인덱스(index)
- 검색 성능을 높여주는 기술
- 인덱스를 생성하면 더 빠른 검색이 가능한 별도 데이터 구조가 만들어짐
-- 인덱스 이름은 보통 'idx_색인하려는 컬럼'으로 지음
CREATE INDEX idx_director ON movies (director)테이블 스캔(table scan)
- DB에서 데이터를 찾기 위해 테이블 전체에서 한 행씩 찾아보는 것
- 테이블 커질수록 비용이 커짐
인덱스가 빠른 이유
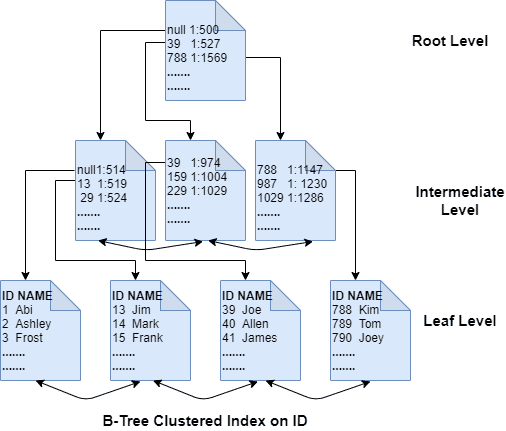 이미지 참고:
이미지 참고:
- 인덱스가 스캔보다 빠른 이유를 알려면 인덱스가 저장되는 데이터 구조를 알아야 함
- 인덱스를 생성하면 B+Tree라는 데이터 구조가 생성됨
- B+Tree는 root node, internal node, leaf node로 구성됨
- 최종적으로 leaf node를 검색함
- 작동 방식: 내가 찾고 있는 값이 로트 노드에서부터 큰지 작은지 비교해서 왼쪽 또는 오른쪽으로 이동 (이진검색)
- 한번 이동할 때마다 절반의 데이터를 확인하지 않아도 되기 때문에 빠르게 검색이 가능
👉 B+Tree는 인덱스로 설정한 컬럼 데이터를 리프 노드에 저장하는데, 이때 컬럼 데이터뿐만 아니라 PK로 선정한 데이터까지 함께 리프 노드에 담김. PK를 이용해서 원래 테이블에서 다른 정보까지 빠르게 가져올 수 있음
인덱스 단점
- 공간비용 측면: 인덱스를 사용하면 디스크에 별도로 저장해야 함
- 운영비용 측면: 인덱스는 기존 테이블과 동기화를 유지해야 하기 때문에 기존 테이블 데이터의 추가, 수정, 삭제 시 느리게 만들기도 함 (변경이 잦은 컬럼은 인덱스 설정하지 않은 게 좋음)
인덱스 vs 스캔
인덱스를 사용했을 때와 사용하지 안 았을 때 query plan 비교
EXPLAIN QUERY PLAN -- sqlite에서 query plan을 확인하는 명령어
WITH director_stats AS (
SELECT
director,
COUNT(title) AS total_movies,
AVG(rating) AS avg_rating,
MAX(rating) AS best_rating,
MIN(rating) AS worst_rating,
MAX(budget) AS highest_budget,
MIN(budget) AS lowest_budget
FROM
movies
WHERE 1=1
AND director IS NOT NULL
AND rating IS NOT NULL
AND budget IS NOT NULL
GROUP BY
director
)
SELECT
director,
total_movies,
avg_rating,
best_rating,
worst_rating,
highest_budget,
lowest_budget,
(
SELECT
title
FROM
movies
WHERE 1=1
AND rating IS NOT NULL
AND budget IS NOT NULL
AND director = ds.director
ORDER BY
rating DESC
LIMIT 1
) AS best_rated_movie,
(
SELECT
title
FROM
movies
WHERE 1=1
AND rating IS NOT NULL
AND budget IS NOT NULL
AND director = ds.director
ORDER BY
rating ASC
LIMIT 1
) AS worst_rated_movie,
(
SELECT
title
FROM
movies
WHERE 1=1
AND rating IS NOT NULL
AND budget IS NOT NULL
AND director = ds.director
ORDER BY
budget DESC
LIMIT 1
) AS most_expensive_movie,
(
SELECT
title
FROM
movies
WHERE 1=1
AND rating IS NOT NULL
AND budget IS NOT NULL
AND director = ds.director
ORDER BY
budget ASC
LIMIT 1
) AS lowest_expensive_movie
FROM
director_stats AS ds;
1) 인덱스가 없을 때 쿼리 플랜
| id | parent | notused | detail |
|---|---|---|---|
| 2 | 0 | 0 | CO-ROUTINE director_stats |
| 9 | 2 | 0 | SCAN movies |
| 18 | 2 | 0 | USE TEMP B-TREE FOR GROUP BY |
| 80 | 0 | 0 | SCAN ds |
| 91 | 0 | 0 | CORRELATED SCALAR SUBQUERY 2 |
| 101 | 91 | 0 | SCAN movies |
| 123 | 91 | 0 | USE TEMP B-TREE FOR GROUP BY |
| 130 | 0 | 0 | CORRELATED SCALAR SUBQUERY 3 |
| 140 | 130 | 0 | SCAN movies |
| 162 | 130 | 0 | USE TEMP B-TREE FOR GROUP BY |
| 169 | 0 | 0 | CORRELATED SCALAR SUBQUERY 4 |
| 179 | 169 | 0 | SCAN movies |
| 200 | 169 | 0 | USE TEMP B-TREE FOR GROUP BY |
| 207 | 0 | 0 | CORRELATED SCALAR SUBQUERY 5 |
| 217 | 207 | 0 | SCAN movies |
| 238 | 207 | 0 | USE TEMP B-TREE FOR GROUP BY |
👉 movies 테이블을 총 5번이나 스캔함
2) 인덱스를 사용할 때 쿼리 플랜
| id | parent | notused | detail |
|---|---|---|---|
| 2 | 0 | 0 | CO-ROUTINE director_stats |
| 10 | 2 | 0 | SEARCH movies USING INDEX idx_director (director>?) |
| 70 | 0 | 0 | SCAN ds |
| 81 | 0 | 0 | CORRELATED SCALAR SUBQUERY 2 |
| 92 | 81 | 0 | SEARCH movies USING INDEX idx_director (director=?) |
| 115 | 81 | 0 | USE TEMP B-TREE FOR ORDER BY |
| 122 | 0 | 0 | CORRELATED SCALAR SUBQUERY 3 |
| 133 | 122 | 0 | SEARCH movies USING INDEX idx_director (director=?) |
| 156 | 122 | 0 | USE TEMP B-TREE FOR ORDER BY |
| 163 | 0 | 0 | CORRELATED SCALAR SUBQUERY 4 |
| 174 | 163 | 0 | SEARCH movies USING INDEX idx_director (director=?) |
| 196 | 163 | 0 | USE TEMP B-TREE FOR ORDER BY |
| 203 | 0 | 0 | CORRELATED SCALAR SUBQUERY 5 |
| 214 | 203 | 0 | SEARCH movies USING INDEX idx_director (director=?) |
| 236 | 203 | 0 | USE TEMP B-TREE FOR ORDER BY |
👉 director 컬럼을 인덱스로 사용하여 검색. 테이블 전체 스캔 x
멀티 컬럼 인덱스 (Multi column index)
- WHER절에서 여러 조건이 있는 쿼리를 더 빠르게 수행하게 해줌
- 자주 사용하고 최적화하고 싶은 쿼리에 대해 index를 만들어야 함
- 조건문에서 자주 사용하는 컬럼을 인덱스 앞에 배치하는 게 좋음 ('=' 연산 사용하는 조건)
- 범위 검색 할 컬럼이 있을 경우 그 이전 인덱스까지만 사용
CREATE INDEX idx_release_rating ON movies (rating, release_date, revenue);
EXPLAIN QUERY PLAN
SELECT
title
FROM
movies
WHERE 1=1 -- 인덱스 사용 여부는 where절 위치와 상관없고, index 순서가 중요
AND revenue = 100
AND rating = 8
AND release_date > 2020;| id | parent | notused | detail |
|---|---|---|---|
| 4 | 0 | 0 | SEARCH movies USING INDEX idx_release_rating (rating=? AND release_date>?) |
커버링 인덱스 (Covering index)
- 쿼리를 수행하는데 필요한 모든 데이터를 갖고 있는 인덱스
- 멀티 컬럼 인덱스와 같이 활용하면 좋음
- 항상 커버링 인덱스를 사용하는 건 지양 -> 인덱스가 지나치게 방대해지면 성능 저하
-- B+Tree 구조 leaf node에 pk, rating, title를 가지고 있어서 메인 테이블로 점프해서 title을 가져올 필요 없음
-- rating만 인덱스를 설정했을 때보다 속도가 조금 더 빨라짐
CREATE INDEX idx_rating_title ON movies (rating, title);
SELECT
title
FROM
movies
WHERE 1=1
AND rating > 7;인덱스를 사용해야 하는 경우
- WHERE, ORDER BY, JOIN 연산 시 자주 사용하는 컬럼을 index로 설정
- 고유한 값을 가진 컬럼이 있을 때 index 후보로 사용하기 좋음
- 테이블이 클 경우 (작은 경우 큰 성능을 보이지 않음) -> 적어도 수백만 개 데이터 이상
- 외래키 또한 index로 사용하기 좋음
- 모든 단일 컬럼마다 인덱스를 만들면 안됨 (인덱스를 사용하면 비용이 따름)
- 모든 작업을 수행하고 나서 인덱스를 추가해야 함 (수행이 오래 걸리는 쿼리를 발견할 시)
- 조건에 등치, 비교 연산자가 있을 경우 멀티 컬럼 인덱스를 적절히 잘 사용하면 좋음
- 복잡한 인덱스를 만들 필요가 없다면 covering index도 유용할 수 있음
- 자주 변경되는 컬럼은 index x (컬럼이 변결될 때마다 index도 업데이트 해줘야 함)
- 큰 길이의 텍스트 컬럼이 있다면 b tree 구조 대신 full text index를 사용해야 함

배움의 흔적이 성장으로 이어지는 공간