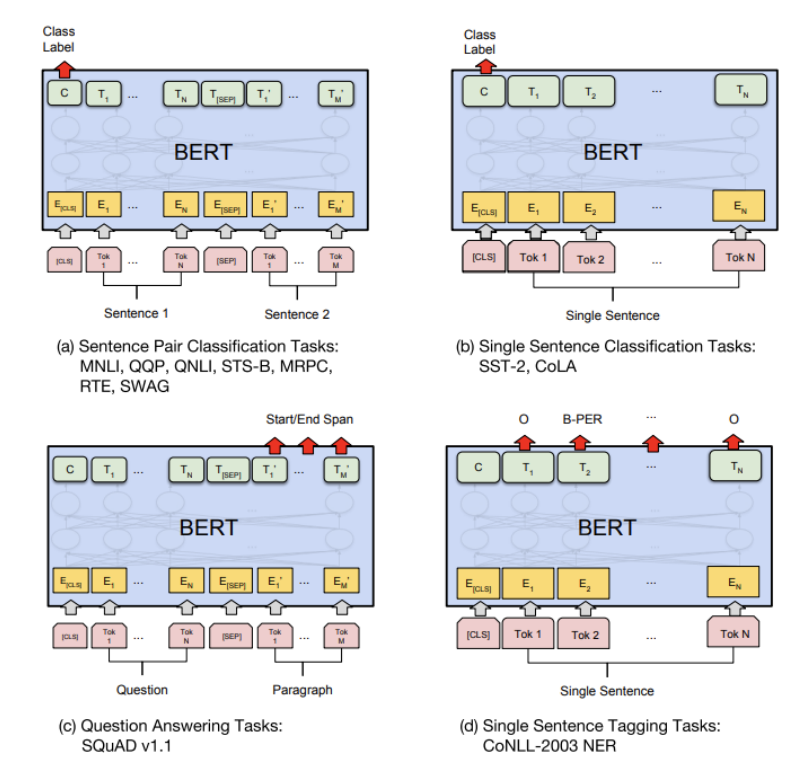
BERT
본 글은 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [arXiv-2018] 논문에 대한 저의 개인적인 이해를 정리한 글입니다. 실제 논문의 구성 및 내용과 약간의 차이가 있을 수 있습니다.
미리보기
- BERT는 pre-training + fine-tuning 방식을 사용하는 LM
- Bidirectional Transformer를 이용하여 양방향에서 문맥 파악
1) Introduction
Language model을 pretrain하는 방식을 통해 다음의 NLP task를 해결할 수 있음
- Sentence level task: 문장 사이의 관계 파악
- Token level task: 토큰 수준에서의 output 예측 또는 생성
Downstream task를 해결하는 방식
- Feature based approach: Pre-trained representation을 하나의 feature로 추출하여 새로운 모델 학습에 이용하는 방식 (ex: ELMO)
- Fine-tuning approach: Pre-trained 모델의 파라미터를 조정하여 downstream task을 수행하는 방식 (ex: BERT, GPT)
BERT 등장
- 기존 방식 (ELMO, GPT)는 모두 unidirectional하며 이는 모델이 문장 전체를 보지 못한다는 점에서 문맥을 파악하는데 한계가 있음 (예를 들어 GPT에서는 모든 토큰이 이전에 생성된 토큰과의 attention만 계산함)
- BERT는 문장 전체를 보는 것을 통해 bidirectional context를 얻으려고 하며 이를 위해 Masked Language Model (MLM)을 이용함
- MLM objective외에도 Next Sentence Prediction (NSP) task를 이용하여 text-pair representations도 학습함
Contributions
- Bidirectional Pre-training의 중요성 입증
- Pre-trained representations를 이용해 task-specific한 아키텍처를 많이 만드는 것을 방지
- 11개의 NLP task에서 우수한 성능을 보임
2) Related Work
Pre-training의 목표
- 모델이 task를 잘 풀 수 있도록 학습하는 과정에서 labeled data는 구하기 어려움
- 그래서 비교적 구하기 쉬운 unlabed data를 이용하여 모델을 pre-training하고자 함
- Unlabed data를 바탕으로 모델이 언어 자체의 semantic이나 knowledge를 이해하도록 훈련
- 훈련된 모델을 이용하여 downstream task를 수행하도록 함
2-1) Unsupervised Feature-based Approach
단어의 representation을 학습하는 접근법으로, 단어 임베딩 벡터를 pre-train하기 위해 left-to-right language modeling objective와 좌우 맥락에서 잘못된 단어를 구분하는 objective가 사용됨.
예를 들어 ELMO는 left-to-right와 right-to-left로부터 context feature를 추출하여 단어 임베딩을 생성하며 QA, 감정분석, NER을 포함한 몇 가지 NLP에서 성과를 냄
2-2) Unsupervised Fine-tuning Approach
Unlabeled data로부터 pre-trained 된 단어 임베딩 파라미터만 사용하며 이후에 fine-tuning하는 방법을 이용함
예를 들어 Open AI의 GPT는 GLUE 벤치마크의 다양한 task에서 성능을 높였으며, 이 방식의 경우 학습이 완료될 때까지 적은 수의 파라미터만을 학습하면 됨.
2-3) Transfer Learning from Supervised Data
자연어 추론이나 기계번역 외에도 대규모 데이터셋을 사용한 supervised learning으로부터 변하는 것을 보여주는 연구도 있음.
예를 들어 computer vision 연구에서도 ImageNet을 활용해 pre-train 한 모델로부터 fine-tuning하는 방식을 사용
3) BERT
BERT란? pre-training 방식을 이용한 language representation model
BERT의 프레임워크 구성: pre-training + fine-tuning
- Pre-training: Unlabeled data를 이용하여 MLM 또는 NSP objective를 수행하면서 모델 학습
- Fine-tuning: Labeled data를 이용하여 downstream task를 수행하도록 모델 학습
BERT의 아키텍처
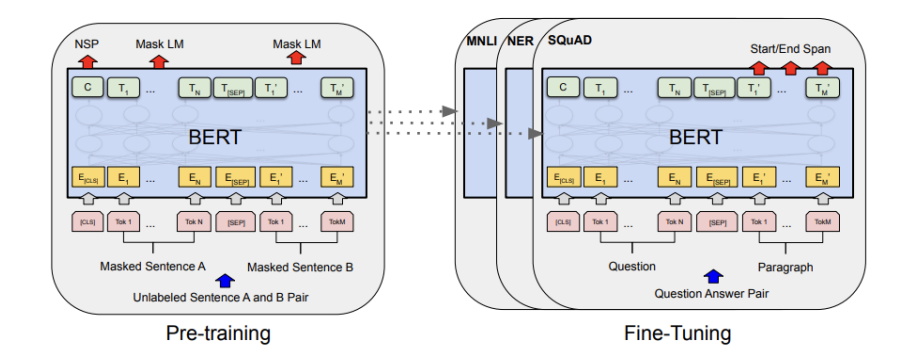
BERT의 input
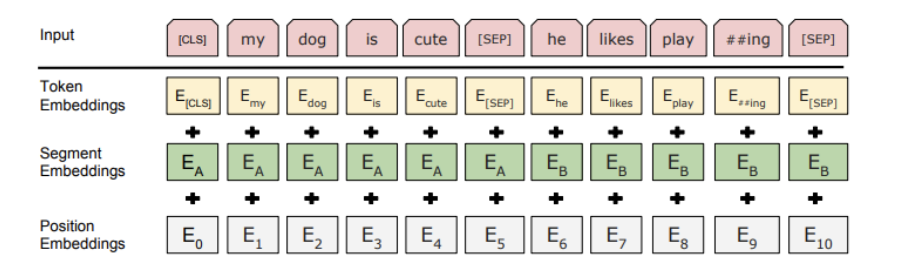
3-1) Pre-training
Masked Language Modeling (MLM)
- 단어가 가지는 context 파악이 목표이며, BERT에서는 양방향 모델을 이용하기 때문에 문장 전체를 볼 수 있다는 장점이 있음.
일반적으로 양방향 모델은 "See itself" 문제가 있음. 이는 모델이 특정 단어의 context를 파악하기 위해 해당 단어를 포함한 모든 단어를 보기 때문에 발생함. - BERT에서는 해당 문제를 해결하기 위해, pre-training 시 특정 단어의 context를 파악할 때, 자기 자신을 보지 못하도록 mask를 씌우는 MLM 방식을 이용함.
- Pre-training 시 MLM 방식으로 모델을 훈련하는 것은 효과적이나 실제 downstream task를 풀 때의 입력에는 mask 토큰이 없음. 즉, pre-training과 fine-tuning 시 입력문 사이의 mismatch가 있음.
- 이를 해결하기 위해서 mask를 씌울 단어들에 대해 일부만 masking을 수행 (80% mask 토큰 + 10% 랜덤 토큰 + 10% 기존 토큰)
Next Sentence Prediction (NSP)
- 두 문장 사이의 관계 파악이 목표이며, 이는 단순히 language modeling만으로 해결할 수 없음.
- Corpus에서 생성될 수 있는 다음 문장 예측을 binarize 하기 위해 pre-training을 실시함. 학습 corpus에서 문장 A와 B를 선택 (50% 확률로 B가 A의 다음 문장 + 50% 확률로 A와 B가 무관한 문장) 후 훈련
3-2) Fine-tuning
Transformer의 selft-attention mechanism을 이용했기 때문에 다양한 downstream task를 해결할 수 있음