머신러닝, 딥러닝을 공부하며 Train 데이터와 Test 데이터는 어느정도 알겠는데 Validation 데이터가 갖는 의미가 헷갈려서 찾아보았다.
머신러닝과 딥러닝 모델을 활용한 기계학습은 모델의 파라미터를 계속 바꾸면서 가장 적절한 파라미터를 찾는 과정이다.
그리고 이렇게 학습한 모델이 내가 가진(학습에 사용한)데이터가 아닌 다른 데이터에도 적용할 수 있는 범용성을 갖춘 모델이여야한다.
내가 이해한 기계학습을 가장 이해하기 쉽게 표현하자면 초등학교때 배우는 방정식과 유사하다.
Y = ax+ b
위와 같은 식에 여러 개의 Y값과 X값 쌍이 주어지고 이러한 식이 다수 존재할 때 가장 적절한 a와 b의 값을 찾는 것이다. (Y= 정답 데이터, X = 입력데이터, a,b = 파라미터)
※실제 모델의 수식은 위와 같이 단순하지 않음
이러한 과정에 입력과 출력으로 들어가게될 데이터셋을 Train, Test, Validation 세 종류로 나누어 사용한다.
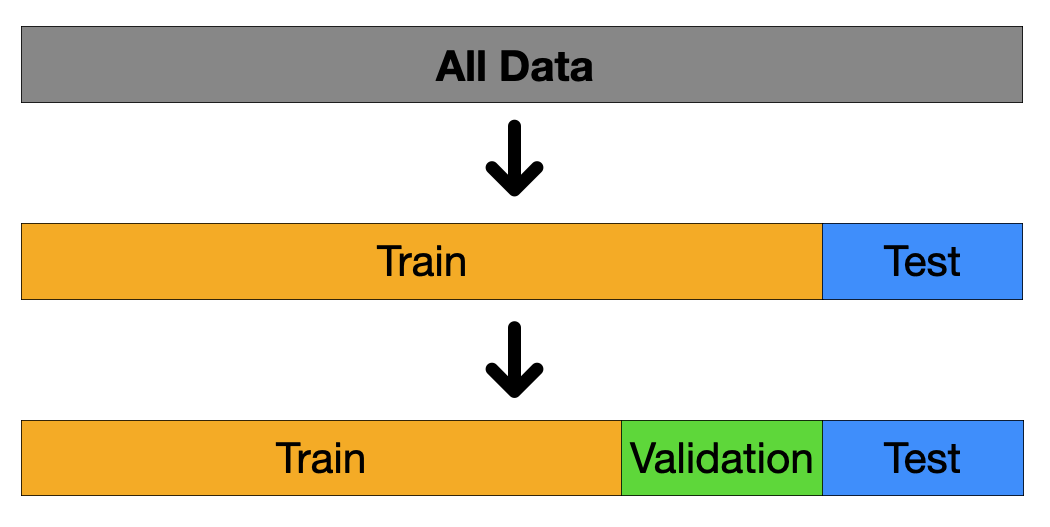
1.Train, Test 데이터 분류
쉽게 말하자면
Train데이터는 내가 가진(학습에 사용할) 데이터이고
Test데이터는 내가 가지지 않은(학습에 사용하지 않을)데이터이다.
현재 Train 데이터로 모델을 학습시키고 학습한 모델의 성능을 평가하기 위해 Test 데이터를 활용한다.
위의 과정에서 나온 모델의 성능을 개선하기 위해 하이퍼파라미터, 입력자료, 모델구조 등을 변경한다.
하지만 이렇게 변경된 모델이 Test 데이터에 과도하게 적합하게 되어버린다면?
앞에서 말했듯 우리가 생성한 모델은 내가 가지고 있지 않은 다른 데이터에도 적용할 수 있는 범용성이 필요하다.
따라서 Train 데이터이던 Test 데이터이던 어떠한 데이터에 과도하게 적합해서는 안된다.
2.Validation
우리의 모델이 Train과 Test 데이터 모두에게 과적합되지 않게 하기 위해 Validation 데이터라는 개념을 사용한다.
사용 목적을 정리하자면
Train 데이터:
1) 모델을 학습시키기 위한 데이터셋으로 오로지 학습에만 사용됨
Validation 데이터:
1) 학습이 끝난 모델을 검증하기 위한 데이터셋
2) 여러 개의 모델 중 가장 좋은 모델을 고르기 위한 데이터셋
-> 학습에 직접 관여(파라미터 변경)에 영향을 주지는 않음
Test 데이터:
1) 모델의 성능을 측정하기 위한 데이터
데이터 셋 분할
데이터를 분할할 때 가장 기본적으로는 6:2:2(Train, Validation,Test)로 구분한다.
만약 데이터가 많은 경우를 가정한다면 위의 식대로 데이터를 구분한다고한들 학습에 충분한 양의 데이터를 사용할 수 있다.
하지만
데이터가 적은 경우에는 6:2:2로 데이터를 나누었을 때 학습데이터의 양이 충분하지 않을 수 있다.
이럴 경우 Cross Validation 방법을 사용할 수 있다.
이전에 공부했을 때 Cross Validation 방법은 모델의 과적합을 방지하기 위한 방법 정도로 알고있었다.
K-fold Cross Validation
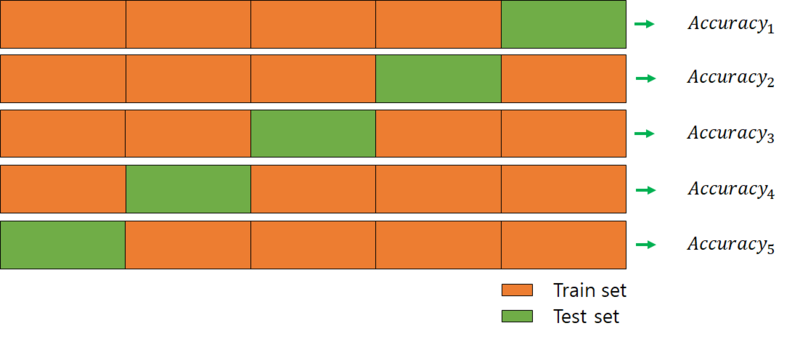
이 사진처럼 데이터를 먼저 5개로 잘라서 3개는 Train, 1개는 Validation, 1개는 Test로 활용한다면 과적합을 방지하면서도 적은 데이터로 모델을 학습시킬 수 있다.(이 사진에는 validation set이 없다.)
또 한가지 더 데이터를 분할할 때 고려해야할 점이 있는데
데이터의 특성을 고려한 분류를 수행해야한다.
