[cvpr2024]
5 Dec 2023
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T. Freeman, Taesung Park
https://arxiv.org/pdf/2311.18828
intro
iterative한 기존 Diffusion model을 이용하여 knowledge distillation(KD)와 비슷하게 distillation을 통해 one-step model을 학습시킴
multi-step model -> (KD) -> one-step model
step수를 줄인 기존 few-step model들은 quality 저하가 심함
GAN과 비슷하게 fake score, real score모델 2개를 놓고 fake score가 real score와 KL divergence가 최소가 되도록 하는 방식(큰 흐름에서는)
+추가 loss 도있다.

정답은
정말 quality가 높다.. 솔직히 DMD방식이 내눈에는 더 좋아 보인다. (잘 나온 것만 올렸나??)
one-step model로 few-step model보다 성능이 좋은 것은 엄청난 기여같다.
https://tianweiy.github.io/dmd/ 에 더 자세한 그림들이 나와 있다.
Distribution Matchin Distillation(DMD)
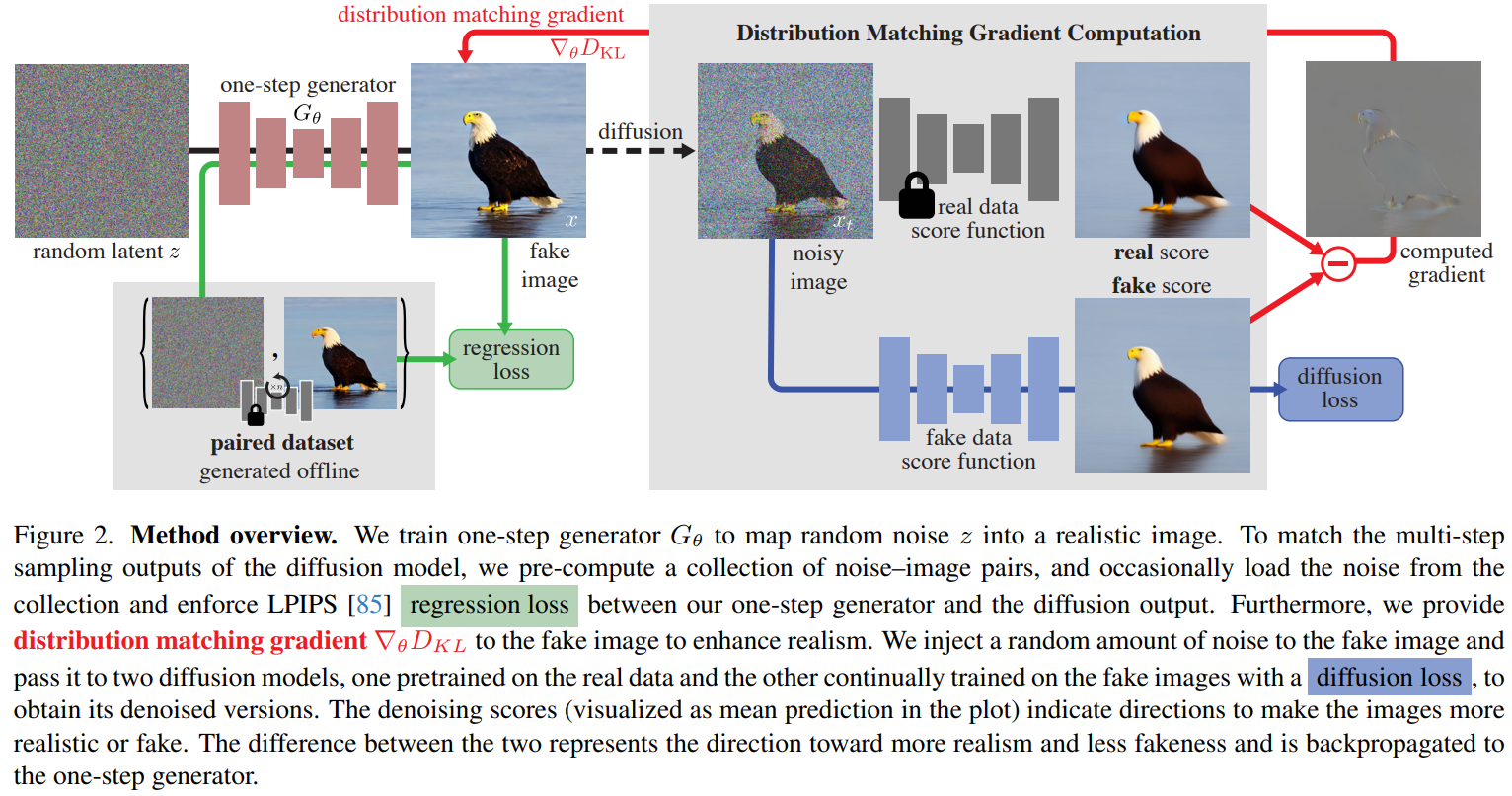
- pre-trained 된 기존방식(1000-step)의 diffusion model(실제 논문에서 teacher model로 stable diffusion과 EDM을 사용) 을 teacher model로 one-step model을 teaching한다.
- GAN처럼 real결과를 teacher model의 sampling 결과로 두고 학습한다.
fake를 one-step model 에서 나온 sample로 둔다.
학습의 목표는 fake와 real을 구분할 수 없게 하는 것!
(학습 데이터로 noise, 해당 noise에서 teacher model이 sampling한 결과를 pair 로 사용)
위의 2가지 내용이 DMD의 기초다.
GAN과 비슷한 real score, fake score
+아래 수식 관련해서 정말 자세히 나와있는 블로그가 있다
https://blog.si-analytics.ai/49 내용을 참조하시면 수식에 대해 자세히 알 수 있다.
위의 그림에서 오른쪽 회색 박스부분 내용이다.
regression loss가 먼저 나와 있지만 더 중요한 것은 회색박스 내용이다.
먼저 real score와 fake score가 있다.
우리가 최종적으로 원하는 것은 fake이미지와 real이미지를 구분 못하게 하는 것
결론적으로는 fake확률이 real확률을 따라가야 된다.(KL divergence를 최소화 하게)
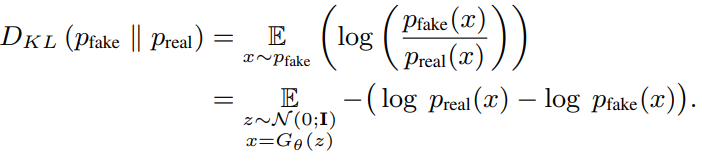
(z = 완전 noise, G = one-step model)
실제 확률 밀도는 intractable하다..
하지만 우리는 학습을 위한 ∇θ만 필요하고 따라서 D의 그래디언트만 알면된다.
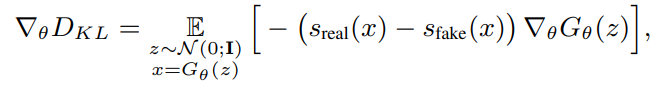
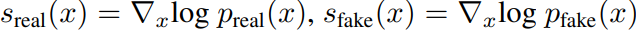
s는 score를 뜻한다. 자세한 score에 대해 이야기하기 전 우선적으로 알아야 될 부분이 있다.
위의 회색박스에 입력으로 one-step model이 만든 image가 들어간다.
하지만 t-step gaussian noise를 곁들인...
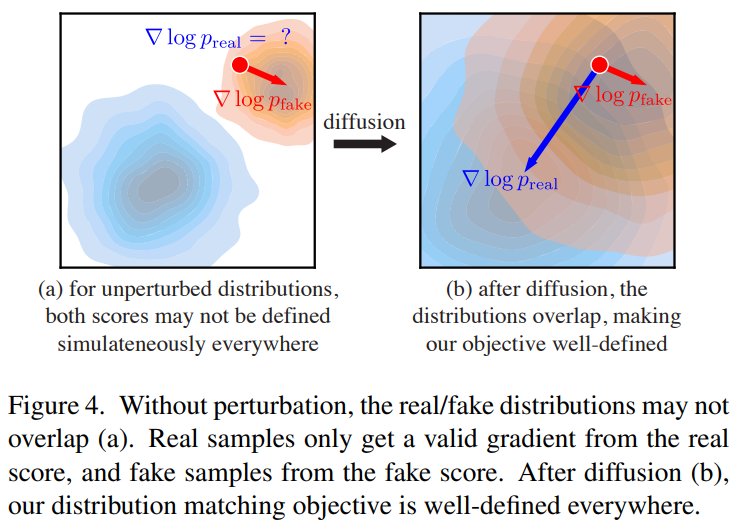
+ 수식적으로 sparse한 영역에서는 score를 estimation하기 어렵고 noise를 기존 data에 섞어 (정의하기 나름이지만) 예로 gaussian분포로 가정하여 score matching을 진행할 수 있다.
왜 이렇게 하는지에 대한 이유는 score-SDE 논문에 자세히 나와있다.
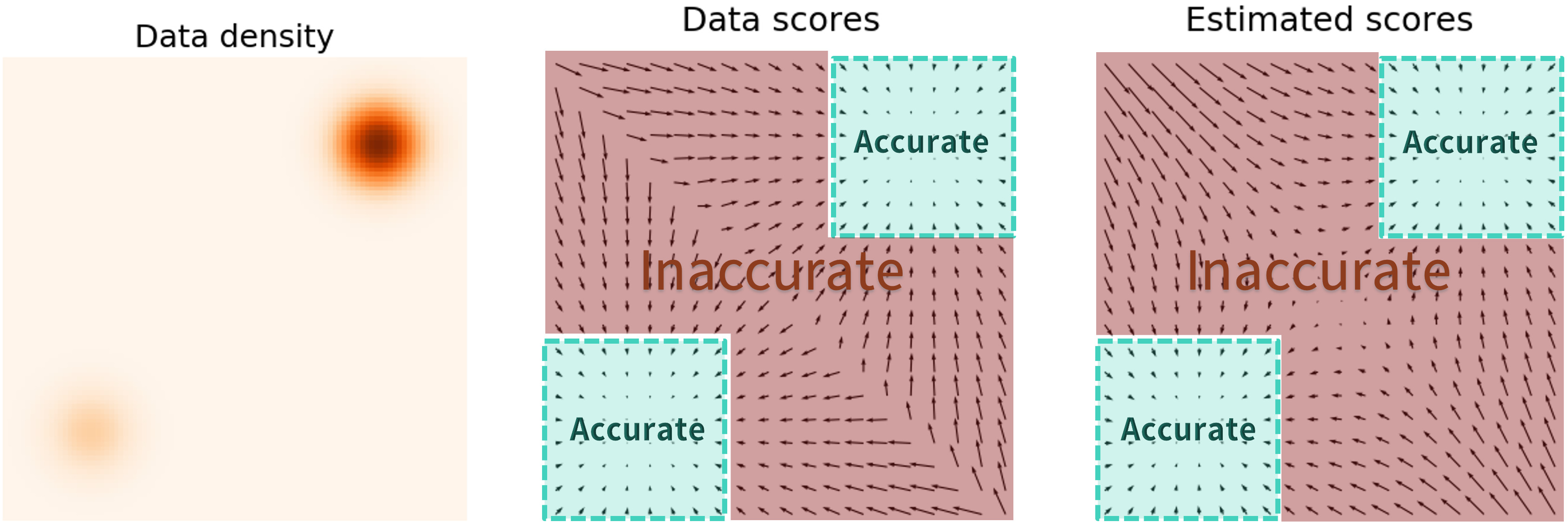
직관적으로 이야기하자면 data가 많은 영역에 대해서는 비교적 accurate한 값을 알 수 있지만 sparse한 data 영역에서는 많이 inaccurate한 score gradient를 얻게되는 것 이다. 하지만 gaussian noise를 sample에 섞게되면

와 같이 data distribution이 부정확해지는 대신에 sparse한 영역에 대해서도 gradient를 발산하지 않게 구할 수 있는,(trade off를 통해) score를 추정할 수 있다.
(마치 입실론-greedy와 같다)
어느정도 noise를 섞어야 될지에 대해서는 score-SDE논문에 나와있다.
score-matching과 noise관련 논문은 엄청 과거부터 있었다
위와 같은 이유로 one-step model에서 구한 sample image에 noise를 섞어 score를 구한다.
noise를 주입하는 과정은 diffusion forward process와 동일하다.
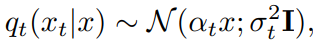
(z = 완전 noise, G = one-step model, x = one-step model에서 나온 sample)
t-step noising 한 것이다.
다시 score를 구하는 것으로 돌아오면
noise 된 image를 2개의 diffusion model을 통해서 real score와 fake score를 구한다.
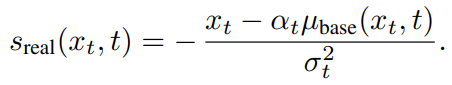
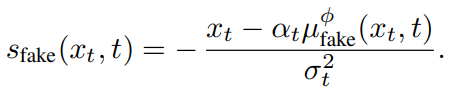
이 score에 대해서도 score-SDE에 나와있다.(나중에 이 논문도 리뷰해야겠다.)
+ 찾아봐도 잘 안나온다.. 기회가 되면 관련해서 추가 하겠습니다.
다음과 같은 식을 통해 gradient를 추정하였다. 식을 보면 model을 통과하여 한단계 denoising된 결과가 많이 차이가 나게되면 그 것은 아직 model과 멀다는 의미이고 값이 커지게되어 score가 낮아지게된다.
둘다 initialize상태로는 teacher model인 
로 시작한다. (앞으로는 base model이라 하자)
fake에는 ϕ이 붙어 있다 real score과 다르게 fake score는 train동안 학습된다.
(real score은 독수리 그림에서 자물쇠표시로 학습되지 않는 model임을 나타냄)
fake score은 에초에 이 데이터가 fake인지 학습하기 위해 존재한다. 따라서 fake score는 ideal하게 one-step model과 같은 결과를 내는 multi-step model로 학습이 되게 된다.
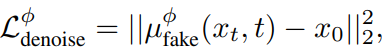
base model과 동일한 loss를 통해서 말이다.(최종 denoising된 sample과의 L2 loss)
gradient detail
실험에서 채택한 실제 gradient는 위에 적은 값과 조금 다르다.
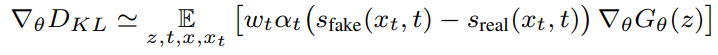
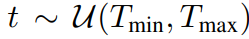
Tmin = 0.02T, Tmax = 0.98T로 실험을 하였다.(Tmax값이 엄청 크네..)
wt항이 붙었다.
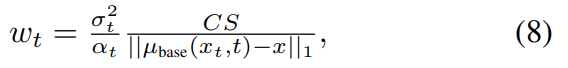
(x는 one-step model에서 뽑고 noising을 안한 원본 sample이다.)
직관적으로 wt(weight)에 대해서 이해하자면
x에 노이즈를 많이 섞는 경우에 score값은 trade-off에 의해 부정확해진다. 따라서 noising step의 크기가 큰 경우(식에서 small t가 큰 경우)
gradient의 크기를 줄여주는 역할을 한다.
분모의 식을 봤을때 x에 noise가 많이 끼게 되면 base model의 예측과 x의 차이가 커지게 됨으로 분모의 값이 커져 wt의 값이 작아진다.
ablation실험 결과에 wt의 영향이 나타나 있다.
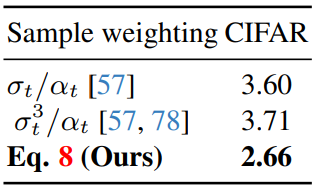
(Eq8이 바로 위에 식이다)
regression loss

그림과 같이 score들만 가지고는 모든 mode를 커버할 수 없다고 논문에서 이야기하고 있다. 따라서 더 많은 mode를 커버하기 위해 regression loss를 추가 하였다.
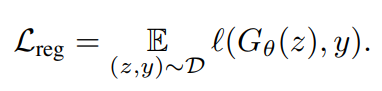
소문자 l은 LPIPS를 사용하여 두 image간의 유사도 function을 뜻한다.
그리고 data set은 초반에 이야기한 {noise, base model을 통한 sample} pair 이고 당연히 똑같은 noise에 대한 sample들 가지고 비교한다.
알고리즘

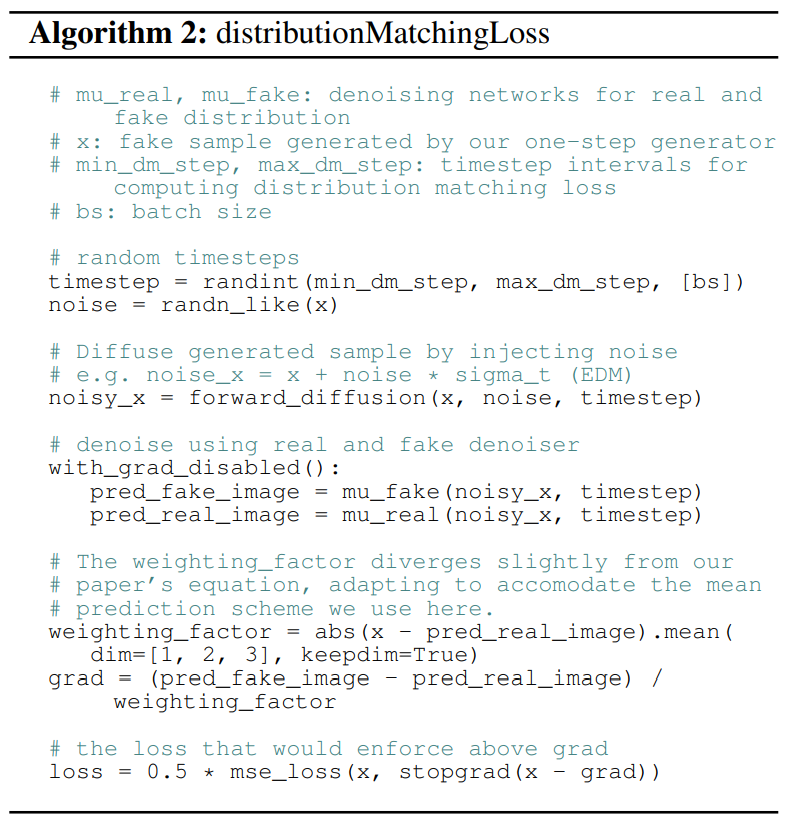

코드가 없어서 열심히 알고리즘만 읽었다....
뉴비는 어디가서 공부하나..........
Experiments와 detail은 추후에 시간이 되면 다시 작성하겠다.
나의 생각
같은 양의 파라미터의 모델사용했는데 왜 step size만큼 속도 향상이 안됐을까?
같은 양의 파라미터를 가지고 거의 좋은 성능을 내는 것이 신기하다. 기존 diffusion이 많이 비효율 적이였나?
fake score model을 fake image를 잘 predict하도록 학습하는 과정이 조금 비효율적으로 느껴진다
