Fast-Whisper 소개
Fast-Whisper는 OpenAI의 Whisper 모델을 CTranslate2를 이용하여 재구현한 버전입니다. CTranslate2는 Transformer 모델을 위한 고속 추론 엔진으로, 이를 통해 기존 Whisper 모델보다 최대 4배 빠른 성능을 자랑하며 메모리 사용량도 적습니다. 특히, CPU와 GPU에서 8비트 양자화를 적용함으로써 성능 효율을 더욱 끌어올릴 수 있습니다.
프로그램은 사용자의 컴퓨터 성능을 활용하여 작동하므로, 사양이 낮은 경우 Whisper-WebUI를 이용하거나 다른 번역 프로그램을 고려하는 것이 좋습니다.
설치 필요 사항
파이썬 설치
Fast-Whisper 사용을 위해서는 Python 3.8 이상이 필요합니다. 파이썬 버전을 확인하려면 터미널에서 python --version 또는 python3 --version을 실행하세요. 파이썬 3.10 이상 버전 사용을 권장하며, 현재 저는 Python 3.10.11을 사용 중입니다.
NVIDIA 라이브러리 설치
GPU를 사용하여 음성 인식 처리 속도를 향상시키기 위해서는 NVIDIA의 cuBLAS와 cuDNN 라이브러리 설치가 필요합니다. GPU가 없거나 해당 라이브러리 설치가 어려운 경우, CPU만을 사용하는 방식으로도 작동하지만, 속도 면에서 제한이 있을 수 있습니다.
cuBLAS 설치 방법
-
cuBLAS for CUDA 11에 접속해 '다운로드'를 클릭합니다.
-
'Download Now'를 선택하여 계속 진행합니다.

-
사용 중인 운영체제에 맞는 버전을 선택하여 설치합니다.
- 현재 Windows에서는 프로그램이 지원되지 않습니다.
- 현재 Windows에서는 프로그램이 지원되지 않습니다.
cuDNN 설치 방법
-
cuDNN 8 for CUDA 11 페이지에서 'Download Library' 목록으로 이동합니다.

-
사용 중인 운영체제에 맞는 라이브러리를 선택하여 설치합니다.
Fast-Whisper 설치방법
파이썬이 설치완료했다면
파이썬 설치가 완료되었다면, 다음 단계를 따라 Fast-Whisper를 설치할 수 있습니다.
1. 라이브러리 설치
터미널을 열고 다음 명령어를 실행하여 faster-whisper 라이브러리를 설치합니다.
pip install faster-whisper2. 사용할 디렉토리 위치 설정
자신이 작업하고 싶은 디렉토리로 이동하여 transcribe_audio.py 파일을 위치시키고, 자막이 생성되어 저장될 폴더를 생성합니다.
3. transcribe_audio.py 파일을 생성합니다.
from faster_whisper import WhisperModel
import sys
import os
def seconds_to_srt_time(seconds):
"""초 단위 시간을 SRT 파일 형식의 시간 문자열로 변환합니다."""
hours = int(seconds // 3600)
minutes = int((seconds % 3600) // 60)
seconds = seconds % 60
milliseconds = int((seconds - int(seconds)) * 1000)
return f"{hours:02}:{minutes:02}:{int(seconds):02},{milliseconds:03}"
def process_audio_to_srt(audio_file, model, srt_folder):
"""오디오 파일을 처리하여 SRT 파일로 변환합니다."""
base_name = os.path.splitext(os.path.basename(audio_file))[0] # 파일 이름에서 확장자를 제거합니다.
srt_file_name = f"{srt_folder}/{base_name}.srt"
# 오디오 파일 변환
segments, info = model.transcribe(audio_file, beam_size=5,language="en")
with open(srt_file_name, "w", encoding="utf-8") as file:
i = 0 # 세그먼트 번호를 추적하기 위한 변수
for segment in segments:
start_time = seconds_to_srt_time(segment.start)
end_time = seconds_to_srt_time(segment.end)
i += 1 # 세그먼트 번호를 증가시킵니다.
file.write(f"{i}\n")
file.write(f"{start_time} --> {end_time}\n")
file.write(f"{segment.text}\n\n")
sys.stdout.write(f"\r세그먼트 {i} 처리 중...")
sys.stdout.flush()
print(f"\n'{audio_file}' 변환 완료! 결과는 '{srt_file_name}' 파일에 저장되었습니다.")
model_size = "large-v3"
# GPU에서 FP16으로 실행
model = WhisperModel(model_size, device="cuda", compute_type="float16")
audio_folder = "." # 현재 폴더 내의 오디오 파일들을 처리합니다.
srt_folder = "SRT" # SRT 파일을 저장할 폴더
# SRT 폴더가 없으면 생성
if not os.path.exists(srt_folder):
os.makedirs(srt_folder)
# 현재 폴더 내의 모든 MP3 파일을 찾아서 처리
for file in os.listdir(audio_folder):
if file.endswith(".mp3"):
audio_file = os.path.join(audio_folder, file)
process_audio_to_srt(audio_file, model, srt_folder)
# python transcribe_audio.py 실행 명령어코드를 복사 하여 파일을 생성합니다.
언어설정
현재 음성인식 파일을 기본 영어로 설정되어있는 상태입니다.
segments, info = model.transcribe(audio_file, beam_size=5,language="en")
자신이 원하는 국가코드를 입력해줘서 필요한 언어에 맟춰 작성해줍니다.
en: 영어
ja: 일본어
ko: 한국어
...
그외 언어 및 다양한 커스텀
다양한 커스텀이 가능하며 본인이 필요한 기능과 지원 되는지 여부는
공식 깃허브 페이지에서 확인 후 필요에 따라 수정해서 사용 하면 될꺼 같습니다.
Fast-Whisper 사용 방법
자막을 생성할 오디오 파일들을 transcribe_audio.py 파일이 있는 디렉토리에 위치시킨 후, 다음 단계를 따릅니다.
터미널에서 다음 명령어를 입력합니다.
python transcribe_audio.py이 명령어를 실행하면 지정한 디렉토리에 위치한 오디오 파일들의 자막이 생성되어 설정한 폴더에 저장됩니다.
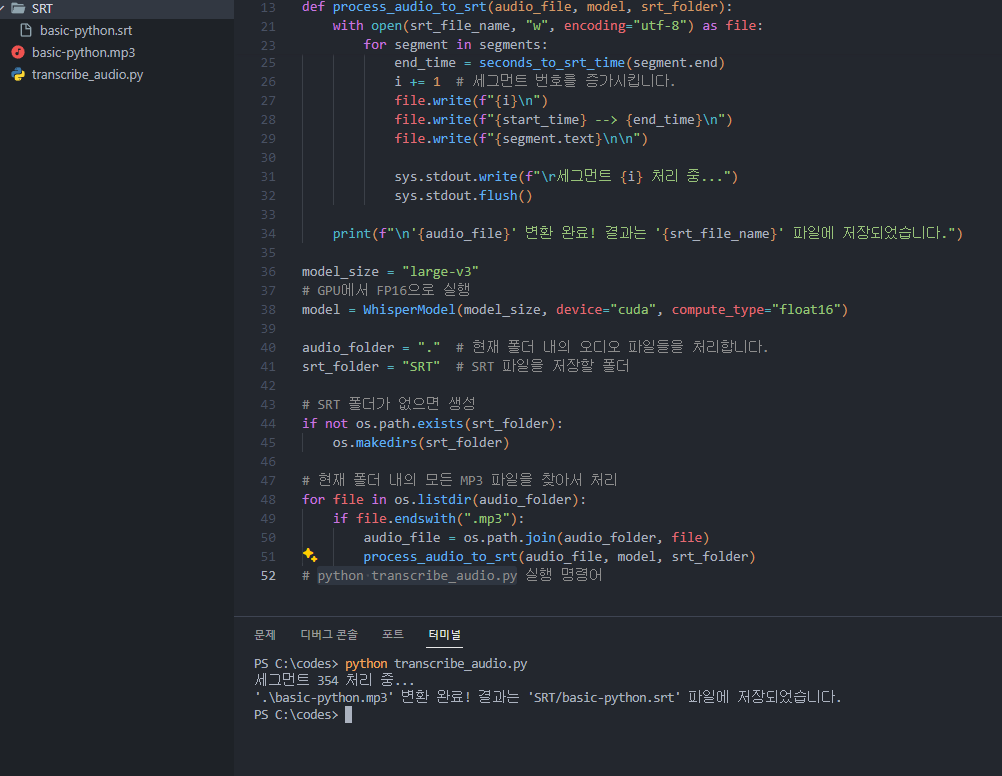
이런식으로 현재 진행중인 라인이 나오며 완료시
SRT 폴더내 .srt 형태로 저장이 완료되었습니다.

안녕하세요. Faster-Whisper 설치 및 사용방법에 대해 친절하게 설명해 주셔서 감사합니다. 하지만, IT 지식이 부족한 사람들에게 Whisper 설치는 여전히 어려운 일이라고 생각합니다. github 의 https://github.com/abus-aikorea/voice-pro 프로젝트에 대해서도 다루어 줄 수 있나요? Voice-Pro는 원클릭으로 Whisper 를 설치할 수 있고, Whisper 뿐만아니라 Faster-Whisper 와 Whisper-Timestamped 를 지원합니다.