신경망 학습
신경망 학습의 의미
학습데이터를 통해 입력 데이터가 들어왔을 때 적절한 출력을 만들어 낼 수 있는 규칙을 찾는 과정
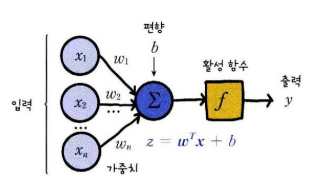
입출력 매핑 규칙의 형태
- 신경망에 입력 데이터가 들어왔을 때 어떤 출력 데이터를 만들어야 할지를 정하는 규칙은 함수적 매핑 관계로 표현된다.
- 가중 합산과 활성함수가 연결되어 뉴런을 구성하고 뉴런이 모여 계층을 구성하며 계층이 쌓여 신경망의 계층구조가 정의된다.
- 신경망 구조와 관련된 것들은 학습전에 미리 정하고 학습 과정에서는 모델 파라미터의 값을 찾는다.
최적의 파라미터 값을 찾는 법
함수의 해를 근사적으로 찾는 최적화 기법을 활용해 신경망이 관측 데이터를 가장 잘 표현하는 함수가 되도록 만들어준다.
최적화 (회귀문제)
타깃과 예측값의 오차를 최소화하는 파라미터를 찾으라는 최적화 문제로 정의
MSE=θminN1i=1∑N∣∣ti−y(xi;θ)∣∣22
최적화 (분류 문제)
분류 문제는 확률 모델 관점에서 관측 확률 분포와 예측 확률 분포의 차이를 최소화하는 파라미터를 찾으라 라는 최적화 문제로 정의
crossentropy=θmin−N1i=1∑Nk=1∑Ktik⋅logμ(xi;θ)k
최적화를 통한 신경망 학습
손실 함수의 임의의 위치에서 출발해 최적해가 있는 최소 지점을 찾아가는 과정을 최적화 과정이라 한다.
최적해를 찾기 위한 좋은 출발점은 알 수 없으므로 최적화 알고리즘은 어느 위치에서 출발하든 손실함수의 최소지점에 갈 수 있어야한다.
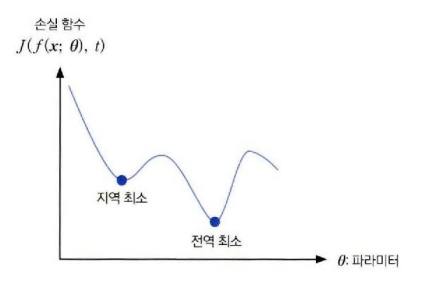
신경망의 학습목표
궁극적인 학습 목표는 Global minimum에 해당하는 파라미터를 찾는 것이지만 Global minimum를 찾기위해선 곡면 전체모양을 확인해야하므로 계산비용이 많이 들어 대부분의 최적화 알고리즘의 목표는 local minimum을 찾는 것이다. 단 좋은 local minimum을 찾으려면 해를 여러 번 찾아 좋은 해를 선택한다.
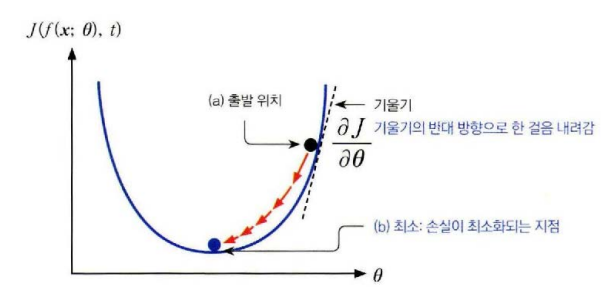
경사 하강법(Gradient Descent)
-
경사 하강법은 손실 함수의 최소 지점을 찾기 위해 경사가 가장 가파른 곳을 찾아서 한 걸음씩 내려가는 방법이다.
-
현재 위치에서 경사가 가장 가파른 곳을 찾기 위해 손실 함수의 기울기를 구하고 기울기의 반대방향으로 내려간다.
θ+=θ−α∂θ∂J
-
경사 하강법으로 손실함수의 현재 위치 θ에서 다음 위치 θ^+로 한걸음 이동하려면 다음과 같은 업데이트 식을 사용한다. θ는 신경망 모델의 파라미터이다.
-
이때 J는 손실함수 α는 step size 또는 learning rate로 이동 폭을 결정한다.
기울기 ∂θ∂J는 손실함수 J(f(x;θ))를 파라미터 θ에 대해 미분한 그래디언트다.
-∂θ∂J는 이동방향으로 기울기의 음수 방향을 나타내므로 현재 지점에서 가장 가파른 내리막길로 내려가겠다는 의미다.
-
경사 하강법에서는 파라미터 업데이트 과정을 반복하다가 θ−θ+가 아주작은 특정값 이하가 되면 최소지점에 도달한 것으로 판단하고 이동을 멈춘다.
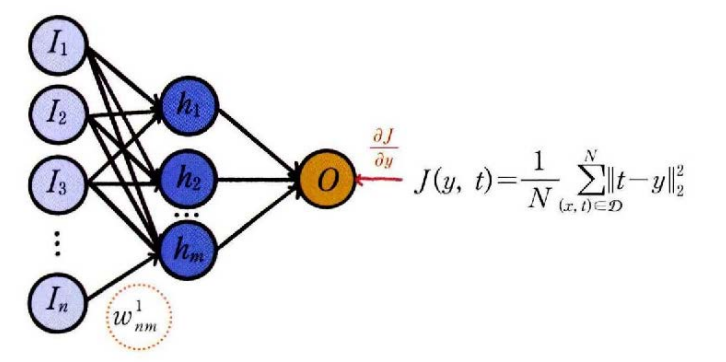
파라미터 업데이트식
- wnm1에서 위 첨자 1은 계층 번호이고 아래 첨자 n은 입력 뉴런의 인덱스를 m은 은닉 뉴런의 인덱스를 나타낸다.
- 경사 하강법을 이용해 가중치 wnm1값을 업데이트하려면 먼저 손실 함수에 대한 가중치의 미분 ∂wnm1∂J를 구해서 다음 업데이트 식으로 wnm1를 wnm1+로 변경한다.
wnm1+=wnm1−α∂wnm1∂J 그런데 이 업데이트식은 바로 계산 할 수 없다.
손실함수 J(y,t)=N1∑(x,t)∈D∣∣t−y∣∣22 에는 가중치 변수 wnm1가 포함되지 않기 때문이다. 신경망에서 가중치변수 wnm1는 은닉 뉴런에 정의되며 출력 뉴런을 거쳐서 손실함수에 간접적으로 영향을 미친다.
즉, 손실함수는 합성 함수로 정의되며 합성함수를 미분하려면 연쇄법칙(chain rule)을 사용해야한다.
연쇄 법칙을 사용한 미분 계산
연쇄법칙으로 합성함수의 미분을 표현할 때는 합성 함수의 실행 순서에 따라 각함수의 미분을 곱해준다.
가중치 변수 w_nm^1가 정의된 은닉 뉴런부터 손실 함수까지 실행되는 함수의 순서
(1)zm1=w1m1⋅x1w2m1⋅x2+⋯+wnm1⋅xn→∂wnm1∂zm1=xn
(2)am1=ReLU(zm1)→∂zm1∂am1=RELU′(zm1)
(3)z2=w12⋅a11+w22⋅a21+⋯+wm2⋅am1→∂am1∂z2=wm2
(4)y=Identity(z2)→∂z2∂y=Identity′(z2)=1
(5)J(y)=N1(x,t)∈D∑N∣∣t−y∣∣22→∂y∂J=−N1(x,t)∈D∑N2(t−y)
(1)과 (2)는 은닉 뉴런 hm에 정의된 가중 합산과 ReLU이다.
(3)과 (4)는 출력 뉴런 O에 정의된 가중 합산과 항등 함수이다.
(5)는 손실 함수이다.
각 함수의 미분을 곱하면 연쇄 법칙 형태
∂wnm1∂J=∂y∂J⋅∂z2∂y⋅∂am1∂z2⋅∂zm1∂am1⋅∂wnm1∂zm1
로 ∂wnm1∂J를 정의할 수 있다.
Backpropagation (역전파 알고리즘)
뉴런 hm의 또다른 가중치 wn−1m1에 대해 미분할 때 연쇄 법칙으로 미분을 표현하면 마지막항인 ∂wn−1m1∂zm1을 제외한 앞부분의 ∂y∂J⋅∂z2∂y⋅∂am1∂z2⋅∂zm1∂am1의 미분과 동일하다는 것을 알 수 있다.
∂wm1∂J=∂y∂J⋅∂z2∂y⋅∂am1∂z2⋅∂zm1∂am1⋅∂wnm1∂zm1
∂wn−1m1∂J=∂y∂J⋅∂z2∂y⋅∂am1∂z2⋅∂zm1∂am1⋅∂wn−1m1∂zm1
즉 공통부분
∂zm1∂J=∂y∂J⋅∂z2∂y⋅∂am1∂z2⋅∂zm1∂am1
은 한 번 계산해두면 같은 뉴런에 속한 모든 가중치의 미분을 계산할 때 재사용 할 수 있다.
공통부분의 계산을 중복하지 않으려면 손실 함수에서 시작해서 입력 계층 방향으로 계산된 미분 값을 역방향으로 전파해주면 된다. 이때 각 뉴런의 공통부분에 해당하는 미분값을 오차라고 하며 오차를 역방향으로 전파하면서 미분을 계산한다고 해서 이런 미분 계산 방식을 오차의 역전파 알고리즘이라고 부른다.
역전파 알고리즘의 실행 순서
손실함수 미분
출력 뉴런 미분
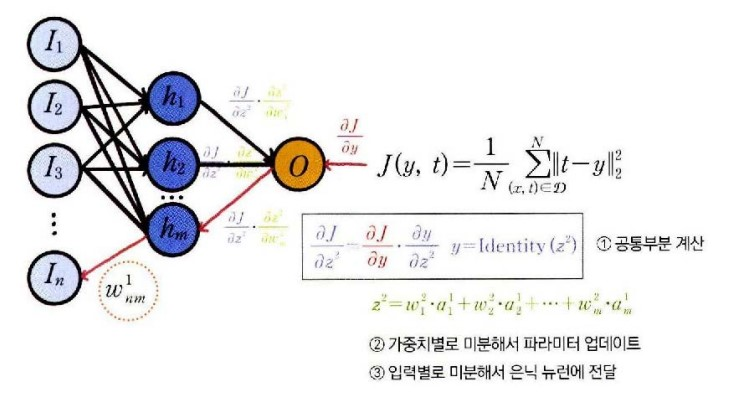
- 공통부분 계산
- 가중치 업데이트
- 은닉 계층에 미분전달
은닉 뉴런 미분
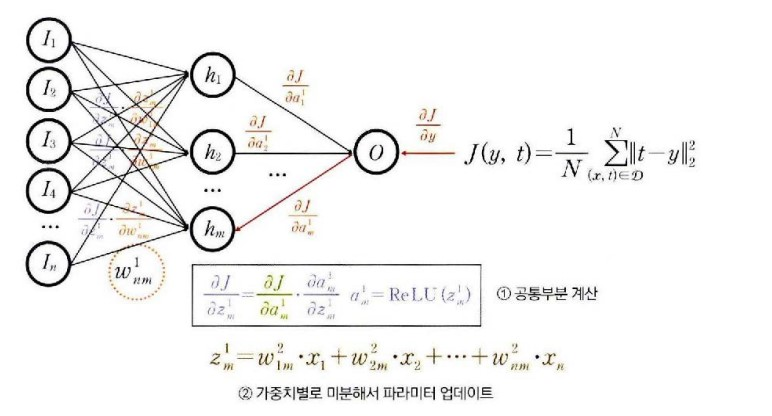
- 공통부분 계산
- 가중치 업데이트 입력 계층에 미분전달
