[영상후기] transaction isolation level 설명합니다! isolation이 안될 때 나타날 수 있는 여러 현상들과 snapshot isolation도 같이 설명합니다!!
영상후기

Isolation이 안될 때 나타날 수 있는 현상들
- Dirty read : commit 되지 않은 변화를 읽음
초기값 : x = 20 / y = 20
A 트랜잭션은 x에 y를 더해서 값 갱신, B 트랜잭션은 y값을 20에서 60으로 업데이트- A 트랜잭션에서 x를 읽음, read(x) => 20
- B 트랜잭션에서 y를 읽고 60변경, read(y) => 20, write(y=60)
- A 트랜잭션에서 x = x+y로 업데이트 하기 위해 y를 읽고, x + 60 후 커밋 => read(y) => 60, read(x=80);
- B 트랜잭션에서 Rollback 발생 -> y = 60 -> 20(기존값)
- A 트랜잭션 작업으로 얻은 결과는 Rollback이 되어야 하는데 이미 commit되어버림
- Non-repeatable read(=Fuzzy read) : 같은 데이터의 값이 달라짐
A 트랜잭션은 x를 두번 읽는다, B 트랜잭션은 x에 40을 더한다
- A가 처음에 x를 읽는다
- B가 x를 읽고, x에 40을 더한 후 커밋한다
- A가 두번째 x를 읽는다. (처음에 읽을때와 값이 달라짐)
- Phantom read : 없던 데이터가 생김
튜플 t1(..., v=10) / t2(..., v=50)
- 트랜잭션 A : v가 10인 데이터를 두 번 읽는다
- 트랜잭션 B : t2의 v를 10으로 바꾼다
- 트랜잭션 A에 의해 read(v=10) => t1 결과를 얻음
- 트랜잭선 B에 의해 write(t2.v = 10) => t2의 v값을 업데이트 후 커밋
- 트랜잭션 A에 의해 read(v=10) => t1, t2의 결과를 얻음 이후 commit
- 트랜잭션의 결과 없던 데이터(t2)가 추가됨
- update 말고도 insert 트랜잭션과 동시에 실행될 때도 발생할 수 있음
- 이상 현상들이 모두 발생하지 않게 만들 수 있지만 제약사항이 많아져 동시 처리 가능한 트랜잭션 수가 줄어든다
- 결국 DB의 전체 처리량(throughput)이 하락하게 된다.
- 일부 이상 현상은 허용하는 몇 가지 level을 만들어 사용자가 필요에 따라 적절히 선택할 수 있도록 하게 됨
- Isolation level의 등장
Isolation level
| Isolation level | Dirty read | Non-repeatable read | Phantom read |
|---|---|---|---|
| Read uncommitted | O | O | O |
| Read committed | X | O | O |
| Repeatable read | X | X | O |
| Serializable | X | X | X |
- Read uncommitted가 가장 동시성이 높으나 격리성이 제일 낮음
- Serializable : 이상 현상 자체가 발생하지 않는 level
- 세 가지 이상 현상을 정의하고 어떤 현상을 허용하는지에 따라 각각의 Isolation level 구분
- 애플리케이션 설계자는 Isolation level을 통해
전체 처리량(throughput)과 데이터 일관성 사이에서 어느 정도 거래(trade)를 할 수 있다
Isolation level의 비판
A Critique of ANSI SQL Isolation Levels- ANSI/ISO standard SQL 92에서 정의한 Isolation level 비판 논문
- 세 가지 이상 현상의 정의가 모호하다
- 이상 현상은 세 가지 외에도 더 있다
- 상업적인 DBMS에서 사용하는 방법을 반영해서 Isolation level을 구분하지 않았다
- SNAPSHOT ISOLATION
논문에서 말하는 추가 이상 현상
- Dirty write : commit 안된 데이터를 write 할 때
- rollback시 정상적인 recovery 매우 중요하기에 모든 Isolation에서 dirty write를 허용하면 안된다.
x 초기값 : 0
트랜잭션 A : x를 10으로 바꾼다.
트랜잭션 B : x를 100으로 바꾼다.
- 트랜잭션 A에 의해 write(x=10)
- 트랜잭션 B에 의해 write(x=100)
- 트랜잭션 A에서 abort 발생 -> Rollback을 하게되면 트랜잭션 B가 사라지기에 Rollback 수행하지 않았다 치고
- 트랜잭션 B에서도 abort 발생 -> x=100 이전 상태인 10으로 rollback
- 10도 abort가 된 값으로 rollback이 되면 안됨
- Lost update : 업데이트를 덮어씀
x 초기값 : 50
트랜잭션 A : x에 50을 더한다.
트랜잭션 B : x에 150을 더한다.
- 트랜잭션 A가 x를 읽는다 read(x) => 50
- 트랜잭션 B가 x를 읽는다 read(x) => 50
- 트랜잭션 B가 x에 150을 더하고 커밋한다. write(x=200), commit
- 트랜잭션 A가 x에 50을 더하고 커밋한다. write(x=100), commit -> A가 읽었던 값은 50이였으니
- Dirty read 확장 : commit 되지 않은 변화를 읽음
- abort가 발생하지 않아도 dirty read가 될 수 있다
x 초기값 : 50, y 초기값 : 50
트랜잭션 A : x가 y에게 40을 이체한다.
트랜잭션 B : x와 y를 읽는다.
- 트랜잭션 A가 x를 읽는다. read(x) => 50
- 트랜잭션 A가 이체를 위해 x에서 40을 뺀다. write(x=10)
- 트랜잭션 B가 x와 y를 읽고 커밋 read(x) => 10 / read(y) => 50 / commit
- 트랜잭션 A가 y를 읽는다. read(y) => 50
- 트랜잭션 A가 y를 업데이터 하고 커밋. write(y=90) / commit
abort가 발생(rollback)하지 않아도 트랜잭션B에서 dirty read 발생
- Read skew : inconsistent한 데이터 읽기
x 초기값 : 50, y 초기값 : 50
트랜잭션 A : x가 y에게 40을 이체한다.
트랜잭션 B : x와 y를 읽는다.
- 트랜잭션 B가 x를 읽는다. read(x) => 50
- 트랜잭션 A가 x를 읽는다. read(x) => 50
- 트랜잭션 A가 이체를 위해 x에서 40을 뺀다. write(x=10)
- 트랜잭션 A가 y를 읽는다, read(y) => 50
- 트랜잭션 A가 y에 40을 추가하고 커밋한다 write(y=90) / commit
- 트랜잭션 B가 y를 읽고 커밋한다. read(y) => 90
트랜잭션 B는 일관성이 없는 데이터를 읽음
- Write skew : inconsistent한 데이터 쓰기
x 초기값 : 50, y 초기값 : 50, x + y >=0 제약사항
트랜잭션 A : x에서 80을 인출한다
트랜잭션 B : y에서 90을 인출한다.
- 트랜잭션 A가 x에서 80을 인출해도 제약사항에 맞는지 확인을 위해 x와 y를 읽는다. / read(x) => 50, read(y) => 50
- 트랜잭션 B가 y에서 90을 인출해도 제약사항에 맞는지 확인을 위해 x와 y를 읽는다. / read(x) => 50, read(y) => 50
- 트랜잭션 A가 조건을 만족함을 보고 x에서 인출한다. write(x = -30), commit
- 트랜잭션 B가 조건을 만족함을 보고 y에서 인출한다. write(y = -40), commit
트랜잭션 수행 결과 일관성이 없게 데이터가 작성됨(제약조건 위반)
- Phantom read 확장 : 같은 조건을 두번 읽는 것이 아니여도 연관된 데이터를 읽을 때도 새로운 데이터가 발생할 수도 있다.
튜플 t1(..., v=7), cnt = 0 ( v>10 개수를 나타내는 변수)
트랜잭션 A : v > 10인 데이터와 cnt를 읽는다.
트랜잭션 B : v = 15인 t2를 추가하고 cnt를 1 증가한다.
- 트랜잭션 A에 의해 v > 10인 튜플 검색 / read(v > 10) => .
- 트랜잭선 B에 의해 튜플 삽입 / write(insert t2 : ..., v=15)
- 트랜잭션 B에 의해 cnt 값 증가하기 위해 기존 cnt값 읽기 / read(cnt) => 0
- 트랜잭션 B에 의해 cnt 값 업데이트 write(cnt = 1) / 이후 commit
- 트랜잭션 A에 의해 cnt 값을 읽음 read(cnt) => 1 / 이후 commit
기존과 다른 조건을 읽는 경우에도 새로운 데이터 발생
SNAPSHOT ISOLATION
- 기존 표준에서 정의한 Isolation과는 약간 다름
- 기존 Isolation은 이상 현상을 정의한 다음 각 레벨이 얼마만큼 허용하는지에 따라 구분
- concurrency control 구현 방식에 기반하여 레벨 정의
- snapshot : 특정 시점에서의 형상 기반
- 트랜잭션 시작하는 시점을 기준으로 잡음
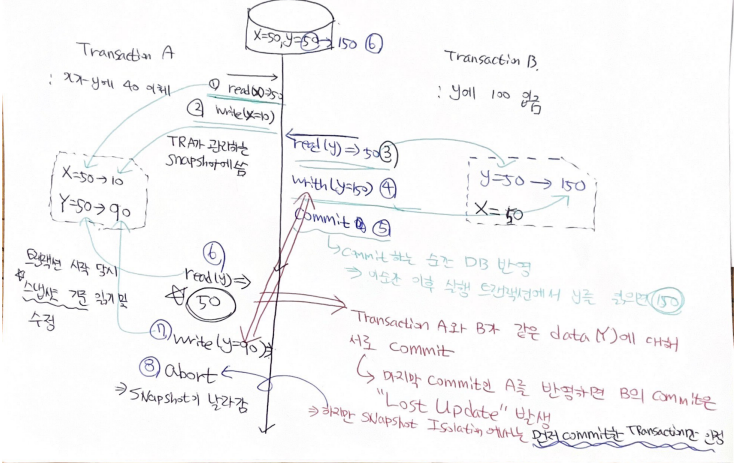
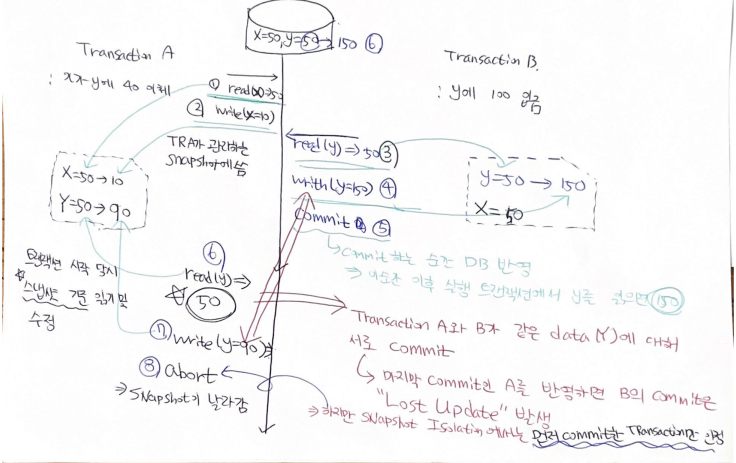
초기 X : 50, Y : 50
트랜잭션 A : X가 Y에 40 이체
트랜잭션 B : Y에 100 입금
- 트랜잭션 A가 X를 읽는다. read(x) => 50
(이때 스냅샷 저장됨, x = 50 / y = 50)
- 트랜잭션 A가 관리하는 스냅샷에 X를 50에서 10으로 변경한다. write(x=10)
- 트랜잭션 B가 y를 읽는다. read(y) => 50
(이때 스냅샷 저장됨, x=50 / y=50)
- 트랜잭션 B가 관리하는 y의 스냅샷에 150으로 변경한다(100입금)
write(y=150)
- 트랜잭션 B가 commit하여 DB에 반영한다. (이 순간 이후 실행 트랜잭션에서 y를 읽으면 150)
- 트랜잭션 A가 y를 읽는다.(이때는 기존의 A가 관리하는 snapshot에서 읽어옴) / read(y) => 50
- 트랜잭션 A가 40 입금을 위해 A가 관리하는 스냅샷에 업데이트한다. / write(y=90)
- 트랜잭션 A가 작업을 마치고 commit 하려고 하지만, 트랜잭션 A와 B가 동일한 데이터(Y)를 수정했기에, 먼저 commit된 트랜잭션 B만 유효하다고 판단한다.
- 8-1. 따라서 A의 snapshot은 날라가게 된다.(X도 반영이 안됨)
- 먼저 commit된 내용만 반영됨
- SNAPSHOT ISOLATION은 MVCC의 한 종류
- Multi Version Concurrenct Control
- Transaction 시작 전 commit된 데이터만 보임
- First-committer win(처음 commit한 녀석이 승리)
정리
-
SQL 표준에 정의된 Isolation level은 각 3가지 현상을 얼만큼 허용하는지 따라 level을 구분
-
DB 종류에 따른 Isolation level
- MySQL : 4가지 level 제공, 표준 SQL 바탕
- Oracle : 표준 SQL Level로 level 정의
- Read Uncommitted : 제공x
- Repeatable Read, Serializable : isolation level을 Serializable로 설정
- 결과적으로 Read Committed, Serializable 2가지 사용하는 셈
- 오라클의 Serializable은 snapshot isolation으로 동작
- SQL server : 표준 SQL 정의된 level 기준 정의 및 설명
- PostgreSQL : 3가지 현상 + 이상 현상
- repeatable read : snapshot isolation level
-
주요 RDBMS는 SQl 표준에 기반해서 Isolation Level을 정의
-
RDBMS마다 제공하는 Isolation level이 다르다
-
같은 이름의 Isolation level이라도 동작 방식이 다를 수 있다.
-
즉 사용하는 RDBMS의 Isolation level을 잘 파악해서 적절한 Isolation level을 사용할 수 있도록 해야 한다.
- Default Isolation level 사용해도 크게 문제는 없겠지만 퍼포먼스 튜닝 또는 예상치 못한 이상현상 위해 각각의 특징 파악하는 것이 좋음
-
논문을 왜 본건가? 다양한 이상현상을 알고있다면 개발 시 문제를 찾아 나가는 것이 더 빠를 수도 있기에 설명함
