
들어가며
이글은 동빈나님의 이코테 강의를 보며 정리한 글입니다. DFS(Depth First Search)는 깊이 우선 탐색입니다. 깊이 우선 탐색 알고리즘은 너비 우선 탐색 알고리즘과 방식만 다를 뿐 한 방식으로 문제가 해결되었다면 다른 방식으로도 문제를 해결할 수도 있습니다.
깊이 우선 탐색의 개념을 먼저 이해해볼까요? 깊이 우선 탐색을 구현하기 위해서는 Stack 자료구조가 사용됩니다. Stack에 대해서 먼저 알아보겠습니다.
Stack 자료구조
Stack은 선형적 자료구조입니다. Stack은 블럭쌓기와 함께 바라볼 수 있습니다. 상자를 겹겹히 쌓았을 때, 가장 먼저 놓은 상자는 가장 아래에 있고, 가장 마지막에 쌓은 상자는 맨 위에 있습니다. 이런 상자들을 다시 내리고 싶다면 가장 위에 쌓인 박스부터 치우는 것이 맞겠죠? Stack도 마찬가지입니다. Stack에 데이터를 삽입(push)하면 Stack에 차곡차곡 쌓이게 됩니다. 그러다가 자료를 삭제(pop)하면 가장 마지막에 들어온 자료가 먼저 삭제됩니다. 이러한 특성을 Last-In-First-Out(LIFO)이라고 합니다.
파이썬에서는 일반적으로 제공되는 List자료형에 자료를 삽입하면 가장 마지막 인덱스에 삽입이 되고, 삭제를 하면 가장 마지막 인덱스의 자료를 삭제하므로 List자료형을 이용해서 쉽게 Stack을 구현할 수 있습니다. 예제로 아래와 같이 나타낼 수 있습니다.
stack = []
stack.append(1) # 1 삽입
# [1]
stack.append(2) # 2 삽입
# [1, 2]
stack.append(3) # 3 삽입
# [1, 2, 3]
stack.pop() # 자료 삭제
# [1, 2]
stack.pop() # 자료 삭제
# [1]
stack.append(4) # 4 삽입
# [1, 4]Depth First Search
DFS 알고리즘은 Stack을 이용하여 깊이를 우선하여 탐색하는 알고리즘입니다. 가장 먼저 탐색이 시작되는 노드가 주어지면, 해당 노드는 Stack에 입력되고, 방문처리됩니다. 방문처리가 완료되면, 해당 노드의 연결된 노드들 중 방문처리가 안되어 있는 노드를 Stack에 입력하고 방문처리를 합니다. 이 과정 중 연결된 노드가 없다면 Stack 자료구조에서 해당 노드를 삭제합니다. 이러한 과정을 반복하면 DFS를 수행할 수 있습니다. 말로만 보게 되면 이해가 어렵죠? 예시를 들어보겠습니다.
하단과 같은 그래프가 있다고 하겠습니다. 이 그래프에서는 가장 먼저 방문이 시작되는 노드는 1입니다.
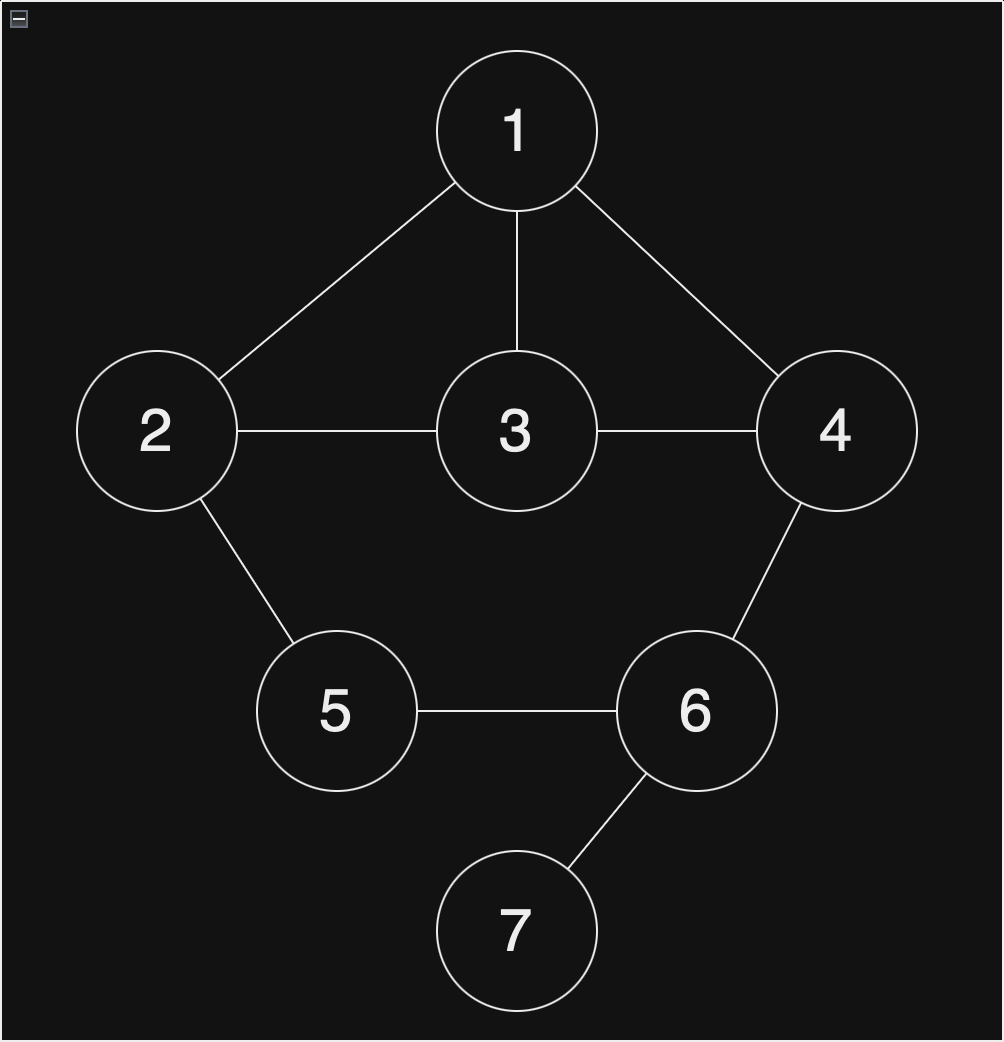
현재 스택 : []
노드 1이 시작이기 때문에 노드 1을 Stack에 입력하고 방문처리를 하게 됩니다.
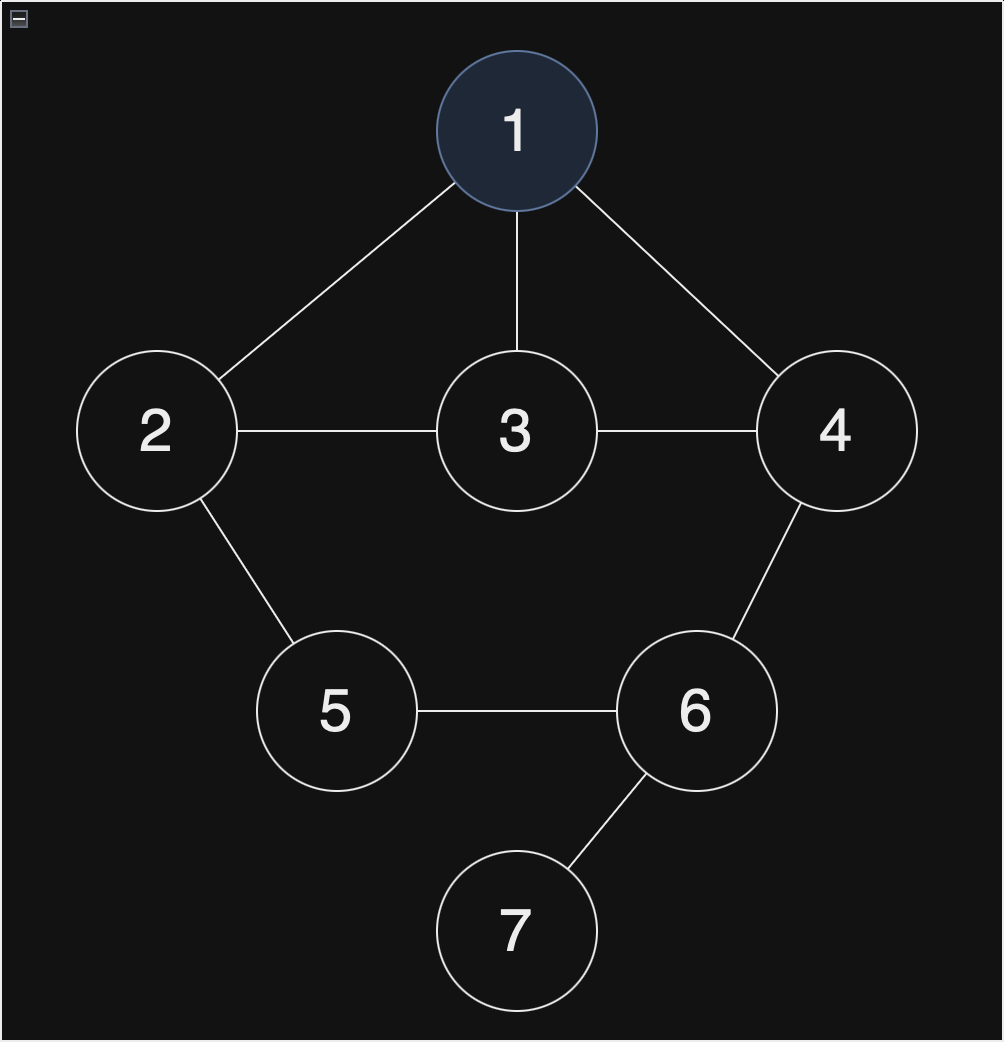
현재 스택 : [1]
이제 노드 1에 대한 처리는 끝났습니다. 1에 연결된 노드 중 가장 작은 수인 노드 2를 Stack에 입력하고 방문처리합니다.
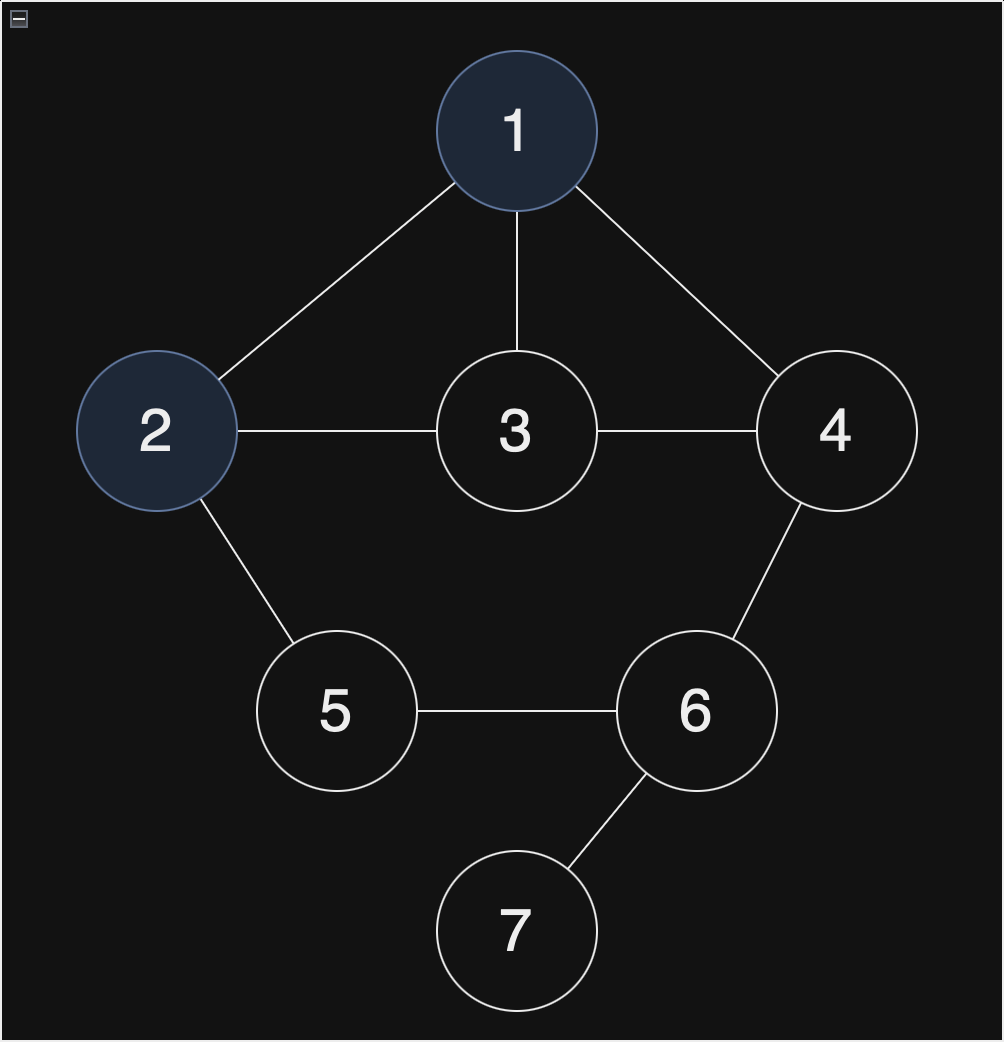
현재 스택 : [1, 2]
노드 2에 대한 처리는 끝났습니다. 2에 연결된 노드가 5밖에 없으므로 노드 5를 Stack에 입력하고 방문처리합니다.
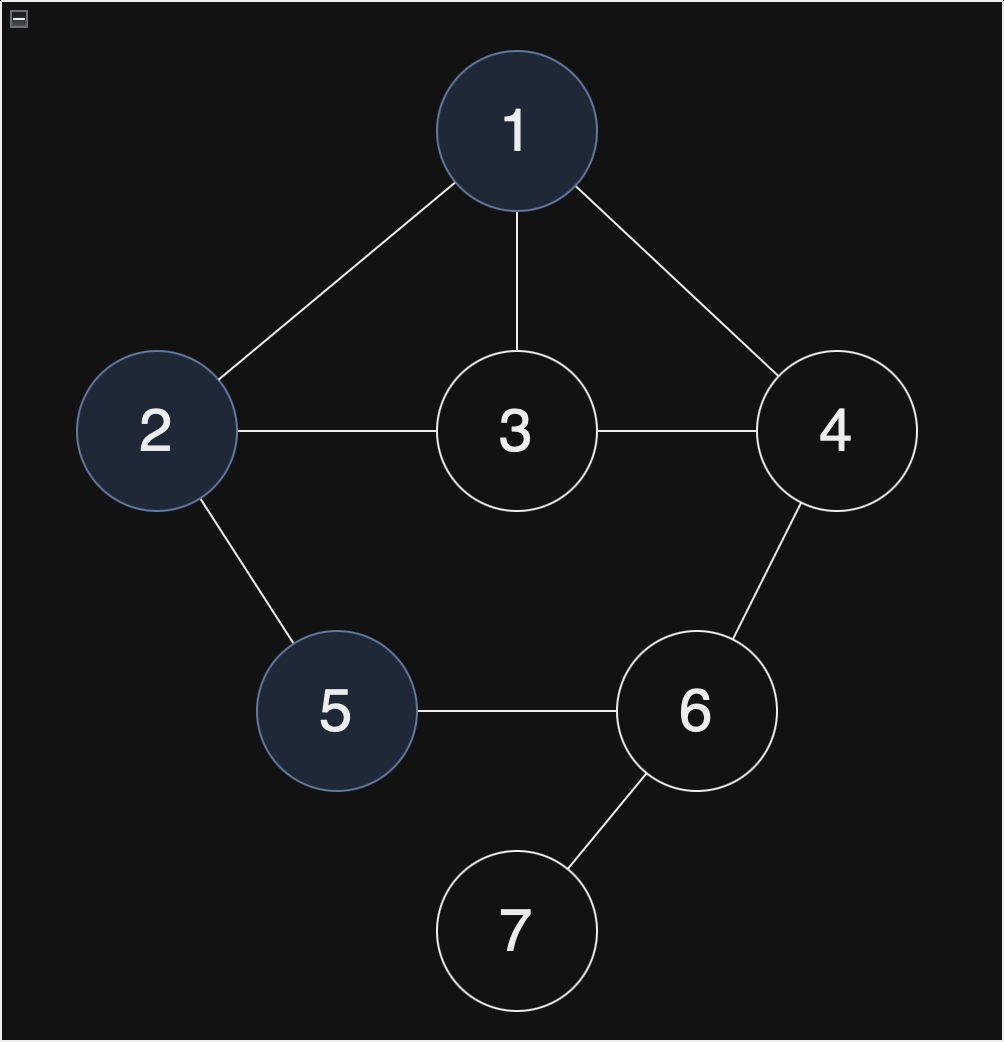
현재 스택 : [1, 2, 5]
노드 6도 동일한 과정으로 처리하고 노드 7까지 처리됩니다.
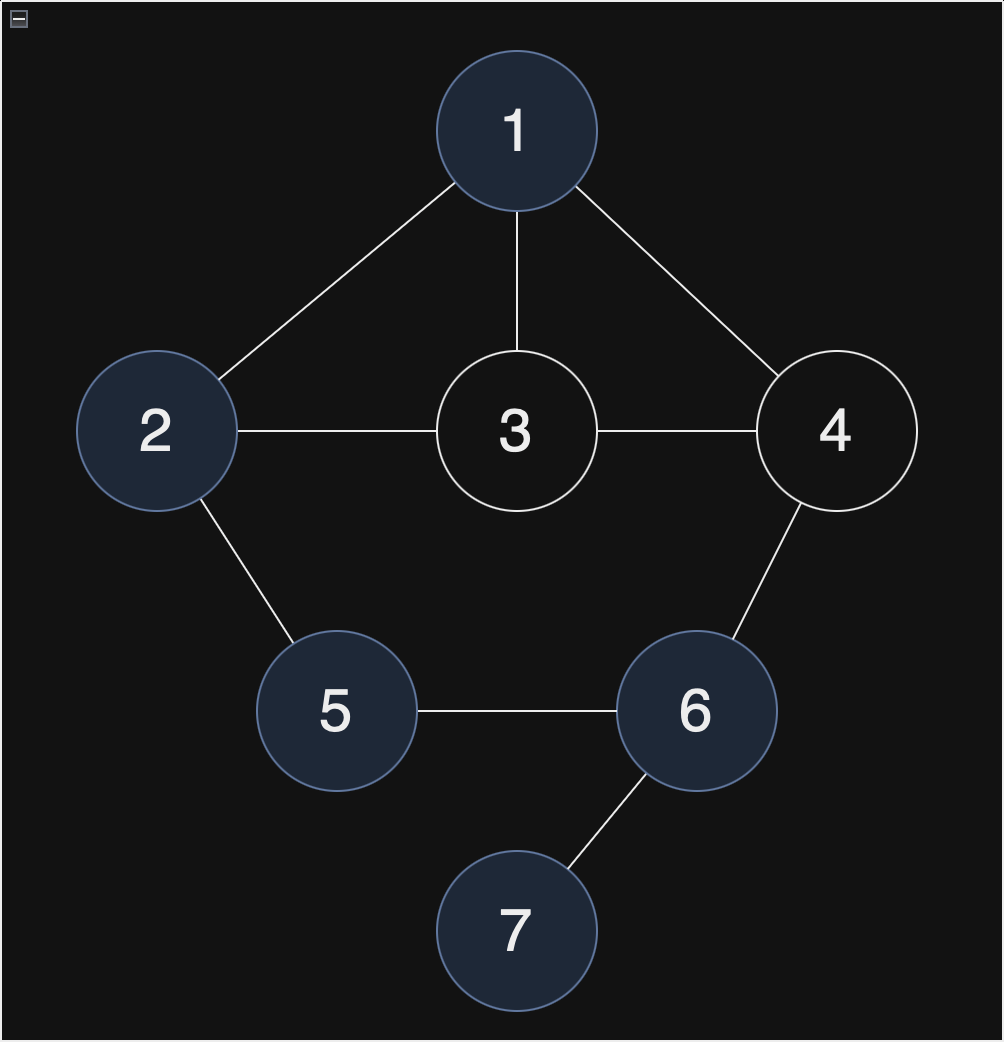
현재 스택 : [1, 2, 5, 6, 7]
이제 노드 7에서는 연결된 노드가 없습니다. 따라서, Stack에서 맨 마지막 7을 삭제하고, 노드 6으로 이동합니다. 노드 6과 연결된 노드 4를 스택에 입력합니다.
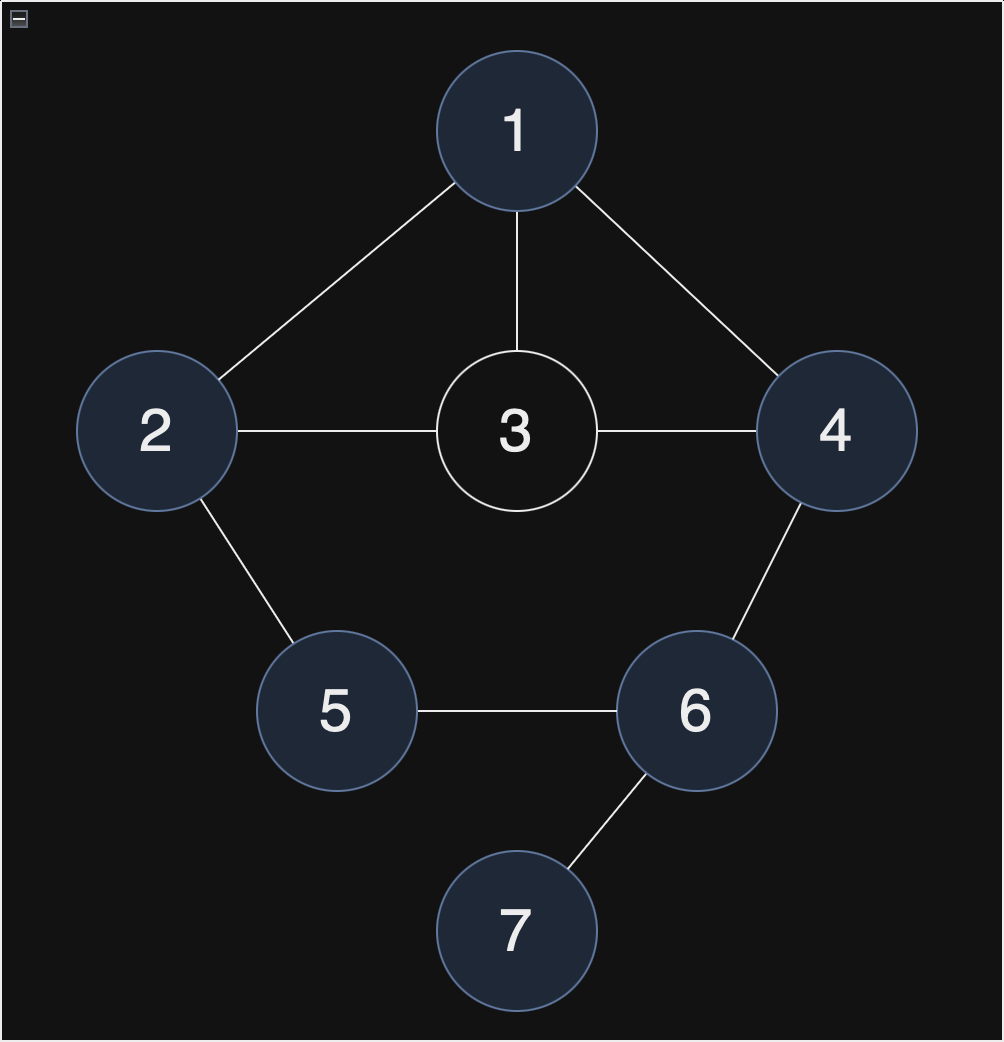
현재 스택 : [1, 2, 5, 6, 4]
이제 마지막입니다. 노드 4와 연결되어 있고, 아직 방문하지 않은 노드 3을 스택에 넣고 방문처리합니다.
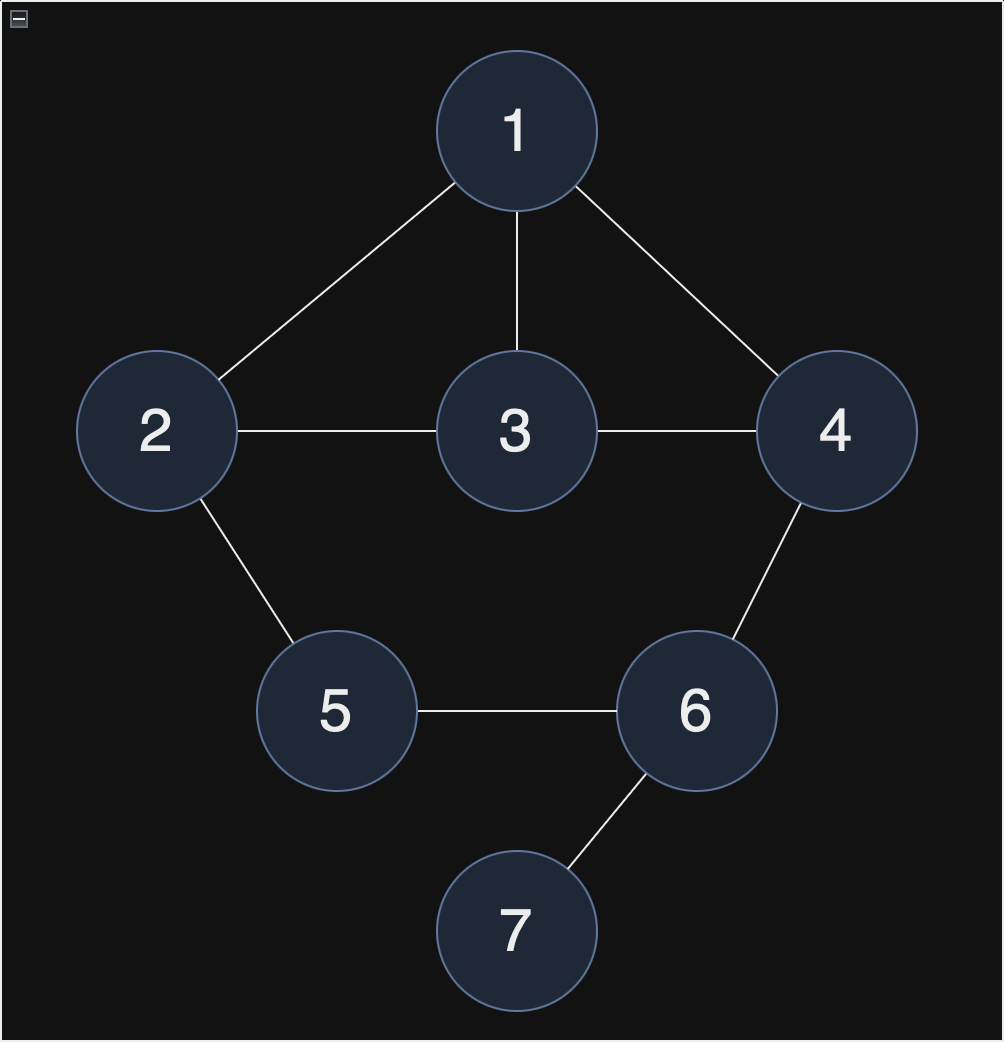
현재 스택 : [1, 2, 5, 6, 4, 3]
이로써 DFS알고리즘을 통해 모든 노드를 방문했습니다.
python에서는 재귀함수를 통해 해당 노드를 방문하지 않았다면 다시 해당 노드에 대한 dfs를 수행하도록 프로그래밍할 수 있습니다. 하단은 python으로 구현한 위의 예제입니다.
# 각 노드의 연결 노드 정보
graph = [
[],
[2, 3, 4],
[1, 5],
[1, 2, 4],
[1, 3, 6],
[2, 6],
[5, 7, 4],
[6],
]
visited = [False]*8
def dfs(graph, v, visited):
# 방문 처리
visited[v] = True
# 방문 노드 출력
print(v, end=' ')
# 연결된 노드 탐색
for i in graph[v]:
# 방문하지 않은 노드가 있다면 재귀함수 호출
if not visited[i]:
dfs(graph, v, visited)
# DFS 수행
dfs(graph, 1, visited)그래프는 각 노드가 연결된 연결정보를 갖고 있습니다. 여기서 0번 인덱스는 그냥 빈 배열로 처리되었습니다. 0번 인덱스를 활용하는 것보단 1번부터 사용하고 0번 인덱스를 사용하지 않는방법이 실수를 줄일 수 있습니다.
6번 노드에 대해서 7번 노드를 먼저 방문해야 하므로 방문 노드 정보를 5, 7, 4로 설정했습니다. 실제로 DFS를 수행하는 경우는 다차원 배열이기 때문에 임의로 설정할 필요는 없습니다.
해당 코드를 실행하면 1, 2, 5, 6, 7, 4, 3이 출력됩니다.

개발자로서 성장하는 데 큰 도움이 된 글이었습니다. 감사합니다.