안녕하세요! 이번 주에는 지난 주에 배운 딥러닝 기초를 바탕으로 시각 지능에 대해 학습했습니다.
첫째 날에는 딥러닝 개념을 복습하고, 둘째 날에는 합성곱 신경망(CNN)에 대해 공부했습니다.
셋째 날에는 데이터가 부족할 때 이를 보완하는 '데이터 증강(Data Augmentation)', 이미 잘 개발된 모델을 활용하는 '사전 훈련된 모델(Pretrained Model)' 사용법과 모델을 커스터마이즈하는 '전이 학습(Transfer Learning)'에 대해 배웠습니다.
넷째 날에는 '객체 탐지(Object Detection)'를 주제로 Yolov8 모델을 사용하여 이미지나 동영상 속 객체를 탐지하는 방법에 대한 실습과 테스트를 진행했습니다.
마지막 날에는 개별 주제로 객체 탐지 실습을 했는데, 저는 알고리즘 스터디에서 친해진 분과 함께 '전략적 팀 전투'라는 게임 화면 속 캐릭터를 탐지하는 미니미니 프로젝트를 진행해보았습니다!
2일차
1. CNN
CNN은 이미지 인식 및 처리에 특화된 딥러닝 모델입니다. 이는 이미지의 시각적 특징을 효과적으로 추출하고 학습하는 데 사용됩니다.
1) 컨볼루션 레이어(Convolutional Layer)
기능: 이미지로부터 특징을 추출합니다.
작동: 필터(또는 커널)를 이미지 위에서 이동시키면서 각 위치의 픽셀 값과 필터 값을 곱한 후 합산합니다.
결과: 특징 맵(Feature Map)을 생성하여 이미지의 특징 정보를 포착합니다.
2) 활성화 함수(Activation Function)
주로 사용되는 함수: ReLU(Rectified Linear Unit)
목적: 비선형성을 도입하여 모델의 학습 능력을 향상시킵니다.
3) 풀링 레이어(Pooling Layer)
종류: 최대 풀링(Max Pooling), 평균 풀링(Average Pooling)
기능: 특징 맵의 크기를 줄이고, 중요한 특징을 유지하면서 계산량을 감소시킵니다.
4) 완전 연결 레이어(Fully Connected Layer)
구성: 풀링 레이어 후에 위치하며, 학습된 특징을 바탕으로 최종 분류를 수행합니다.
2. CNN의 작동 과정
이미지가 입력되면, 여러 컨볼루션 레이어와 활성화 함수를 통해 특징을 추출합니다.
추출된 특징은 풀링 레이어를 통해 크기가 감소됩니다.
마지막에는 완전 연결 레이어를 거쳐 분류 문제에 대한 예측을 수행합니다.
3. CNN의 응용
이미지 분류, 객체 탐지, 영상 인식 등 다양한 시각 지능 관련 작업에서 활용됩니다.
3일차
1. Data Agumentation
개요
데이터 증강은 기존의 데이터셋을 인위적으로 변형하여 데이터의 양과 다양성을 증가시키는 기법입니다.
특히, 데이터가 부족하거나 한정적인 경우에 효과적으로 사용됩니다.
방법
회전(Rotation), 크기 조절(Scaling), 자르기(Cropping)
색상 변경(Color Jittering): 밝기, 대비, 채도 조정
수평 또는 수직으로 뒤집기(Flipping)
기하학적 변형(Geometric Transformations) 등
목적
모델의 일반화 능력을 향상시켜 오버피팅을 방지
다양한 변형에 대한 모델의 강인함을 높임
2. Pretrained Model
개요
사전 훈련된 모델은 이미 대규모 데이터셋에서 훈련된 모델을 의미합니다.
이러한 모델들은 일반적인 특징을 이미 학습했기 때문에 다양한 문제에 활용할 수 있습니다.
사용 방법
특정 작업에 맞게 마지막 몇 개의 계층을 교체하거나 조정
모델의 전체 구조는 유지하되, 특정 작업에 대해 추가 훈련
장점
학습 시간과 컴퓨팅 자원을 절약
소량의 데이터로도 높은 성능 달성 가능
3. Transfer Learning
개요
전이 학습은 기존에 학습된 모델의 지식을 새로운 문제에 적용하는 방법입니다.
주로 사전 훈련된 모델을 기반으로 사용됩니다.
과정
사전 훈련된 모델을 선택
모델의 최종 계층 또는 여러 계층을 새로운 작업에 맞게 변경
새로운 데이터셋에 대해 모델을 재학습
목적
새로운 작업에 대한 학습 시간 및 데이터 요구량 감소
작은 데이터셋으로도 효과적인 모델 학습 가능
주의점
전이 학습의 성공은 원본 데이터셋과 새로운 데이터셋 간의 유사성에 영향을 받음
4일차
1. Object Detection이란?
오브젝트 디텍션은 이미지 내 여러 객체를 식별하고 위치를 찾는 기술입니다. 이는 이미지 분류(Classification)와 위치 추정(Localization)을 결합한 형태로, 각 객체에 대해 다중 라벨 분류(Multi-Labeled Classification)와 바운딩 박스 회귀(Bounding Box Regression)를 수행합니다.
2. Object Detection 주요 개념
1) 바운딩 박스(Bounding Box)
목적: 하나의 오브젝트를 포함하는 최소 크기의 박스를 정의합니다.
좌표: x 최소값, y 최소값, x 최대값, y 최대값, x 중심, y 중심, 너비, 높이
예측: 좌표(, )를 예측하여 오브젝트의 위치와 크기를 정의합니다.
2) 클래스 분류(Class Classification) 및 신뢰도 점수(Confidence Score)
목적: 오브젝트가 바운딩 박스 안에 있는지와 그 확신의 정도를 평가합니다.
방법: 신뢰도 점수가 높을수록 오브젝트가 바운딩 박스 안에 존재한다고 판단합니다.
변형: 단순한 오브젝트 존재 확률, 오브젝트 존재 확률 x IoU, 오브젝트가 특정 클래스일 확률 x IoU 등 다양한 방식으로 계산될 수 있습니다.
3) IoU(Intersection over Union)
목적: 두 바운딩 박스의 겹치는 영역을 기준으로 예측의 정확도를 측정합니다.
범위: 0부터 1까지의 값으로, 값이 클수록 예측이 정확함을 의미합니다.
4) NMS(Non-Maximum Suppression)
목적: 동일한 오브젝트에 대한 중복된 바운딩 박스를 제거합니다.
과정:
일정 신뢰도 점수 이하의 바운딩 박스 제거
남은 바운딩 박스를 신뢰도 점수 기준으로 정렬
가장 높은 신뢰도를 가진 바운딩 박스와 IoU가 높은 박스 제거
하나의 바운딩 박스만 남을 때까지 반복
5) 정밀도(Precision), 재현율(Recall), AP(Average Precision), mAP(mean Average Precision)
5-1) 정밀도: 모델이 오브젝트라고 예측한 것 중 실제 오브젝트의 비율 (TP / (TP + FP))
5-2) 재현율: 실제 오브젝트 중 모델이 올바르게 탐지한 오브젝트의 비율 (TP / (TP + FN))
5-3) AP: 정밀도와 재현율의 그래프 아래 면적을 측정하여 오브젝트 디텍션 성능을 나타냅니다.
5-4) mAP: 다양한 클래스에 대한 AP의 평균값으로, 모델의 전체적인 성능을 평가합니다.
6) 애노테이션(Annotation)
목적: 이미지 내 오브젝트 디텍션 정보를 특정 포맷으로 제공합니다.
내용: 오브젝트의 바운딩 박스 위치, 오브젝트 이름 등을 포함합니다.
5일차
수동 레이블링을 직접 해보면서, 개념적으로만 이해했던 현업에서의 수동 레이블링 과정에서 발생할 수 있는 결측치의 원인을 직접 경험하게 되었습니다.
레이블링을 시작하기 전에 레이블의 이름을 어떻게 정할지에 대한 논의가 없었기 때문에, 레이블이 추가되거나 서로 다른 이름으로 레이블링이 이루어지는 문제를 뒤늦게 발견하게 되었습니다.
이로 인해 수정에 상당한 시간이 소요되었습니다. 이러한 경험을 통해, 앞으로 여러 사람과 수동 레이블링 작업을 할 때는 레이블명을 정확히 어떻게 지정할지 사전에 논의하는 것이 중요하다는 것을 깨달았습니다.
위는 Yolov8 모델을 돌릴 때의 대화 입니다 ㅋㅋㅋ
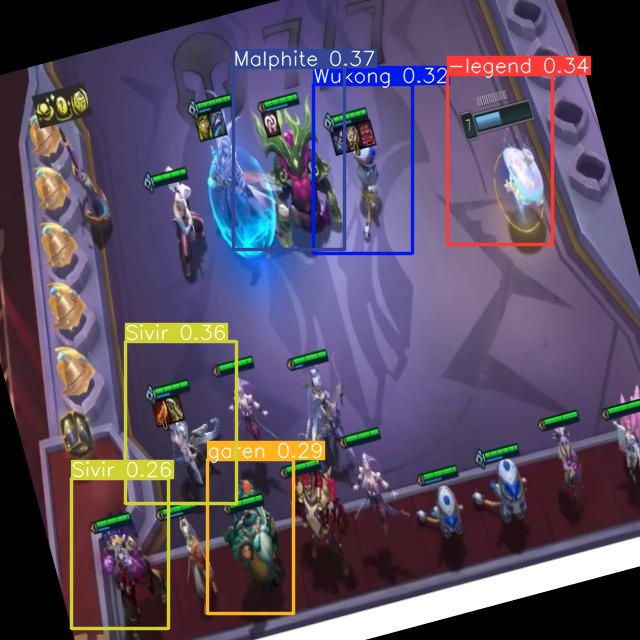

이미지 200장을 수집한 후 데이터 증강(Augmentation)을 통해 이를 600장으로 확장해 모델을 학습시켜 보았지만, 예상보다 낮은 모델의 예측 성능에 실망했습니다. 프로젝트를 마친 후에 되돌아보니, 게임 캐릭터 위에 있는 아이템들이 학습 과정에서 모델에 방해가 되었을 가능성과, 캐릭터의 단계별 변화가 정확한 예측을 어렵게 만들었을 것 같다는 생각이 들었습니다.
만약 다음에 이런 프로젝트를 진행한다면, 챔피언별로 구분하고, 그 단계별로도 구분하여 학습시키면 성능이 더 좋아지지 않을까 하는 생각을 하게 되었습니다.
요즘 주말에는 집에 조용히 있는 일이 드물어져서, 가끔 집에만 있으면 심심함을 느끼게 되더라고요 ㅋㅋㅋ 몸이 바쁜 활동에 익숙해진 것 같아요!
이제 정처기 실기 시험이 얼마 남지 않아서, 다음 주부터는 본격적으로 공부를 시작해야 할 것 같아요
에이블러님들 중에도 정처기 시험을 준비하시는 분들이 계실텐데, 모두 화이팅입니다!
이 글을 쓰는 다음 날부터는 새로운 미니프로젝트가 시작되는데, 흥미로운 주제로 재미있게 진행해보고 싶어요~!
저는 화요일, 목요일, 금요일에 강의장에 가서 프로젝트를 진행할 예정인데,
새로운 조원들과 함께 의견을 나누며 즐거운 시간을 보내길 기대하고 있습니다!
