회귀 모델과 분류 모델을 학습하기 위한 최적화 문제를 정의해보았다. 그렇다면 최적화 문제의 손실 함수는 어떤 기준으로 정의해야 하며 어떤 의미로 해석해야 할까?
신경망 모델이 정확하게 예측하려면 모델은 관측 데이터를 잘 설명하는 함수를 표현해야 한다. 이때 모델이 표현하는 함수의 형태를 결정하는 것이 손실함수이다. 따라서 손실 함수는 모델이 관측 데이터를 잘 표현하도록 정의되어야 한다.
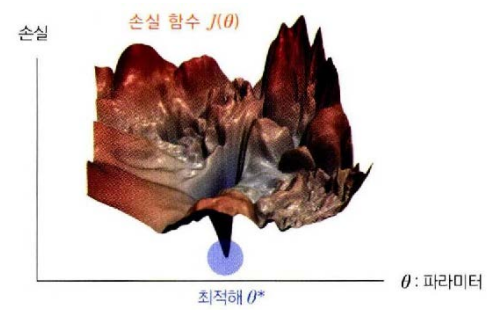
손실함수가 다음과 같은 모양일 때 파란색 동그라미 지점의 파라미터값이 손실 함수의 최적해가 된고 모델은 손실 함수의 최적해로 파라미터화된 함수를 표현한다.
만일 손실 함수가 바뀐다면 모델이 표현하는 함수는 어떻게 될까?
손실 함수의 모양이 달라지면 최적해의 위치가 바뀌므로 모델이 표현하는 함수도 달라진다.
결국 모델이 관측 데이터를 잘 설명하는 함수를 표현하려면 손실함수는 손실함수 최적해가 관측 데이터를 잘 설명할 수 있는 함수의 파라미터값이 되도록 정의되어야 한다.
손실함수가 ’최적해가 관측 데이터를 잘 설명할 수 있는 함수의 파라미터 값이 되도록’ 하려면 어떤 기준으로 정의해야 할까?
모델이 오차 최소화(error minimization)되도록 정의하는 방법
모델이 추정하는 관측데이터의 확률이 최대화되도록 최대우도추정(maximum likelihood estimation)방식으로 정의하는 방법
손실 함수를 정의하는 기준 : 오차 최소화 관점
모델의 오차는 모델의 예측과 관측 데이터의 타깃의 차이를 말한다.
손실 함수의 목표가 모델의 오차를 최소화하는 것이므로 직관적이고 이해하기 쉽다. 따라서 손실함수를 정의할 때 어떤 방식으로 오차의 크기를 측정할지만 정하면 된다.
오차 최소화 관점에서 손실 함수 정의
오차 최소화 관점에서 모델의 예측값과 타깃값의 오차가 최소화되도록 손실 함수를 정의해 보자.
신경망 모델은 파라미터 θ로 이루어져 있고 학습데이터 D=(xi,ti):i=1,…,N 가 있다고 하자 모델의 예측을 y(xi;θ)라고 하고 타깃을 ti라고 하면 오차 ϵi는 다음과 같다.
ϵi=ti−y(xi;θ)
오차 최소화 관점에서 손실 함수 J(θ)는 오차 ϵi의 크기를 나타내는 함수로 정의하면 된다. 여기서 손실 함수 J(f(x;θ),t)는 간단히 J(θ)로 표시했다.
따라서 손실 함수 J(θ)의 성지릉ㄴ 어떤함수로 오차의 크기를 표현하는지에 따라 달라진다. 오차의 크기를 나타내는 대표적인 함수는 벡터의 크기를 나타내는 노름(norm)이며 주로 L2 노름과 L1노름을 사용하며 이때 손실 함수를 평균제곱오차(MSE : meansquared error)와 평균 절대오차(MAE : mean absolute error)라고 부른다.
평균제곱오차 (MSE)
평균 제곱오차는 N개의 데이터에 대해 오차의 L2노름의 제곱의 평균으로 정의되며 l2손실로 표기한다.
J(θ)=N1i=1∑N∣∣ti−y(xi;θ)∣∣22
평균제곱오차는 모델이 타깃 ti의 평균을 예측하도록 만든다. 오차가 커질수로 손실이 제곱승으로 증가하므로 이상치에 민감하게 반응하는 단점이 있다.
평균절대오차 (MAE)
평균절대오차는 N개의 데이터에 대해 오차의 L1노름의 평균으로 저의하며 l1손실로 표기한다.
J(θ)=N1i=1∑N∣∣ti−y(xi;θ)∣∣1
평균절대오차는 모델이 타깃 ti의 중앙값(median)을 예측하도록 만든다. 오차가 커질수록 손실이 선형적으로 증가하므로 이상치에 덜 민감하다. 하지만 미분가능 함수가 아니기 때문에 구간별로 미분을 처리해야하는 단점이 있다.
오차 최소화 관점에서 최적화 문제 정의
오차 최소화 관점에서 신경망 학습을 위한 최적화 문제를 정의해보자.
평균제곱오차를 예로 정의해보면 다음과 같은 최적화 문제로 정의할 수 있다.
손실함수의 목표는 관측 데이터의 확률이 최대화되는 확률분포 함수를 모델이 표현하도록 만드는 것이다.
이 방식은 확률 모델인 경우에만 적용할 수 있으며 최대우도추정 방식이라고 한다. 대부분의 신경망 모델은 확률 모델을 가정하므로 최대우도추정 방식으로 손실 함수를 유도할 수 있다.
최대우도추정 관점에서 손실 함수 정의
신경망 모델은 파라미터 θ로 이뤄진 확률 모델이고 학습 데이터 D=(xi,ti):i=1,…,N의 각 샘플 (xi,ti)는 같은 분포에서 독립적으로 샘플링되어 i.i.d 성질을 만족한다고 하자 이때 신경망 모델로 추정한 관측데이터의 확률이 우도 p(D∣θ)이다. 샘플 (xi,ti)가 서로 독립이므로 관측 데이터의 우도 p(D∣θ)는 N개의 샘플의 우도의 곱으로 표현할 수 있다.
최대우도추정 관점에서 최적화 문제 정의
최대우도추정 관점에서 신경망 학습을 위한 최적화 문제를 정의해보자. 목점함수인 우도 p(D∣θ)를 최대화하는 확률 모델의 파라미터 θ를 찾는 문제로 다음과 같이 정의할 수 있다.
θ∗=θargmaxp(D∣θ)=θargmaxi=1∏Np(ti∣xi;θ)
최대우도추정 관점의 최적화 문제 개선
최대우도추정의 경우 최적화 문제를 개선된 형태로 바꿔야 한다. 앞에서 정의한 최적화 문제를 조금만 변형하면 수치적으로 다루기 쉬워질 뿐만아니라 안정적으로 최적화를 할 수 있기 때문이다. 또한 표준형태의 최소화 문제로 통일할 수도 있다.
목적 함수를 개선된 형태로 만들기 위해 우도 대신 로그 우도(log likelihood)를 사용한다.
최대화 문제를 최소화 문제로 변환하기 위해 목적 함수에 음의 로그 우도(negative log likelihood)를 사용한다.
목적 함수를 로그 우도로 변환
로그 우도는 우도에 로그를 취한 형태를 말한다. 목적 함수에 사용했던 관측 데이터의 우도 대신 로그 우도를 사용하면 다음과 같은 식으로 변환한다.
가우신분포 또는 베르누이 분포와 같은 지수 함수 형태로 표현되는 지수족(exponential family) 확률분포의 경우 로그를 취하면 지수 항이 상쇄되어 다항식으로 변환되기 때문에 함수 형태가 다루기 쉬워진다.
N개의 샘플에 대한 우도의 곱을 로그 우도의 합산으로 바꾸면 언더플로를 방지할 수 있다. 확률은 1보다 작기 때문에 확률을 N번 곱하면 N이 커질수록 언더플로가 쉽게 생긴다. 따라서 우도 대신 로그 우도를 사용하면 곱이 합산 형태로 바뀌므로 언더플로를 방지할 수 있다.
우도 대신 로그 우도를 사용해도 최적해는 달라지지 않는다. 최적화 문제는 목적 함수에 log와 같은 증가 함수를 적용하더라도 동일한 해를 얻을 수 있기 때문이다.
최대화 문제를 최소화 문제로 변환
최대화 문제를 표준 형태의 최소화 문제로 변환해 보자.
이 때는 로그 우도에 음수를 취한 음의 로그 우도, 즉 NLL(negative log likelihood)로 손실 함수가 정의된다.
NLL(θ)=−logp(D∣θ)=−i=1∑Nlogp(ti∣xi;θ)
이제 최대우도추정 문제가 다음과 같은 표준 형태의 최소화 문제로 재정의 되었다.
θ∗=θargmin−i=1∑Nlogp(ti∣xi;θ)
우도와 최대우도추정
우도는 파라미터 θ로 추정된 확률 분포에서 관측데이터 x의 확률을 의미한다.
L(θ∣x)=p(x∣θ)
관측 데이터를 이용해서 확률분포를 추정한다고 가정해 보자.이때 추정된 확률 분포가 관측 데이터를 가장 잘 표현한다고 말할 수 있으려면 관측 데이터의 확률을 최대화해야 한다.
다시말하면 우도 L(θ∣x)를 최대화하도록 확률분포를 추정하는 것이 관측 데이터를 가장 잘 표현하는 확률 분포를 추정하는 것이다.
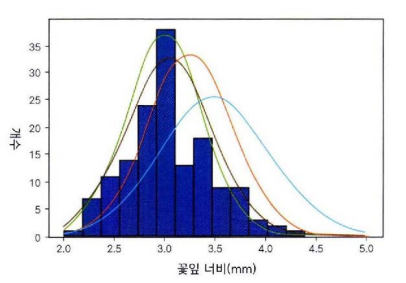
이 관측 데이터의 확률분포를 네개의 가우시안 분포로 추정한다고 하면 어떤 분포가 관측 데이터를 가장 잘 표현한다고 할 수 있을까?
히스토그램의 모양과 비슷한 모양으로 추정된 가우시안 분포가 관측 데이터를 가장 잘 표현한다고 직관적으로 말할 수 있을 것이다.
관측데이터가 많다면 사건이 발생할 확률이 높은 것이므로 해당 부분의 가우시안 분포의 곡선도 높아야 하고 반대로 관측 데이터가 적다면 사건이 발생할 확률이 낮은 것이므로 가우시안 분포의 곡선은 낮아야 한다. 즉 관측 데이터의 히스토그램의 모양을 따르는 가우시안 분포 곡선이 만들어질 때 관측 데이터를 가장 잘 표현한다. 따라서 관측 데이터가 많으면 확률이 높고 관측 데이터가 적으면 확률이 낮게 추정된 확률분포에서 우도는 최대화된다.반대로 관측 데이터가 많은데 확률이 낮게 추정되어 있거나 관측 데이터가 적은데 확률이 높게 추정되어 있으면 관측 데이터의 우도는 작을 수 밖에 없다.
관측 데이터의 우도가 클수록 추정된 확률분포가 관측데이터를 잘 표현하고 있다고 말할 수 있다.
우도는 추정된 분포가 관측 데이터의 분포를 얼마나 잘 나타내는지 또는 일관되는지를 나타내는 측도(measure)이며 우도를 최대화 하는 확률분포를 추정하는 방식을 최대우도추정 방식이라고 한다.
회귀문제에서 최대우도 추정을 위한 함수 정의
회귀 문제에서 최대우도추정을 위한 손실 함수를 정의해 보자.
회귀 모델이 추정하는 가우시안 분포 p(ti∣xi;θ)는 신경망 모델이 출력한 평균 y(xi;θ)와 정밀도의 역수 β−1를 분산으로 하는 분포로 정의된다.
이제 신경망 모델을 통해 추정된 가우시안 분포의 음의 로그우도를 손실 함수로 정의해 보자.
J(θ)=−logi=1∏Np(ti∣xi;θ)
=−logi=1∏Nβ−12π1e−2β−1(ti−y(xi;θ))2
=i=1∑Nlogβ−12π1e−2β−1(ti−y(xi;θ))2
=2βi=1∑N(ti−y(xi;θ))2+2Nlogβ−12π
=2βi=1∑N∥ti−y(xi;θ)∥22+const
네 번재 식은 로그함수가 지수항을 상쇄했다.
다섯번째 식은 ti−y(xi;θ))2=∥ti−y(xi;θ)∥22로 만들고 2Nlogβ−12π는 const로 만들었다.
이 식에서 2β 는 1 로 변경하고 const를 없애면 다음과 같이 오차제곱합(sum of squared error)
또는 SSE가 된다
J(θ)=i=1∑N∥ti−y(xi;θ)∥22
최적화 문제에서 목적 함수에 상수배를 해도 최적해는 동일하기 때문에 2β 는 1로 변경할 수 있다. 마찬가지로 목적 함수에 상수를 더하거나 빼도 최적해는 동일하기 때문에 const는
없애도 된다.
이 식에 N1 로 곱하면 앞에서 오차 최소화 관점에서 유도했던 평균제곱오차로 변환한다.
평균제곱오차는 오차제곱합의 상수배를 한 식이므로 둘의 최적해는 동일하다. 따라서 우도를 최대화하는 것은 오차를 최소화하는 것과 같다는 것을 알 수 있다.
만약 예측 분포가 라플라스 분포(Laplacian distribution)라면, 평균절대오차와 같은 결과를
얻을 수 있다.
이진 분류 문제에서 최대우도추정을 위한 손실 함수 정의
이진 분류 문제에서 최대우도추정을 위한 손실 함수를 정의해 보자.
이진 분류 모델이 추정하는 베르누이 분포 p(ti∣xi;θ)는 신경망 모델이 출력한 첫 번째 클래스의 발생 확률인 µ(xi;θ)로 정의된다.
p(ti∣xi;θ)=Bern(ti;μ(xi;θ))
=μ(xi;θ)ti(1−μ(xi;θ))1−ti,ti∈{0,1}
이제 신경망 모델을 통해 추정된 베르누이 분포의 음의 로그 우도를 손실 함수로 정의해 보자.
J(θ)=−logi=1∏Np(ti∣xi;θ)
=−logi=1∏Nμ(xi;θ)ti(1−μ(xi;θ))1−ti
=−i=1∑Nlogμ(xi;θ)ti(1−μ(xi;θ))1−ti
=−i=1∑Nti⋅logμ(xi;θ)+(1−ti)⋅log(1−μ(xi;θ))
네 번째 식은 지수 ti와 1−ti를 log 함수의 밖으로 옮긴 것이다 이 식을 이진 크로스엔트로피(binary cross entropy)라고 한다. 이진 크로스 엔트로피는 K = 2인 크로스 엔트로피이다.
최적화 할 때는 이 식에 N1 을 곱해서 샘플에 대한 합산을 평균으로 바꿔 사용하기도 한다. 두 손실 함수의 최적해는 동일하지만 평균을 사용하면 최적화 과정에서 손실이 작아지므로 수치상 안정화 될 수 있다.
이제 신경망 모델을 통해 추정된 카테고리 분포의 음의 로그우도를 손실 함수로 정의해 보자.
J(θ)=−logi=1∏Np(ti∣xi;θ)
=−logi=1∏Nk=1∏Kμ(xi;θ)ktik
=−i=1∑Nlogk=1∏Kμ(xi;θ)ktik
=−i=1∑Nk=1∑Ktik⋅logμ(xi;θ)k
신경망 학습을 위한 손실 함수
신경망을 학습하기 위해 오차를 최소화하거나 우도를 최대화하는 방법으로 손실 함수를 유도해 보았다.
지도 학습에서 대부분의 문제가 기본 회귀 문제와 분류 문제를 확장하거나 변형 또는 혼합한 형태인 만큼 손실 함수에 평균제곱오차와 크로스 엔트로피가 포함될 때가 많다.
요약해 보면 회귀 문제에서는 평균제곱오차를 사용하고 분류 문제에서는 이진 크로스 엔트로피 또는 크로스 엔트로피를 사용한다.
정보량, 엔트로피, 크로스 엔트로피
정보량은 확률을 표현하는데 필요한 비트 수로 사건이 얼마나 자주 발생하는지를 나타낸다.
엔트로피는 확률 변수가 얼마나 불확실한지를 나타낸다.
크로스 엔트로피는 두 분포의 차이가 어느 정도인지를 판단하는 데 사용한다.
정보량
정보는 놀라움의 정도에 비례한다.
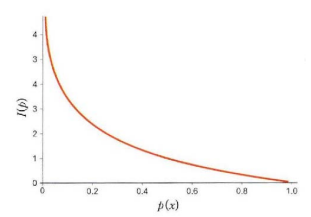
확률이 낮은 사건이 발생하면 놀라움의 정도가 커지므로 정보가 많다고 볼 수 있다. 따라서 정보량은 확률에 반비례하면서 독립 사건들의 정보량은 더해져야 하므로 정보량은 확률의 역수에 로그를 취한 값으로 정의된다. 확률 변수 관점에서 정보량은 확률을 표현하는 데 필요한 비트 수이다.
확률이 0이면 정보량은 무한대가 되고 확리이 1이면 정보량은 0이다 즉 발생하지 않는 사건의 정보량은 무한대이며 100% 발생하는 사건의 정보량은 없다.
엔트로피
엔트로피란 확률 변수 또는 확률 분포가 얼마나 불확실 한지 혹은 무작위한지를 나타낸다.
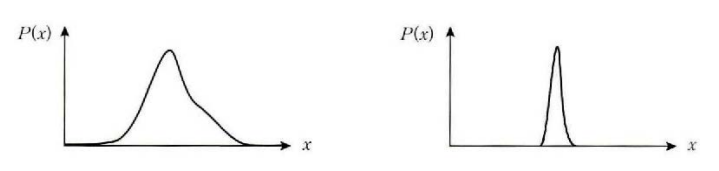
왼쪽 그래프는 분산이 큰 확률분포로 넓은 범위에서 사건이 발생하기 때문에 어떤 사건이 발생할지 불확실하다. 따라서 엔트로피가 높은 상태이다.
오른쪽 그래프는 분산이 작은 확률분포로 좁은 범위에서 사건이 발생하기 때문에 어떤 사건이 발생할지 확실하다 따라서 엔트로피가 낮은 상태이다.
엔트로피는 확률 변수의 정보량의 기댓값으로 정의된다.
H(p)=Ex∼p(x)[−logp(x)]=−∫xp(x)logp(x)dx
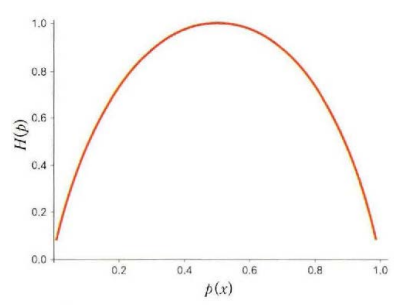
p(x)를 −logp(x)의 가중치로 생각하면 p(x)=0이면 −logp(x)=∞ 이므로 두값의 곱인 −p(x)−logp(x)=0이 되고 p(x)=0 또는 p(x)=1일때 엔트로피는 0이 되고 p(x)=0.5일때 엔트로피는 가장 커진다.
동전을 던졌을 때 앞면이 나올 확률로 정의되는 베르누이 분포에 대한 엔트로피를 생각해보면 동전의 앞면이 나올 확률이 0.5인경우 앞면이 나올지 뒷면이 나올지 불확실 하므로 엔트로피가 가장 높다.
동전의 앞면이 나올 확률은 p(x=1)=μ 이고 동전의 뒷면이 나올 확률은 p(x=0)1−μ 라고 하자 이 식에 동전의 앞면이 나올 확률 μ=0.5를 대입하면 엔트로피가 1이 되는 것을 확인할 수 있다.
H(p)=Ex∼p(x)[logp(x)]
=−(p(x=1)logp(x=1)+p(x=0)logp(x=0))
=−(μlogμ+(1−μ)log(1−μ))
=−(0.5log0.5+0.5log0.5)
=−log0.5
=1
크로스 엔트로피
크로스 엔트로피는 두 확률분포의 차이 또는 유사하지 않은 정도(dissimilarity)를 나타낸다. 확률분포 q로 확률분포 p를 추정한다고 해보자.
크로스 엔트로피는 q의 정보량을 p에 대한 기댓값을 취하는 것으로 정의된다. q가 p를 정확히 추정해서 두 분포가 같아지면 크로스 엔트로피는 최소화되고 q가 p를 잘못 추정하면 크로스 엔트로피는 높아진다. 따라서 크로스 엔트로피는 q와 p의 유사하지 않은 정도를 나타내는 지표로 볼 수 있다.
손실 함수로서 이진 크로스 엔트로피의 동작
신경망의 예측 분포와 타깃 분포가 같을 때와 다를 때 크로스 엔트로피가 어떻게 달라지는지 확인해 보자.
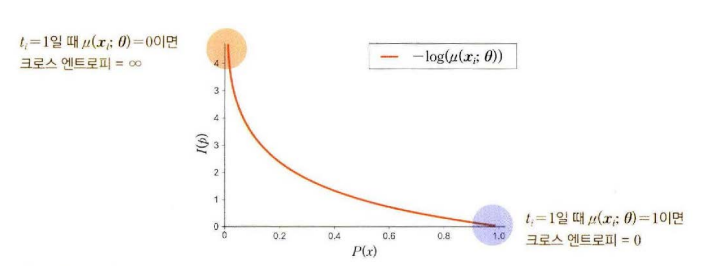
다음과 같은 이진 크로스 엔트로피 손실 함수의 타깃값이 ti=1인 경우와 ti=0인 경우를 별도로 살펴보자. 단 하나의 데이터 샘플 (x_i, t_i)에 대해서만 살펴본다.
이 경우 모델의 예측값 μ(xi;θ)가 1이면 엔트로피는 0이고 μ(xi;θ)가 0이면 크로스 엔트로피는 ∞가 된다.
따라서 예측 분포와 타깃 분포가 같으면 크로스 엔트로피는 0이 된다는 것을 알 수 있다.
반면 ti=1이고 μ(xi;θ)=0이면 두 값이 반대이므로 크로스 엔트로피는 ∞가 된다.