Generative Adversarial Networks(GAN)
: 생성기(generator)와 판별기(discriminator) 두 개의 네트워크를 활용한 생성 모델로, 생성기와 판별기를 경쟁적으로 대립시켜 학습을 시키는 신경망을 말한다.
GAN의 구조와 원리
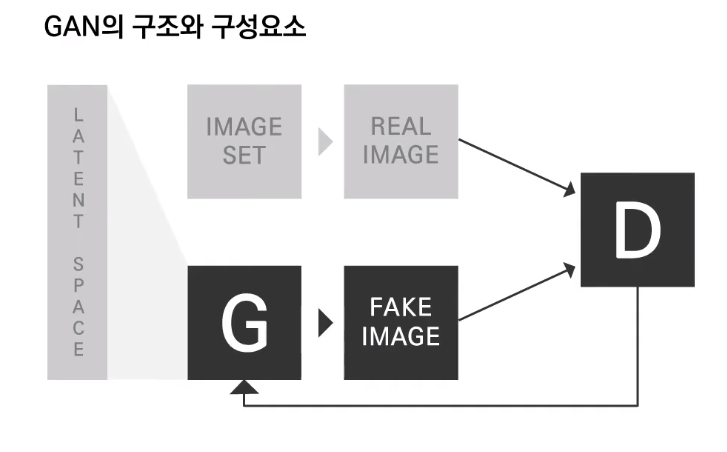
여기서의
G는 Generator, 즉 생성기로 임의의 설정된 정보(latent space)를 바탕으로 가상의 이미지를 만들어 내는 신경망 구조의 생성 시스템 이다.
D는 Discriminator, 판별기로 실제 데이터와 생성기가 생성한 가짜 데이터를 입력받아 해당 이미지가 진짜 이미지일 확률(0과 1 사이의 값)을 출력 값으로 하여 일치의 정도를 출력하는 시스템이다.
이는 다음의 목적 함수(objective function)을 통해 학습할 수 있다.
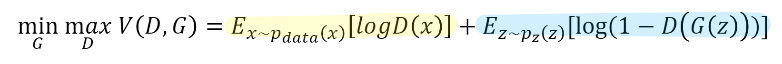
여기서의 V(D,G)라는 함수 값을 G는 낮추고자 노력하고, D는 높이고자 노력한다.
먼저 D가 목적을 이루기 위해서는, 노란색으로 표시한 진짜 데이터를 판별하는 수식에 대해서는 1을 출력하여야 하고 파란색으로 표시한 가짜 데이터를 판별하는 수식에 대해서는 0을 출력하여야 한다. 즉, D(x) = 1, D(G(z)) = 0이 되어 함수 값이 0이 되면 최대 목적을 이루게 되는 것이다.
반면, G는 자신이 생성한 가짜 데이터가 D에게 진짜 데이터로 판별되도록 하는 것이 목적이다. 즉, D(G(z)) = 1이 되어 함수 값을 최소로 만들면 목표에 도달한다.
GAN의 학습
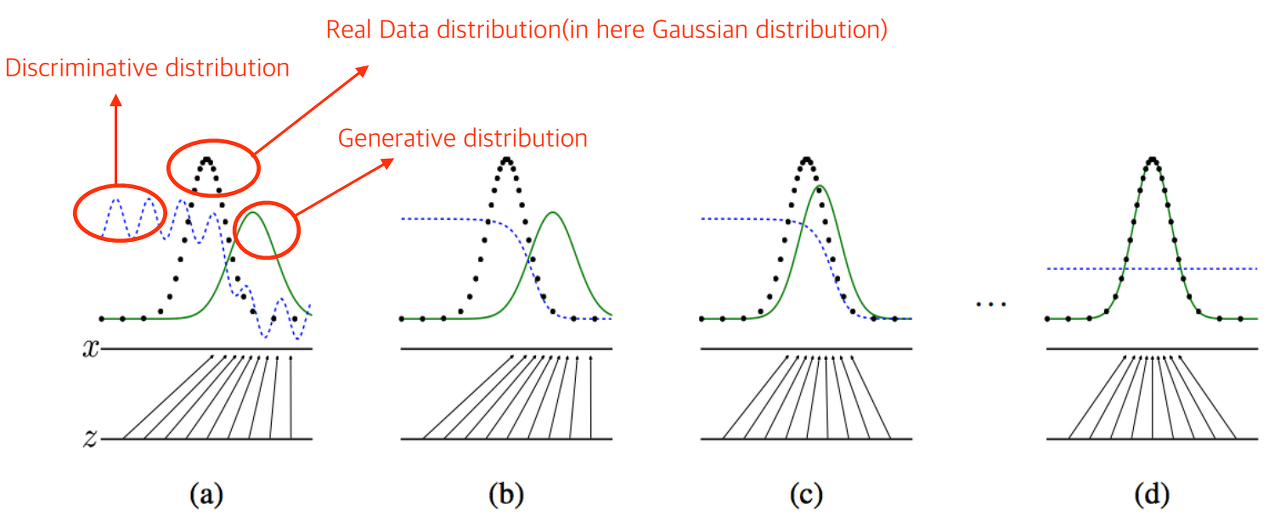
GAN의 구성 요소인 두 모델은
(a) 처럼 학습이 진행되기 전의 진짜 데이터의 확률 분포, 생성기의 확률 분포, 판별기의 확률 분포를 가진 상태에서 판별기는 생성기가 진짜 데이터의 확률 분포와 얼마나 다른지를 판단한다. 이에 따라 생성기는 판별기를 속이기 위해 생성 모델을 진짜 데이터의 확률 분포에 근사하도록 수정해나가고, 궁극적으로 (d)와 같이 생성기의 확률 분포가 진짜 데이터의 확률 분포와 구분이 불가능한 수준이 되도록 하는 과정을 가지게 된다.
결론적으로 둘을 거의 구분할 수 없어져 판별기의 확률 분포(파란색 선)가 0.5로 일정해지면, 50%의 확률로 진짜인지 가짜인지 찍어야하는 순간이 오고 그때 GAN은 학습을 종료하는 것이다.
참고 링크
https://ebbnflow.tistory.com/167
https://www.youtube.com/watch?v=AVvlDmhHgC4
https://www.youtube.com/watch?v=52r9F05wAl4
