
정산시스템
- 주문과 결제가 1:N
- 주문과 할인 1:0..N
- 주문, 결제 10억건 이상 존재하는 상황
- 1000만건에서 10억건 되는 과정에서 얻은 Querydsl-JPA 개선 TIP
- 버전별 버전 차이가 있을 수 있음
워밍업
extends / implements 사용하지 않기
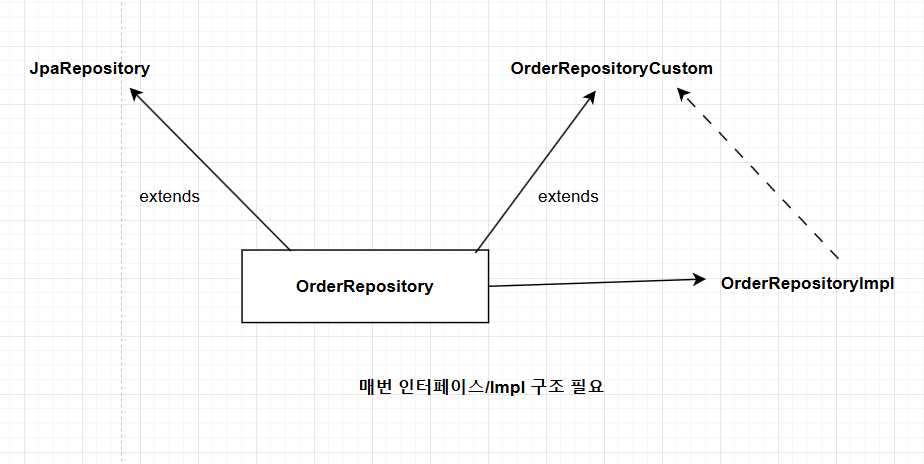
- JPA Repository 상속을 받되, Custom이라 하는 별도의 Interface를 추가적으로 상속 & 구현체 필요
- 매번 이러는 것이 과하다 생각하면? QuerydslRepositoySupport 상속 가능
- 이것 역시 Super 생성자에 Entity를 등록해야 함
@Repository
public class BookRepositorySupport extends QuerydslRepositorySupport {
private final JPAQueryFactory queryFactory;
public BookRepositorySupport(JPAQueryFactory queryFactory) {
super(Book.class);
this.queryFactory = queryFactory;
}
}- 꼭 무언가를 상속, 구현 받지 않다라도 & 꼭 특정 Entity를 지정하지 않더라도 Querydsl을 사용할 수 있는 방법에 대한 고민에 빠지게 된다.
- JPAQueryFactory만 있다면 Querydsl은 사용할 수 있다.
@RequiredArgsConstructor @Repository public class AcademyQueryRepository { private final JPAQueryFactory queryFactory; public List<Academy> findByName(String name) { return queryFactory.selectFrom(academy) .where(academy.name.eq(name)) .fetch(); } }
동적 쿼리
@Override
public List<Academy> findDynamicQuery(String name, String address, String phoneNumber) {
BooleanBuilder builder = new BooleanBuilder();
if(!StringUtils.isEmpty(name)) {
builder.and(academy.name.eq(name));
}
if(!StringUtils.isEmpty(address)) {
builder.and(academy.address.eq(address));
}
if(!StringUtils.isEmpty(phoneNumber)) {
builder.and(academy.phoneNumber.eq(phoneNumber));
}
return queryFactory
.selectFrom(academy)
.where(builder)
.fetch();
}- 동적 쿼리 부분에서 일반적으로 어떤 쿼리인지 예상하기 어렵다
- 사용할 컬럼이 5~7개라면? 예상하기 넘나 어려울듯
- 동적 쿼리를 BooleanExpression으로 사용
- null 반환시 자동으로 조건절에서 제거 된다.
- null을 반환함으로써 조건에서 제외된다는 것을 명시적으로 알 수 있음
- 모든 조건이 null이 발생하는 경우는 대장애 발생하니 주의!
- 모든 조건이 삭제되어 모든 데이터 조회처리 됨
@Override
public List<Academy> findDynamicQuery(String name, String address, String phoneNumber) {
return queryFactory
.selectFrom(academy)
.where(eqName(name),
eqAddress(address),
eqPhoneNumber(phoneNumber))
.fetch();
}
private BooleanExpression eqName(String name) {
if(StringUtils.isEmpty(name)) {
return null;
}
return academy.name.eq(name);
}
private BooleanExpression eqAddress(String address) {
if(StringUtils.isEmpty(address)) {
return null;
}
return academy.address.eq(address);
}성능개선 - Select
Querydsl의 exist 금지(2500만건 기준)
- exist의 경우 첫번째 값이 발견되는 즉시 쿼리 종료
- count는 끝까지 모든 조건 체크
- 스캔 대상이 앞에 있을 수록 더 심한 성능차이 발생
// SQL.exist - 2s 57ms,
select exists(
select 1
from ad_item_sum
where created_date > '2020-01-01')
// SQL.count(1) > 0 - 5s 208 ms
select count(1)
from ad_item_sum
where created_date > '2020-01-01'Querydsl의 실제로 exists는 count() > 0 으로 실행된다.
- 영상 발표에서 다룬 2.6.0 버전은 아래와 같이 비효율적으로 동작
@Override
public boolean exists(Predicate predicate) {
return createQuery(predicate).fetchCount() > 0;
}- 직접 만들자
- JPQL은 from 없이는 쿼리를 생성할 수 없는 문제
return queryFactory.select(queryFactory
.selectOne()
.from(book)
.where(book.id.eq(bookId))
.fetchAll(.exists())
.fetchOne();-
exists가 빠른 이유는 조건에 해당하는 row 1개만 찾으면 바로 쿼리를 종료하기 때문
- 이를 직접 구현하자
-
가장 쉬운 방법
- limit 1로 조회 제한
- 조회 결과가 없으면 null 이라서 체크
- 조회 결과가 없으면 0이 아닌 null 반환됨
- 실제 쿼리 날려봐도 SQL exist와 거의 동일
@Transactional(readOnly = true)
public Boolean exist(Long bookId) {
Integer fetchOne = queryFactory
.selectOne()
.from(book)
.where(book.id.eq(bookId))
// limit(1).fetchOne()과 동일
.fetchFirst();
return fetchOne != null;
}참고) 최신 버전에서 exist 메서드 개선
- 첫번째 값만 보고 null이냐 아니냐로 개선됨

Cross Join 회피
묵시적 Join으로 Cross Join 발생
- JPA에도 동일하게 발생
- Hibernate 이슈
public List<Cutomer> crossJoin() {
return queryFactory
.selectFrom(customer)
.where(customer.customerNo.gt(customer.shop.shopNo))
.fetch();
}- 명시적 Join으로 Inner Join 발생
public List<Cutomer> crossJoin() {
return queryFactory
.selectFrom(customer)
.innerJoin(customer.shop, shop)
.where(customer.customerNo.gt(customer.shop.shopNo))
.fetch();
}참고) 버전업 되면서 join과 innerJoin이 동일하게 바뀜
연관관계 맺어있다면 default로 innerJoin, join으로 동작
- category : Product = 1 : N 관계
- 묵시적 Join이 innerJoin
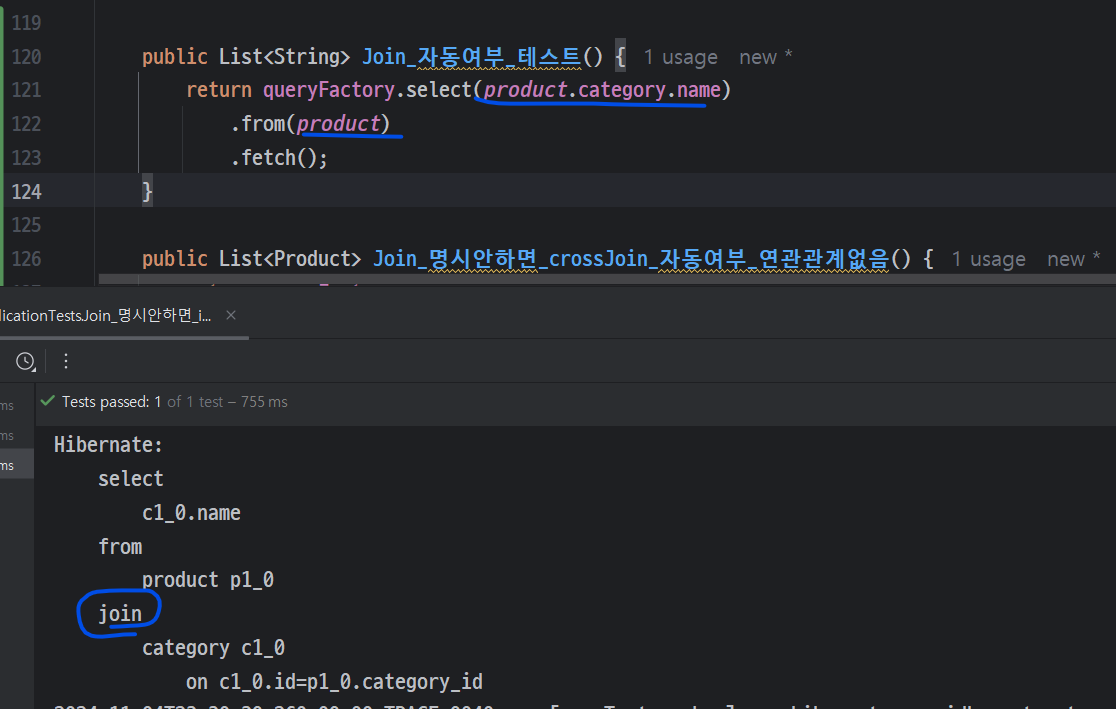
- 묵시적 Join이 innerJoin
연관관계가 없이 crossJoin이면 Join이 미표기됨
- crossJoin 명시적 발생 시키더라도 cross Join이라 미표기됨
- CustomUser와 Product 연관 없을때
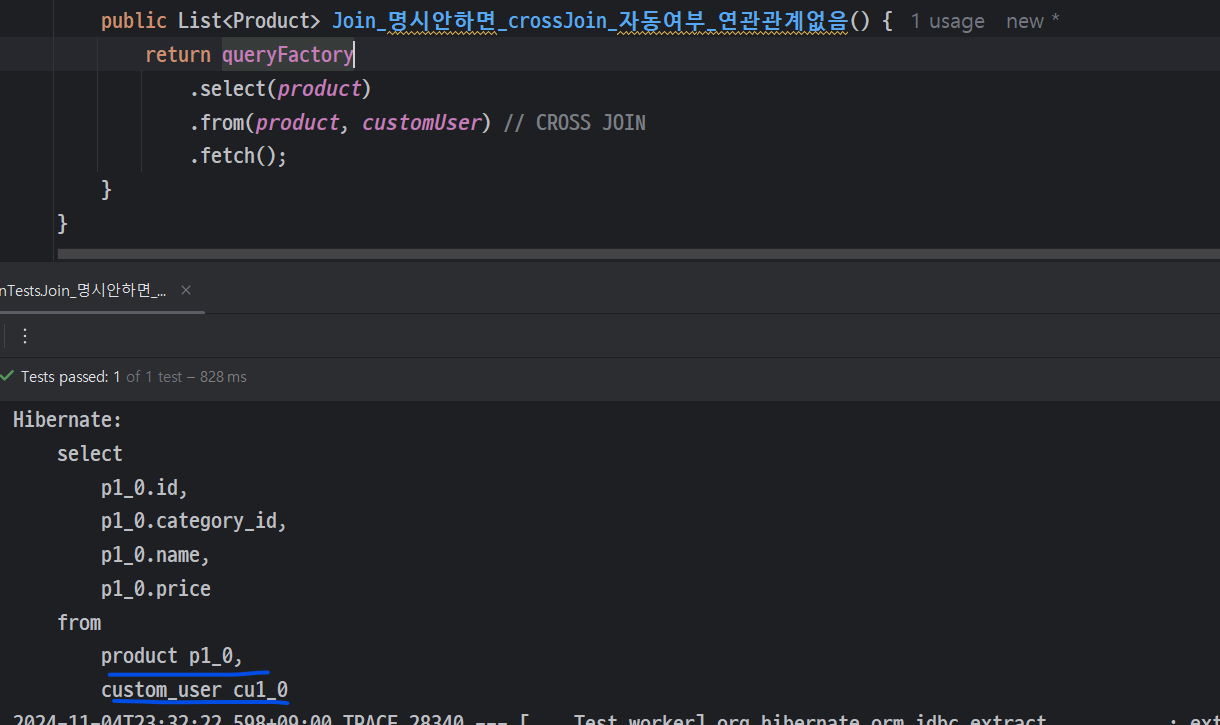
- CustomUser와 Product 연관 없을때
join으로 적더라도 innerJoin으로 동작하도록 변경됨
-
일부 블로그들.. 해당 영상 예전 블로그 포스팅 참조해서 꼭 명시적으로 InnerJoin() 메서드를 써야한다고 하는데.. 아닙니다...
- 물론 쓰면 가독성엔 좋겠지만 안쓴다고 꼭 크로스 조인이 아닙니다.... 버전 업됐어요..!
- 아 포스팅 하신분들이 모두 영상 처럼 Querydsl 4.x 버전이라면.. 맞을듯요
-
Querydsl crossJoin() 메서드 없음
- 버전 업 되면서 제외가 된 것 같습니다. 자동완성에 안떠요
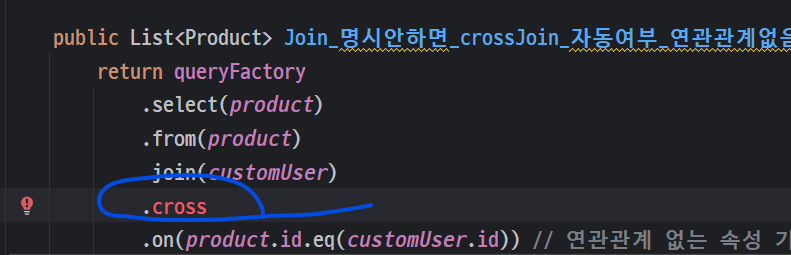
- 버전 업 되면서 제외가 된 것 같습니다. 자동완성에 안떠요
-
join 메서드가 innerJoin으로 동작
- 연관관계 없더라도 innerJoin으로 자동 동작
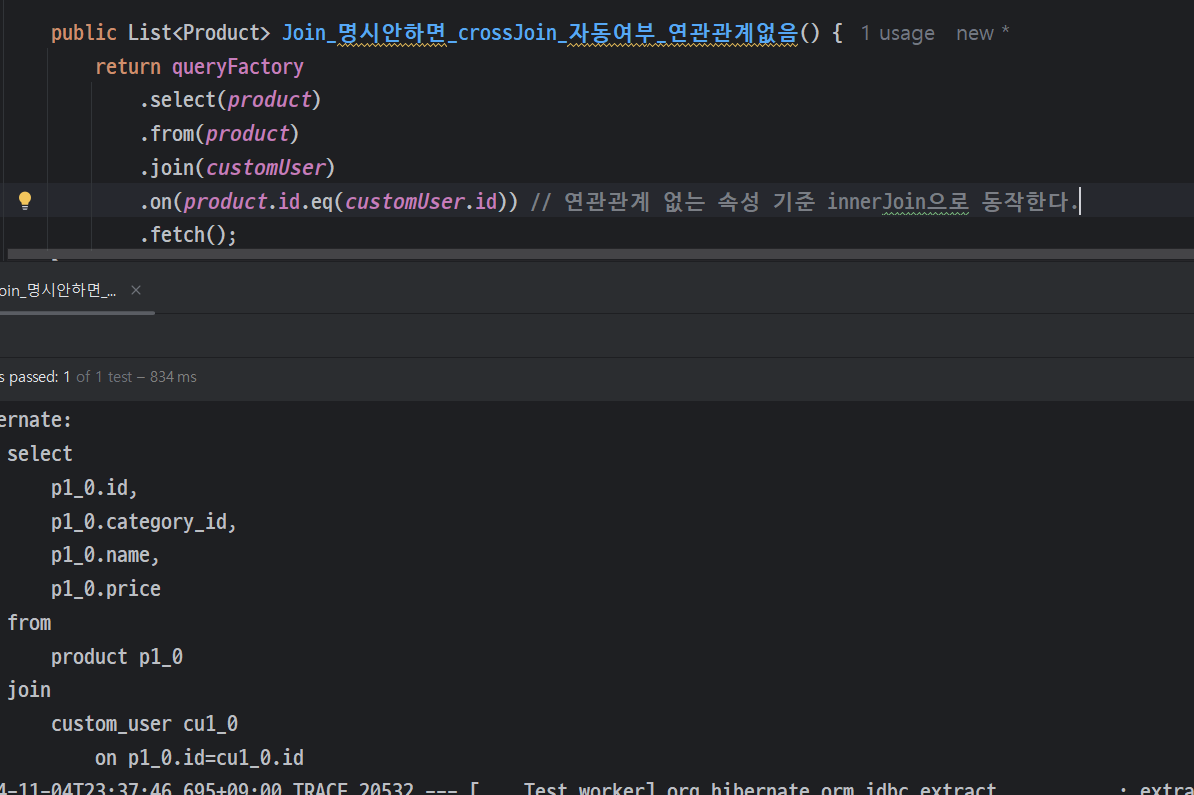
- Product => id 0 ~ 29 (테스트 상품명 0~29)
- User => id 0 ~ 1
- id가 0, 1인 Product 조회 확인
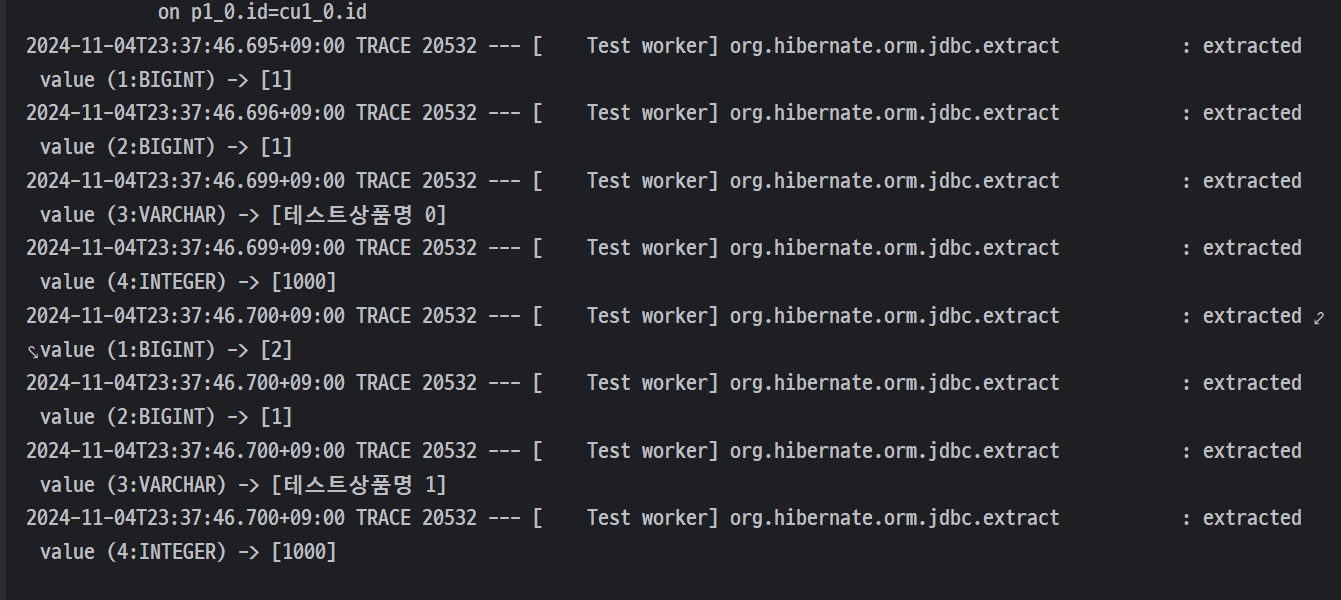
- 연관관계 없더라도 innerJoin으로 자동 동작
Entity 보다는 Dto를 우선
- Entity를 무조건 사용하는 것이 아닌 Dto를 사용하면 얻는 장점에 대해 설명
- Entity 조회 시
- Hibernate 캐시
- 캐시 문제가 무엇일까? 고민
- JPQL 쿼리는 flush하여 데이터를 가져오는데, 엔티티를 가져올 경우 1차 캐시에 저장한다.
- 하지만 이 전체 데이터를 추후에 사용하지도 않는데 메모리를 차지하는 문제가 발생한다.
- 불필요한 컬럼 조회
- OneToOne N+1 쿼리 등
- 단순 조회 기능에서는 성능 이슈 요소가 많다.
- Hibernate 캐시
queryFactory
.selectFrom(book)
.where(book.bookNo.eq(bookNo))
.offset(pageNo)
.limit(10)
.fetch();
queryFactory
.selectFrom(Projections.fields(BookPageDto.class,
book.name,
book.bookNo,
book.id))
.from(book)
.where(book.bookNo.eq(bookNo))
.offset(pageNo)
.limit(10)
.fetch();Entity 조회
- 실시간으로 Entity 변경이 필요한 경우
Dto 조회
- 고강도 성능 개선 or 대량의 데이터 조회가 필요한 경우
어떻게 하면 Entity보다 Dto를 사용하는데 좀 더 개선된 방법이 없을까?
조회 컬럼 최소화 하기
- 이미 bookNo라는 값을 알고 있기 때문에 조회할 필요가 없음
public List<BookPageDto> getBooks (int bookNo, int pageNo) {
return queryFactory
.select(Projections.fields(BookPageDto.class,
book.name,
book.bookNo,
book.id
))
.from(book)
.where(book.bookNo.eq(bookNo))
.offset(pageNo)
.limit(10)
.fetch();- as 표현식으로 대체할 수 있음
- as 컬럼은 select에서 제외된다.
public List<BookPageDto> getBooks (int bookNo, int pageNo) { return queryFactory .select(Projections.fields(BookPageDto.class, book.name, // as 표현식으로 대체할 수 있음 // as 컬럼은 select에서 제외된다. Expressions.asNumber(bookNo).as("bookNo"), book.id )) .from(book) .where(book.bookNo.eq(bookNo)) .offset(pageNo) .limit(10) .fetch();
select 컬럼에 Entity 자제
return queryFactory
.select(Projections.fields(AdBond.class,
adItem.amount.sum().as("amount"),
adItem.txDate,
adItem.orderType,
// adItem과 연결된 Customer 조회
// Customer의 모든 컬럼 조회(사용하지 않는 컬럼임에도..)
adItem.customer)
)
....Select 컬럼에 Entity 자제 - N+1
-
Customer와 @OneToOne 관계인 Shop이 매 건마다 조회한다.
- @OneToOne은 Lazy Loading이 안된다.
- N+1 무조건 발생
-
Shop에도 @OneToOne인 컬럼이 있다면??!
- 100배, 1000배의 쿼리가 수행된다!!
- 100배, 1000배의 쿼리가 수행된다!!
-
Entity간 연관관계를 맺으려면 반대 Entity가 있어야하지 않나요?
- 연관된 Entity의 save를 위해서는 반대편 Entity의 Id만 있으면 된다.
- Join Column에 들어갈 Id만 필요
- 연관된 Entity의 save를 위해서는 반대편 Entity의 Id만 있으면 된다.
return queryFactory
.select(Projections.fields(AdBond.class,
adItem.amount.sum().as("amount"),
adItem.txDate,
adItem.orderType,
// customerId만 조회
adItem.customer.id.as("customerId")
)
....- 개선 : AdBond가 저장되는 시점에는 Customer의 Id외에는 필요없다
public AdBond toEntity() {
return AdBond.Builder()
.amount(amount)
.txDate(txDate)
.orderType(orderType)
.customer(new Customer(customerId))
.build();
}-
성능 비교 : 2500만건 기준
- Entity 조회 : 13.923 초
- id 컬럼 조회 : 2.526 초
-
엔티티 조회는 실제 필요한지를 고려하여 사용하길 추천
Select 컬럼에 Entity 자제 - distinct 문제
- Select에 선언된 Entity 컬럼 전체가 distinct의 대상이 된다.
- distinct 위한 임시 테이블을 만드는데 공간, 시간이 필요하여 기존 대비 성능 떨어짐
Group By 최적화
- MySQL Group By 실행하면 Filesort가 필수로 발생
- 해당 쿼리가 index를 타지 않았을 경우
- MySQL에서 order by null을 사용하면 Filesort가 제거된다.
- Querydsl에서는 order by null 문법을 지원하지 않는다.
public class OrderByNull extends OrderSpecifier {
public static final OrderByNull DEFAULT = new OrderByNull();
private OrderByNull() {
super(Order.ASC, NullExpression.DEFAULT, Default);
}
}
.groupBy(txAddition.type, txAddition.code)
.orderBy(OrderByNull.DEFAULT)
.fetch();- 성능 : 2500만건 기준
- Group By : 47.945초
- Order By null : 8.465초
정렬이 필요하더라도, 조회 결과가 100건 이하라면 애플리케이션에서 정렬한다.
- DB 보다는 WAS의 자원이 저렴하기 때문
result.sort(comparingLong(PointCalculateAmount::getPointAmount));
- 단 페이징일 경우 order by null을 사용하지 못한다.
커버링 인덱스
- 쿼리를 충족시키는데 필요한 모든 컬럼을 갖고 있는 인덱스
- select / where / order by / group by 등에서 사용되는 모든 컬럼이 인덱스에 포함된 상태
- NoOffset 방식과 더불어 페이징 조회 성능을 향상시키는 가장 보편적인 방법
- Join절 안에 있는 쿼리가 커버링 인덱스를 사용한 것
// 1. 속성들을 가져올 때
select *
from academy a
// 2. 커버링 인덱스를 사용함
// -> JPQL에서 안되니까 PK를 커버링 인덱스로 먼저 가져오고 속성들 가져오는 방식으로 우화
join (select id
from academy
order by id
limit 10000, 10) as temp
on temp.id = a.id;- JPQL은 from절의 서브쿼리를 지원하지 않는다.
커버링 인덱스 조회는 나눠서 진행
- Cluster Key (PK)를 커버링 인덱스로 빠르게 조회하고
- 조회된 Key로 Select 컬럼들을 후속 조회하는 방식으로 나눠 진행
// 1. PK 먼저 가져오고
List<Long> ids = queryFactory
.select(book.id)
.from(book)
.where(book.name.like(name + "%"))
.orderBy(boo.id.desc())
.limit(pageSize)
.offset(pageNo * pageSize)
.fetch();
if (CollectionUtils.isEmpty(ids)) {
return new ArrayList<>();
}
// 2. 나머지 속성들 가져오기
return queryFactory
.select(Projections.fields(BookPaginationDto.class,
book.id.as("bookId"),
book.name,
book.bookNo,
book.bookType))
.from(book)
.where(book.id.in(ids))
.orderBy(book.id.desc())
.fetch(); - 성능 : 1억건 기준
- 기존 : 26s
- jdbc 커버링 : 27s
- querydsl 커버링 : 0.58s
- 기존 커버링 인덱스와 거의 비슷한 성능을 보여줌
Update/Insert 성능 개선
일괄 Update 최적화
객체지향 핑계로 성능을 버리진 않는지 무분별한 DirtyChecking을 확인해야 한다.
DirtyChecking
List<Student> students = queryFactory
.selectFrom(student)
.where(student.id.loe(studentId))
.fetch();
for (Student student : students) {
student.updateName(name);
}Querydsl.update
queryFactory.update(student)
.where(student.id.loe(studentId))
.set(student.name, name)
.execute();-
DirtyChecking이란?
- 트랜잭션 내부에 엔티티의 값을 조회해서 값을 바꾸면 자동으로 DB에 반영해주는 방식
- 1000건, 10_000건의 엔티티 변경이 필요하다 하더라도 해당 엔티티 값을 조회해서 직접적으로 값을 변경하는 방식을 사용
- 위에 Querydsl update 한방 쿼리로 해결되는 것에 비해 성능상 많이 떨어짐
-
성능 : 1만건 기준 (약 2,000배 차이)
- DirtyChecking : 9.1s
- Querydsl.update : 0.272ms
하이버네이트 캐시는 일괄 업데이트 시 캐시 갱신이 안된다.
- 일괄 업데이트가 그러면 무조건 좋나? 하는 생각이 들 수 있다.
- 하지만 하이버네이트 캐시는 일괄 업데이트 시 캐시 갱신이 안된다.
- 이럴 경우 업데이트 대상들에 대한 Cache Eviction이 필요하다
DirtyChecking
- 실시간 비즈니스 처리, 실시간 단건 처리시
Querydsl.update
- 대량의 데이터를 일괄로 Update 처리시
- 하이버네이트 캐시 갱신이 필요 없는 서비스에 고려하면 좋음
공통 내용 : 진짜 Entity가 필요한게 아니라면 Querydsl과 Dto를 통해 딱 필요한 항목들만 조회하고 업데이트한다.
Bulk Insert
JPA로 Bulk Insert는 자제한다.
-
성능 : 단일 Entity 1만건 save 기준
- JPA.merge : 62s
- JPA.persist : 62s
- Jdbc.Batch : 0.58s
-
rewriteBatchedStatements로 Insert 합치기 옵션을 넣어도 JPA는 auto_increment일때 insert 합치기가 적용되지 않는다.
-
JdbcTemplate으로 Bulk Insert는 처리되나 컴파일 체크, 코드-테이블간 불일치 체크 등 Type Safe 개발이 어려움
- 문자열로 쿼리를 작성해야 함
-
일부만 적용하고 있으니 걸러서 듣기..!
TypeSafe한 방식으로 Bulk Insert를 처리할 순 없을까?
- Querydsl은 추상회된 상위의 개념, 하위에는 아래 개념들이 있다.
- Querydsl-JPA -> JPQL
- Querydsl-SQL -> Native SQL
- Querydsl-MongoDB -> Mongo Query
- Querydsl-ElasticSearch -> ES Query
QClass 기반으로 Native SQL을 사용할 수 있는 Querydsl-SQL ???
- 여태 왜 안썼나요?
- 테이블을 Scan 해서 QClass를 만드는 방식 번거로움
- 로컬 PC에 DB 설치 및 실행
- Gradle/Maven에 로컬 DB 정보를 등록
- flyway로 테이블 생성
- Querydsl-SQL 플러그인으로 테이블 Scan 하여 QClass 생성
- 테이블을 Scan 해서 QClass를 만드는 방식 번거로움
- 로컬 DB로 하려니 너무 귀찮다! 이미 만들어진 베타 DB를 이용한다면!?
- 베타 DB를 QA하고 있는 중에 신규 컬럼이 추가된다고 하면 반영할 수가 없음
JPA 어노테이션으로 Querydsl-SQL QClass를 생성할 순 없을까?
- EntityQL 프로젝트 존재 확인
- JPA Entity를 기반으로 Querydsl-SQL QClass를 생성해준다.
- 테이블 스캔하는 Querydsl-SQL을 생성하는 방식은 작업이 너무 번거롭고, 어노테이션으로 만드는 Querydsl-JPA는 작업은 간단하지만 bulk Insert가 안되는 성능상 이슈 발생하는 Insert 합치기를 지원하지 않는 문제를 동시에 해결할 수 있는 방법
EntityQL - Bulk Insert
-
EntityQL로 만들어진 Querydsl-SQL의 QClass를 이용하면 BulkInsert 가능!
-
단일 Entity
SQLInsertClause insert = sqlQueryFactory.insert(qAcademy);
for (int j = 1; j <= 1_000; j++) {
insert.populate(new Academy("address", "name"), EntityMapper.DEFAULT)
.addBatch();
}
insert.execute();- OneToMany
SQLInsertCluase insert = sqlQueryFactory.insert(qStudent);
for (int j = 1; j <= 1_000; j++) {
Academy = academy = academyRepository.save(new Academy("address", "name"));
insert.populate(new Student("student", 1, academy), EntityMapper.DEFAULT).addBatch();
insert.populate(new Student("student", 2, academy), EntityMapper.DEFAULT).addBatch();
}
insert.execute();- 성능 비교 : 단일 Entity 1만건, 약 135배
- JPA : 1m 7s
- Querydsl-SQL : 0.56ms
- 성능 비교 : OntToMany, 약 6배
- JPA : 12 m 6s
- Querydsl-SQL : 2m 49s
- 추가적 작업이 필요한데 이정도(매핑 등)
EntityQL - 단점
-
Gradle 5이상 필요
-
어노테이션에 (name = "") 필수
- @Column의 name 값으로 QClass 필드가 선언된다.
- @Table의 name 값으로 테이블을 찾을 수 있다.
-
primitive type 사용 X
- int, double, boolean 등 사용할 수 없다.
- 모든 컬럼은 Wrapper Class로 선언해야 한다.
-
복잡한 설정
- querydsl-sql이 개선되지 못해 불편한 설정이 많음
-
@Embedded 미지원
- @Embedded 어노테이션을 통한 컬럼 인식 못함
- @JoinColumn은 지원
-
Querydsl-SQL의 미지원으로 insert 쿼리를 @Column의 name으로 만들 수가 없음
- 컬럼명과 필드명이 일치해야하는 BeanMapper만 지원
- 카멜케이스, 언더스코어 문법상 차이가 있으면 인식하지 못함
- 문법 차이를 인식해줄 수 있는 @Column용 Mapper가 별도로 필요
- 컬럼명과 필드명이 일치해야하는 BeanMapper만 지원
EntityQL을 어떤식으로 사용하나?
- 최선이 아닌 차악을 고른다는 마음으로 사용
- JdbcTemplate과 EntityQL 단점 명확
- TypeSafe 보장 x vs 여러 제약사항, 설정의 불편함
- 어느 것이 덜 싫은 쪽으로 선택
마무리
- 상황에 따라 ORM / 전통적 Query 방식을 골라 사용할 것
- JPA / Querydsl로 발생하는 쿼리 한번 더 확인하기
- 신입이 오면 2가지 책 추천
- JPA
- Real My SQL
- JPA 특성과 DB의 양쪽의 특성을 이해해야 함
