Machine Learning
1.Classification

머신러닝 지도 학습의 기본적인 유형인 분류(classification)는 학습 데이터로 주어진 피처와 레이블값(결정값, target)을 머신러닝 알고리즘으로 학습해 모델을 생성하고 이렇게 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측한다.기존
2.결정 트리(Decision Tree)
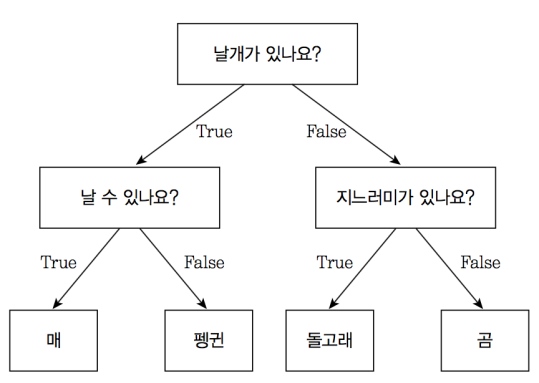
결정 트리머신러닝 알고리즘 중 가장 직관적으로 이해하기 쉬운 알고리즘으로 데이터에 있는 규칙을 학습하여 찾아내 트리(Tree)기반의 분류 규칙을 만드는 것쉽게 생각하면 스무고개 게임과 유사하여 if, else를 통해 규칙을 찾아내 데이터를 점진적으로 나누는 것으로 아래
3.앙상블(Ensemble)
앙상블 학습앙상블 학습을 통한 분류는 여러개의 분류기(Classifier)를 생성하고 결과를 예측함으로써 하나의 분류기를 사용했을 경우 보다 더 정확한 최종 예측을 도출하는 방법을 말한다.이미지, 영상, 음성 등의 비정형 데이터에 대한 분류는 딥러닝의 성능이 뛰어나지만
4.차원 축소(Dimension Reduction)
많은 피처로 구성된 다차원 데이터 세트의 차원을 축소해 새로운 차원의 데이터 세트를 생성하는 것으로 일반적인 경우 차원이 증가할수록 데이터 포인트 간의 거리가 멀어지게되고 희소한 구졸ㄹ 가지게됨 수백 개 이상의 피처로 구성된 데이터 스트의 경우 상대적으로 적은 차원에서
5.PCA, LDA, SVD, NMF
가장 대표적인 차원 축소 기법으로 PCA는 여러 변수간에 존재하는 상관관계를 이용해 주성분(Principal Component)을 추출해 차원을 축소하는 기법으로 PCA로 차원을 축소할 경우 기존 데이터의 정보가 유실이 최소화 된다.PCA는 가장 높은 분산을 가지는 데