
과적합
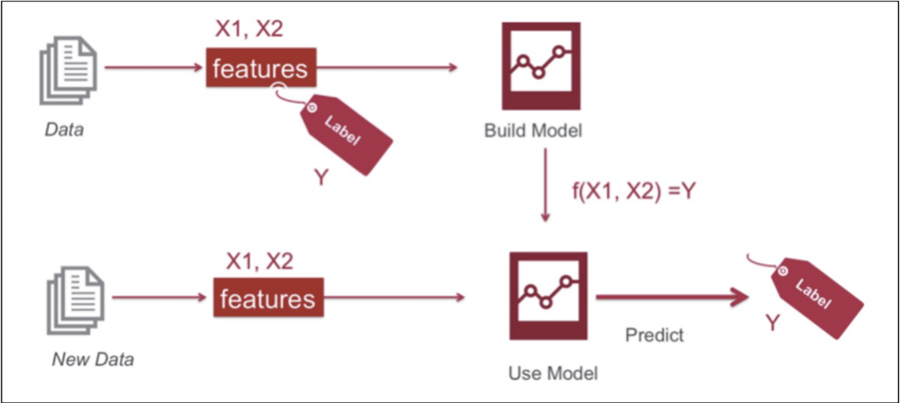
지도학습
- 학습 대상이 되는 데이터에 정답(label)을 붙여서 학습 시키고
- 모델을 얻어서 완전히 새로운 데이터에 모델을 사용해서 “답”을 얻고자 하는 것
mlxtend 설치
- sklearn에 없는 몇몇 유용한 기능을 가지고 있다

Tree model visualization
-
iris의 품종을 분류하는 결정나무 모델
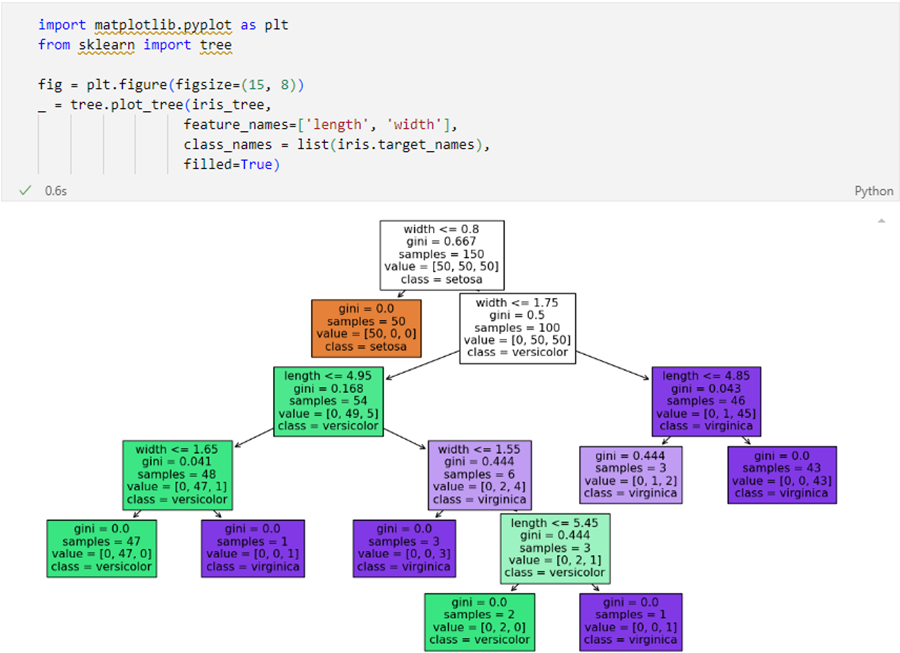
-
iris의 품종을 분류하는 결정나무 모델 데이터를 분류
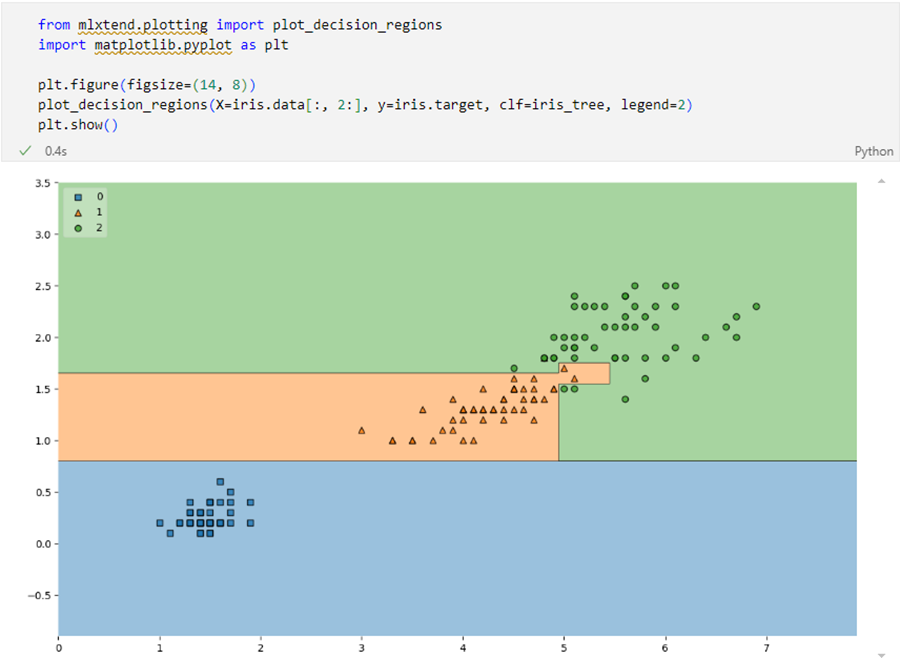
-
결정 경계를 확인

-
Accuracy가 높다고 믿을 수 있을까?
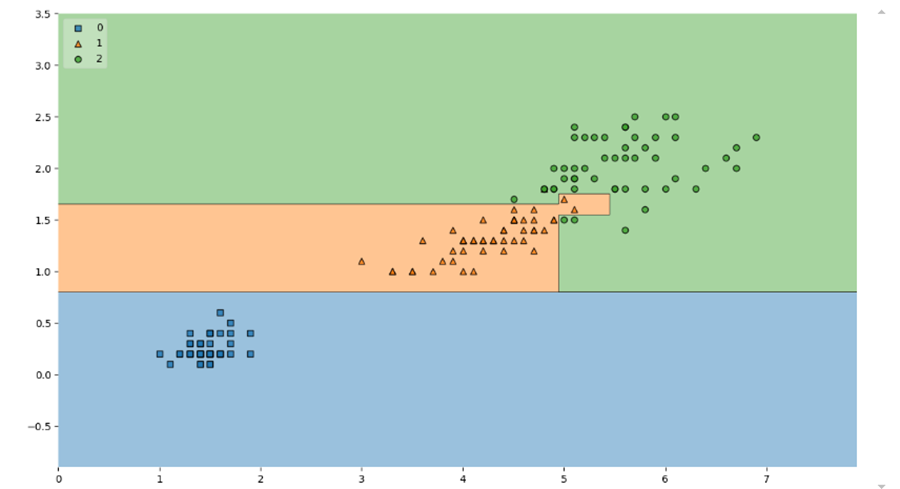
- 저 경계면은 올바른 걸까?
- 저 결과는 내가 가진 데이터를 벗어나서 일반화할 수 있는 걸까?
- 어차피 얻은 데이터는 유한하고 내가 얻은 데이터를 이용해서 일반화를 추구하게 된다.
- 이때 복잡한 경계면은 모델의 성능을 결국 나쁘게 만든다.
데이터 분리
데이터의 분리 (훈련 / 검증 / 평가)
- 확보한 데이터 중에서 모델 학습에 사용하지 않고 빼둔 데이터를 가지고 모델을 테스트한다.

아이리스 데이터 분리
-
다시 아이리스 데이터를 불러온다.

-
데이터를 훈련 / 테스트로 분리
- 8:2 확률로 특성(features)과 정답(labels)를 분리

-
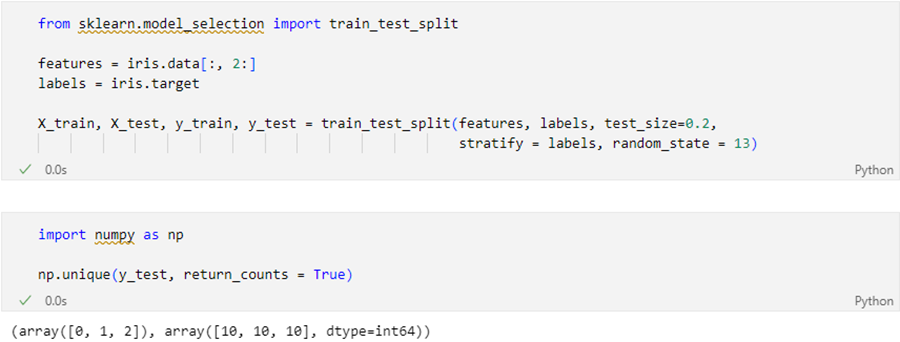
훈련용 / 테스트용이 잘 분리 되었는지 확인
→ 문제가 각 클래스(setosa, versicolor, verginica) 별로 동일 비율이 아니다

-
데이터를 훈련 / 테스트로 분리 + 옵션 추가 & 확인
train data
-
train 데이터만 대상으로 의사결정나무 모델 생성
- 학습할 때 마다 일관성을 위해 random_state 고정
- 모델을 단순화시키기 위해 max_depth를 조정
-
train 데이터에 대한 accuracy 확인

-
모델 확인

-
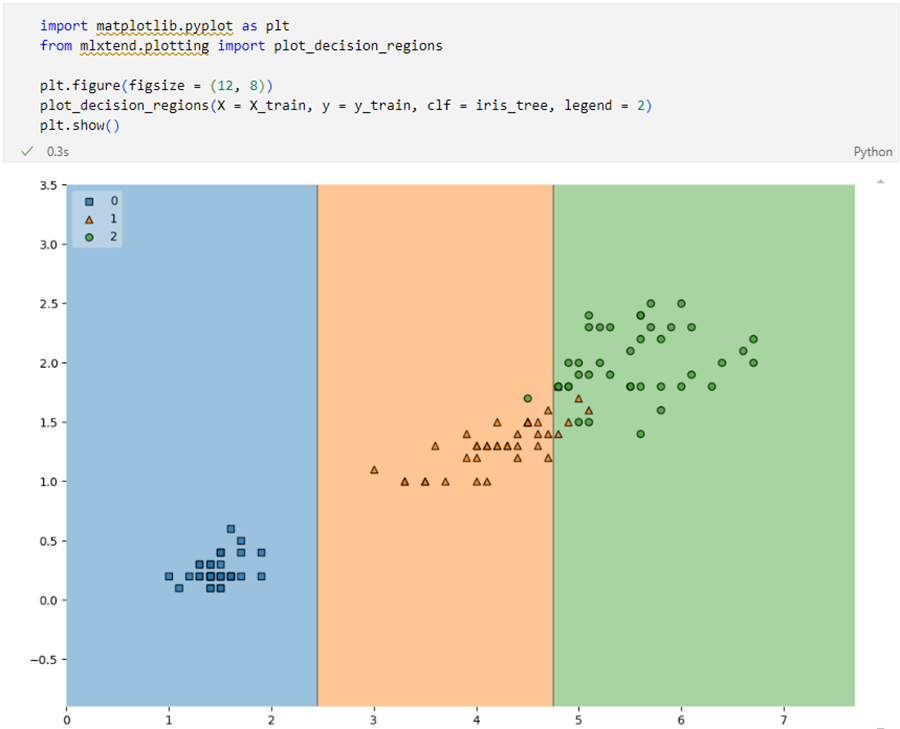
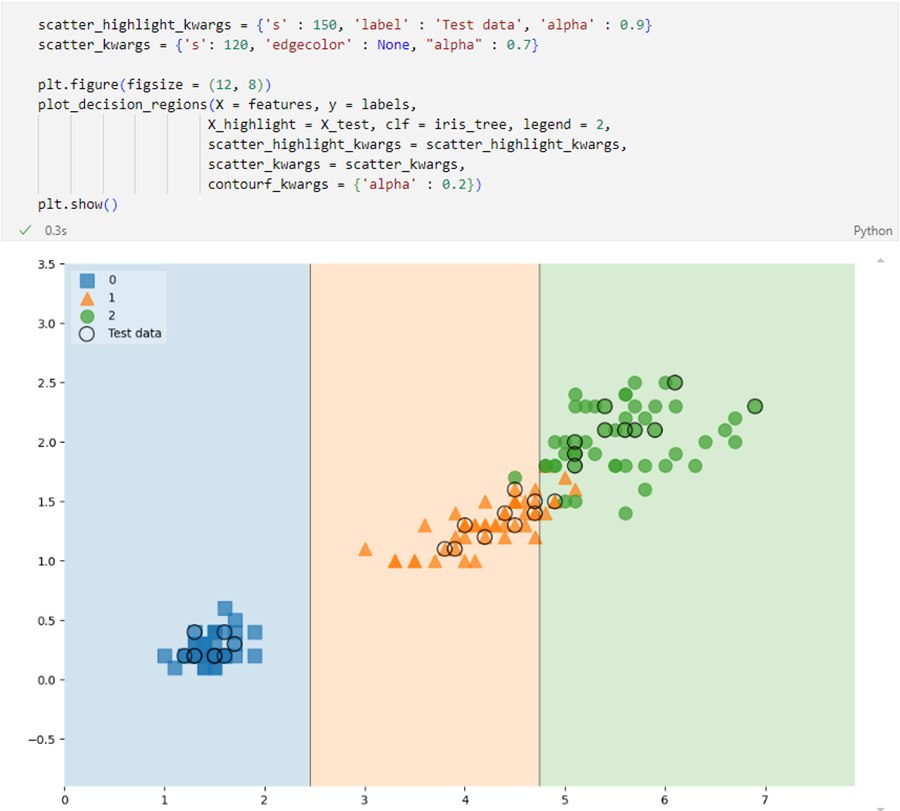
훈련데이터에 대한 결정경계를 확인
test data
-
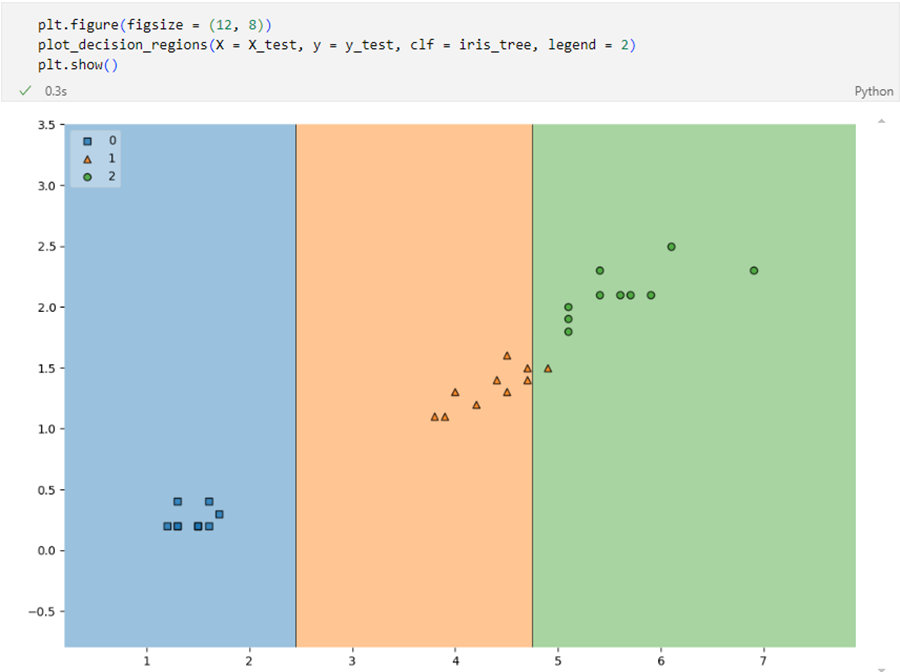
테스트 데이터에 대한 accuracy 확인

-
결과
train + test data
- 전체 데이터에서 관찰
feature 모두 적용
-
feature를 모두 사용하여 코드 수정
-
전체 특성을 사용한 결정나무 모델

모델 사용법
-
새로운 data로 target 검색
- 길가다가 주운 iris가 sepal과 petal의 length, width가 각각 [4.3, 2. , 1.2, 1.0]이라면

- 각 클래스별 확률이 아니라 범주 값을 바로 알고 싶다면
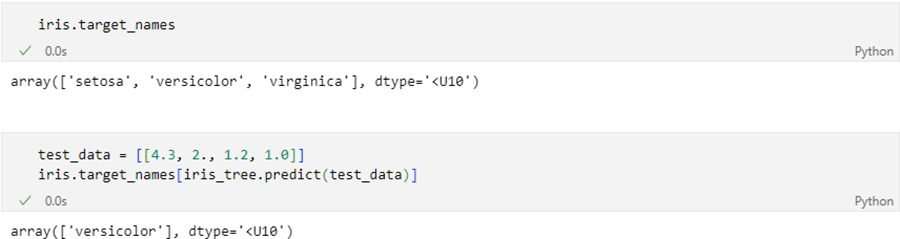
- 길가다가 주운 iris가 sepal과 petal의 length, width가 각각 [4.3, 2. , 1.2, 1.0]이라면
-
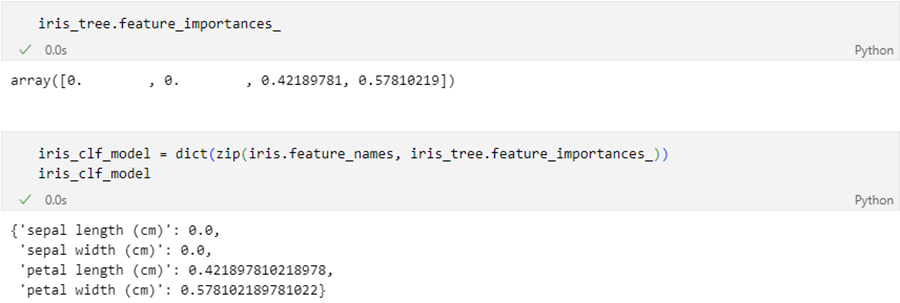
주요 특성 확인
- 여기서 잠깐 Black box / White box 모델
- Tree계열 알고리즘은 특성을 파악하는데 장점을 가진다.
간단한 zip과 언패킹
-
리스트 → 튜플
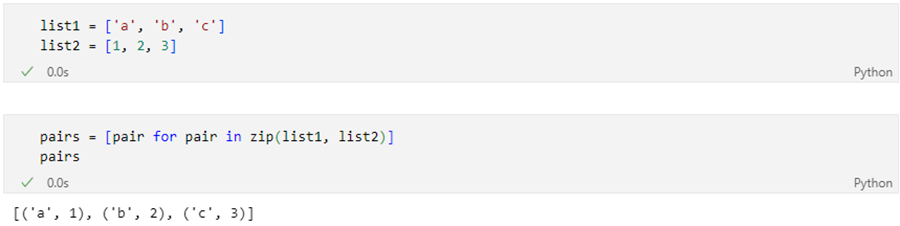
-
튜플 → dict

-
리스트 → dict

-
unpacking

