로깅을 하자!
운영을 하다보면 엔지니어라면 피해갈 수 없는 추리물이 있다.
바로 원인분석!! 범인잡기

범인잡기?!
세상에 완벽한 솔루션은 없다. 조금 바꿔말해 보자면, 계산기 수준의 간단함이 아니라면 결함 및 오류는 언제나 일어난다고 생각한다. 아니, 계산기 수준의 간단한 어플리케이션이라도 여러 문제로 인해 문제는 발생할 수 있다.
가만히 놔뒀는데도 불구하고, 운영 단계에서 문제가 일어날 수 있는 원인은 너무 다양하다.
ex)
- 갑자기 업데이트가 되며 VM이 꺼지는 경우
- 클라우드 플랫폼 자체적인 문제로 안되는 경우
- app 자체의 메모리 누수가 발생되어 oom이 난 경우
- 사용하는 외부 서비스 api 에서 timeout이 나는 경우
- 처리해야 될 메시지를 큐에 넣었는데, 입력받은 값이 잘못된 형식이라 제대로 처리되지 않은 경우
그냥 생각나는데로만 나열해도 너무 많다. 가만히 잘 돌아가는 서비스가 갑자기 안되는건 너무 비일비재하며 놀랍지도 않다.
우린 이렇게 많은 장애속에 어디가 잘못되었으며 어떻게 고쳐야할지를 알아내야한다. end단에서 보는 부분은 한계가 있기에 운영하는 입장에서 어떻게 이러한 장애들을 tracking 할 지에 대한 계획이 필요하다.
어떤 아이가 문제를 일으켜 내가 이렇게 고생하는지 범인 잡기를 하기 위해선 로깅이라는게 필요하다. 구동일 잘되거나 잘 안되거나 모두 오류 메시지를 뱉게 하여 그 메시지를 저장한다. 저장된 로그 메시지들을 토대로 범인 색출을 진행해야한다.
그럼 내가 지금 구축하려는 Kubernetes 환경에서 범인잡기는 어떻게 할 수 있을까?
이 질문을 대답하기에 앞서, Kubernetes 환경에서는 어떤 문제로 인해 장애가 발생될 수 있는지를 봐야한다.
- kubernetes가 범인인 경우
- application이 범인인 경우
- virtual machine이 범인인 경우
1번의 경우, 범인을 잡기 위해선 control plane과 events 의 logging 이 필요하다.
2번의 경우, 얘네는 node가 사라지면 같이 사라진다. 즉 loki 또는 elasticsearch 같은 곳에 따로 저장할 필요가 있다.
3번의 경우, 흔히 사용하는 prometheus 또는 클라우드의 managed kubernetes를 많이들 사용할텐데 웬만해선 cloud에서도 제공이된다.
Azure에서 control plane, events logging 하기
Control Plain logging
control plain은 간단하다.
AKS의 Diagnostic Setting에서 선택하여 할 수 있다.
아래와 같은 부분을 지원하며 원하는 부분을 Diagnostic Setting에서 지원하는 여러가지 저장소로 이동 시킬 수 있다.
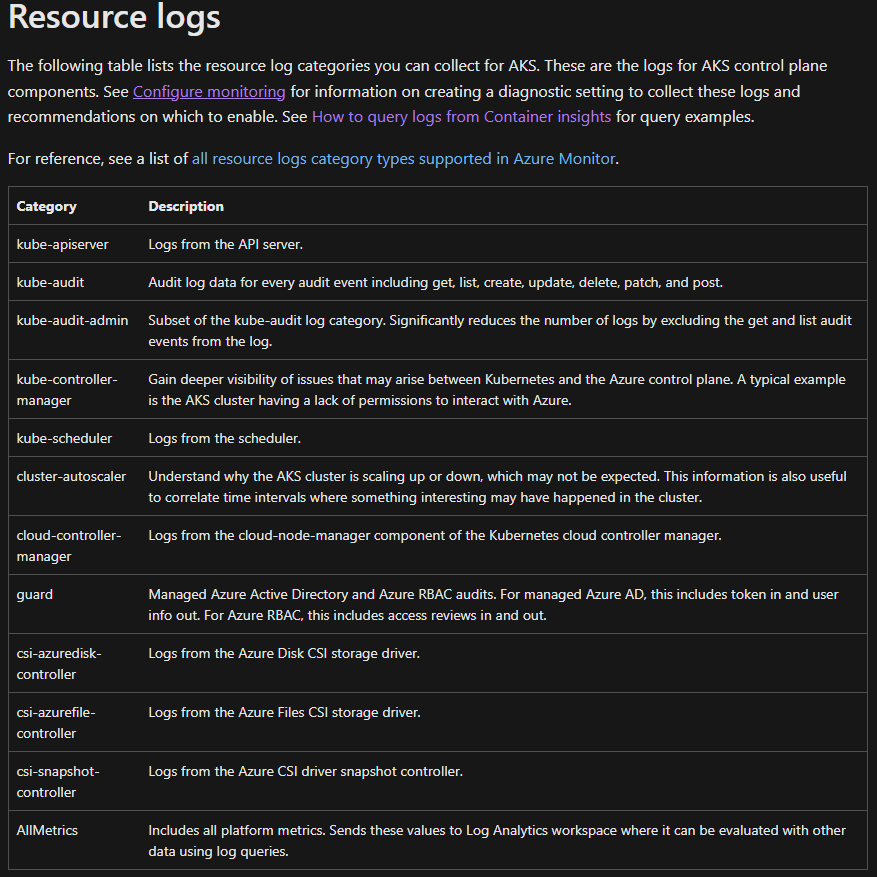
Diagnostic Setting에서 보낼 수 있는 저장소 리스트는 아래와 같다.

그럼 여기서 드는 의문이 있다.

다 좋은데, 이거 어디다 넣어야 해요??
Log Analytics는 비용이 감당 안되구,
Storage Account는 쿼리나 필요한 데이터 뽑기가 너무 난해한데요?
마지막 옵션인 3rd 파티로 넘기는거는, 옵션이 안된다는거 아시죠?
고민이 많이 되는 부분이다. Log analytics는 규모가 커지면 장담하는데 비용감당 안 될거다. Storage Account는 쌓고 저장은 싼데, 로그 찾으러 1시간 간격으로 json 떨궈주는 걸 일일이 열어서 각 파일을 전부 보면서 trouble shooting 할 자신이 있다면 써도 된다. 웬만하면 못 쓴다는 말
추천은 Event hubs에 넣고 쓰는거다. Event hubs가 9093 포트로 사용되면 kafka 처럼 사용할 수 있다. promtail이나 grafana-agent 같은 아이들로 kafka topic을 긁어 올 수 있는데, 이러한 조합으로 loki나 elasticsearch에 넣은 후, Grafana와 같은 대시보드에서 data source로 꽂아서 사용한다면 꽤 괜찮게 사용할 수 있다.
control plain의 데이터를 어떻게 긁어와서 어떻게 볼 것인가는 정말 큰 고민인데 현재 위와 같이 진행하고 있다. 만약 여기 기술한 방법보다 더 좋은 방법이 있다면 이 시리즈에 추가할 예정이다. (이 시리즈는 journey 니까요!!)
Kubernetes Events logging
우리가 흔히 보는 kubectl get events 와 같은 kubernetes events는 일어난 일들을 볼 수 있어 좋으나 1시간만 저장된다. 따로 저장해서 쌓을 필요가 있다. 여러가지 방법이 있겠지만 grafana-agent 같은 아이들을 통해 kafka로 보내고 해당 kafka topic을 loki에 쌓는 방식을 택했다.
Application은 뭘루?
Application Log는 중요하다. 이슈가 발생되면 왜 발생했으며 어디까지 된것인지 알아야 하기에 원인 분석에 아주 쉬운 환경 또한 제공 되어져야 한다.

대체 어디까지 처리된거야!!
이부분은 선택지가 있지만 종착지는 뻔하다.
- Application 개발자에게 자체적으로 특정 경로에 쌓아서 알아서 보라고 한다.
- Loki, elasticsearch와 같은 아이들을 사용하고 Kibana 또는 Grafana 같은 모니터링 tool을 활용한다.
대부분 2번을 선택할 것이다. ELK, EFK, PLG 등 다양한 조합들이 있다. 나는 PLG로 묶어 가고 있다.
범인은 machine?!
이 경우는 보통 범인잡기에서 1차 웬만해선 application log를 먼저 볼텐데 해당 로그들이 없는 경우에 보게된다. 다른 아이들은 있는데 내가 찾는 log만 없다면 control plain 로그 또는 kubectl event 로그를 볼 것이고, 해당 시간대에 모든 로그들이 보이지 않는다면 metric 로그가 필요하다. 이때 사용할 수 있는 아이들이 prometheus와 같은 아이들이다.
만약 cloud 플랫폼에서 제공하는 managed kubernetes를 사용한다면 플랫폼에서도 제공 받을 수 있으나, 나의 경우, 내가 원하는 모니터링 툴에 꽂기 위해서 prometheus를 선택하였다. 특히나 istio를 사용하는데 있어 prometheus가 필요하기에 겸사 겸사 prometheus를 선택하였다. cloud 플랫폼에서 제공하는 것들을 바로 보려면 돈이 많이 필요하다구!!
앞으로의 나의 계획은?
아직 진행중이지만 logging 부분 관련해서 간략하게 계획을 말하자면 아래와 같다.
AKS에서 사용될 logging 및 dashboard tool 리스트
- Prometheus
- Promtail
- Garafana-Agent
- Grafana
- Jaeger
- Kiali
대부분이 Helm으로 말아서 배포할 계획이다. 현재 chart를 열심히 말고 있기에 sub chart로 다 말고 배포 하고 정리해서 하나하나 따로따로 글을 올릴 것 같다!!
마치며
다 정리하고 글로 표현하니 매우 간단해 보이는데, 이거 파악하고 테스트하고 진짜 되는건가 찾아보고 promtail, grafana-agent config 값 바꿔가며 어떻게 들어오는지 보고 하는 부분이 시간이 많이 걸렸다. (같이 테스트 도와주신 엔지니어 분께도 감사를 표한다) (진짜 내가 테스트 많이하고 쉽게 써서 이렇지 쉽지 않았다구요!!) 그래서 나와 같은 고통을 받는 사람이 더이상 없었으면 한다. 각 tool에 대한조금 더 세세한 내용은 뒤에 위의 툴들 관련해서 하나하나 따로따로 올릴 계획이다.
