
N+1문제란?
- 요청이 1개의 쿼리로 처리 되길 기대했는데, N개의 추가 쿼리가 발생하는 현상
지연로딩
- 엔티티를 조회할 시 사용할 때 까지 데이터 로딩을 늦추는 것
- @OneToMany(mappedBy = "크루", fetch = FetchType.LAZY)
- Lazy 부분 생략해도 OneToMany는 자동 Lazy
- findAll로 조회하는 상황 가정
- @OneToMany(mappedBy = "크루", fetch = FetchType.LAZY)
- JPQL : 엔티티를 대상으로 쿼리 작성
- findAll() ->
select * from crew로 변환- crew : 할일 => 1 : N 관계
- JPA 요청 보내고 크루를 가져옴, 할일 목록은 지연로딩으로 proxy 객체로 가져옴
- 크루 한명당 몇개의 할일 목록이 있는지 확인 하려 함
for(Crew crew : CrewList) { // 크루1, 2, ... crew.목록(proxy).getSize(); }- JPA가 1차 캐시에서 크루1의 목록 있는지 확인
- 없어서
select * from 할일 where 크루_id = 1
- 없어서
- 2, 3, ...번째 크루도 목록이 없어 N명의 추가 쿼리 발생
- N+1 문제 발생!
- findAll() ->
- 데이터가 100만건이라면? 쿼리가 100만개
해결 방법 : Fetch Join
- Fetch join : 연관된 엔티티나 컬렉션을 한 번에 같이 조회하는 기능
- 연관된 엔티티까지 영속성 컨텍스트에 전부 올려버림
쿼리문에 직접 fetch 명시,@EntityGraph 사용하는 방법존재- 영상에서는 쿼리문에 명시 방식 사용
크루_Repository.findAll()
// select 크루.*, 할일.* from 크루 join fetch 할일 로 쿼리 발생
for(Crew crew : CrewList) {
// 크루1, 2, ...
crew.목록(proxy).getSize();
}- 최초에 관련된 데이터를 한번에 가져와서 객체화를 해주었기 때문에 DB를 거치지 않고, (영속성 컨텍스트에서) 데이터를 꺼내서 반환(1개의 쿼리로 문제 해결)
select 크루.*, 할일.* from 크루 join fetch 할일
즉시(Eager) 로딩으로 지정하면 N+1 문제는 없는 것 아닐까?
-
즉시 로딩으로 지정해도 동일하게 발생한다.
-
JPQL 쿼리 만들때 : 처음 쿼리를 만들 때 크루에 연관관계가 있는 엔티티는 신경 쓰지 않고, 조회 대상이 되는 Entity 기준으로 쿼리 생성
- Crew에 연관관계는 신경 쓰지 않고 최초에 Crew에 대해서만 쿼리를 뿌림
- 그 이후 연관된 엔티티인 할일 확인
- fetch 전략이 Eager를 보고
아 지금 당장 필요하네하며할일 엔티티를 조회하는 N개의 쿼리 추가 발생
-
즉시로딩을 최대한 사용하지 않고, 지연 로딩 + fetch join 사용 권장
Fetch join이면 N+1 다 해결되네요?
그 전에 DB에서 1:N 관계?
- Entity에서는 Crew 1개에 할일 N개 리스트를 1개의 Entity에서 가질 수 있음
- DB에서는 한줄로 해당 데이터 전체를 표현할 수 없음
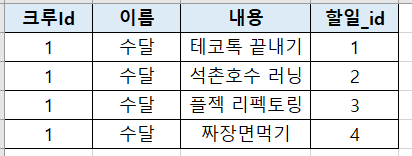
Crew 100여명에서 5명만 보고싶다면?
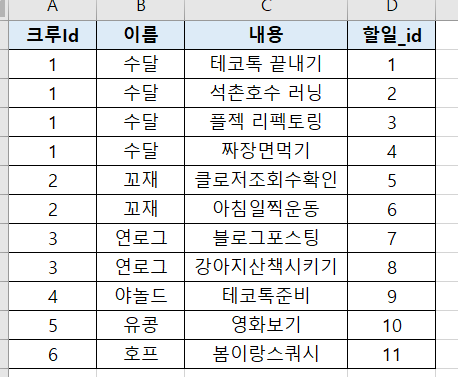
- DB에서 Limit을 걸어서 추출하면 되지않겠나?
- DB에서
offset 1 ~ limit 5하겠지?- 문제점 1 : 5명을 기대했지만 수달, 꼬재 총 2명만 추출되는 문제 (예상했던 결과와 다름)
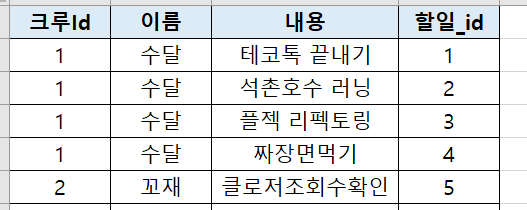
- 문제점 2 : 수달은 모든 할일을 가져왔지만, 꼬재는 할일 중 하나만 가져오는 문제 (데이터 누락 문제)
- 문제점 1 : 5명을 기대했지만 수달, 꼬재 총 2명만 추출되는 문제 (예상했던 결과와 다름)
- DB에서
아 데이터 정확성의 문제가 있으니 JPA가 해결해줄게!
-
일단 데이터를 전부다 가져오고 인메모리에서 내가 원하는대로 바꿀게
- 쿼리문에서 limit이 없음
- Data 전체 full scan으로 가져오고 메모리에서 페이지 처리
- 100만건을 메모리에서 관리한다면 메모리 부하가 일어날듯
-
해결하는 방법으로는 @ManyToOne일때 페이징 처리, @BatchSize()로 해결 등

비슷한 어려움을 겪는 누군가에게 도움이 되길