Event Hubs, 왜 필요할까?
새로운 서비스나 기존에 있던 서비스들을 볼 때, 아마 가장 먼저 보는 부분이 아닐까 한다.
간단히 말하면 다수의 서비스간 event들이 발생될텐데, 이 event msg를 서로 주고 받아야 할 때, 유용하게 쓸 수 있는 PaaS형 서비스이다.
event 처리 플랫폼!!
그리고, Event Hubs는 fully managed PaaS이기에, 비슷한 솔루션을 사용할 때 겪었던, cluster나 manage 또는 configuration이라는 고통들로부터 해방될 수 있다.

출처: https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-about
위와 같이, 이벤트들이 발생되고, event를 핸들링 하기 위해, event receiver들에게 이벤트를 전달해야하는데, 이 event msg들을 전달할 수 있게 해주는 플랫폼을 제공한다.
이벤트가 발생한다 -> 메시지를 보낸다 -> 메시지를 받아서 처리한다.
위와 같은 과정에서,
메시지를 어떻게 주고 받을 것인가?를 해결 해준다.
어떤 방식으로 event msg를 주고 받나?
위와 같이 대량의 event 처리를 위해 msg queue와 같은 솔루션을 많이 찾아보았다면 pub/sub이라는 단어를 접해 보았을 것이다.
pub/sub은 뭘까?
publish와 subscribe의 줄임말로, msg를 어떻게 주고 받냐에 대한 부분이다.
pub/sub의 과정 간단 설명
- msg를 생산하는 쪽에서 A라는 박스안에 msg를 생산될 때마다 넣어놓는다.
- msg를 가져가서 처리하는 쪽이 A라는 박스를 주기적으로 확인하다가 msg가 들어오면 가져가서 처리한다.
참 쉽죠?
이제 간다, 심해속으로...
조금 더 심화편으로 가보자

너무 깊이 와버렸나?
Event hubs 구조
기존 kafka를 다루신 분들은 아래를 통해 빠른 이해가 될 것 같다.
- Event hubs Namespace == kafka cluster
- Event hubs Instance == Topic
- Consumer group == Consumer group

처음 접하시는 분들을 위해, 비루한 글솜씨지만 열심히 준비해 보았다.
Event hubs Namespace
event 처리 플랫폼은 big data와 같은 큰 단위도 처리해야하고, 여러 event 처리 통로를 가져야 하기에, cluster로 구성되어져 있다.
이러한 전체 cluster를 Event hubs Namespace라고 표현한다.
(kafka cluster)
Cluster에서 node의 개수와 같이, Event hubs에서는 아래의 스크린샷과 같이, Event hubs는 throughput unit과, 추가적으로 auto inflate를 지원한다.

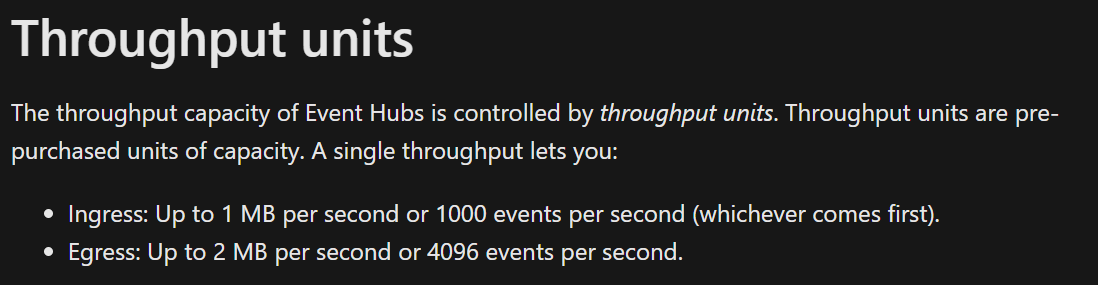
Throughput Units은, ingress, egress의 단위라고 보면된다.
1 throughput unit은,
ingress: 1MB/sec 또는 1000 envents/sec
egress: 2MB/sec 또는 4096 events/se
이다.
Auto-inflate는, 자동으로 salce up되는 부분이다. 사용량이 많아질 경우, 자동으로 throughput unit을 scale up하여 나의 서비스가 계속 돌아가게끔 도와준다.
Event hubs Instance
kafka에서 topic이라고도 불리우는 개념으로, msg가 생산되어지고 저장이 되어지는 큰 저장창고라고 보면된다.
안에는 partition이라고 불리우는 저장창고안의 저장공간이 있다.
여러개로 partition을 사용할시, 분산 저장되어, 뒤쪽의 consumer가 가져갈때 분산하여 들고 갈 수 있어 빠르게 처리가 가능하다. partition은 저장창고의 출구도 같이 포함하고 있다고 표현하면 조금 더 쉬운 표현이 되려나?
partition과 cosnumer의 수는, partition >= consumer instance가 적절하다.
partition의 수보다 consumer instance가 더 많아져도 어차피 partition에 접근할 수 있는 consumer는 1개이기 때문이다.
차라리, partition수보다 consumer 수를 더 적게 하여, 중간에 consumer instance가 죽더라도, offset이라는 것을 통해 어디까지 읽었는지 알 수가 있어, 다른 consumer instance가 이어서 읽을 수 있다.
가장 중요한 부분인데, partition 수는 한번 늘리면, 구조상 다시 줄일 수 없기에 신중해야 한다.
Consumer group
이름에서 유추할 수 있듯, partition에 있는 msg들을 가져가는 주체.
테스트 코드
아래 테스트 코드 사용의 목적은,
Event hubs도 따로 lib를 제공하지만, 분명 많은 사람들이 기본적으로 kafka를 사용하던 사람들이라, kafka package 또는 confluent에서 사용하는 package를 사용할 것이라 생각했다.
완벽 까지는 아니더라도, 구조가 동일하다면, 코드를 똑같이 쓰고 endpoint만 Event hubs 것으로 바꾸면 대박이겠는데?
테스트 코드들은 아래의 github에서 확인할 수 있다.
https://github.com/Azure/azure-event-hubs-for-kafka/tree/master/quickstart/python
producer와 consumer코드를 보면 알 수 있듯, confluent package를 사용한 코드다.
python
producer.py
#!/usr/bin/env python
#
# Copyright (c) Microsoft Corporation. All rights reserved.
# Copyright 2016 Confluent Inc.
# Licensed under the MIT License.
# Licensed under the Apache License, Version 2.0
#
# Original Confluent sample modified for use with Azure Event Hubs for Apache Kafka Ecosystems
from confluent_kafka import Producer
import sys
if __name__ == '__main__':
if len(sys.argv) != 2:
sys.stderr.write('Usage: %s <topic>\n' % sys.argv[0])
sys.exit(1)
topic = sys.argv[1]
# Producer configuration
# See https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md
# See https://github.com/edenhill/librdkafka/wiki/Using-SSL-with-librdkafka#prerequisites for SSL issues
conf = {
'bootstrap.servers': 'mynamespace.servicebus.windows.net:9093', #replace
'security.protocol': 'SASL_SSL',
'ssl.ca.location': '/path/to/ca-certificate.crt',
'sasl.mechanism': 'PLAIN',
'sasl.username': '$ConnectionString',
'sasl.password': '{YOUR.EVENTHUBS.CONNECTION.STRING}', #replace
'client.id': 'python-example-producer'
}
# Create Producer instance
p = Producer(**conf)
def delivery_callback(err, msg):
if err:
sys.stderr.write('%% Message failed delivery: %s\n' % err)
else:
sys.stderr.write('%% Message delivered to %s [%d] @ %o\n' % (msg.topic(), msg.partition(), msg.offset()))
# Write 1-100 to topic
for i in range(0, 100):
try:
p.produce(topic, str(i), callback=delivery_callback)
except BufferError as e:
sys.stderr.write('%% Local producer queue is full (%d messages awaiting delivery): try again\n' % len(p))
p.poll(0)
# Wait until all messages have been delivered
sys.stderr.write('%% Waiting for %d deliveries\n' % len(p))
p.flush()consumer.py
#!/usr/bin/env python
#
# Copyright (c) Microsoft Corporation. All rights reserved.
# Copyright 2016 Confluent Inc.
# Licensed under the MIT License.
# Licensed under the Apache License, Version 2.0
#
# Original Confluent sample modified for use with Azure Event Hubs for Apache Kafka Ecosystems
from confluent_kafka import Producer
import sys
if __name__ == '__main__':
if len(sys.argv) != 2:
sys.stderr.write('Usage: %s <topic>\n' % sys.argv[0])
sys.exit(1)
topic = sys.argv[1]
# Producer configuration
# See https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md
# See https://github.com/edenhill/librdkafka/wiki/Using-SSL-with-librdkafka#prerequisites for SSL issues
conf = {
'bootstrap.servers': 'mynamespace.servicebus.windows.net:9093', #replace
'security.protocol': 'SASL_SSL',
'ssl.ca.location': '/path/to/ca-certificate.crt',
'sasl.mechanism': 'PLAIN',
'sasl.username': '$ConnectionString',
'sasl.password': '{YOUR.EVENTHUBS.CONNECTION.STRING}', #replace
'client.id': 'python-example-producer'
}
# Create Producer instance
p = Producer(**conf)
def delivery_callback(err, msg):
if err:
sys.stderr.write('%% Message failed delivery: %s\n' % err)
else:
sys.stderr.write('%% Message delivered to %s [%d] @ %o\n' % (msg.topic(), msg.partition(), msg.offset()))
# Write 1-100 to topic
for i in range(0, 100):
try:
p.produce(topic, str(i), callback=delivery_callback)
except BufferError as e:
sys.stderr.write('%% Local producer queue is full (%d messages awaiting delivery): try again\n' % len(p))
p.poll(0)
# Wait until all messages have been delivered
sys.stderr.write('%% Waiting for %d deliveries\n' % len(p))
p.flush()Event hubs를 생성하고, 위의 필요 요소들을 채워서 테스트하면, producer.py를 통해 msg를 생성해서 Event hubs안으로 넣고, consumer.py를 통해 잘 읽어 오는 부분을 확인할 수 있다.
진짜 테스트했는데 스크린샷을 안찍어놨었네....
거짓말 아니라구...
마치며
기존에 kafka를 사용 하였거나, event 처리 플랫폼을 고려하고 있다면, Event hubs 나쁜 선택이 아닐 것 같다. 기존에 썻던 코드 100%까진 아니겠지만 (IaaS에서 사용하던 것들을 PaaS에서 100% 다 쓰고 싶다는건, 사실 욕심이 아닐까?) 웬만한 부분까지는 그대로 돌아간다고 말할 수 있는것 같다.
특히 kafka 클러스터 관리 힘들지 아니한가?
가자 Fully Managed PaaS인 Event hubs로.
