넓은 범위의 문자(Wide character)
일반적인 문자(char)보다 더 많은 범위의 문자를 표현하기 위해 더 넓은 메모리 공간을 사용하는 문자 타입입니다. 이를 통해 1Byte로 표현할 수 없는 문자셋을 다룰 수 있습니다. 대표적인 예로는 유니코드(Unicode) 문자가 있습니다.
ASCII(미국 표준 코드)는 1Byte로 문자를 표현하며, 주로 영어와 숫자, 몇몇 특수문자들을 포함합니다. 하지만 전 세계의 여러 언어와 문자들을 표현하기 위해서는 1Byte만으로는 부족합니다.
예를 들어, 한글, 중국어, 일본어 등의 문자들은 1Byte로 표현할 수 없습니다. 이러한 문자를 처리하기 위해서는 2Byte 이상을 사용하는 wide character가 필요합니다.
std::wchar_t : C++에서 wide character를 표현하기 위한 데이터 타입입니다.
std::wchar_t ch = L'한';- L 접두사 : wide character Literal을 나타내는 데 필수적입니다. 이 접두사는 C++에서 문자 리터럴이 wchar_t 타입임을 명확하게 표시합니다. L이 없으면, 해당 문자나 문자열은 char 타입으로 해석되며, 이는 1Byte 문자로 처리됩니다.
std::wstring : C++에서 std::wchar_t 타입을 사용하는 문자열을 의미합니다.
std::wstring wstr = L"안녕하세요.";std::wcout : C++에서 넓은 범위의 문자를 출력하기 위해 사용됩니다.
std::wcout << ch;std::wcin : C++에서 넓은 범위의 문자를 입력받기 위해 사용됩니다.
std::wcin >> wstr;<example>
#include <iostream>
#include <locale>
using namespace std;
int main() {
// 로케일을 "en_US.UTF-8"로 설정 (시스템에 따라 다를 수 있음)
setlocale(LC_ALL, "en_US.UTF-8");
wchar_t wide_char = L'가';
wcout << L"Wide character: " << wide_char << endl;
wstring wide_str = L"안녕하세요, C++!";
wcout << L"Wide string: " << wide_str << endl;
return 0;
}결과값

확장된 개념
인코딩(Encoding)
주로 텍스트 데이터가 컴퓨터 시스템에 어떻게 저장되고 처리되는지를 나타냅니다. 텍스트 인코딩은 텍스트 데이터를 이진 형식으로 변환하는 방법으로, 각 문자가 이진 코드에 매핑되는 방식을 정의합니다.
디코딩(Decoding)
인코딩된 데이터를 원래 형식으로 복원하는 과정입니다. 즉, 컴퓨터 시스템이 처리할 수 있는 형식에서 사람이 이해할 수 있는 형식으로 변환하는 것입니다.
대표적인 문자 인코딩 방식
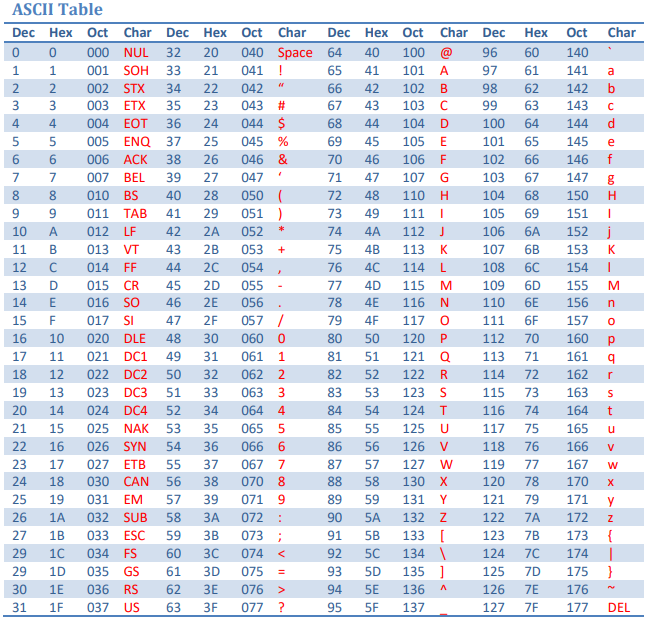
1. ASCII(American Standard Code for Information Interchange)
- 7bit 문자 인코딩 방식으로, 128개의 문자를 표현할 수 있습니다. (0 ~ 127)
- 영어 알파벳(대소문자), 숫자, 구두점, 제어 문자 등을 지원하므로 국제적인 사용에는 제한적입니다.
Unicode
전 세계 모든 문자를 고유한 코드 포인트로 정의하여 컴퓨터 시스템에서 일관되게 처리하고 표현할 수 있도록 만든 글자 인코딩 표준입니다.
2. UTF-8 (Unicode Transformation Format - 8-bit)
- Unicode를 표현하기 위한 가변 길이 인코딩 방식으로, 2,097,152개의 문자를 표현할 수 있습니다.
U+0000 ~ U+10FFFF까지 길이를 조정하여 다양한 문자를 표현합니다. (0 ~ 2,097, 151) - ASCII와 호환되며, 가변 길이로 저장 효율이 높습니다.
- 가장 많이 사용되는 방식이며, 일반적으로 Web에서 널리 사용됩니다.
1Byte : U+0000에서 U+007F (영어 알파벳 및 기본적인 특수문자)
2Byte : U+0080에서 U+07FF (유럽, 아시아 언어의 일부 문자들)
3Byte : U+0800에서 U+FFFF (중국어, 일본어, 한국어 등 다양한 언어의 문자들)
4Byte : U+10000에서 U+10FFFF (희귀 문자, 고대 문자, 이모지 등)
C++의 std::string을 사용하면, 내부적으로 문자 인코딩이 UTF-8로 처리되는 경우가 많습니다.
<example>
#include <iostream> using namespace std; int main() { string str = "한글"; cout << str; return 0; }결과값

3. UTF-16 (Unicode Transformation Format - 16-bit)
- 고정 길이(2Byte) 또는 가변 길이(4Byte)로 문자를 인코딩하는 방식입니다.
- Windows 시스템에서 주로 사용됩니다.
4. UTF-32 (Unicode Transformation Format - 32-bit)
- 고정 길이(4Byte)로 문자를 표현하는 인코딩 방식입니다.
- 이론적으로 4,294,967,296개의 문자를 표현할 수 있습니다.
- 고정 길이 인코딩이므로 각 문자가 항상 4Byte로 표현되어 계산이 간단하지만, 저장 공간이 비효율적일 수 있습니다.
