
📝 버블 정렬(Bubble Sort)
- 서로 인접한 두 원소를 검사하여 정렬하는 알고리즘이다.
- 인접한 2개의 원소를 비교하여 조건대로 되어 있지 않으면 자리를 바꾸어준다.
📝 개념(오름차순)
- 버블 정렬의 1회전에서는 첫번째 원소와 두번째 원소, 두번째 원소와 세번째 원소, ... , 마지막 - 1번째 원소와 마지막 원소를 비교하여 앞의 원소가 뒤의 원소보다 클 경우 둘을 서로 교환하면서 자료를 정렬한다.
- 1회전 수행 후에는 가장 큰 원소가 맨 뒤로 이동한 상태이다.
- 2회전 수행 시 맨 끝의 원소를 제외하고 정렬을 수행한다. 2회전 수행 후에는 가장 큰 원소는 맨 뒤에 위치해 있고, 두번째로 큰 원소가 마지막 -1번째에 위치해 있다.
- 3회전 수행 시 맨 끝과 그 바로 앞의 원소를 제외하고 정렬을 수행한다.
- 위와 같이 1회전 수행 시마다 데이터를 하나씩 정렬에서 제외한다.
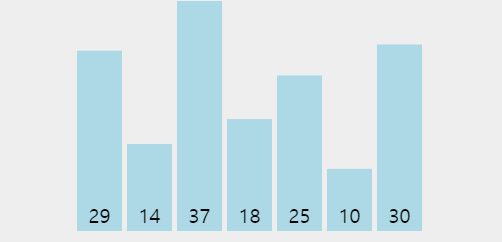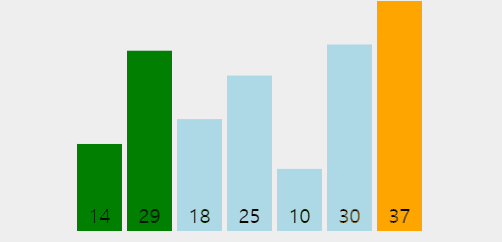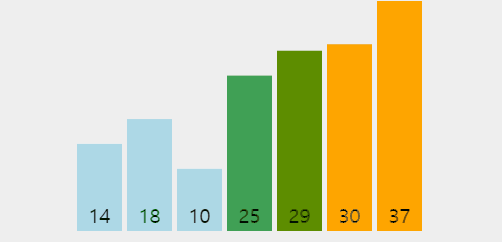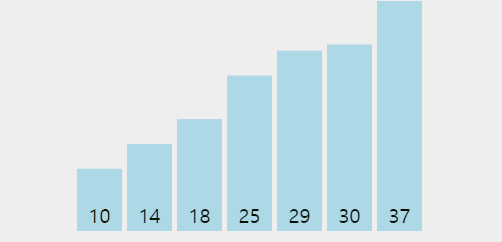
👆 위 짤에서 1회전 시 37이 맨 뒤로 가고 2회전부터는 37을 제외하고 정렬함을 볼 수 있다.
💾 Java코드
private static void sort(int[] arr) {
for (int i = 0; i < arr.length; i++) { 1️⃣
for (int j = 0; j < arr.length - i - 1; j++) { 2️⃣
if (arr[j] > arr[j + 1]) { 3️⃣
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}- ①
for문은 제외될 원소의 갯수를 의미한다. 1회전 시에는 제외할 원소의 갯수가 0개이므로 i가 0부터 시작한다. 한 번 회전 할 때마다 제외시키는 원소의 갯수가 하나씩 늘어나므로 i를 1씩 증가시킨다. - ②의
for문은 원소를 비교하는 반복문이다. j는 현재 위치한 원소를 의미하며, j+1은 그 다음 원소이고 둘을 비교해야 하므로 j를arr.length-i-1까지 1씩 증가시킨다. 그래야arr.length-i까지 비교가 가능하다.arr.length-i까지 비교하는 이유는 ①에서 제외시키는 원소를 제외하고 비교해야하기 때문이다. - ③의
if문은 두 원소를 비교하는 부분이다. 만약 j번째 원소가 j+1보다 크다면 오름차순 정렬을 해야 하므로 두 원소의 위치를 바꾸어 줘야 한다.
📝 특징
-
장점
- 구현이 간단하고 코드가 직관적이다.
- 이미 정렬된 데이터를 정렬할 때, 가장 빠르다.
- 배열 안에서 정렬하는 방식이므로, 다른 메모리 공간을 필요로 하지 않는다.
-
단점
- 시간복잡도가 최악, 최선, 평균 모두 O(n^2) 으로, 굉장히 비효율적입니다.
- 정렬 돼있지 않은 원소가 정렬 됐을때의 자리로 가기 위해서, 교환 연산(swap)이 많이 일어나게 됩니다.
📝 시간 복잡도
(n-1)+(n-2)+(n-3)+ ... +2+1 = n(n-1)/2이므로, O(N^2) 이다. 또한 버블 정렬은 정렬 여부에 상관없이 2개의 원소를 비교하기 때문에 최선, 평균, 최악 모든 경우의 시간복잡도가 O(N^2) 이다.
📝 공간 복잡도
주어진 배열 안에서 교환을 통해 정렬이 수행되므로 O(N)이다.

이것저것 공부중