추천 시스템
요즘은 추천 시스템이 대부분 적용되어 있다.
특히 온라인 쇼핑몰 콘텐츠 등에서는 꽤 중요한 부분을 차지한다.

콘텐츠 기반 필터링 추천 시스템
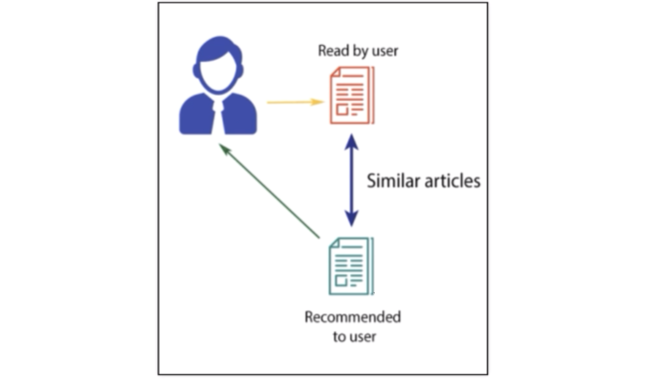
사용자가 특정한 아이템을 선호하는 경우, 그 아이템과 비슷한 아이템을 추천하는 방식
최근접 이웃 협업 필터링
- 축적된 사용자 행동 데이터를 기반으로 사용자가 아직 평가하지 않은 아이템을 예측 평가
- 사용자 기반 : 당신과 비슷한 고객들이 다음 상품도 구매했음
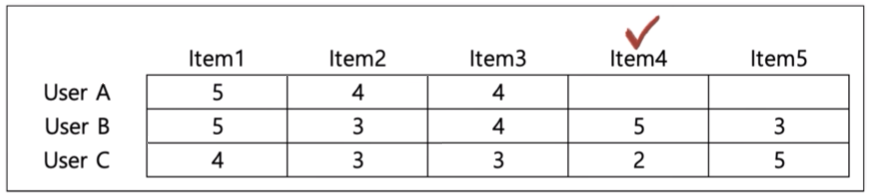
- 아이템 기반 : 이 상품을 선택한 다른 고객들은 다음 상품도 구매했음
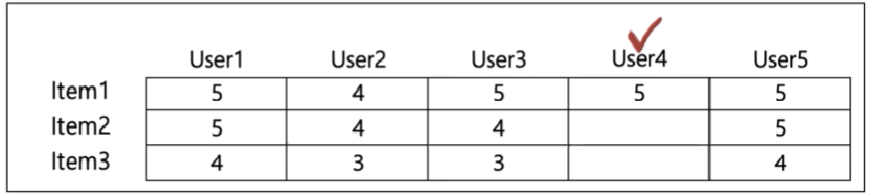
일반적으로 사용자 기반보다는 아이템 기반 협업 필터링이 정확도가 더 놓다.
- 비슷한 영화를 좋아한다고 취향이 비슷하다고 판단하기 어렵다.
- 매우 유명한 영화나 드라마는 취향과 관계없이 관람하는 경우도 있다.
- 사용자들이 평점을 매기지 않는 경우가 많다.
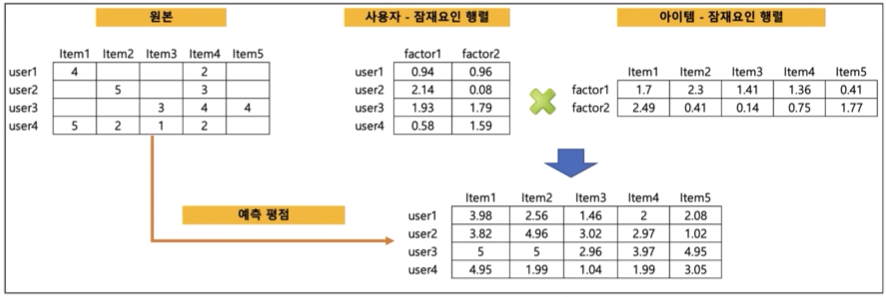
잠재 요인 협업 필터링
- 사용자-아이템 평점 행렬 데이터를 이용해서 '잠재요인'을 도출하는 것
- 주요인과 아이템에 대하여 잠재요인에 대해 행렬 분해를 하고 다시 형렬곱을 통해 아직 평점을 부여하지 않은 아이템에 대한 예측 평점을 생성하는 것
TMDB5000 데이터
콘텐츠 기반 필터링 실습 (TMDB5000 영화 DATASET)
실습 데이터

데이터 선택
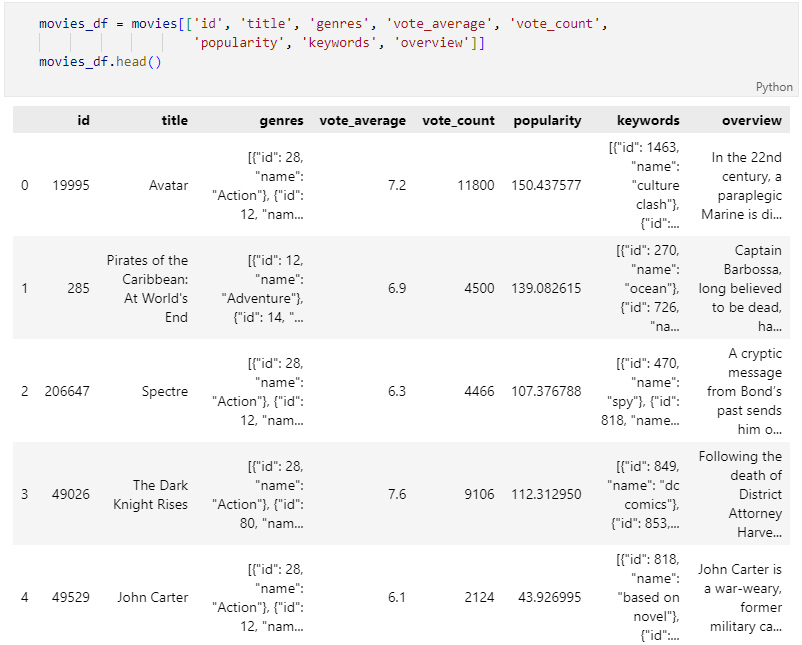
id, title(영화제목), genres(장르), vote_average(평균평점), vota_count(투표수), popularity(인기), keywords(키워드), overview(영화개요)
데이터 주의 사항
genres와 keywords는 컬럼안에 dict형으로 저장됨

genres와 keywords의 내용을 list와 dict로 복구

dict의 value값을 특성으로 사용하도록 변경
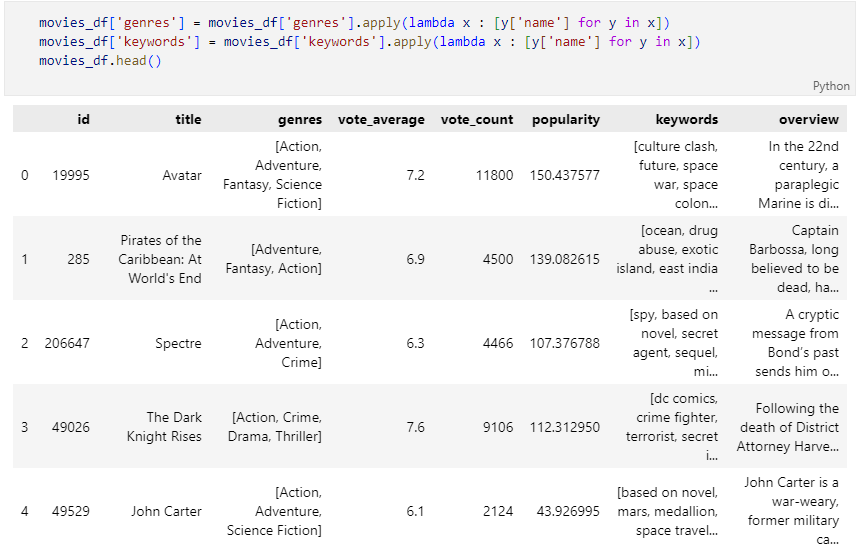
genres의 각 단어들을 하나의 문장으로 변환
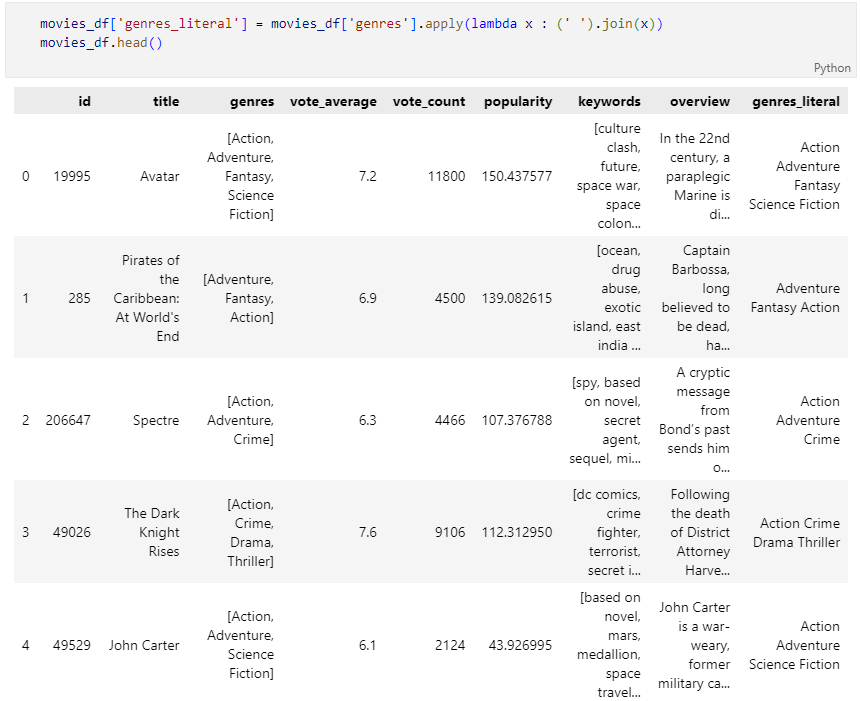
문자열로 변환된 genres를 CountVectorize 수행

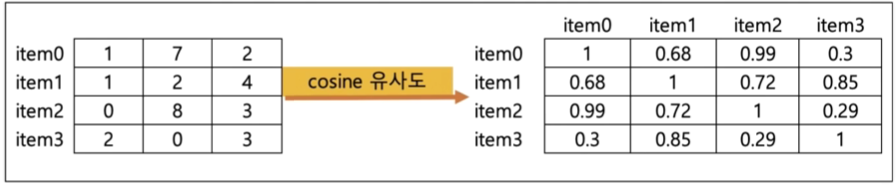
코사인 유사도
코사인 유사도 계산식
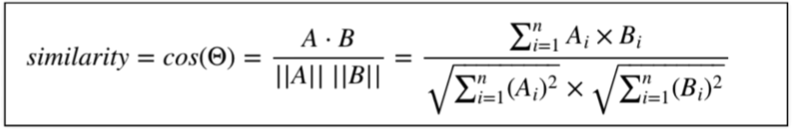
confusion_matrix와 유사하게 해석
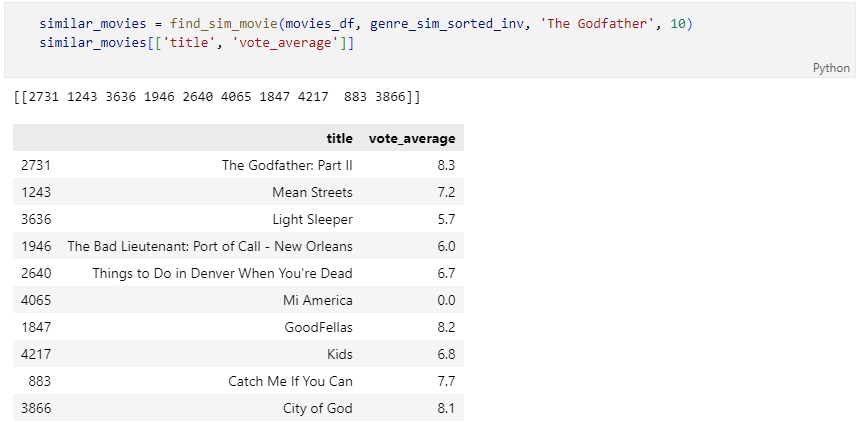
추천 영화를 DataFrame으로 반환하는 함수

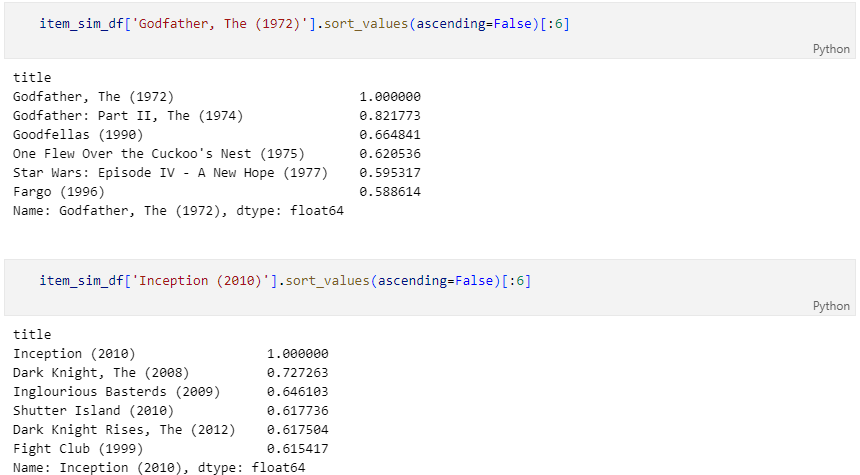
영화 '대부'와 유사한 영화 조회
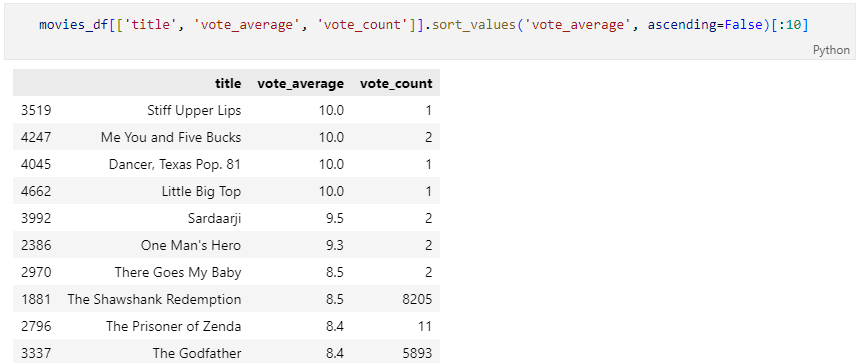
vota_count 컬럼을 추가하여 조회
영화 선정을 위한 가중치 선정
v : 개별 영화에 평점을 투표한 횟수
R : 개별 영화에 대한 평균 평점
m : 평점을 부여하기 위한 최소 투표 횟수
C : 전체 영화에 대한 평균 평점
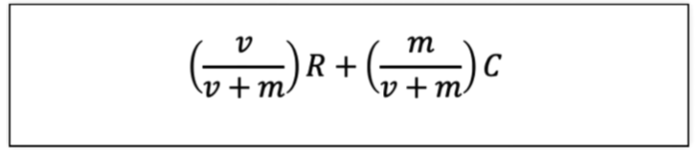
가중치가 부여된 평점을 계산하기 위한 함수
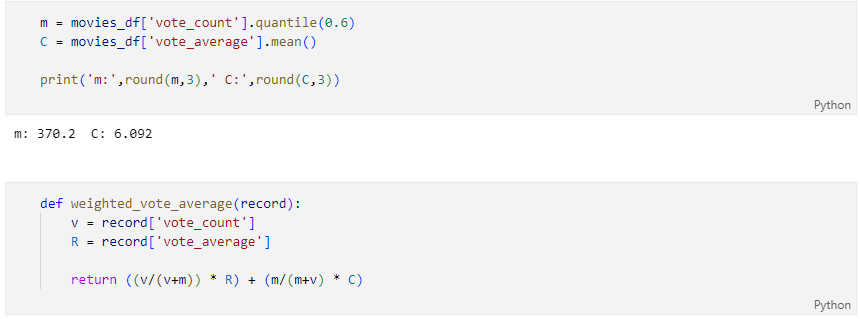
가중치가 부여된 평점을 새로운 컬럼에 추가
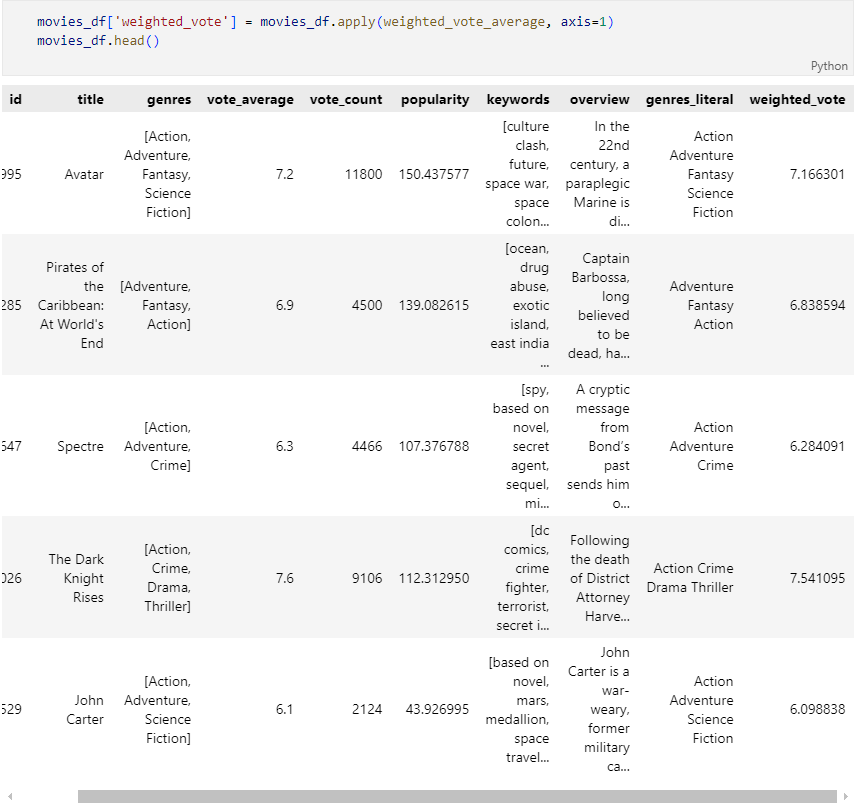
전체 데이터에서 가중치가 부여된 평점 순으로 조회
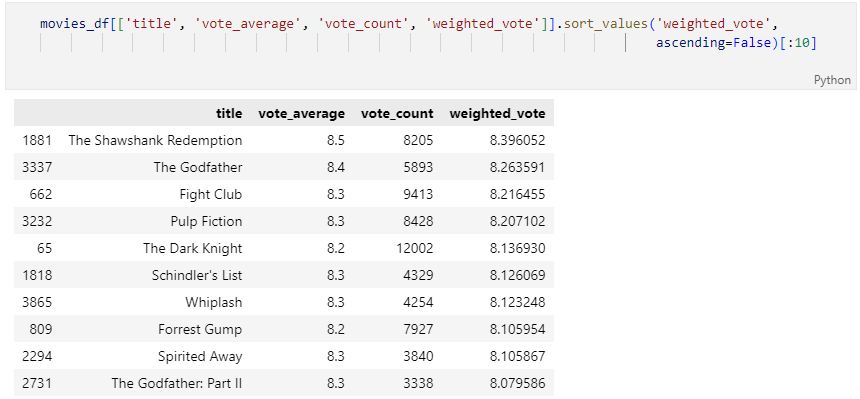
유사 영화를 찾는 함수 수정 후 조회
아이템 기반 최근접 협업 필터링
실습 데이터
영화의 평점을 매긴 사용자와 영화 평점 행렬 등의 데이터
(https://grouplens.org/datasets/movielens/latest/)
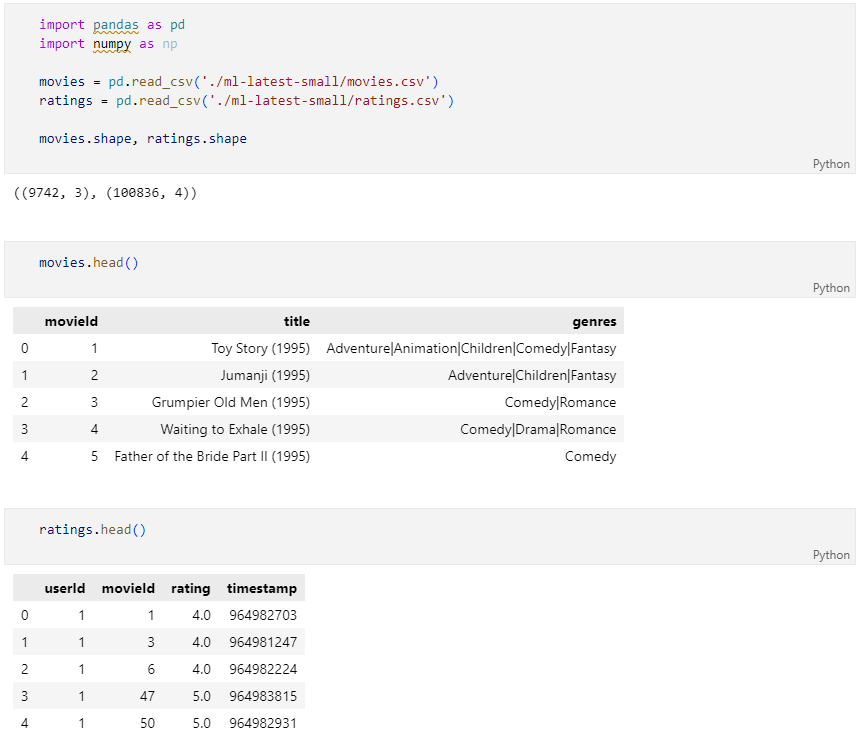
movie & ratings 데이터 조회
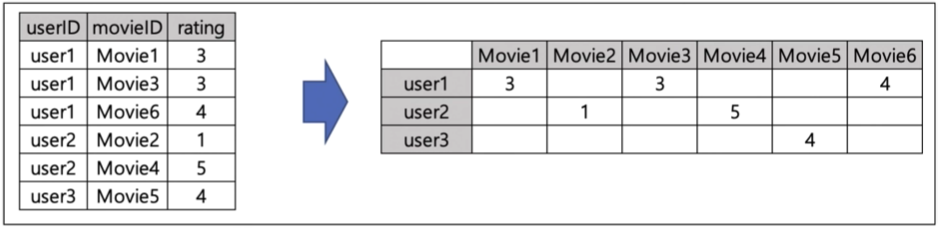
raw 데이터를 정리
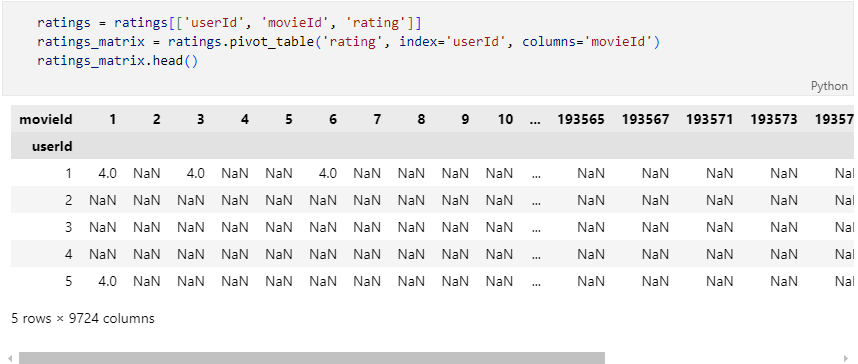
pivot_table
movie와 ratings를 movieID 기준으로 merge 후 pivot_table을 이용하여 정리
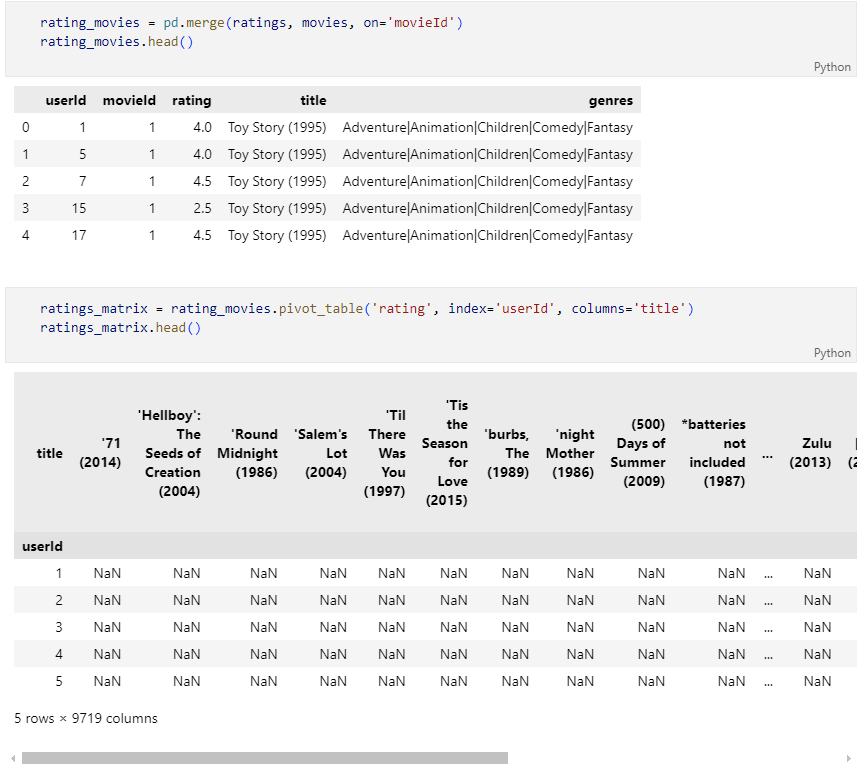
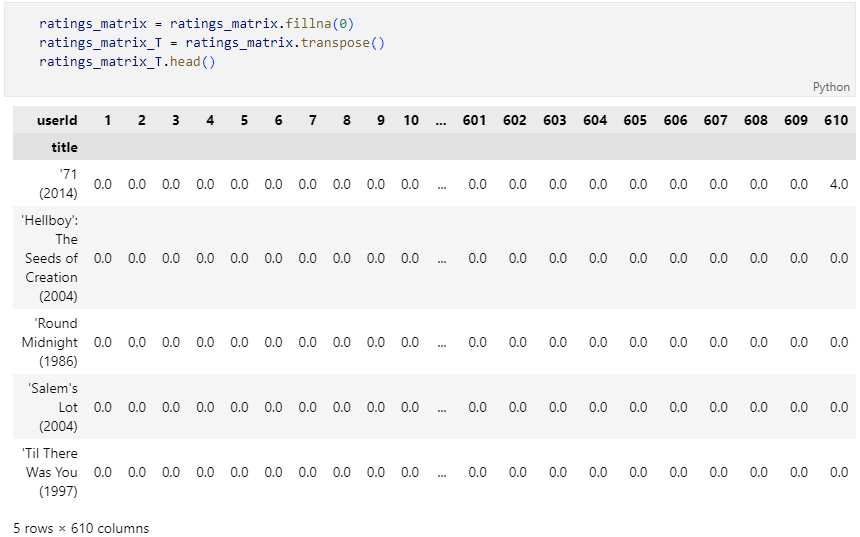
nan값을 0으로 변환 후 유사도 측정을 위해 행렬의 transpose
유사도 측정 결과
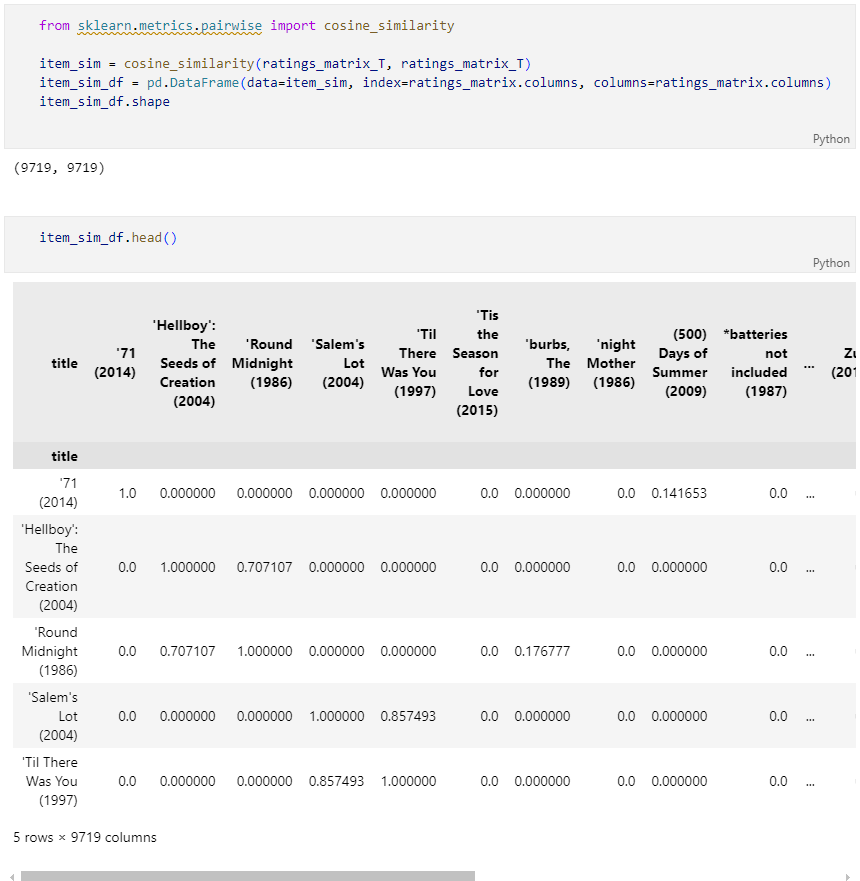
유사한 영화 조회 (ex.대부,인셉션)