
-
프로그래밍 패러다임 : 절차 지향, 객체 지향, 함수형 프로그래밍 등
-
데이터 저장 기술 : 파일 시스템, 관계형 데이터베이스(RDB), NoSQL DB 등
-
영상에서는 객체지향 패러다임과 관계형 DB 중심으로 다룸
-
데이터 접근 기술 : 프로그래밍 패러다임에서 데이터 저장기술에 접근을 가능하게 하는 기술
-> 데이터를 저장하기 위해 프로그래밍 패러다임과 별개로 독립적으로 발전한 기술 패러다임
-> JAVA에서 관계형 DB를 사용하기 위해서는 서로 다른 기술 패러다임간 인터페이스(데이터 접근 기술) 필요
-> JDBC, SQL Mapper, ORM 등이 있음 -
자바에서 DB 접근
1) DB Connection 얻기
2) SQL 전달 및 실행 : DB에게 원하는 동작을 SQL로 표현하여 연결된 커넥션을 통해 DB에게 전달
3) DB Connection 닫기 : 전달된 SQL을 수행하고 결과를 응답, 서버는 응답 결과를 활용하고 커넥션을 닫는다. -
데이터 접근 기술의 어려움 : 각 DB마다 Connection 연결 방법, SQL 전달 방법, 응답 방법이 모두 다름
- 문제점 1) DB를 다른 DB로 변경하면 서버에 개발된 DB 코드도 함께 변경해야 함
- 문제점 2) 개발자가 각각의 DB마다 커넥션 연결, SQL 전달, 결과 응답 방법을 새로 작성해야 한다.
- JDBC가 없다면? MySQL 사용 => 이용자가 늘어 ORACLE DB 추가 => 접근 방식이 달라 새로운 코드를 짰어야 함 => 데이터 접근 방식이 같았다면 확장, 변경 시 코드 수정이 필요 없었을 듯한 생각 => JDBC의 등장
-
JDBC(Java Database Connectivity) : 자바를 이용해 다양한 데이터 저장 기술에 일관적으로 접근할 수 있는 데이터 접근 기술
- 데이터 저장 기술을 데이터 소스라는 추상화된 인터페이스를 통해 접근
-> 데이터 소스가 파일 시스템, 어떤 DB인지, 커넥션 풀 라이브러리인 지를 고려하지 않고 일관된 접근이 가능함 - 한계
- 반복되는 데이터 접근 관련 코드(커넥션 얻고, statement생성, ... connection 닫기) 중복
- 핵심 관심사(DB가 수행할 동작을 표현한 SQL) 미분리
-> 핵심 관심사 : 보통 CRUD 연산정도, 그 외 나머지 코드(비핵심 관심사) => JDBC를 사용할 경우 분리가 안되고 공존
- Java Code 내 SQL 직접 전달 문제
-> JDBC가 사용하는 SQL은 단순 문자열(String), 컴파일 체크 불가(문법 오류, 오타 발생 확률 높음)
-> 자바 어플리케이션 내 다른 언어인 SQL을 포함, SQL이 핵심 로직을 담당하는 주객 전도(SQL을 이해하고 있어야 하는 개발자..)
장점 단점 여러 데이터 저장 기술을 일관적 방식으로 접근 가능 Connection, SQLException 처리, Transaction 등 직접 처리 필요 Transaction, 예외 처리 등 세부 조정 가능 Transaction 등 직접 처리 필요 일관적 데이터 접근 중복코드, 관심사 미분리 - 데이터 저장 기술을 데이터 소스라는 추상화된 인터페이스를 통해 접근
-
SQL Mapper : SQL문과 객체의 필드를 매핑하여 데이터를 객체화
-> Spring JDBC, MyBatis 등 -
Spring JDBC Templete에서 코드의 중복을 해결하고 SQL Exception 문제도 내부적으로 해결 => 불필요한 코드 제거, 가독성 증가
-> 하지만 반복적 데이터 바인딩, SQL쿼리문, 자바와 SQL문 분리의 문제는 해결하지 못함 -
SQL Exception : JDBC 관련 로직을 실행하는 동안 발생하는 기본 예외 클래스(checked Exception이라 try-catch 필수)
-> 사용자의 잘못된 SQL문 입력으로 발생하는 예외가 대부분임
-> 예외가 발생해도 사용자가 다시 입력하지 않는 이상 해결이 안되는데도 try-catch문이 필수 구현.. 다소 무의미한 코드
-> JDBC Template에서는 unchecked Exception으로 바꿔서 해결 -
MyBatis : XML 서술자나 어노테이션을 사용하여 자바 오브젝트와 SQL 사이 자동 매핑 기능을 지원하는 자바 퍼시스턴스 프레임워크
-> XML 코드(SQL 쿼리문만)와 인터페이스(자바코드만)를 정의하여 사용
-> 자바코드와 SQL 분리 문제 해결
-> 반복적인 데이터 바인딩 문제 : MyBatis 내부 동적 바인딩으로 해결
-> 객체지향 패러다임 불일치 + 반복적 SQL의 문제가 남음.. -
ORM : 객체와 RDB 사이 패러다임 불일치에서 오는 불편함을 해결하기 위해 객체와 RDB를 변환시켜주는 데이터 접근 기술
-> 객체와 관계형 DB를 적절하게 변화시켜줌
-> 관계형 DB에 담긴 정보를 객체를 다루는 것처럼 관리 가능
-> 반복적인 SQL 직접 작성할 필요가 없고, 객체에 집중한 설계 가능
-> 필요한 SQL문을 자동으로 생성한 뒤 결과를 객체로 돌려줌(객체에 집중한 설계가 가능) -
JPA : Java 진영 표준 ORM 기술 명세
-
세분성 문제 : 한번 결정된 테이블을 변경하는 것은 비용 소모가 큼
| 테이블 | 객체 |
|---|---|
| 변경이 어렵다 | 변경이 쉽다 |
| 모이는 경향(집합적) | 분리되는 경향(분해적) |
-> 객체지향의 세분성(Granularity) : 객체의 수는 테이블의 수보다 빠르게 증가
-> 세분성 문제 : 어플리케이션 규모가 커질 수록 객체와 테이블의 대응관계의 괴리가 커져 관계를 파악하기 힘들어 지는 문제
-> JPA : DB테이블 구조(객체를 가질 수 없고 각 하나의 필드로만 가짐)로 객체를 설계했을때 발생하는 문제를 해결(객체를 필드로 가질 수 있도록) => 손쉽게 객체를 분류할 수 있게 함
-
상속 : DB구조로 구현 시 상속 관계인 두 테이블에 모두 쿼리를 날려야 함(DB에는 상속이라는 개념 존재x)
-> JPA에서는 상속하는 각 객체를 만들어주면 JPA가 각 객체에 맞춰 테이블을 나눈 후 여러 INSERT를 대신 처리
-> 여러 테이블 파악, SQL 작성에서 벗어나 객체 설계에 도움을 줌 -
동일성 문제 : 데이터 접근과정에 의해 객체 연속성이 깨지는 문제
-> 객체의 id를 DB id 정책(Auto Increment 정책 의존)
=> 테이블에 저장된 후에야 객체가 id를 가지는 문제
=> 객체가 id를 가지기 전 불안전한 상태
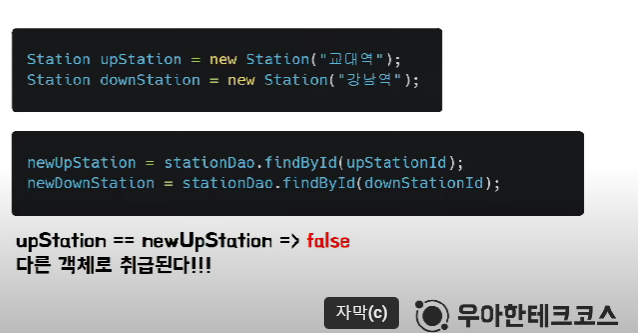
=> JAVA에서는 다른 객체로 인식하므로 newUpStation 객체로 활용해야 함(기존 upstation은 버림) -
JPA는 트랜잭션 내 엔티티를 동일하게 봄
-> 동일한 객체 주소에 ID값을 추가하여 수정함
-> 객체의 동일성이 유지되므로 불필요하게 객체를 새로 생성하지 않아도 됨
ex) newUpStation과 같은 객체 불필요
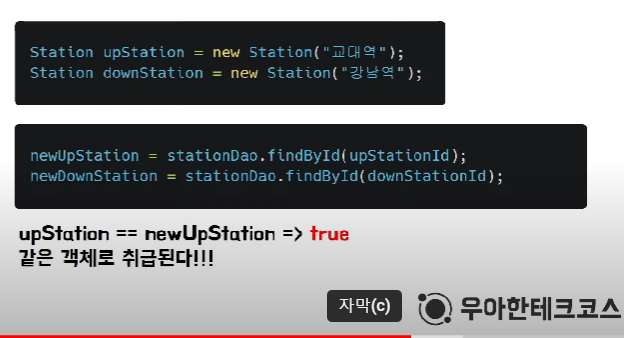
-
관계 문제 : RDB(외래키), 객체(참조) => 객체가 외래키만 가지고 관계를 형성할 수 없음 => 외래키를 토대로 객체의 참조를 얻어야만 관계를 맺을 수 있음
-> 패러다임 불일치 : 관계형 DB에서 외래키를 중심으로 맺는 테이블, 참조를 중심으로 맺는 객체의 차이에서 오는 불일치 -
JPA에서 객체들 끼리 참조값을 가지려면 관계를 설정하고, 객체를 저장
-> OneToMany, ManyToOne
-> 참조를 외래키로 변환해서 적절한 INSERT SQL을 DB에 전달
-> 객체를 조회할 때 외래키를 참조로 변환하는것도 JPA가 처리
-> 즉, JPA가 참조와 외래키 매핑을 자동으로 해줌, 객체와 테이블 매핑에 관련 코드를 작성할 필요가 없음 -
JPA : 객체를 객체지향적으로 사용하는데 필요한 부가적인 일들을 대신해줌 -> 코드 작성의 부담 완화
-
객체 탐색(navigation) 문제
-> 데이터 중심 설계 : 처음 실행하는 SQL에 따라 객체를 어디까지 탐색할 수 있는지 정해줌 => 객체의 참조 가능여부는 SQL에 달려있어 계층분할x => 온전히 객체만으로 동작을 파악할 수 없어 SQL 의존을 피할 수 없음
-> JPA에서는 지연로딩(Lazy Loading)으로 해결
=> 연관 객체를 직접 사용할 때까지 조회를 미룬다. -
JDBC, SQL MApper, ORM은 결국 객체지향 기술 : SQL 의존코드, 데이터 중심 설계, 패러다임 불일치 문제 해결 => 좀 더 객체지향 프로그래밍과 핵심 비즈니스 로직 개발에만 집중할 수 있도록 해줌
