
목차
- 발표 대상
- 인덱스를 왜 쓸까?
- 인덱스 적용 사례 (1)
- 인덱스 적용 사례 (2)
- 인덱스 적용 사례 (3)
- 인덱스 적용 사례 (4)
발표 대상
- 인덱스가 무엇인지는 알고 있는분
- 라라, 제로의 인덱스 테코톡 참고
- 성능 개선을 위해 인덱스를 걸고 싶은 분
- 어디에 인덱스를 어떻게 걸어야할지 고민인 분
전제조건
- MySQL 8.0과 기본 스토리지 엔진인 InnoDB
- 인덱스를 활용한 쿼리 최적화
테이블 설명
-
crew (크루)
- id : INT
- nickname : VARCHAR(20)
- track : VARCHAR(20) // 백엔드, 프론트 2가지
- age : INT
-
study_log (학습로그)
- id : INT
- crew_id : INT
- title : VARCHAR(50)
- content : TEXT
- type VARCHAR(20)
- created_at : DATETIME
- updated_at : DATETIME
인덱스를 왜 쓸까?
조회 성능 개선
- 디스크 I/O를 줄이는 것이 핵심
- 원하는 데이터를 읽기 위해서 디스크가 돌아야하고 바늘처럼 보이는 헤더가 움직여야 하는 물리적 움직임 필요
- 물리적 움직임이 있기 때문에 데이터의 입출력은 느립니다.
- 하드디스크와 메모리 IO의 속도 차이는 10~15만배 정도 차이
- 달팽이와 전투기의 속도 차이
- SSD가 많이 보편화 되었지만 메모리에 비해 많이 느림
- 즉 성능 개선이란 것은 디스크 IO를 줄이는 것이 핵심
조회 성능만 개선해도 괜찮나요?
조회에 이득을 얻고 수정/삭제에서 손해를 보는데 괜찮나요?
- 일반적인 웹 서비스의 경우 R(Read) 와 CUD의 비율이 8:2
- GET요청이 압도적으로 많기 때문에 조회에서 성능 최적화를 하고 데이터의 수정, 삭제에서 조금 손해를 보더라도 전체적인 성능에 이득을 보자라는 것이 취지
ORDER BY, GROUP BY에서 이점
ORDER BY : 인덱스를 이용해 정렬 처리되는 경우
- 만약 인덱스가 없었다면 데이터를 전체 다 읽어와서 DB에서 직접 정렬했어야 함
- 인덱스는 이미 정렬되어 있어 인덱스 순서대로 파일을 읽기만 하면 됨
SELECT *
FROM crew
WHERE nickname >= "매트" AND nickname <= "토르"
ORDER BY nickname;GROUP BY : 인덱스를 이용하여 GROUP BY를 하는 경우
-
각 track(프론트, 백엔드)에서 nickname이 가장 빠른 사람들을 가져오는 쿼리 날린다고 가정
- 프론트 : 꼬재, 나인, ...., 동키콩
- 백엔드 : 매트, 이스트, ..., 헌치
-
프론트에서 가장 빠른
꼬재를 읽고 바로 백엔드 track으로 넘어가서매트만 읽으면 됨- 중간 내용을 읽지 않았기 때문에 디스크 IO를 많이 줄일 수 있습니다.
CREATE INDEX idx_crew_track_nickname ON crew (track, nickname);
SELECT track, MIN(nickname) FROM crew GROUP BY track;인덱스 실행 계획
- 아래 3가지 말고 더 있으나 가장 많이 사용하는 것
- all : 테이블 전체를 스캔할 때
- range : 인덱스를 이용하여 범위 검색을 할 때
- index : 인덱스 전체를 스캔할 때
all : full scan
-
데이터를 하나하나 다 읽는 것
- 디스크 IO 시간이 많이 걸리기 때문에 성능이 좋지 않음
-
인덱스가 없는 경우 발생
-
인덱스가 있는 경우 발생
- 데이터 전체의 수가 많지 않음
- 읽고자 하는 데이터가 전체 데이터의 25%를 넘어가면 인덱스가 있더라도 full table scan이 일어남
range scan
- 이상적으로 인덱스를 잘 걸었을 때 발생하는 실행 계획
- 예시 : id가 19 이상이고 27 이하인 데이터를 가지고 오라 했을 때 Root에서 타고 내려옴 -> 필요한 부분만 데이터를 읽게 됨
- 탐색 데이터를 줄여서 디스크 IO를 줄이게 됨
index
- index full scan으로 인덱스 전체를 다 읽음
- 네이밍이 좋지 않지만, Full Table Scan 보다는 성능이 좋음
- 전체 데이터 25% 이하를 조회할 때
- 인덱스는 데이터 파일보다는 크기가 작기 때문
- 그럼에도 불구하고 index range scan 보다는 성능이 좋지 않음
인덱스 적용 사례(1)
기본 컬럼에 인덱스 적용
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| id | int | No | Pri | null | auto_increment |
| nickname | varchar(20) | NO | Null | ||
| track | varchar(20) | No | Null | ||
| age | int | No | Null |
- id는 cluster Index가 미리 걸려있을 것
대체 어느 컬럼에 인덱스를 걸어야 할까?
-
서비스의 특성상 무엇에 대한 조회가 많이 일어나는지 파악
- 서비스에서 nickname에 대한 조회가 많다고 가정
-
카디널리티가 높은 컬럼에 대해 인덱스 생성
- 백엔드 80, 프론트 40 이라고 가정
- 카디널리티가 2개 뿐으로 다소 비효율
-
그래서 발표자는 어디다가? nickname에 걸었음
- 조회 성능이 2.55초 -> 0.72초
인덱스 적용 사례(2)
복합 인덱스 적용
- 복합 인덱스 : 두 개 이상의 컬럼을 합쳐서 인덱스를 만드는 것
- 하나의 컬럼으로 인덱스를 만들엇을 때 보다 더 적은 데이터 분포를 보여 탐색할 데이터 수가 줄어듬
- 결합 인덱스, 다중 컬럼 인덱스, Composite Index라고도 불림
ALTER TABLE crew ADD INDEX idx_crew_age_nickname (age, nickname);- 영상에서 나이순, nickname 순으로 정렬
| age | nickname |
|---|---|
| ... | ... |
| 23 | 티거 |
| 24 | 파랑 |
| 25 | 나인 |
| 25 | 무비 |
| ... | ... |
| 26 | 동키콩 |
| 28 | 리버 |
아래와 같은 쿼리를 통해 탐색 범위를 줄일 수 있을 지 생각하면 복합 인덱스를 쓸 수 있을지 없을지 알 수 있음
select * from crew where age >= 25;- 나이 25이상이니까 나이가 index에 포함되기 때문에 탐색 범위를 줄일 수 있음
SELECT * FROM crew Where age >= 26 AND nickname >= '토르';- 나이가 26 이상이고, nickname이
토르보다 뒤에 나오는 사람들을 가져 옴- 나이 순으로 정렬되어 있고 닉네임 순으로 정렬되어 있기 때문에 탐색 범위를 줄일 수 있음
select * from crew where nickname >= '동키콩';- 만약 닉네임 순으로만 확인하려 한다면?
- 이 기준으로는 원하는 만큼 데이터 탐색 범위를 줄일 수 없음
- 동키콩 다음인 티거, 파랑, 나인, 무비 등은 동키콩 나이인 26 이전인 23~25세에 분포되어 있음
- Full Table Scan을 읽게 됩니다.
인덱스 적용 사례(3)
- 인덱스를 사용하여 처리하는 쿼리 중 가장 큰 부하를 차지하는 부분은 인덱스 검색에서 일치하는 키 값의 레코드를 읽는 것
- 인덱스를 찾고 해당 인덱스로 데이터 파일에서 매칭시켜서 가져와야 함
- 추가적인 디스크 IO 발생
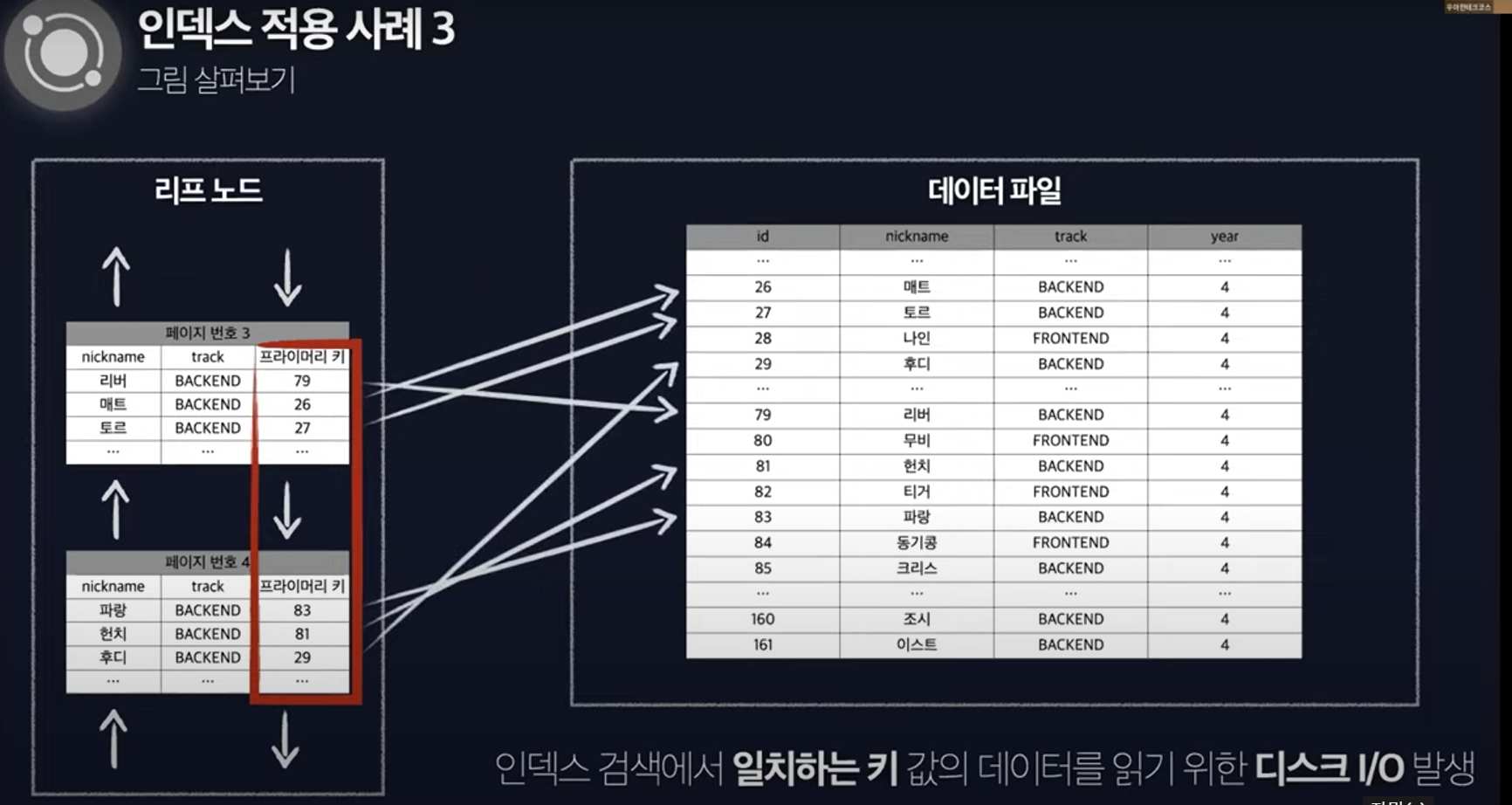
- N개의 인덱스 검색할 때 최악의 경우 N번의 디스크 IO
- 쿼리 최적화의 가장 큰 목적은 디스크 IO를 줄이는 것
예시
SELECT *
FROM crew
WHERE nickname BETWEEN 'a' AND 'd' AND track = 'BACKEND'- crew 테이블 a와 d 사이의 닉네임을 가진 백엔드 크루 조회
ALTER TABLE crew ADD INDEX idx_crew_nickname_track (nickname, track);- 원활한 조회를 위해 nickname과 track에 복합 인덱스 설정
실행계획 살펴보기
EXPLAIN SELECT *
FROM crew
WHERE nickname BETWEEN 'a' AND 'd' AND track = 'BACKEND';| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | crew | Null | All | idx_crew_nickname_track | NULL | NULL | NULL | 997853 | 3.78 | Using where |
- 옵티마이저는 전체 데이터의 20 ~ 25% 이상을 조회하는 경우 인덱스를 조회하는 것 보다 데이터 파일을 바로 읽는 것(Full Table Scan)이 효율적이라 판단
- Full Table Scan 발생
- 예시에서 Full인 이유가 백엔드 80명, 프론트 40명이라해서 백엔드 인원이 더 많아 탐색 대상이 더 많고 / 아마도 a ~ d 비율도 더 많다고 알기 때문인듯
커버링 인덱스를 활용하여 개선
- 인덱스로 설정한 컬럼만 읽어 쿼리를 모두 처리할 수 있는 인덱스
- 불필요한 디스크 IO를 줄여 조회 시간 단축
적용
- 모든 컬럼 조회
SELECT *
FROM crew
WHERE nickname BETWEEN 'a' AND 'd' AND track = 'BACKEND'- nickname, track 조회
SELECT nickname, track
FROM crew
WHERE nickname BETWEEN 'a' AND 'd' AND track = 'BACKEND'- 추가적인 데이터 파일 읽지 않고 인덱스만 읽어 불필요한 디스크 I/O시간 단축

실행계획 살펴보기
EXPLAIN SELECT nickname, track
FROM crew
WHERE nickname BETWEEN 'a' AND 'd' AND track = 'BACKEND';| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | crew | Null | range | idx_crew_nickname_track | NULL | NULL | NULL | 997853 | 3.78 | Using where; Using index |
- Index Range Scan 발생
- 커버링 인덱스를 타게 되면 Extra 컬럼에 Using index가 표시
결과
- 100만건 기준 3.04초 -> 0.54초(커버링 인덱스)
커버링 인덱스의 숨겨진 비밀
- 프라이머리 키인 id를 함께 조회한다면 Full Scan인가? Index Range Scan인가?
SELECT id, nickname, track
FROM crew
WHERE nickname BETWEEN 'a' AND 'd' AND track = 'BACKEND';EXPLAIN SELECT id, nickname, track
FROM crew
WHERE nickname BETWEEN 'a' AND 'd' AND track = 'BACKEND';| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | crew | Null | range | idx_crew_nickname_track | NULL | NULL | NULL | 997853 | 3.78 | Using where; Using index |
- 이전과 동일하게 커버링 인덱스를 사용하고 있음
- id(Primary Key)는 복합 인덱스로 설정하지 않았는데 왜 같은 결과가 나온 걸까?
InnoDB 세컨더리 인덱스의 특수한 구조 덕분
- 리프노드에는 실제 레코드 주소가 아닌 클러스터드 인덱스가 걸린 PK를 주소로 가짐
- nickname, track, id 모두 활용 가능!
- 리프노드 구조
| nickname | track | primary key(id) |
|---|---|---|
| 리버 | BACKEND | 79 |
| 매트 | BACKEND | 26 |
| 토르 | BACKEND | 27 |
| ... | ... | ... |
인덱스 적용 사례(4) - 인덱스 컨디션 푸시다운
-
study_log (학습로그)
- id : INT
- crew_id : INT
- title : VARCHAR(50)
- content : TEXT
- type VARCHAR(20)
- created_at : DATETIME
- updated_at : DATETIME
-
1명의 크루는 N개의 학습 로그 작성 가능
-
type에는 SHARE, QUESTION 등 학습 로그의 목적을 명시
-
type 기준 빠른 조회를 위한 인덱스 생성
ALTER TABLE study_log ADD INDEX idx_study_log_type (type);예시 살펴보기
SELECT *
FROM study_log
WHERE type = 'QUESTION'
AND created_at BETWEEN '2022-10-07 00:00' AND '2022-10-13 00:00';- QUESTION 목적을 가진 2022-10-07 ~ 2022-10-13 사이 학습 로그 조회
실행 계획 살펴보기
Explain SELECT *
FROM study_log
WHERE type = 'QUESTION'
AND created_at BETWEEN '2022-10-07 00:00' AND '2022-10-13 00:00';| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | study_log | ref | idx_study_log_type | idx_study_log_type | 82 | const | 487403 | 11.11 | Using where |
-
idx_study_log_type을 통한 REF
- 언뜻 보면 index가 잘 되는 것 같음
-
Extra 컬럼의 Using where
Extra 컬럼
- 쿼리의 실행 계획에서 성능에 관련된 중요한 내용 표시
- 내부적인 처리 알고리즘에 대해 조금 더 깊은 내용을 포함
Extra 컬럼의 Using where
- InnoDB 스토리지 엔진을 통해 테이블에서 행을 가져온 뒤, MySQL 엔진에서 추가적인 체크 조건을 활용하여 행의 범위를 축소한 것
그림 살펴보기
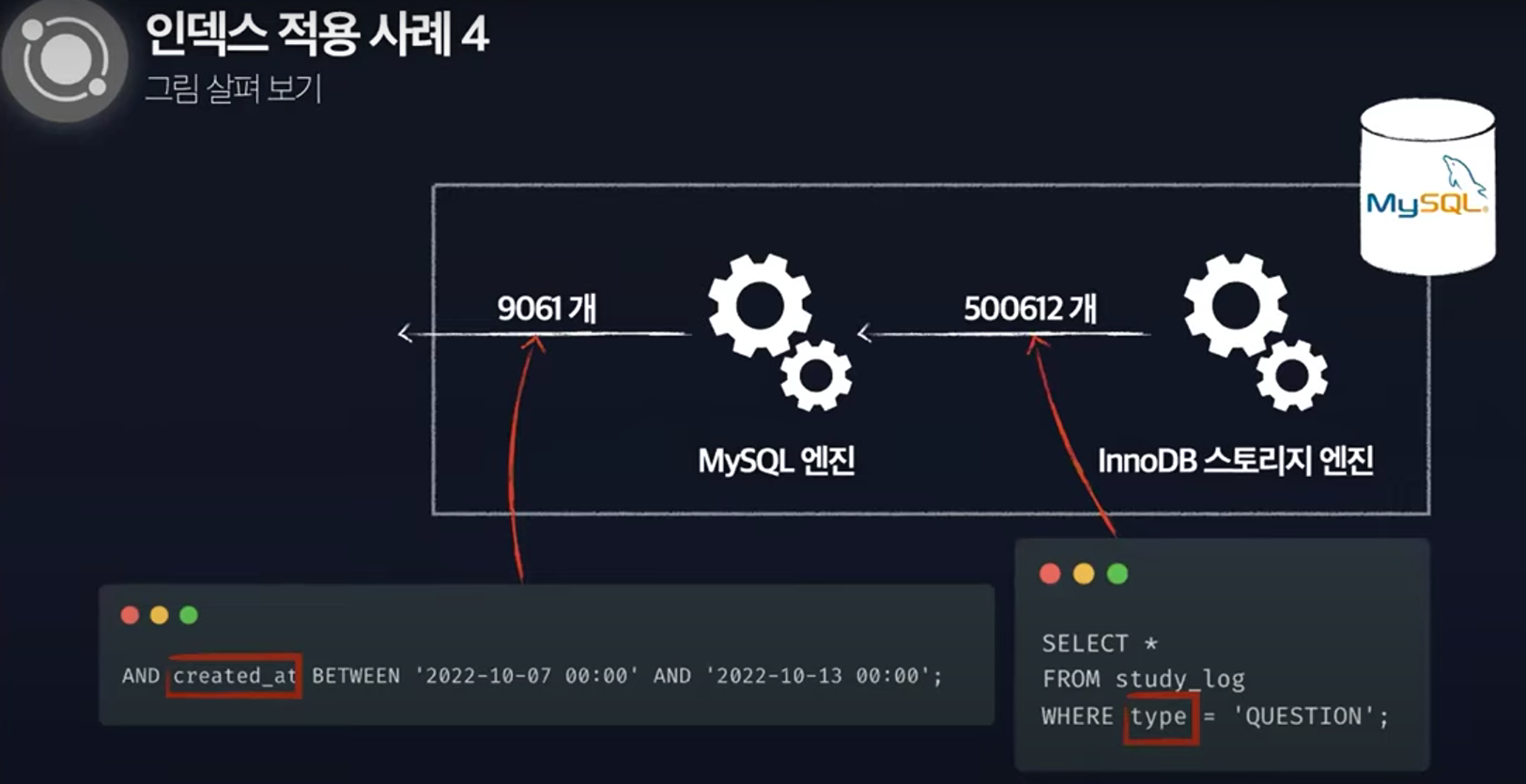
- 불필요한게 너무 많은 데이터를 디스크에서 읽어버린 셈
복합 인덱스를 통해 개선 가능
ALTER TABLE study_log ADD INDEX idx_study_log_type_careated_at (type, created_at);- where 조건에서 사용하고 있는 type과 created_at 기반 복합 인덱스 생성
복합 인덱스 후 실행 계획
Explain SELECT *
FROM study_log
WHERE type = 'QUESTION'
AND created_at BETWEEN '2022-10-07 00:00' AND '2022-10-13 00:00';| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | study_log | range | idx_study_log_type_created_at | idx_study_log_type_created_at | 82 | const | 487403 | 11.11 | Using index condition |
- idx_study_log_type_created_at을 통한 Index Range Scan이 발생한 것을 확인할 수 있음
인덱스 컨디션 푸시다운
-
Extra 컬럼의 Using Index Condition은 인덱스 컨디션 푸시다운 으로 인해 표시
-
인덱스 컨디션 푸시다운(ICP, Index Condition Pushdown)이란, MySQL이 인덱스를 사용하여 테이블에서 행을 검색하는 경우의 최적화를 의미
-
ICP를 활성화하고 인덱스의 컬럼만 사용하여 WHERE 조건의 일부를 평가할 수 있는 경우 MySQL 엔진은 WHERE 조건 부분을 스토리지 엔진으로 푸시
-
ICP는 최신 버전의 MySQL을 사용할 경우 기본적으로 활성화
다시 그림을 살펴보면
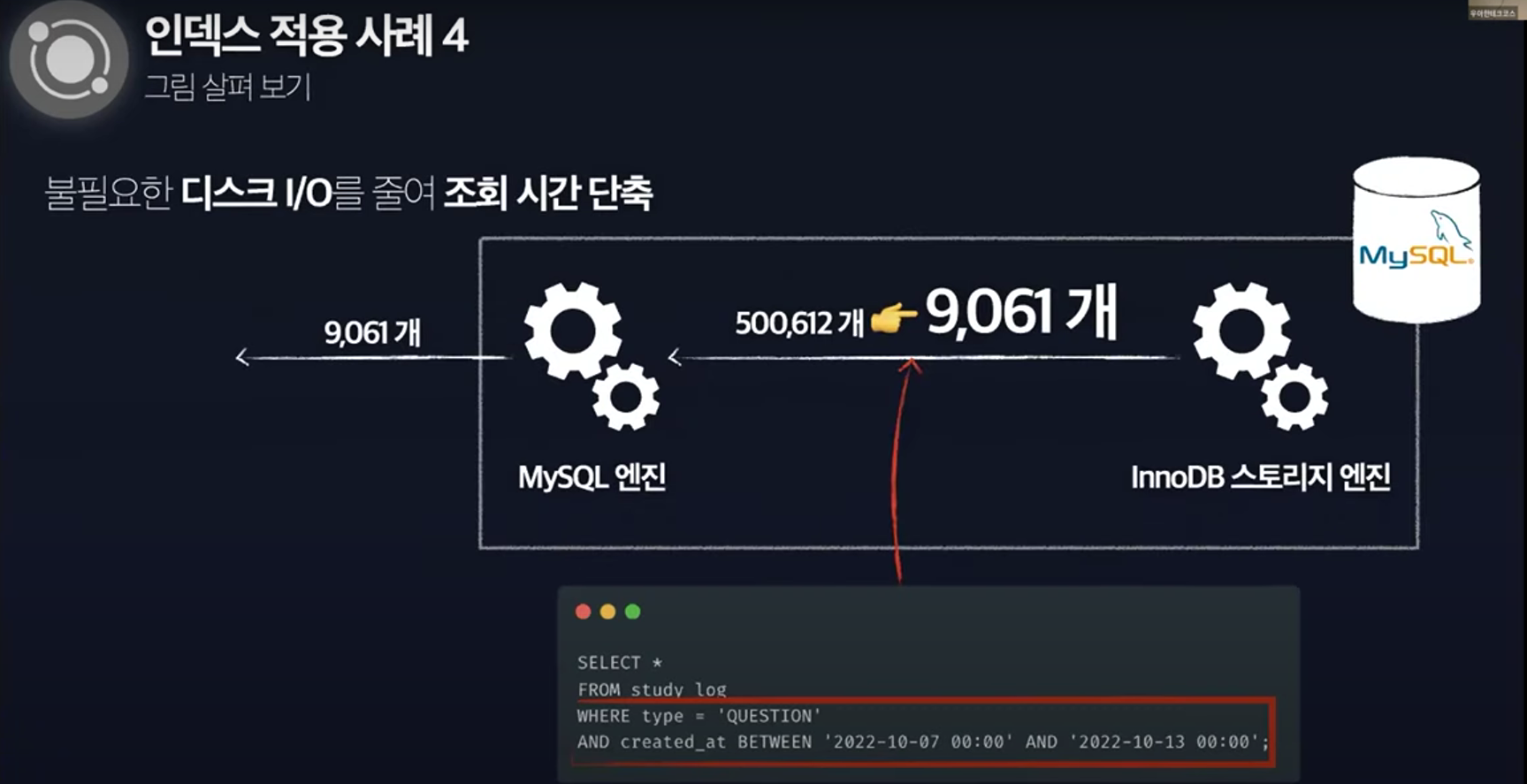
- InnoDB 스토리지 엔진이 복합 인덱스 조건을 모두 활성화 하여 불필요한 데이터를 전달하지 않게 된다.
성능 비교 - 100만건 기준
- 인덱스 푸시다운 하지 않은 경우 : 6.37초
- 인덱스 푸시 다운 한 경우 : 0.42초
- 단순히 시간만 보고 성능을 판단하는 것이 아니라 Extra 컬럼까지 인덱스로 탔나 안탔나도 확인을 헤야함
더 나아가기 - 다양한 인덱스
- 인덱스 스킵 스캔
- 루스 인덱스 스캔
- 유니크 인덱스
- 전문 검색 인덱스
- 옵티마이저
- ...

비슷한 어려움을 겪는 누군가에게 도움이 되길