데이터 소개
신용카드 부정 사용자 검출

신용카드 부정사용 검출에 관한 논문의 한 예

데이터 다운로드
https://www.kaggle.com/MLG-ULB/CREDITCARDFRAUD
데이터 개요

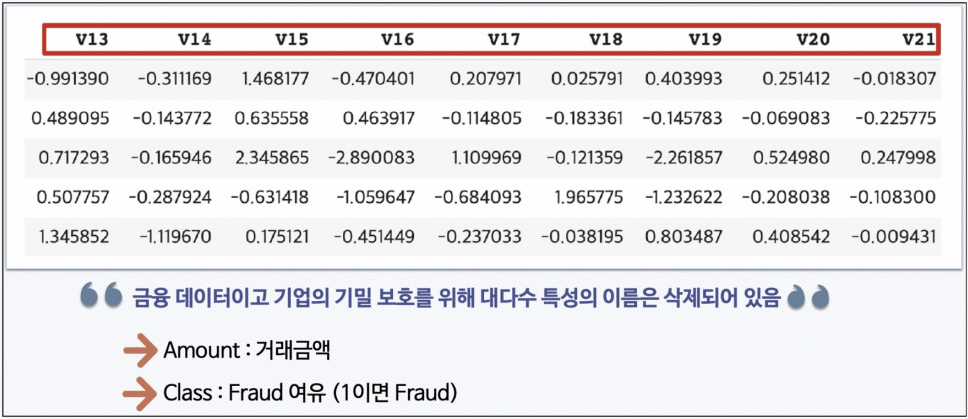
데이터 특성
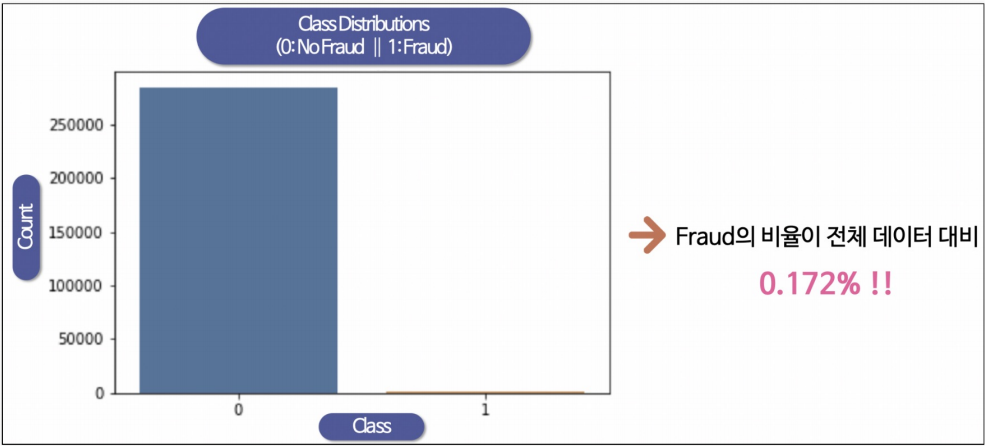
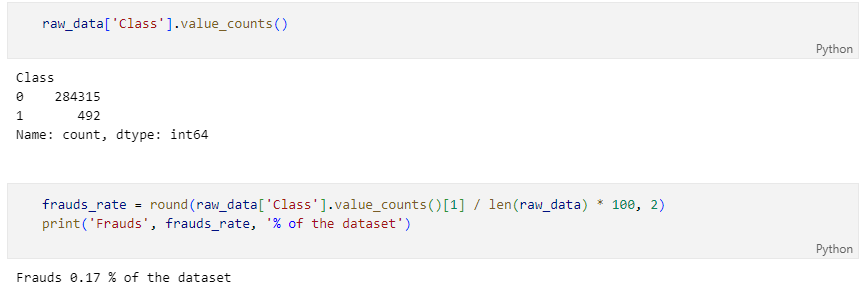
데이터의 불균형이 극심함
실습
데이터 읽고 관찰하기
데이터 읽기 / 특성 확인
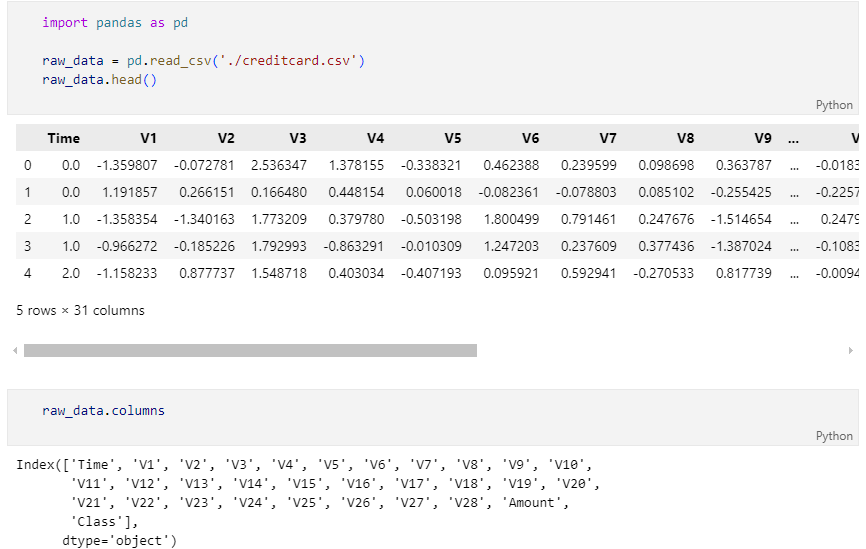
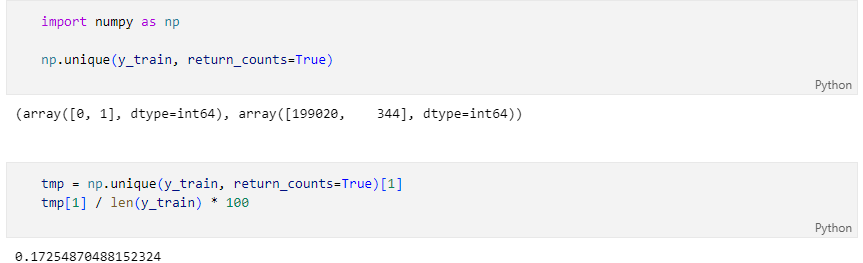
데이터 라벨의 불균형이 정말 심하다
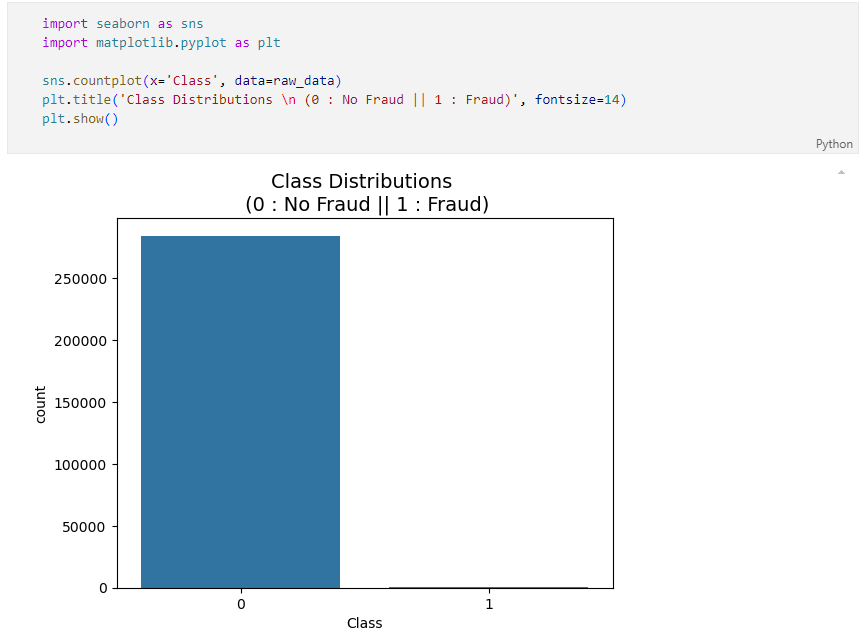
그래프로 표현되기도 힘들다
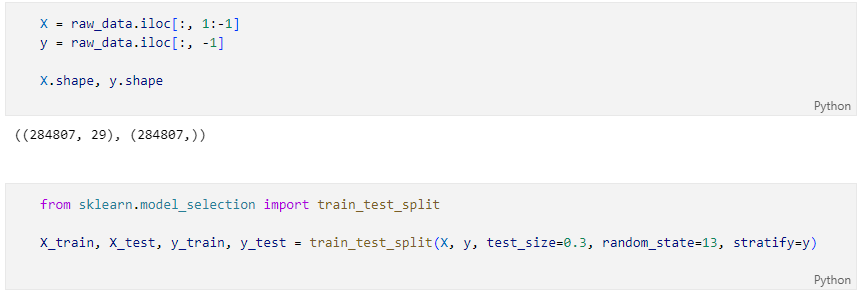
X, y로 데이터 선정 후 분류
나눈 데이터의 불균형 정도가 어떤 지 확인
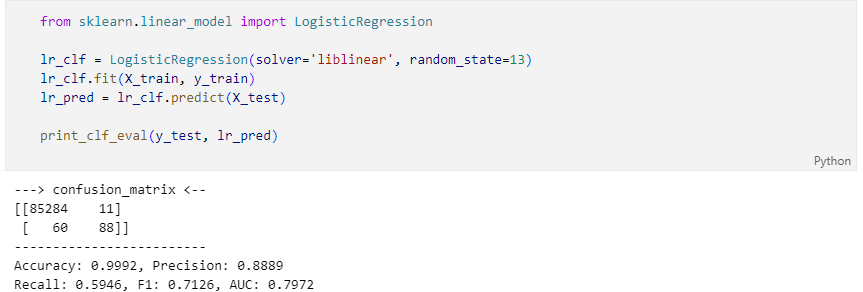
단순 무식한 첫 도전 - 1st Trial
분류기의 성능을 return하는 함수
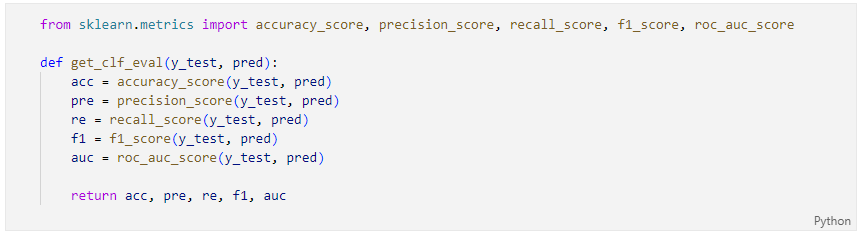
성능을 출력하는 함수
Logistic Regression
Decision Tree
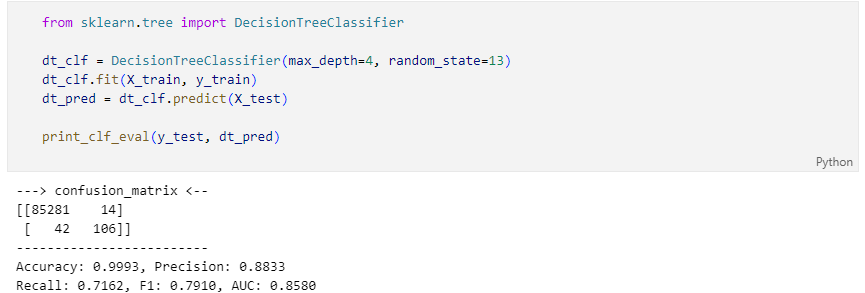
Random Forest
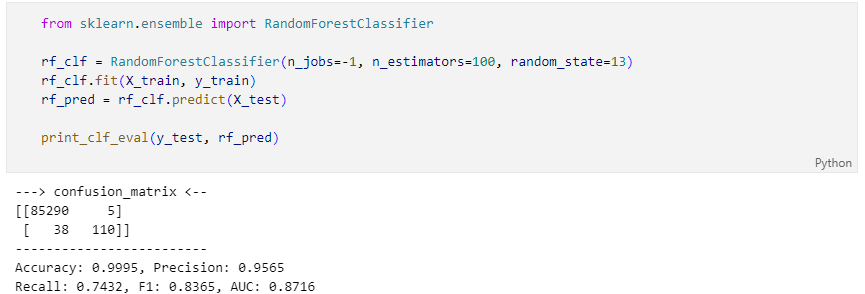
LightGBM
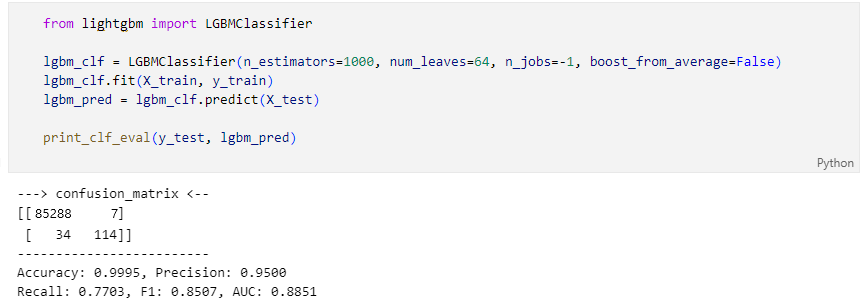
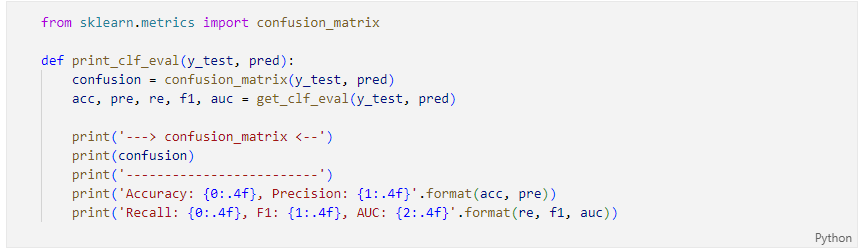
모델과 데이터를 주면 성능을 출력하는 함수

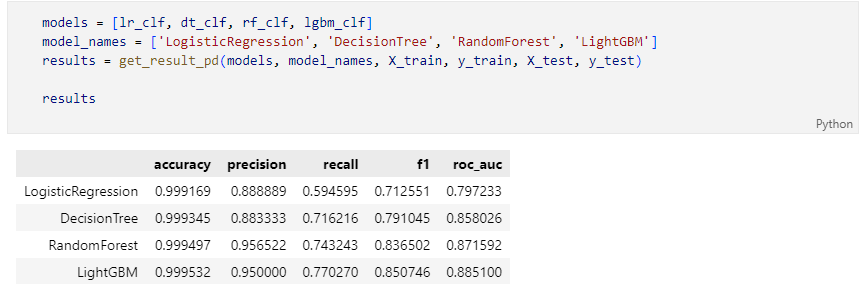
다수의 모델의 성능을 정리해서 DataFrame으로 반환하는 함수

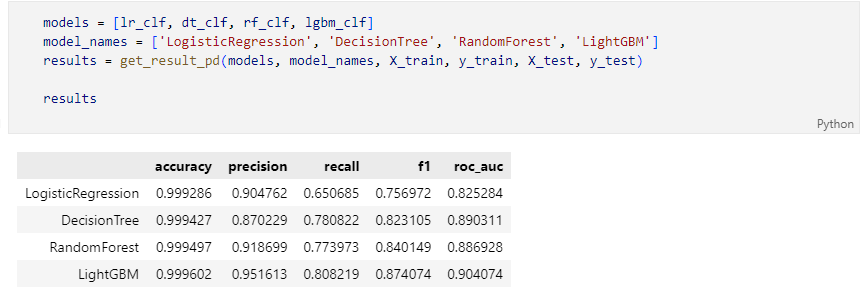
4개의 분류 모델을 한 번에 표로 정리
데이터를 정리해서 다시 도전하자 - 2nd Trial
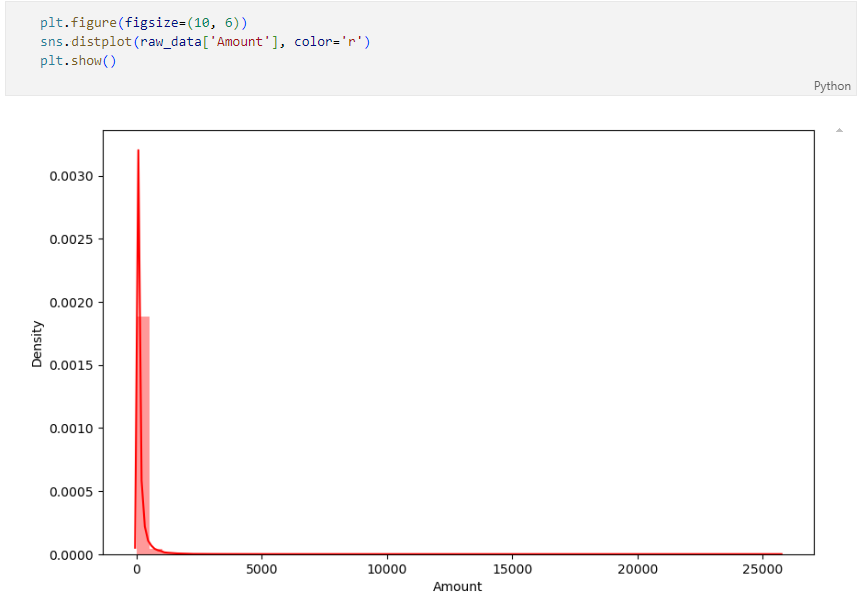
raw_data의 Amount 컬럼 확인 (Amount : 신용카드 사용 금액)
Amount 컬럼에 StandardScaler 적용
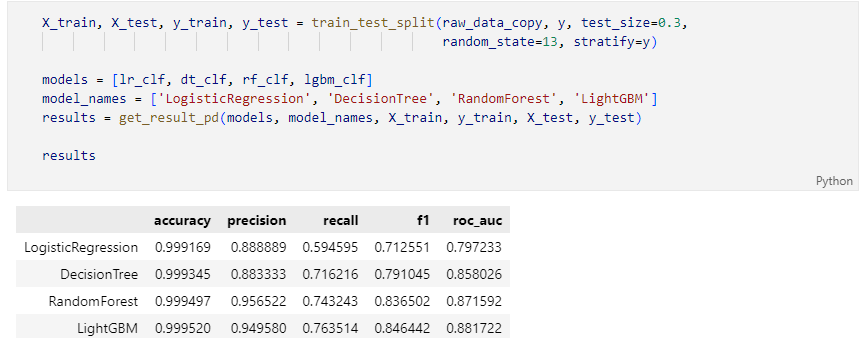
데이터 분류 후 모델에 다시 평가
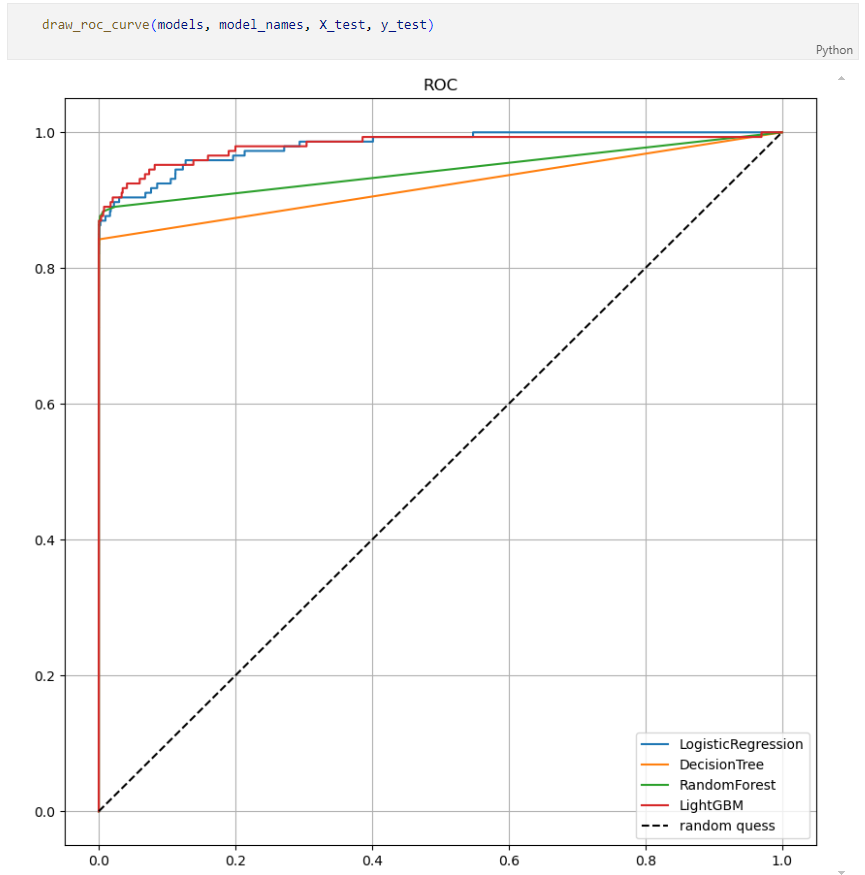
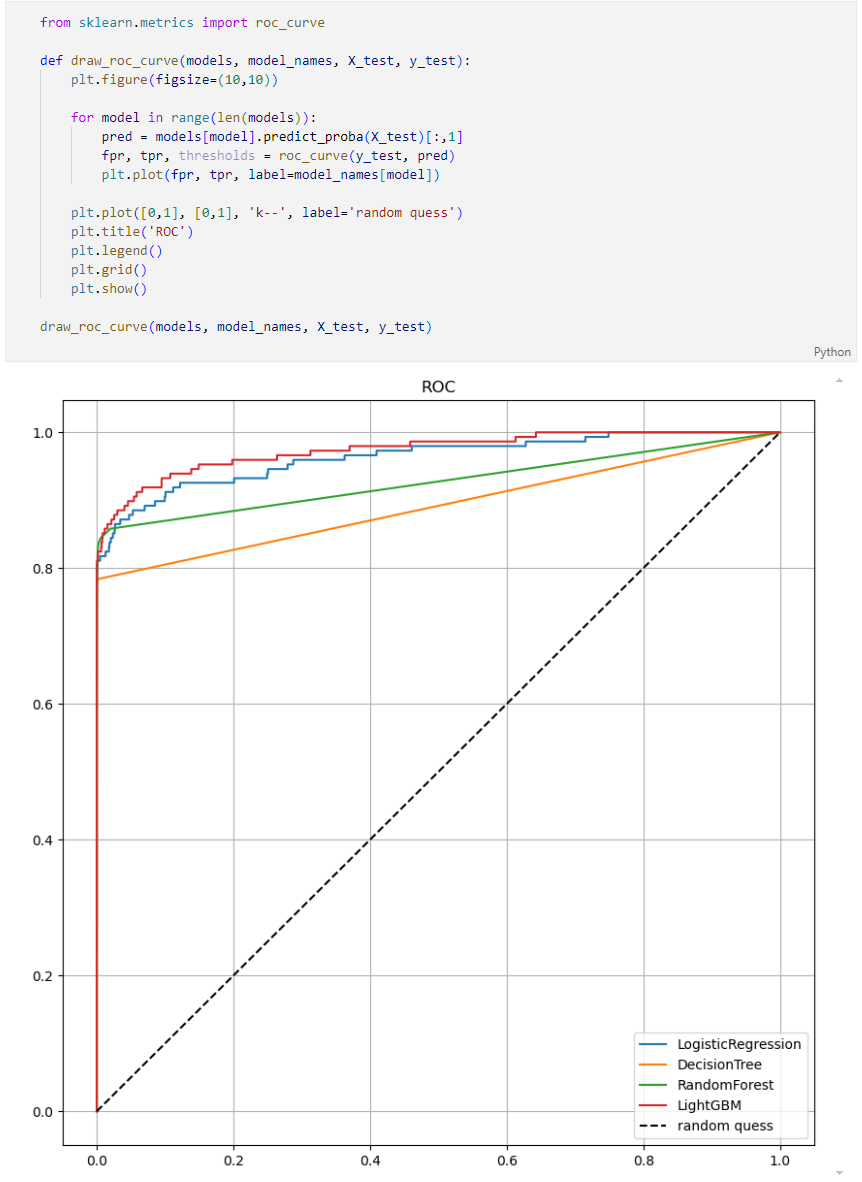
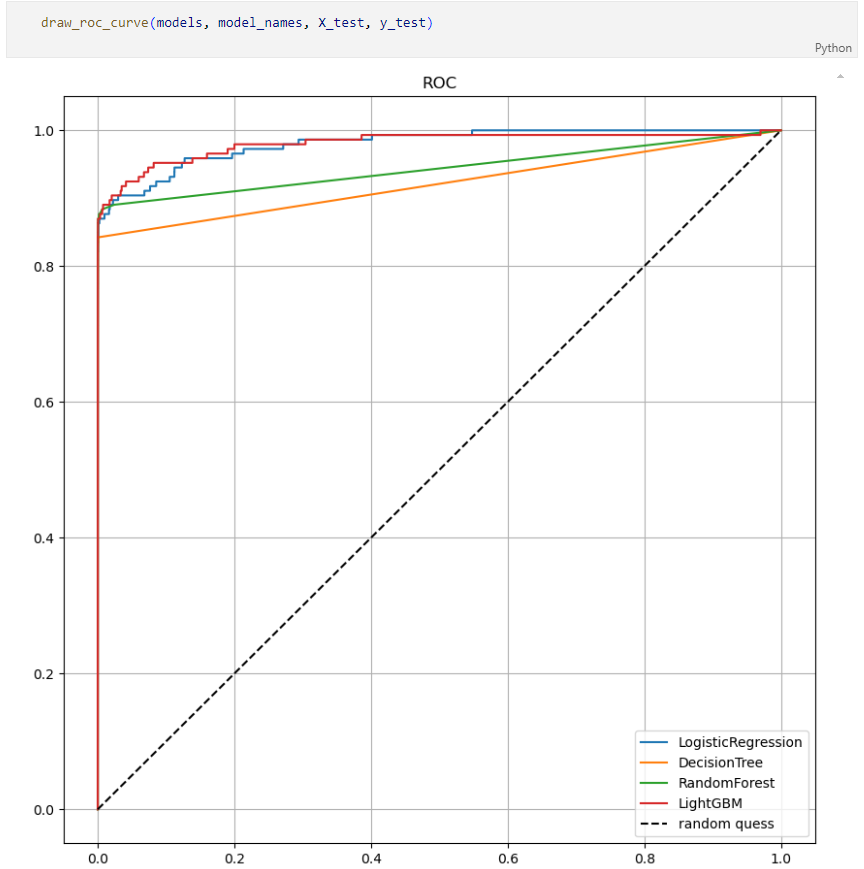
모델별 ROC 커브
또다른 시도 log scale
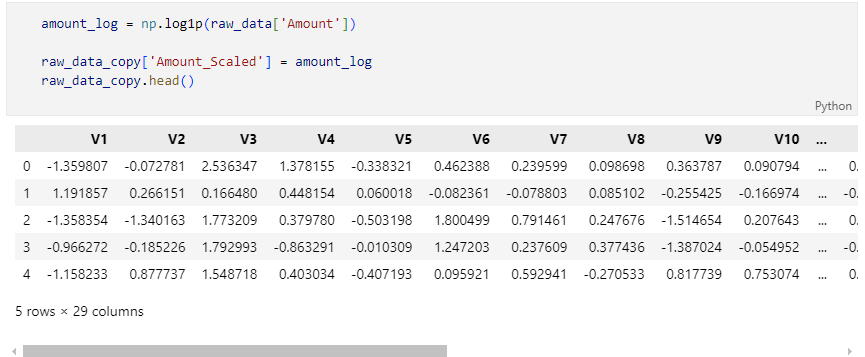
한쪽에 치우쳐 있던 분포가 변화
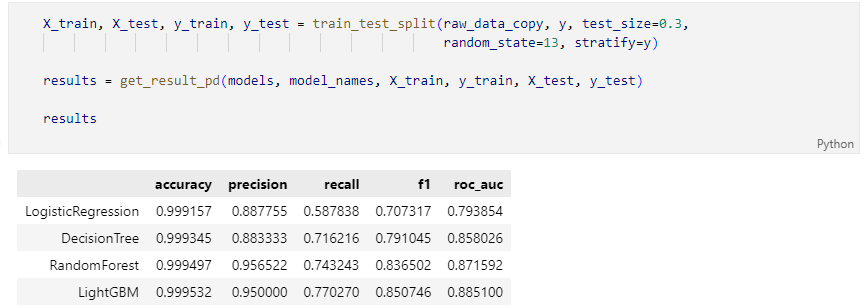
다시 성능을 확인
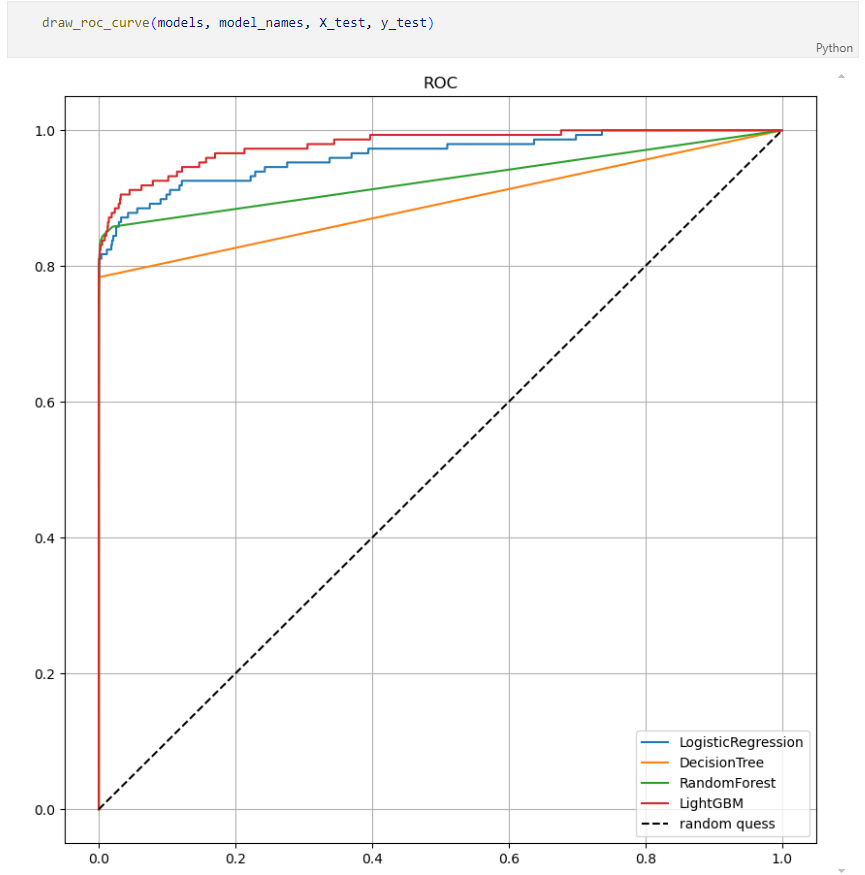
모델별 ROC 커브
데이터의 Outlier를 정리해보자 - 3rd Trial
특이 데이터
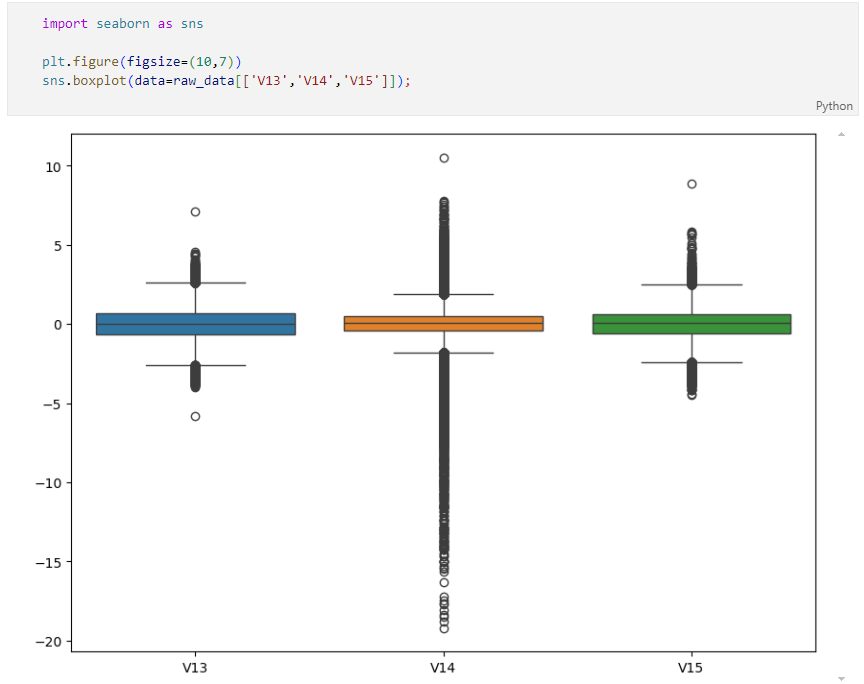
Outlier를 정리하기 위해 Outlier의 인덱스를 파악하는 코드
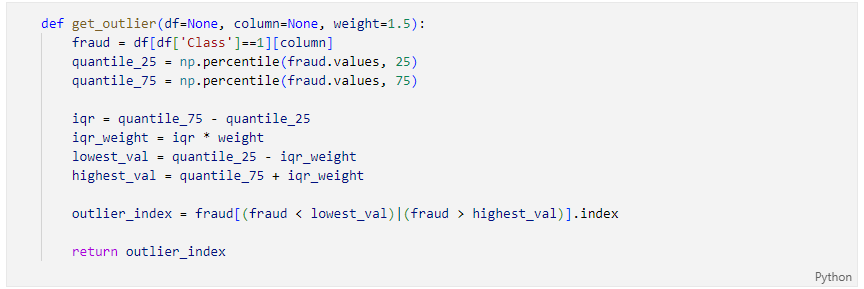
Outlier 찾기

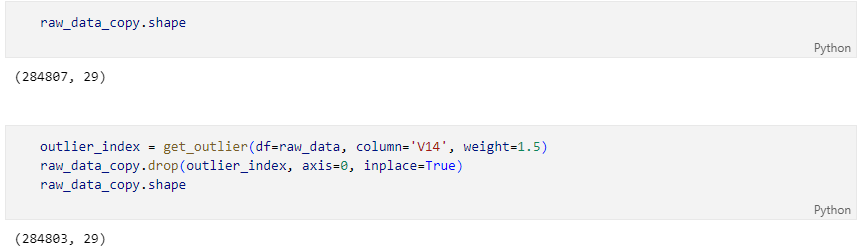
Outlier 제거
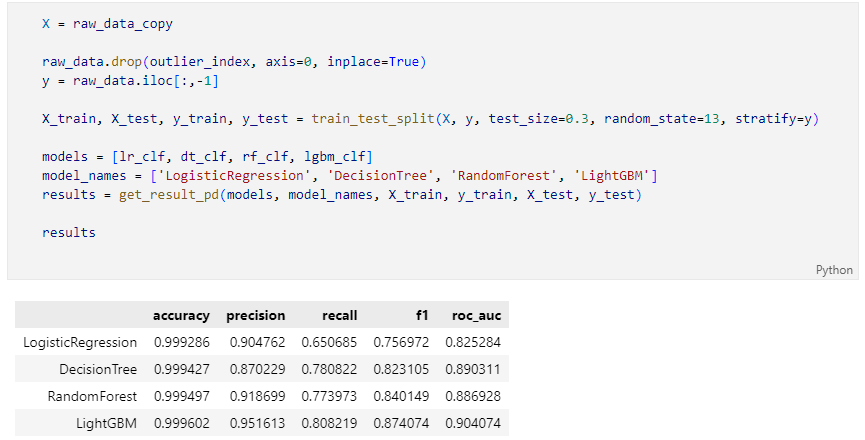
Outlier를 제거한 데이터 분류 후 다시 평가
모델별 ROC 커브
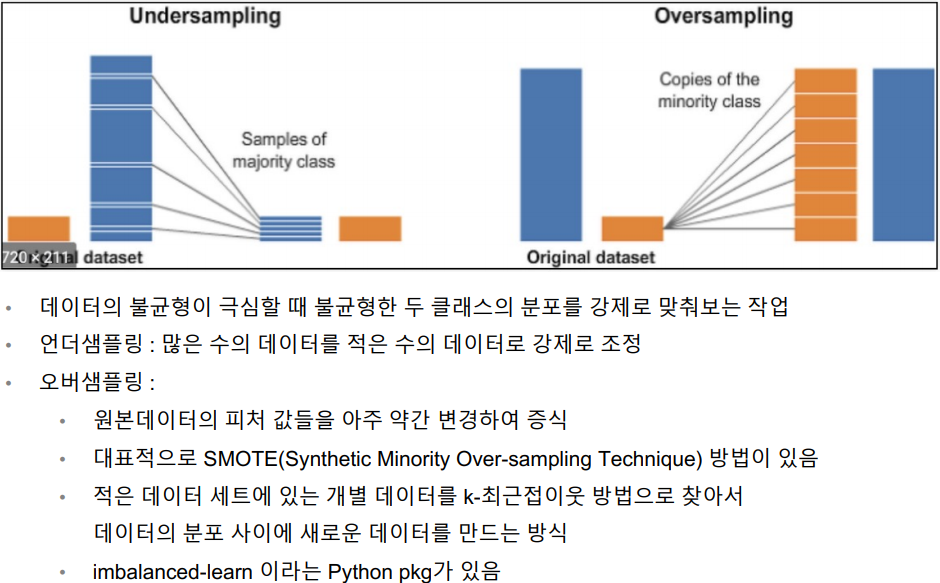
SMOTE Oversampling - 4th Trial
Undersampling vs Oversampling
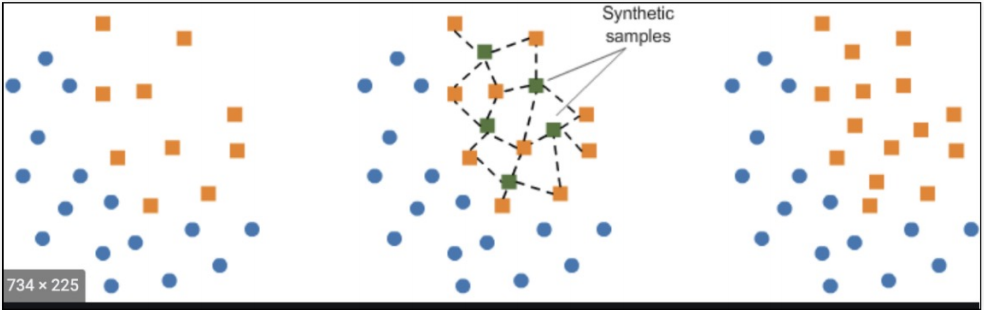
SMOTE 적용

데이터 증강 효과와 결과
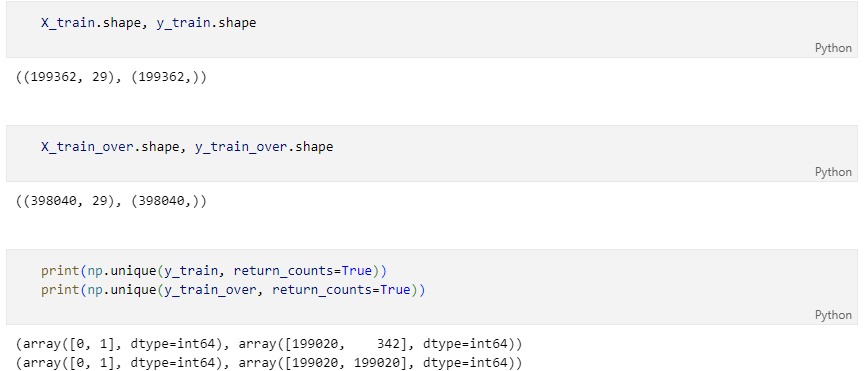
다시 성능 확인
모델별 ROC 커브