
목표
- 특정 사이트, 특정 글 스크랩
- 스크랩한 자료 DB에 저장
- 매주 추가되는 당첨번호 자동으로 스크랩하기
1. 특정 사이트, 특정 글 스크랩
1) 웹페이지 소스확인

2) Code
import requests #파이썬 웹 데이터 처리 모듈 import
from bs4 import BeautifulSoup #BeautifulSoup 모듈을 사용하여 가독성 향상
def lotto(page, max_pages): #크롤링 할 회차 parameter로 함수 정의
while page < max_pages: #원하는 회차까지 크롤링 할 수 있도록 while 반복문 사용
#회차별 url이 No= 뒤에 숫자가 바뀌기 때문에 int를 str로 변환해 입력
url = 'https://dhlottery.co.kr/gameResult.do?method=byWin&drwNo=' + str(page)
req = requests.get(url) #url의 데이터 불러오기
html = req.text #text 부분만 html 변수에 저장
bsObject = BeautifulSoup(html, 'html.parser') #(target, 'parser')
lotto_num = list() #회차별 구분을 위해 for문 전에 리스트 생성
#select 사용하여 지정한 범위 긁어오기
for numbers in bsOject.select('div>div>div>div>p>span'):
number = int(numbers.string) #str의 숫자를 int형으로 변환
lotto_num.append(number) #for문 전에 만든 리스트에 추가
print(lotto_num) #확인용 print
page += 1 #while 반복문이 무한반복문이 되지 않도록 특정 페이지까지 범위 지정
lotto(1, 5)
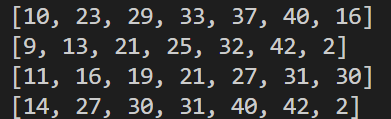
1회부터 4회까지의 당첨번호와 보너스 번호가 출력됨.
참고
- select vs. find
select는 find에 비해 직관적인 형태의 태그 작성 가능하다.

Back-end, Python, Data