
오늘부터 개강 전까지 자료구조론에 관한 공부를 진행하기로 했다. 강의를 베이스로 해서 궁금한 건 추가적으로 조사해보려고 한다! 이번 챕터의 목표는
✅자료구조가 무엇인지 이해하기
✅Abstract Data Type(ADT)에 대해 이해하기
✅자료구조의 효율성을 판단하는 방법 알기
이상의 세 가지이다. 그럼 정리 시작 !
## 1.자료구조
교수님께서 자료구조를 "데이터를 논리적으로 정리할 수 있는 방법과 효과적으로 데이터에 접근할 수 있는 기술을 제공해주는 자료들의 집합" 이라고 설명하셨다. 설명을 듣고 나는 자료구조란 데이터를 논리적으로 표현하고 접근성에 있어서 효율적이게 저장하는 것을 의미한다고 이해했다.
자료구조가 필요한 이유는 방대한 양의 데이터를 효율적으로 처리하기 위함이다. 이제 데이터는 요타바이트단위(YB)까지 써야할 정도로 많아졌고, 앞으로는 더 빠른 속도로 증가할 것이라고 한다. 요타바이트까지는 알아두라고 하셔서 기록해두기 😊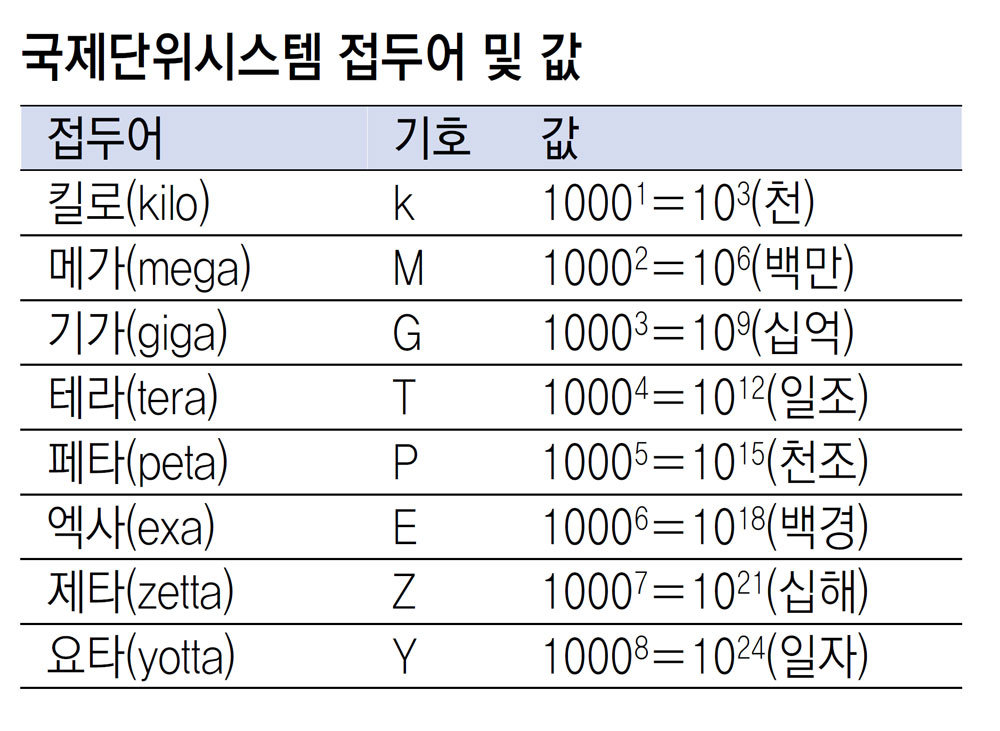
자료구조를 듣고 놀랐던 건, 1년 내내 썼던 int, char등 자료형도 자료구조의 일부라는 것이었다. 이런 자료형은 이미 구현되어 내장돼 있는 것이고 앞으로 배울 스택, 큐, 트리, 그래프는 사용자가 직접 정의(구현)해야 하는 것이다.
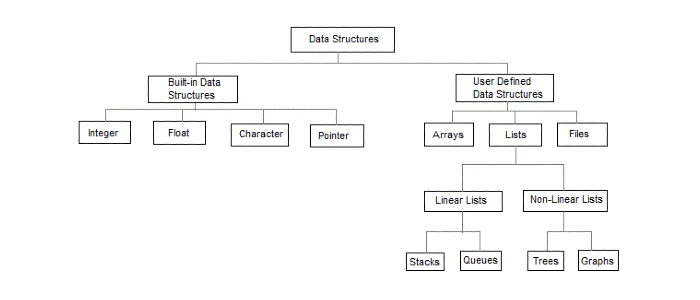
## 2. ADT (Abstract Data Type)
이건 C언어를 공부할 때 스치듯이 봤던 기억이 있다. 정확한 뜻은 몰랐지만 이제 알면 되지 뭐!
ADT는 '어떤 과정으로 구현하는지'가 목적이 아니라 해당 자료구조의 특성을 잘 정의하기 위해 사용한다. 즉 순수하게 기능이 무엇인지만 쓰는 것이다. 구현과는 분리된 개념이다.
ADT 정의에 꼭 필요한 함수들이 있다. 이 세가지가 꼭! 포함되어야한다.
▶특정 자료구조를 생성하는 함수
▶값을 변형해주는 함수
▶자료구조에 어떤 데이터가 있는지 찾고 출력해주는 함수
3. 좋은 자료구조인지 아닌지 분석하기
이 부분을 공부하면서 생각보다 개발을 할 때 신경써야 하는 부분이 많다는 걸 다시 한 번 느꼈다. 훌륭한 프로그램인지 판단하는 기준은 크게 7가지였다.
- 주어진 업무를 수행하기 위한 코드인지, 값은 잘 도출되는지 확인
- 다른 개발자들이 잘 이해할 수 있는지, 가독성 좋은 코드인지 확인
- 메모리의 효율성이 좋은지, 러닝타임이 괜찮은지 확인
자료구조론에서는 위 조건들 중에서 세번째 조건을 다룬다고 하셨다. 시간적 효율과 메모리의 효율 둘 다 중요함을 강조하셨음!
3-1 자료구조 효율성 분석과정🌟
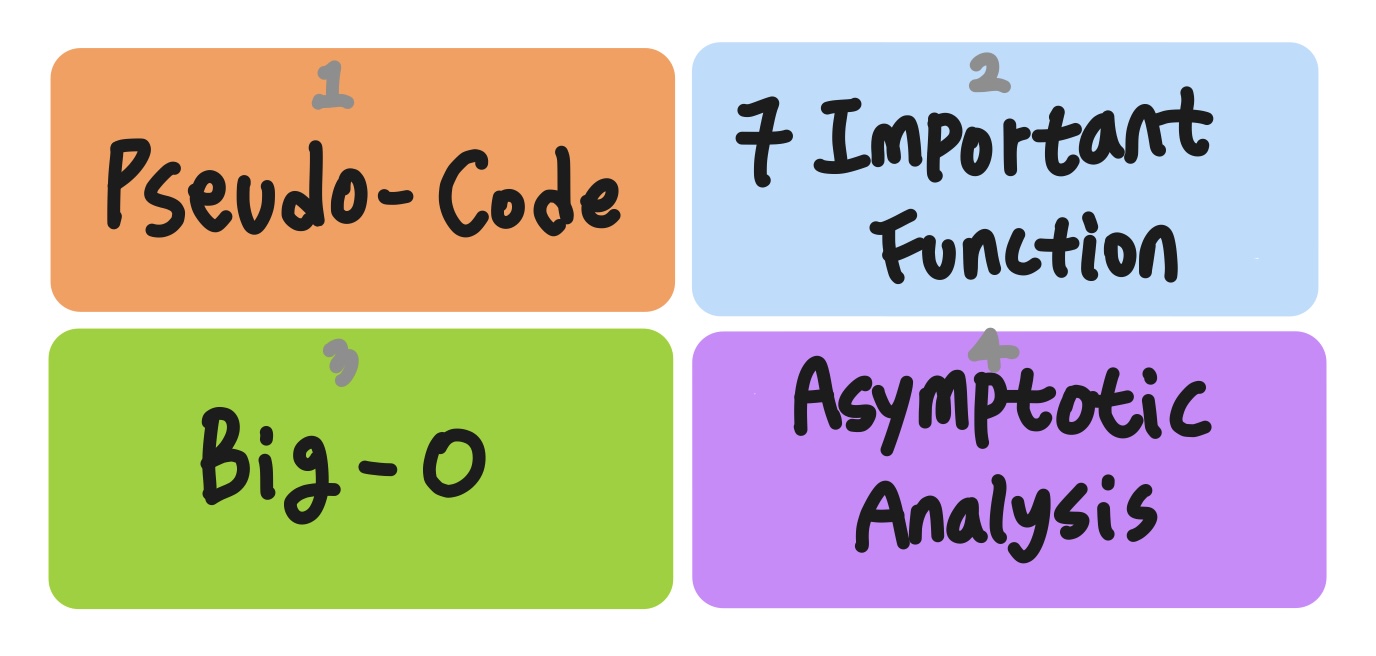
알고리즘이 정해지면 다음과 같은 순서로 자료구조를 분석해준다.
Pseudo-code로 바꾼 후 7Function을 이용해 수식으로 바꾼다. 그 후 Big-O로 worst case를 나타내어 성능을 비교한다. 단어 각각의 설명은 아래에 할 예정!😊
Pseudo-Code
얘는 쉽게 말하면 사람의 언어와 컴퓨터 프로그래밍 언어의 중간 어딘가로 생각하면 될 것 같다. 코드의 알고리즘을 구상할 때 사용하고, Algorithm, Input, Output등의 단어를 이용해 구상한다. 또 프로그래밍언어로 코딩하듯이 for,if,while 등의 문법을 사용한다. 그런데 특이점은 '←'를 할당의 뜻으로 이용하고, '='를 같다는 뜻으로 이용한다는 점이었다.
7 Important Function
이거는 함수그래프의 종류를 의미한다. x축을 데이터의 양, y축을 러닝타임으로 설정하여 그래프를 그리고, g(n)이라는 함수로 정의한다.
그래프의 종류는 7가지로 상수함수, lg n, n, n lg n, n^2, n^3, 2^n 이 있다. 오른쪽으로 갈수록 그래프의 기울기가 기하급수적으로 커지며, 이는 데이터의 양이 많아지면 러닝타임이 급격히 길어짐을 의미한다. 왼쪽의 함수일수록 좋은 함수라고 볼 수 있다. 실질적으로 성능이 좋은 코드는 g(n) = n lg n 함수로 다루며 성능이 나쁜 코드도 g(n) = n^2로 커버 가능하다. 만약 내 코드가 n^3이나 2^n이 나온다면.. 그 코드는 버리라고 하셨다..😂
Big-O
이 개념을 설명하려면 러닝타임에 대해 먼저 설명해야한다. 러닝타임이 좋은 케이스, 평균치인 케이스, 최악인 케이스가 있다면 무엇을 중심으로 봐야할까? 정답은 최악인 케이스(Worst case)이다. 얘가 가장 중요하다.
big-o는 시간복잡도를 다룰 때 사용하는 표기법 중 하나로 n의 값이 충분히 커지면
그 이상의 어떤 n을 대입하여도 c*g(n)보다 결과값이 작은 상수 c가 존재한다는 뜻이다.
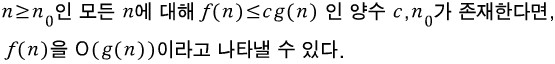
f(n)<=cg(n)이라는 것은 충분히 커진 n값을 넣으면 g의 y값이 항상 크다는 것이고, 이는 러닝타임이 항상 길다는 것이며 쉽게 말하면 worst case인 것이다!
O(n)은 최고차항만 취하고 나머지를 버리면서 쉽게 구할 수 있다고 하셨다.
big-O는 worst case와 관련된 것이고 이 외에도 big-Omega (best case), big-Theta (average case)가 있다.
빠른 컴퓨터와 더 나은 알고리즘이 있다면 더 나은 알고리즘이 더 효율적이라고 하셨다!
Asymptotic Analysis
n을 충분히 큰 값으로 보냈을 때 성능을 비교하는 것이라는 뜻이다!
이렇게.... 2023년..1월..27일...우당탕탕 자료구조 1일차 기록 끝😎🎶
