비지도 학습

비지도 학습
- 군집 Clustering : 비슷한 샘플을 모음
- 이상치 탐지 Outier detection : 정상 데이터가 어떻게 보이는지 학습, 비정상 샘플을 감지
- 밀도 추정 : 데이터셋의 확률 밀도 함수 Probability Density Function PDF를 추정. 이상치 탐지 등에 사용
K-Means
- 군집화에서 가장 일반적인 알고리즘
- 군집 중심(centroid)이라는 임의의 지점을 선택해서 해당 중심에 가장 가까운 포인트들을 선택하는 군집화
- 일반적인 군집화에서 가장 많이 사용되는 기법
- 거리 기반 알고리즘으로 속성의 개수가 매우 많을 경우 군집화의 정확도가 떨어짐
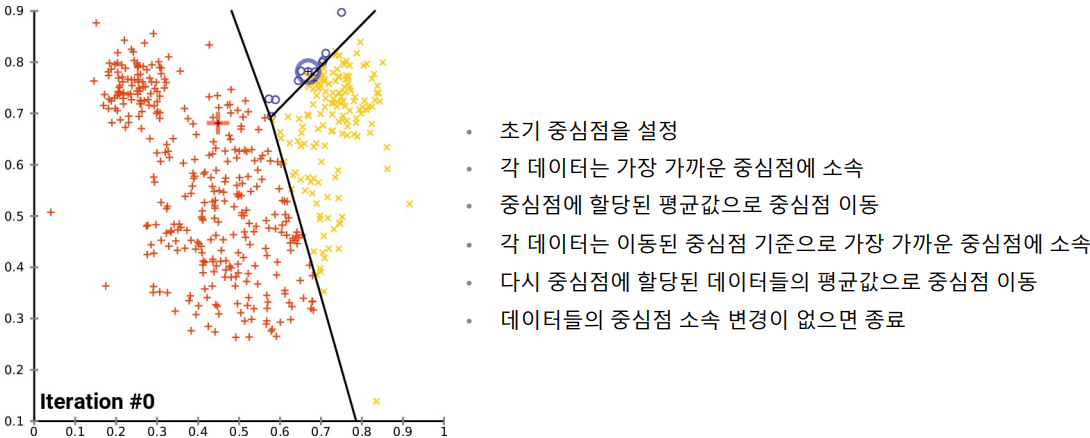
K-Means 알고리즘

알고리즘의 원리 1
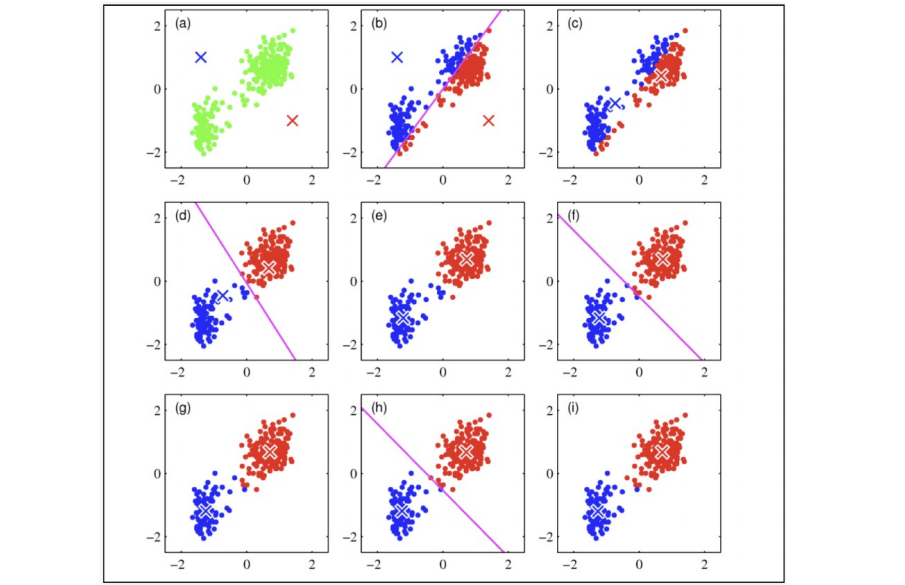
알고리즘의 원리 2
실습 데이터
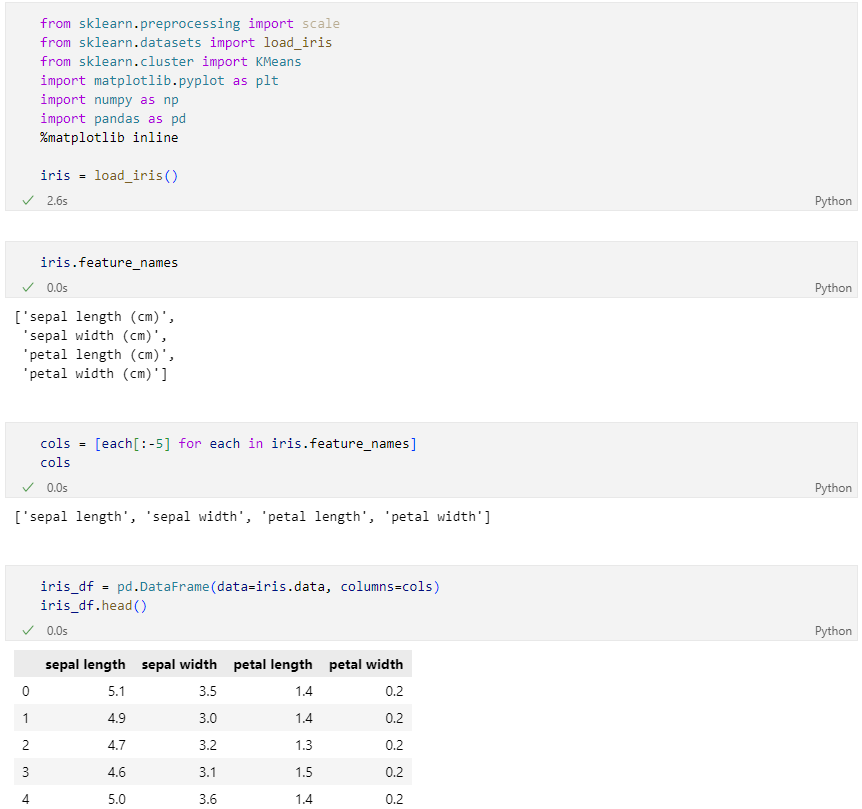
편의상 두 개의 특성만
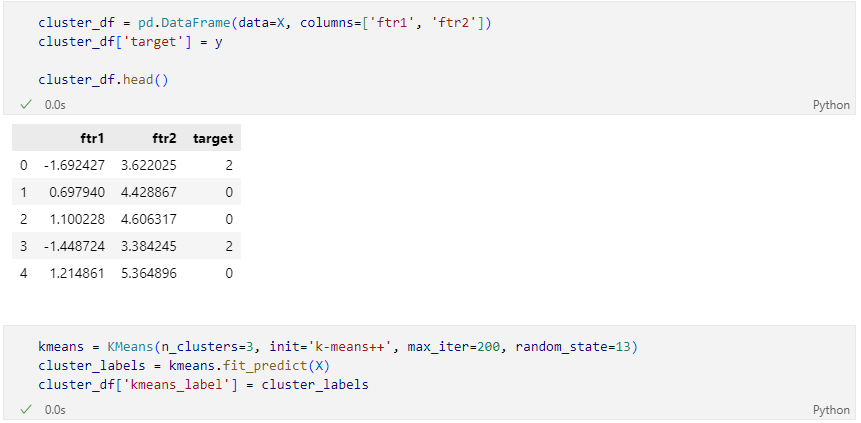
군집화
• n_clusters : 군집화 할 개수, 즉 군집 중심점의 개수
• init : 초기 군집 중심점의 좌표를 설정하는 방식을 결정
• max_iter : 최대 반복 횟수, 모든 데이터의 중심점 이동이 없으면 종료
결과 라벨
군집화라서 지도학습의 라벨과 다르다

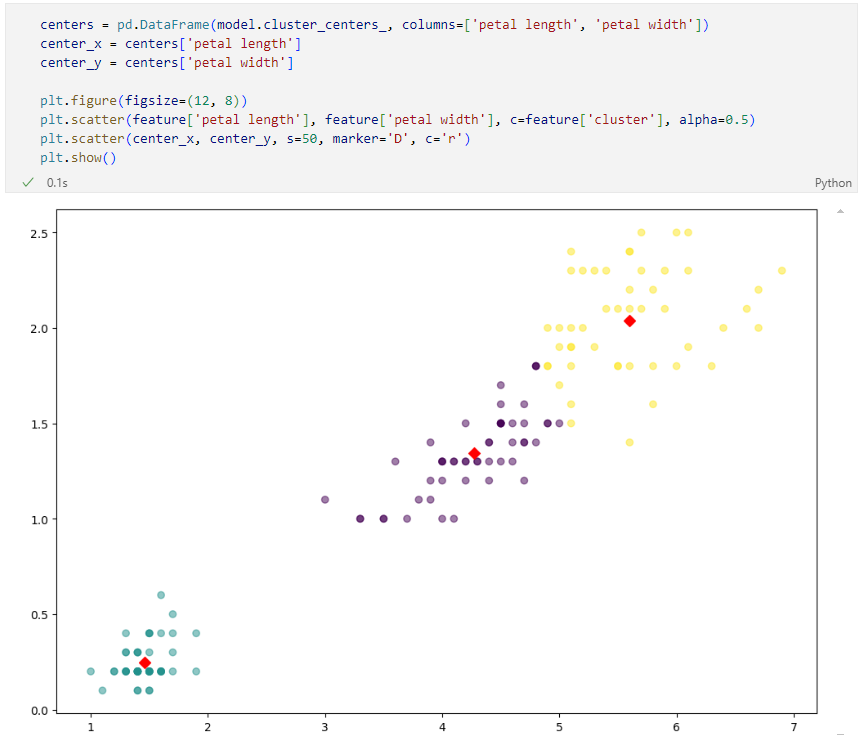
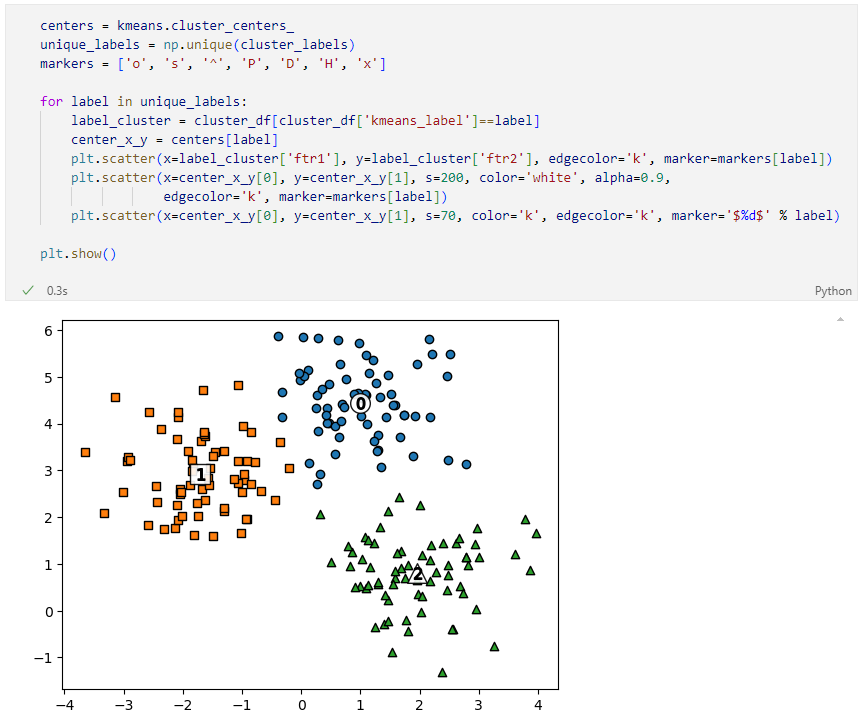
군집 중심값

그래프를 그리기 위한 정리
결과 확인
make_blobs
실습 데이터
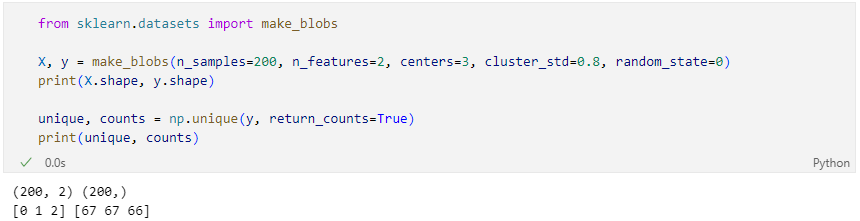
데이터 정리 및 군집화
결과 도식화
결과 확인
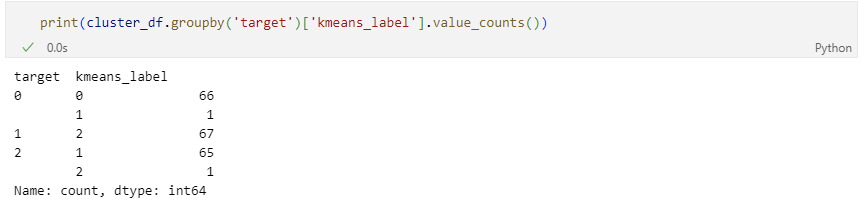
군집 평가
군집 결과의 평가
- 분류기는 평가 기준(정답)을 가지고 있지만, 군집은 그렇지 않다.
- 군집 결과를 평가하기 위해 실루엣 분석을 많이 활용한다.
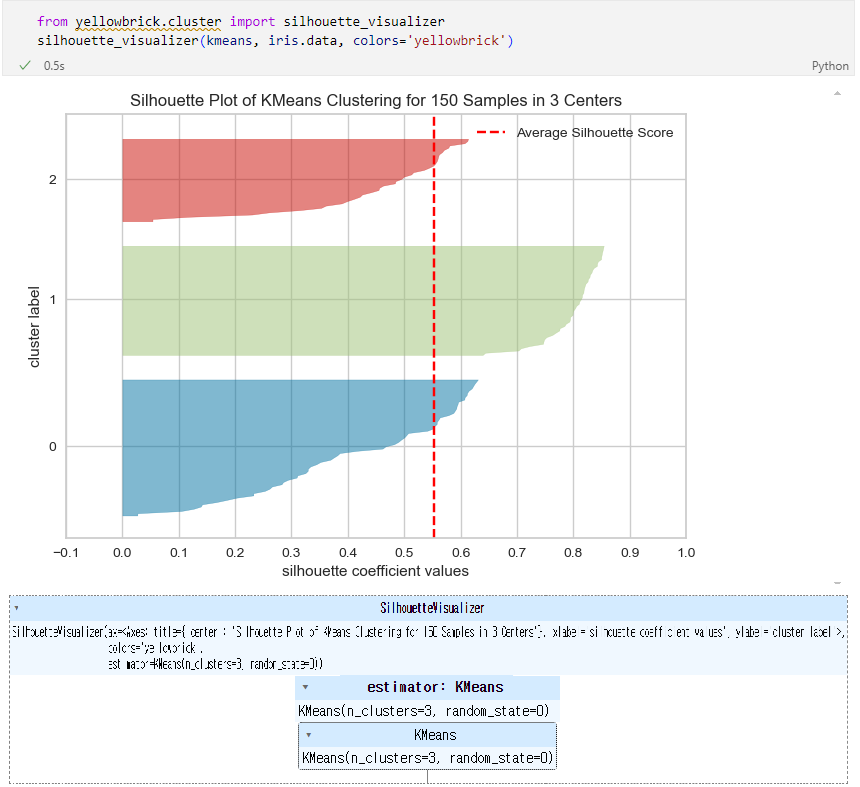
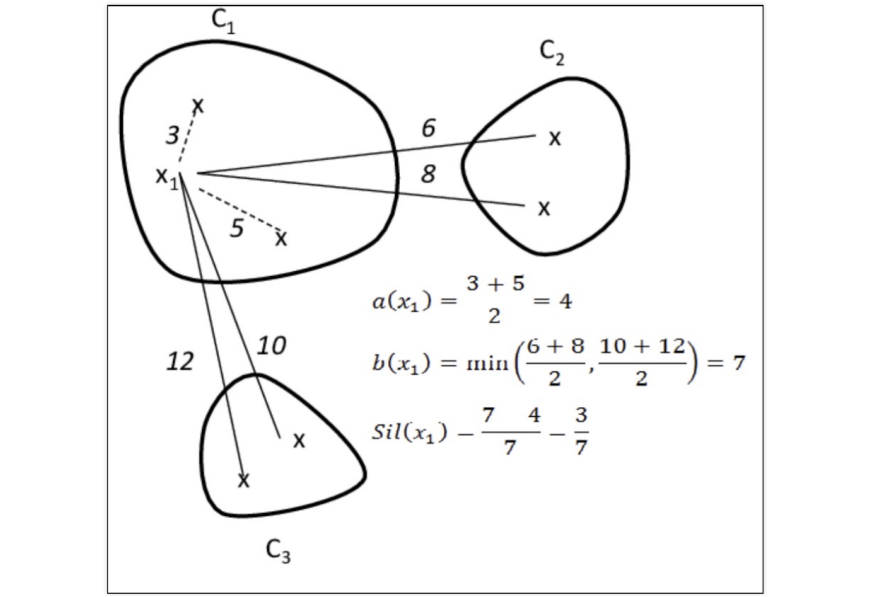
실루엣 분석
- 실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 나타냄
- 다른 군집과는 거리가 떨어져 있고, 동일 군집간의 데이터는 서로 가깝게 잘 뭉쳐 있는지 확인
- 군집화가 잘 되어 있을 수록 개별 군집은 비슷한 정도의 여유공간을 가지고 있음
- 실루엣 계수 : 개별 데이터가 가지는 군집화 지표
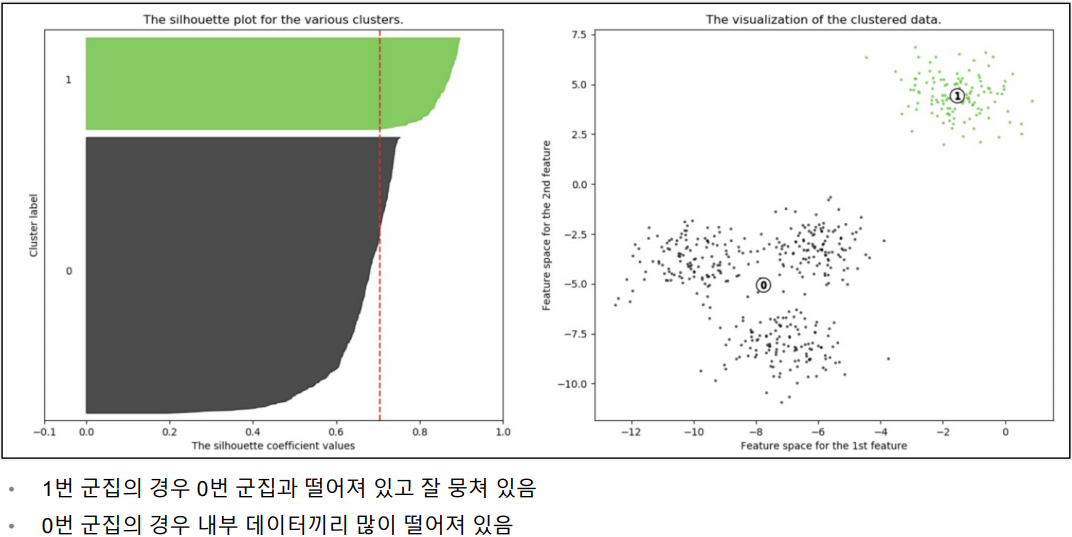
n = 2 인 경우
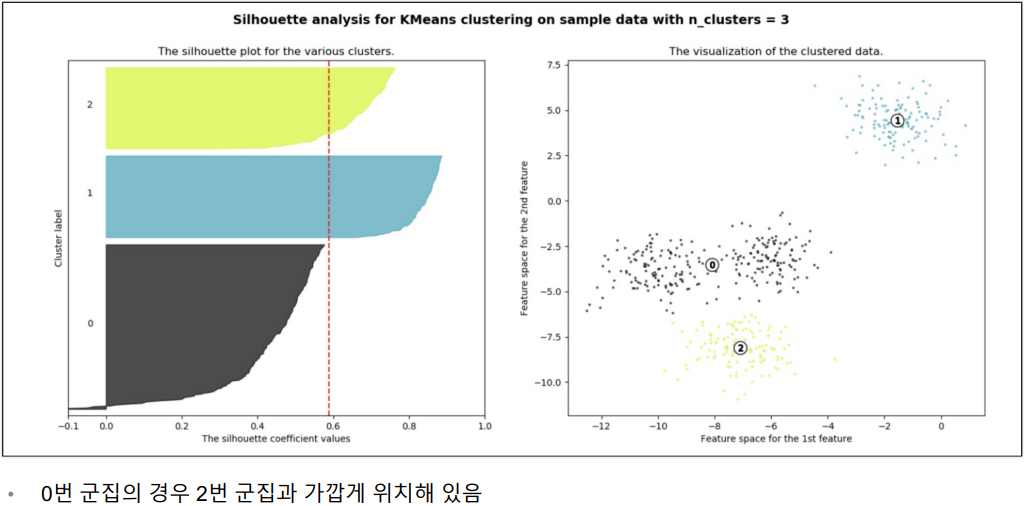
n = 3 인 경우
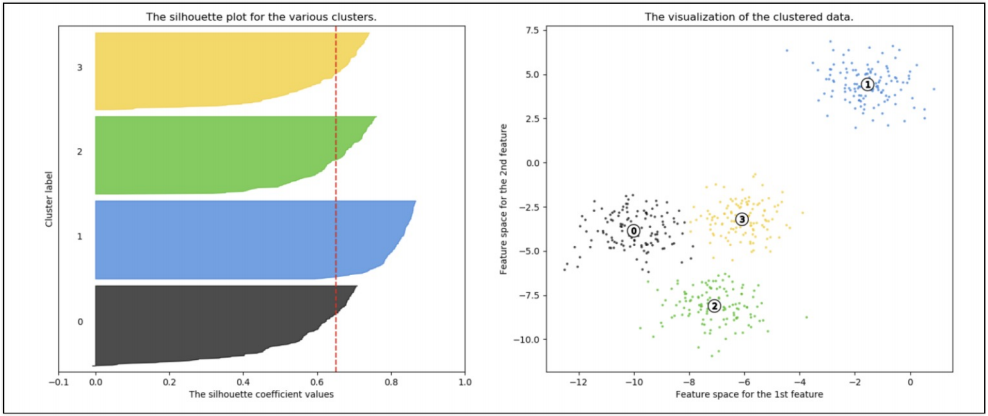
n = 4 인 경우
데이터 읽기

군집 결과 정리
군집 결과 평가

실루엣 플랏의 결과