
📝 선택 정렬(Selection Sort)
- 새로운 원소를 정렬된 원소 사이에 올바른 자리를 찾아 삽입한다.
- 모든 원소를 차례대로 이미 정렬된 부분과 비교하여 자신의 위치를 찾아 삽입한다.
- 2번째 원소부터 시작하여 그 앞(왼쪽)의 원소들과 비교하여 삽입할 위치를 지정한 후, 원소를 뒤로 옮기고 지정된 자리에 자료를 삽입하여 정렬하는 알고리즘이다.
📝 개념(오름차순)
- 두 번째 자료는 첫 번째 자료, 세 번째 자료는 두 번째와 첫 번째 자료, 네 번째 자료는 세 번째, 두 번째, 첫 번째 자료와 비교한 후 자료가 삽입될 위치를 찾는다. 자료가 삽입될 위치를 찾았다면 그 위치에 자료를 삽입하기 위해 자료를 한 칸씩 뒤로 이동시킨다.
- 1회전 시 두 번째 위치의 값을 저장한다. 그리고 저장된 값과 두 번째 위치 이전의 값들(여기서는 첫 번째 위치의 값)과 비교한다. 만약 저장된 값이 비교한 값보다 작다면 둘의 위치를 바꾸어준다.
- 2회전 시 세 번째 위치의 값을 저장한다. 그리고 저장된 값과 세 번째 위치 이전의 값들(여기서는 두 번째와 첫 번째 위치의 값)과 비교한다. 그리고 저장된 값이 들어갈 알맞은 위치를 찾았다면 그 위치에 저장된 값을 삽입하기 위해 원소들을 한 칸씩 뒤로 이동시킨다.
- 위의 과정을 반복한다.
이렇게 말로 풀어쓰면 무슨 말인지 헷갈리니 실제 코드와 gif파일로 확인하는게 낫겠다.
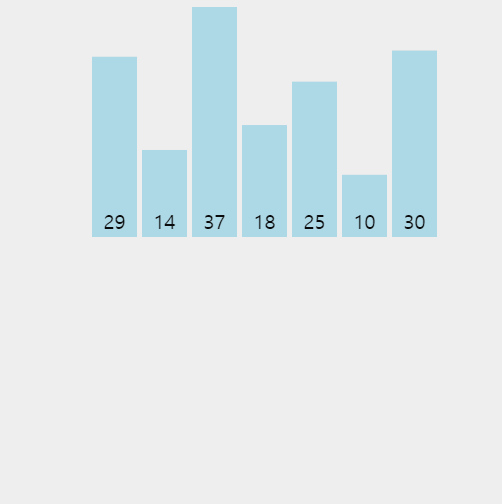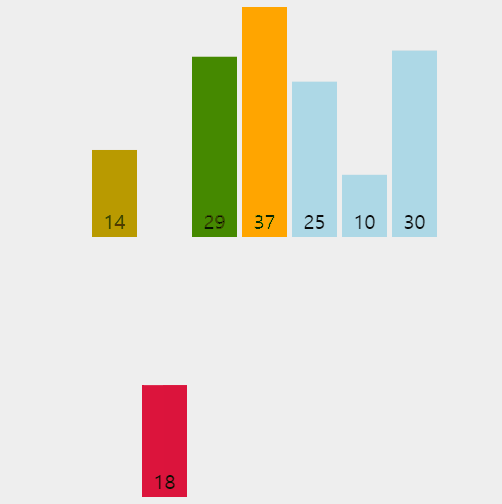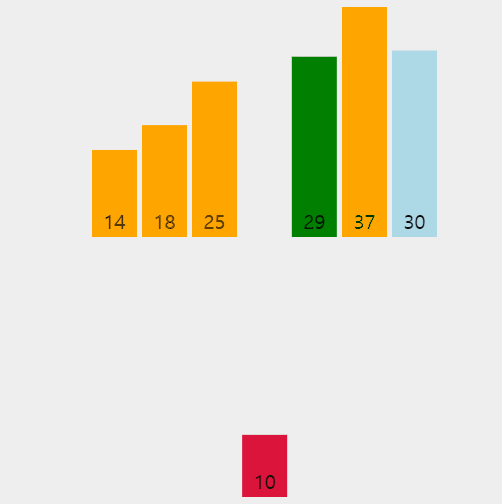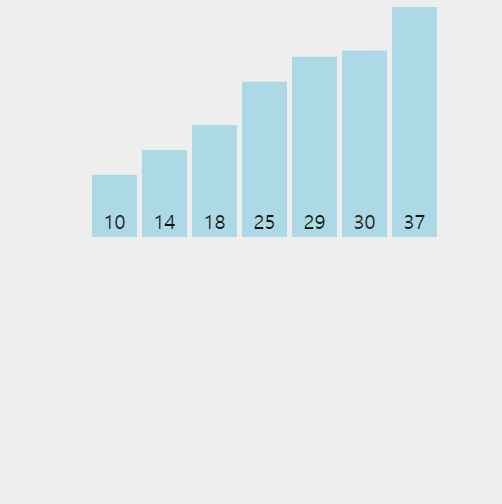
👆 1회전 시 14와 29를 비교하고, 2회전 시 37과 29를 비교하였으나 37이 더 크기 때문에 14와 비교할 필요가 없다.
💾 Java코드
private static void sort(int[] arr) {
for (int i = 1; i < arr.length; i++) { // 1️⃣
int tmp = arr[i];
int prev = i - 1;
while ((prev >= 0) && (tmp < arr[prev])) { // 2️⃣
arr[prev + 1] = arr[prev];
prev--;
}
arr[prev + 1] = tmp; // 3️⃣
}
}- ① 첫번째 원소의 앞에는 어떤 원소도 없기 때문에 두 번째 위치(
i = 1) 부터for문으로 탐색한다.tmp에 임시로i번째 위치의 값을 저장하고,prev에는 해당 위치의 이전 위치(i-1)을 저장한다. - ②의
while문은 이전 위치인prev가 음수가 되지 않고, 이전 위치의 값인arr[prev]가 기준이 되는 값인tmp(arr[i])보다 크다면 둘을 교환해준다. 그 후prev를 1 감소시키므로prev가 음수가 되거나(가장 첫번째 원소까지 비교 끝),tmp가arr[prev]보다 크다면while문을 빠져나온다. - ③은 ②의
while문이 끝나고 난 후prev에는tmp가 들어갈 위치의-1 을 가르키므로( ②에서tmp보다 큰 값들을 한 칸씩 오른쪽으로 밀었으므로)prev + 1자리에tmp를 삽입해준다.
📝 특징
-
장점
- 단순한 알고리즘
- 안정 정렬
- 버블 정렬과 선택 정렬에 비해 상대적으로 빠르다.
- 정렬하고자 하는 배열 안에서 교환하는 방식이므로, 다른 메모리 공간을 필요로 하지 않는다.
-
단점
- 비교적 많은 원소들의 이동을 포함한다.
- 평균과 최악의 시간 복잡도가 O(N^2) 이므로 비효율적이다.
- 비교할 원소가 많고 크기가 클 경우에 적합하지 않다.(배열의 길이가 길어질수록 비효율적)
📝 시간 복잡도
(n-1) + (n-2) + .... + 2 + 1 = n(n-1)/2이므로, O(N^2) 이다. 하지만 모두 정렬이 되어 있는 경우에는 한 번씩만 비교를 하면 되므로 O(n) 의 시간복잡도를 가진다.
따라서 최선의 경우 : O(n),
평균과 최악의 경우 : O(n^2)
📝 공간 복잡도
주어진 배열 안에서 교환을 통해 정렬이 수행되므로 O(N)이다.

이것저것 공부중