읽어올 때read()메소드가 호출됨
@FunctionalInterface
public interface ItemReader<T> {
@Nullable
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}ItemStream
-
open(): 배치 처리가 시작되고 Step에서 처음 reader를 부르면 시작되는 부분으로 초기화나 이미 했던 작업의 경우 중단점 까지 건너 뛰도록 설계하는 부분 -
update(): 배치 작업 시 read()와 함께 불러지는 메소드로 read() 호출 후 바로 호출되기 때문에 read()에서 처리한 작업 단위 기록하는 용도로 사용 -
close(): 배치 작업이 완료되고 불러지는 메소드로 파일을 저장하거나 필드 변수를 초기화 하는 메소드로 사용
public interface ItemStream {
default void open(ExecutionContext executionContext) throws ItemStreamException {
}
default void update(ExecutionContext executionContext) throws ItemStreamException {
}
default void close() throws ItemStreamException {
}
}ExecutionContext
- ItemStream의 open(), update()에 매개변수로 주입되는 객체로 배치 작업 시 기준점을 잡을 변수를 계속하여 트래킹하기 위한 저장소로 사용됨
- 해당 클래스에서 put으로 값을 넣고, get으로 넣은 값을 가져옴
- ExecutionContext 데이터는 JdbcExecutionContextDao에 의해 메타데이터 테이블에 저장되며 범위에 따라 아래와 같이 나뉨
BATCH_JOB_EXECUTION_CONTEXT: Job 실행 상태 Context 저장BATCH_STEP_EXECUTION_CONTEXT: Step 실행 상태 Context 저장
구현 예시
- 실제 동작은 안되지만 예시
- API를 호출하거나 개별적 파일 읽기 등 Reader를 사용하려면 Custom 해서 구현을 해야함
- 구글링 했을 때 현재 상태 트래킹하는
open()메서드 내에서context.containsKey()메서드 써서 어디까지 읽었는지 정보 안가져오는 경우가 많기에 이 부분은 주의해서 참고해야 함
- 구글링 했을 때 현재 상태 트래킹하는
public class CustomItemStreamReaderImpl implements ItemStreamReader<String> {
private final RestTemplate restTemplate;
private int currentId;
private final String CURRENT_ID_KEY = "current.call.id";
private final String API_URL = "https://www.devyummi.com/page?id=";
public CustomItemStreamReaderImpl(RestTemplate restTemplate) {
this.currentId = 0;
this.restTemplate = restTemplate;
}
@Override
public void open(ExecutionContext executionContext) throws ItemStreamException {
/** 이 부분처럼 open 메서드에서 어디까지 읽었는지 가져오는거 있는지 주의해서 참고 자료 참고**/
if (executionContext.containsKey(CURRENT_ID_KEY)) {
currentId = executionContext.getInt(CURRENT_ID_KEY);
}
}
@Override
public String read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException {
currentId++;
String url = API_URL + currentId;
String response = restTemplate.getForObject(url, String.class);
if (response == null) {
return null;
}
return response;
}
@Override
public void update(ExecutionContext executionContext) throws ItemStreamException {
executionContext.putInt(CURRENT_ID_KEY, currentId);
}
@Override
public void close() throws ItemStreamException {
}
}Step 안전 장치(옵션)
Skip
- Step의 과정 중 예외가 발생하게 되면 예외를 특정 수 까지 건너 뛸 수 있도록 설정
faultTolerant()선언 + skip + noSkip + skipLimit 설정Exception으로 크게 skip 잡아두고, noSkip으로 명시하는 방향 추천- skip, noSkip의 순서는 무방함
@Bean
public Step sixthStep() {
return new StepBuilder("sixthStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(beforeSixthReader())
.processor(middleSixthProcessor())
.writer(afterSixthWriter())
.faultTolerant() // 선언 필수
.skip(Exception.class) // 어떤 예외를 건너뛸지
.noSkip(FileNotFoundException.class) // 어떤 예외는 스킵하지 않을지
.noSkip(IOException.class)
.skipLimit(10) // 10번까지 예외 넘어간다.
.build();
}Skip을 조금 더 커스텀 하는 방법 (모든 예외 허용)
skipPolicy에 커스텀한 스킵 정책 매개변수 넘겨줌shouldSkip메서드 구현에서 항상 true로 반환
@Bean
public Step sixthStep() {
return new StepBuilder("sixthStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(beforeSixthReader())
.processor(middleSixthProcessor())
.writer(afterSixthWriter())
.faultTolerant()
.skipPolicy(customSkipPolicy)
.noSkip(FileNotFoundException.class)
.noSkip(IOException.class)
.build();
}@Configuration
public class CustomSkipPolicy implements SkipPolicy {
@Override
public boolean shouldSkip(Throwable t, long skipCount) throws SkipLimitExceededException {
return true;
}
}Retry
- Skip의 과정 중 예외가 발생하면 예외를 특정 수까지 반복 할 수 있도록 설정
faultTolerant()명시 필수retry()예외 지정 /noRetry()재시도 안할 예외 지정retryLimit(3)으로 횟수 지정 가능
@Bean
public Step sixthStep() {
return new StepBuilder("sixthStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(beforeSixthReader())
.processor(middleSixthProcessor())
.writer(afterSixthWriter())
.faultTolerant()
.retryLimit(3) // 1~3 정도 줘서 아래 예외가 발생할 수 있기에 달아두면 좋을 듯
.retry(SQLException.class) // data 읽어들일 때
.retry(IOException.class) // 특정 파일 IO 할때
.noRetry(FileNotFoundException.class)
.build();
}Writer 롤백 제어
- Write 시 특정 예외에 대해 트랜잭션 롤백을 제외하는 방법
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.<String, String>chunk(2, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.faultTolerant()
.noRollback(ValidationException.class) // 특정 예외 지정
.build();
}Step listener
- Step 실행 전후에 특정 작업을 수행 시킬 수 있는 방법
- 로그를 남기거나 다음 Step이 준비 되었는지, 이번 Step과 다음 Step이 의존되는 경우 변수 정리를 진행할 수 있음
1. StepExecutionListener Bean 등록
- beforeStep : step 전 동작
- afterStep : Step 이후 동작
@Bean
public StepExecutionListener stepExecutionListener() {
return new StepExecutionListener() {
@Override
public void beforeStep(StepExecution stepExecution) {
StepExecutionListener.super.beforeStep(stepExecution);
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
return StepExecutionListener.super.afterStep(stepExecution);
}
};
}2. StepBuilder에서 등록
listener()매개변수에 함수 호출
@Bean
public Step sixthStep() {
return new StepBuilder("sixthStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(beforeSixthReader())
.processor(middleSixthProcessor())
.writer(afterSixthWriter())
.listener(stepExecutionListener())
.build();
}Job 설정
순차적으로 Step 실행
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}- 가장 첫번째 실행될 Step만 Start() 메소드로 설정한 뒤 next()로 이어주면 됨.
- 다만 앞선 Step이 실패할 경우 연달아 등장하는 Step 또한 실행되지 않음
조건에 따라 실행
"*"문자의 경우 어떠한 상태는 다 매칭됨FAILED,COMPLETED등 상태 조건을 명시한 경우 해당 조건에 맞춰서만 매칭됨- *와 함께 존재할 경우 명시한 상태가 우선됨
@Bean
public Job job(JobRepository jobRepository, Step stepA, Step stepB, Step stepC, Step stepD) {
return new JobBuilder("job", jobRepository)
.start(stepA)
.on("*") // 이 step이 끝났을 때 "FAILED"가 오든"COMPLETED"가 오든 다음 스텝을 실행 할 수 있음
.to(stepB)
.from(stepA).on("FAILED").to(stepC)
.from(stepA).on("COMPLETED").to(stepD)
.end()
.build();
} ┌────────────┐
│ job() │
└──────┬─────┘
│
▼
┌──────────┐
│ stepA │
└──────────┘
/ | \
(FAILED)/ |(any) \ (COMPLETED)
/ | \
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ stepC │ │ stepB │ │ stepD │
└──────────┘ └──────────┘ └──────────┘
ExitStatus - Step의 결과
| 상태 | 의미 |
|---|---|
| COMPLETED | 정상 종료 |
| FAILED | 실패 종료 |
| STOPPED | 중단됨 |
| UNKNOWN | 알 수 없음 |
| NOOP | 수행할 대상 없음 |
| CUSTOM (예: SKIPPED, PARTIAL 등) | 직접 정의 가능 |
Job Listner
- Job의 실행 전후에 특정 작업을 수행 시킬 수 있는 방법
- 로그 찍기 등 가능
1. JobExecutionListener Bean 등록
- beforeJob : job 실행 전
- afterJob : job 실행 후
@Bean
public JobExecutionListener jobExecutionListener() {
return new JobExecutionListener() {
@Override
public void beforeJob(JobExecution jobExecution) {
JobExecutionListener.super.beforeJob(jobExecution);
}
@Override
public void afterJob(JobExecution jobExecution) {
JobExecutionListener.super.afterJob(jobExecution);
}
};
}2. JobBuilder에 listener 등록
@Bean
public Job sixthBatch() {
return new JobBuilder("sixthBatch", jobRepository)
.start(sixthStep())
.listener(jobExecutionListener())
.build();
}JPA 성능 문제와 JDBC (JPA의 Write 성능 문제)
- 스프링 배치 read와 write 부분을 JPA로 구성할 경우 JDBC 대비 처리 속도 저하
- Reader의 경우 큰 영향을 미치진 않지만 Write의 경우 엄청난 영향을 끼침
성능 저하 이유 : bulk 쿼리 실패
- JPA의 Entity Id 생성 전략은 보통 IDENTITY로 설정
save()수행 시 DB 테이블을 조회하여 가장 마지막 값 보다 1을 증가시킨 값을 저장- Batch 청크 단위 bulk insert 수행이 무너짐(항상 id값을 가져와서 그것보다 +1 해야하기 때문)
비교
- JDBC 기반으로 작성시 청크로 write할 대상을 bulk 쿼리로 1번의 insert 수행
- JPA의 경우 IDENTITY 전략 때문에 bulk 쿼리 대신 각각의 수 만큼 insert 수행
성능 측정 - FirstBatch를 수정하며 진행
-
데이터 100개를 Before -> After table로 저장
-
RepositoryItem 기반
- Job 실행 시간 : 4.5초
-
JDBC 기반
- Job 실행 시간 : 1.99초
Batch 성능 향상 관련 자료
- JPA Batch 성능 향상 유튜브 검색 -> 배민 등 영상 많으니 참조
JPA 성능 문제 2
-
JPA를 사용할 경우 Reader에서 읽은 Entity를 영속성 컨텍스트에 Entity를 유지하여 메모리를 계속 점유하고 있는 문제
- Chunk 단위가 끝나고난 뒤 commit 이후 clear를 명시적으로 하지 않는다면 Job이 끝날때까지 영속성 컨텍스트 유지
- writer의 @AfterChunk 어노테이션이 붙은 메소드에 영속성 컨텍스트를 명시적으로 초기화 해주는 작업이 필수적임
-
그리고 사실 단순히 메모리만 차지하는 문제가 아니라, 변경 감지(Dirty Checking) 자체가 오버헤드를 만든다.
- 이미 update 쿼리를 바로 날려도 되는 상황에서도, JPA는 모든 Entity의 변경 여부를 일일이 추적한다. (2,000만건의 Entity 객체를..)
-
이런 구조는 2,000만 건처럼 대용량 데이터를 처리해야 하는 배치 환경에는 부적합하다.
- Chunk size가 100이라면,
clear()를 20만 번 호출해야 한다는 뜻이다. - clear()로 캐시를 비워도, Entity를 다시 만들고 관리하는 비용은 그대로 발생한다.
이건 조상님이 해주셔야 가능하다...
- Chunk size가 100이라면,
💡 결론: JPA 기반 Reader는 엔티티 변경 감지 중심의 ORM 구조라, 대용량 I/O 배치에는 JDBC나 MyBatis 기반 Reader로 교체하는 것이 훨씬 효율적이다.
Chunk size vs Page Size
- Spring Batch에서 대량 데이터를 읽고 쓸 때, 보통 chunk-oriented processing 방식 사용
- 자주 혼동되는 개념 Chunk Size와 Page Size이다.
- 이 둘은 이름이 비슷하지만 실제로는 서로 다른 레벨의 단위 의미
Chunk Size란?
✅ “한 번에 처리하고 커밋할 아이템 개수”
- Spring Batch는 데이터를 한 줄씩 바로바로 DB에 저장하지 않고,
여러 개를 모아서 한 번에 처리(=Chunk) 후 커밋
예를 들어 chunkSize = 10 이면,
1. 10개의 데이터를 읽고(read)
2. 10개를 처리(process)
3. 10개를 한번에 저장(write)
4. 트랜잭션 1회 커밋- Chunk Size = “Spring Batch의 내부 루프 기준”
- 커밋 단위(트랜잭션 단위) 와 동일
Page Size란?
✅ “한 번의 DB 쿼리로 읽어올 데이터 개수”
JpaPagingItemReader,JdbcPagingItemReader,MyBatisPagingItemReader등에서 사용- 데이터베이스에서 몇 개의 데이터를 메모리로 한 번에 로딩할지를 결정
예를 들어 pageSize = 10 이면,
Reader는 한 번의 select 쿼리로 10개의 row를 가져온다.
SELECT * FROM member ORDER BY id LIMIT 10 OFFSET 0;
- Page Size는 “DB 접근 단위”
- Chunk Size는 “처리/커밋 단위”이다.
둘의 비교
| 구분 | Chunk Size | Page Size |
|---|---|---|
| 역할 | 커밋 단위 | DB 조회 단위 |
| 책임 | 트랜잭션 처리 / write 커밋 | 데이터 읽기 성능 |
| 관련 객체 | Step / ChunkOrientedTasklet | ItemReader (Paging 기반) |
| 메모리 영향 | 처리 중 누적된 데이터 수 | 한 번에 읽는 DB row 수 |
| 조정 기준 | 트랜잭션 비용 / 실패 복구 단위 | DB I/O 효율 / 네트워크 부하 |
권장 옵션 (두 값을 같게)
chunkSize = pageSize
→ 한 번의 쿼리로 읽은 데이터를 한 번의 커밋 단위로 처리.
장점
- Reader 한 번(DB Access 1회)
- Processor/Writer 한 번에 끝남
- 가장 단순하고, 메모리 예측이 쉬움
- 대부분의 케이스에서 권장되는 설정
두 값이 다를때
pageSize > chunkSize
- 예: pageSize=100, chunkSize=10
- Reader는 100개를 한 번에 읽어오지만, Step은 10개씩 잘라서 10번 커밋
Reader 캐시: [1~100]
Processor: [1~10] commit → [11~20] commit → ... → [91~100] commit장점
- DB Access 횟수 감소 (쿼리 1회로 100개 확보)
단점
- 한 번에 읽어온 데이터가 많아 메모리 사용량 증가
- 장애 시 “이미 읽은 데이터”를 다시 읽게 됨 (중복 SELECT)
- 예: 50번째에서 장애 발생 → 다음 실행 시 1~100 전부 다시 SELECT
- 이미 처리한 49개도 같이 다시 읽음 → “읽기 중복”
- 단, 트랜잭션 롤백 덕분에 DB 쓰기 중복은 없음
pageSize < chunkSize
-
예: pageSize=10, chunkSize=100
-
Reader는 10개씩 여러 번 DB 쿼리 (총 10번)
-
Chunk가 100개 찰 때까지 반복 후 커밋
SELECT 10개 → process 10개
SELECT 10개 → process 10개
(10번 반복 후) → write 100개 → commit장점
- Reader의 메모리 부담 적음 (10개씩만 캐시)
- Reader는 PageSize 단위로 읽고 Processor로 넘기며 소비함
- 위 예시에서 10개 읽음 -> 10개 Processor 처리 를 10번 반복한 뒤에야 Write
- 이 과정에서 Reader가 10개씩 10번을 다 보관하는 것이 아닌 읽은 뒤 바로 넘김 반복
단점
- DB I/O 횟수 많아져 성능 저하
- Chunk가 꽉 차야 커밋하므로 처리 지연 발생
- 100개 커밋이기 때문에, 중간 장애 시 0~100 전부 재처리 필요
🔁 정리 요약
| 설정 | 특징 | 복구 단위 | 메모리 영향 | 성능 |
|---|---|---|---|---|
| pageSize = chunkSize | ✅ 권장. 단순하고 예측 쉬움 | Chunk 단위 | 중간 | 중간 |
| pageSize > chunkSize | Reader 캐시 많음, DB I/O 효율 ↑ | Chunk 단위 | ↑ 메모리 높음 | ↑ 빠름 |
| pageSize < chunkSize | Reader 자주 쿼리 | Chunk 단위 | ↓ 메모리 낮음 | ↓ 느림 |
💡 한눈에 정리
| 구분 | 설명 |
|---|---|
| pageSize | Reader가 DB에서 한 번에 읽는 개수 (fetch 단위) |
| chunkSize | Processor/Writer가 한 번에 처리하고 커밋하는 단위 |
| 복구 단위 | 커밋된 Chunk까지만 완료로 간주, 나머지는 재실행 |
| 권장 조합 | pageSize = chunkSize (대부분 케이스) |
📘 비유로 이해하기
| 역할 | 비유 |
|---|---|
| Page Size | “마트에서 한 번에 장바구니에 담는 물건 개수” |
| Chunk Size | “계산대에서 한 번에 결제할 물건 개수” |
장바구니(pageSize)가 너무 크면 무겁고 버겁고,
계산대(chunkSize)가 너무 크면 결제 중 장애 시 처음부터 다시 해야 함.
결국 둘의 균형(pageSize = chunkSize) 이 가장 효율적
마치며
- Spring Batch를 곧 다뤄야하는 프로젝트에 투입되는데 한번도 해본 적 없던 나에게 해당 유튜브 재생목록은 그저 빛이였다..!
- 이번 기회로 우선 개념은 잡은 것 같고, 실전에서 부딪혀가며 이겨내길..!
- Context에 저장하고 Data 자체로도 중복 막고 이건.. 아직 명확한 기준이 서진 않는데 이게 막상 구현 이것 저것 해보다 보면 감이 오지 않을까.. 싶다(제발..!)
프로젝트 실습 코드
- 깃허브에서 각 실습 코드별로 상세 설명을 PR로 달아두었습니다.
- 상세 내용은 아래 Repository의 Read Me 참조
GitHub - SampleBatch
출처
