ElasticSearch를 통해 실시간 데이터를 받아올 일이 생겨 검색 api를 알아보았다.
현재 사용하는 웹 서버는 node를 사용하고 있어
npm install elasticsearch 으로 npm 모듈을 사용하여 검색을 할 수도 있으나, 직접 url query를 날라기로 하였다.
ElasticSearch에서 제공하는 검색 api를 알아보자.
먼저 es의 현재 버전을 알아보기위해
http://x.x.x.x:9020/ url 요청을 해보면
{
"name" : "es-node-main-master",
"cluster_name" : "bd1-es-cluster-1",
"cluster_uuid" : "gtAG1_WwQwG120G0XYQuZw",
"version" : {
"number" : "7.10.2",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "747e1cc71def077253878a59143c1f785afa92b9",
"build_date" : "2021-01-13T00:42:12.435326Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}검색시 url 방식, query DSL 방식이 있다.
-
URL 검색은 HTTP GET 요청을 활용하는 방식, 파라미터를 'key=value' 형태로 전달.
단, 파라미터로 표현하는 한계가 있어 복잡한 질의를 작성하는 것이 불가.
* ex. http://x.x.x.x:9020/system/_search?q=date:[20220615150224%20TO%2020220620150324]&pretty
date라는 필드를 특정 range를 주어 가져오는 url. -
QUERY DSL
** REQEST 구조
{
"size": -- 1) return 받는 결과의 갯수
"from": -- 2) 몇 번째 문서부터 가져올지 지정. 기본값은 0
"timeout": -- 3) 검색을 요청해서 결과를 받는 데까지 걸리는 시간. 기본값은 무한대
"_source": {} -- 4) 검색시 필요한 필드만 출력하고 싶을 때 사용
"query": {} -- 5) 검색 조건문이 들어가야 하는 공간
"aggs": {} -- 6) 통계 및 집계 데이터를 사용할 때 사용하는 공간
"sort": {} -- 7) 문서 결과를 어떻게 출력할지에 대한 조건을 사용하는 공간
}** RESPONSE 구조
{
"took": -- 1) 쿼리를 실행한 시간
"timed_out": -- 2) 쿼리 시간이 초과할 경우
"_shards": {
"total": -- 3) 쿼리를 요청한 전체 샤드의 갯수
"successful": -- 4) 검색 요청에 성공적으로 응답한 샤드의 갯수
"failed": -- 5) 검색 요청에 실패한 샤드의 갯수
},
"hits": {
"total": -- 6) 검색어에 매칭된 문서의 전체 갯수
"max_score": -- 7) 일치하는 문서의 스코어 값 중 가장 높은 값
"hits": [] -- 8) 각 문서 정보의 스코어 값
}
}** 예제
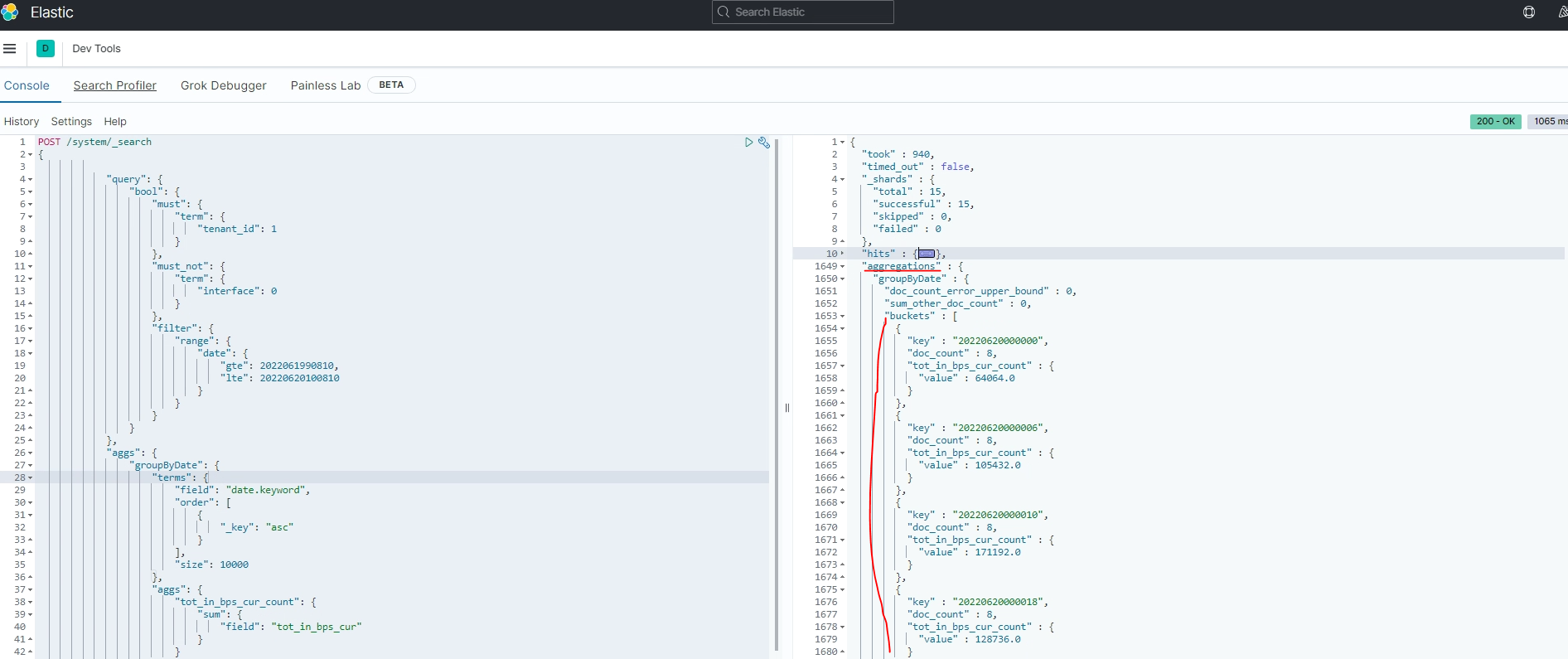
const response = await axios({
url: 'http://x.x.x.x:9020/system/_search',
method: 'POST',
timeout: 3000,
headers: {
'Content-Type': 'application/json'
},
data: {
// "size": 0,
// "_source":["tot_in_bps_cur","date","tenant_id"]
"query": {
"bool": {
"must": {
"term": {
"tenant_id": 1
}
},
"must_not": {
"term": {
"interface": 0
}
},
"filter": {
"range": {
"date": {
"gte": 20220620090810,
"lte": 20220620100810
}
}
}
}
},
"aggs": {
"groupByDate": {
"terms": {
"field": "date.keyword",
"order": [
{
"_key": "asc"
}
],
"size": 10000
},
"aggs": {
"tot_in_bps_cur_count": {
"sum": {
"field": "tot_in_bps_cur"
}
}
}
}
}
}
});위 코드는 es에 system으로 인덱싱된 곳에서 데이터를 질의하는 query 이다.
간단히 설명하면
1. tenant_id === 1 이고 interface !== 0 이며 date가 20220620090810 ~ 20220620100810 사이인 값을 질의한다.
2. 1의 질의 결과를 aggregation 하는 query는 aggs에서 볼 수 있다.
groupByDate라는 명칭으로 date 기준으로 group by 후, tot_in_bps_cur_count라는 명칭으로
tot_in_bps_cur 값을 sum 하는 부분이다.
( 날짜별로 tot_in_bps_cur의 값을 합친다.)
- 추가로 이러한 검색을 kibana를 통해서 쉽게 접근해서 볼 수 있다.
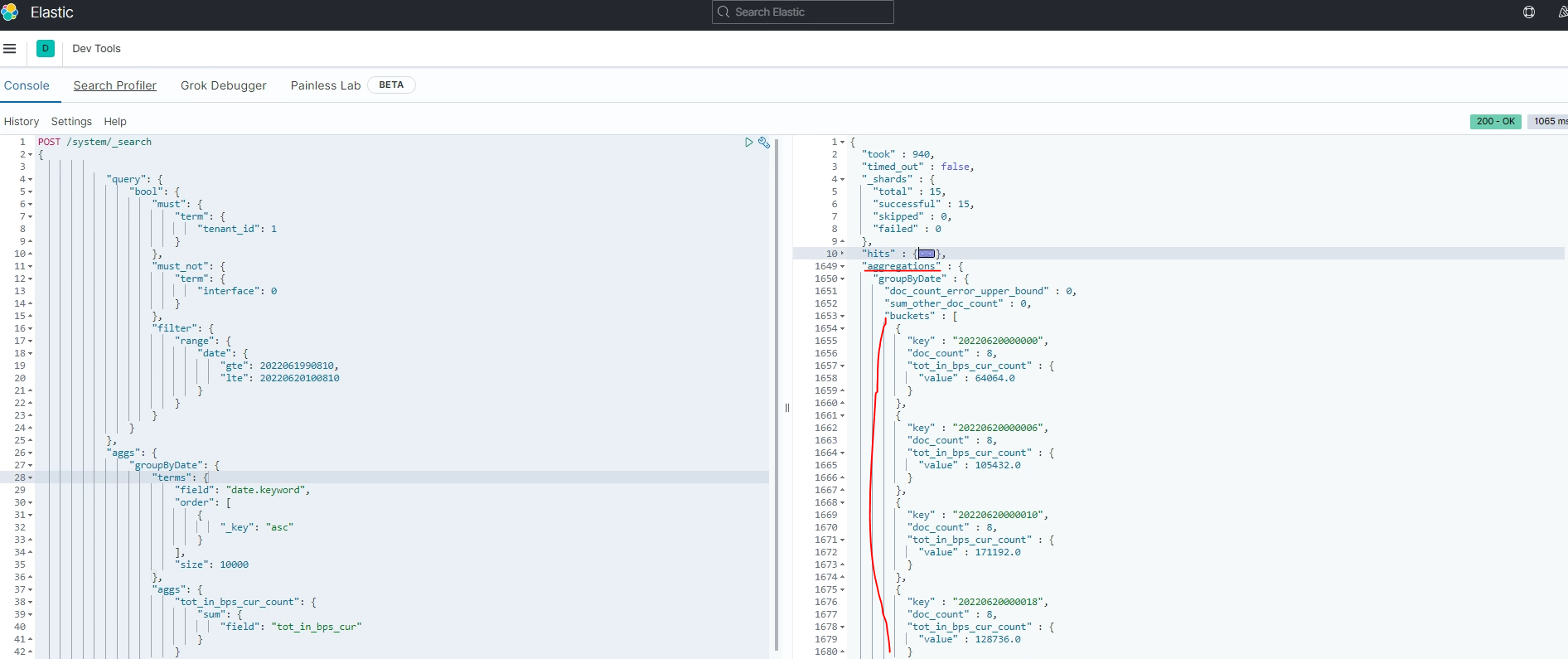
위에 예제 query에 대한 응답값
*