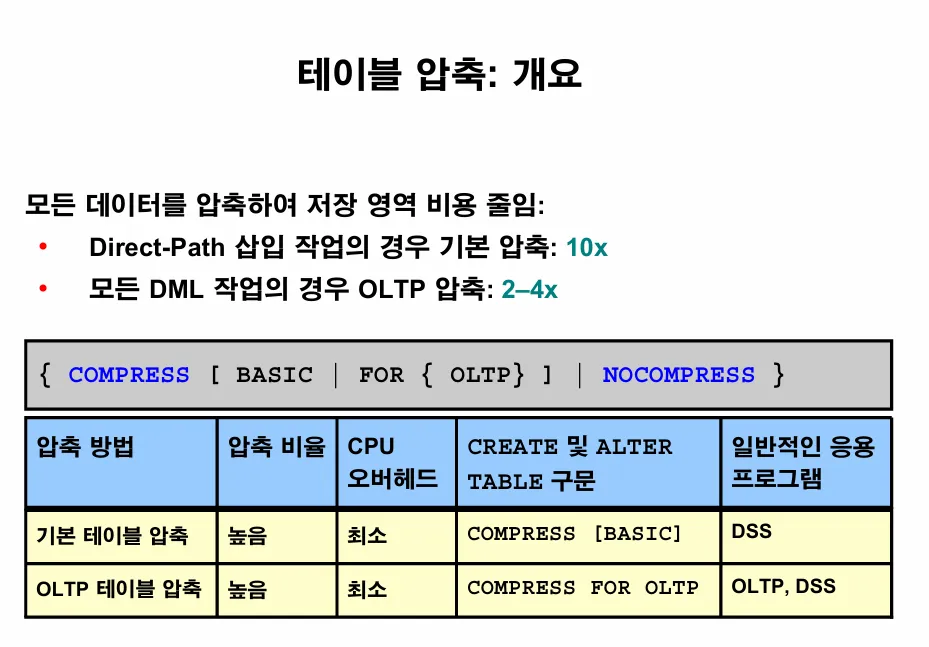
💡 테이블을 압축하는 이유
저장공간을 절약하기 위해서
윈도우에서 압축 프로그램으로 압축을 하는 것은 파일의 압축을 풀어야 내용을 볼 수 있는데
오라클의 압축 테이블은 압축을 풀지 않아도 select 할 수 있음
--> 대신 insert 작업이 느려짐
--> 그래서 주로 쿼리 위주의 변경이 필요없는 히스토리성 데이터들을 담은 테이블을 압축함
💡 압축하는 방법
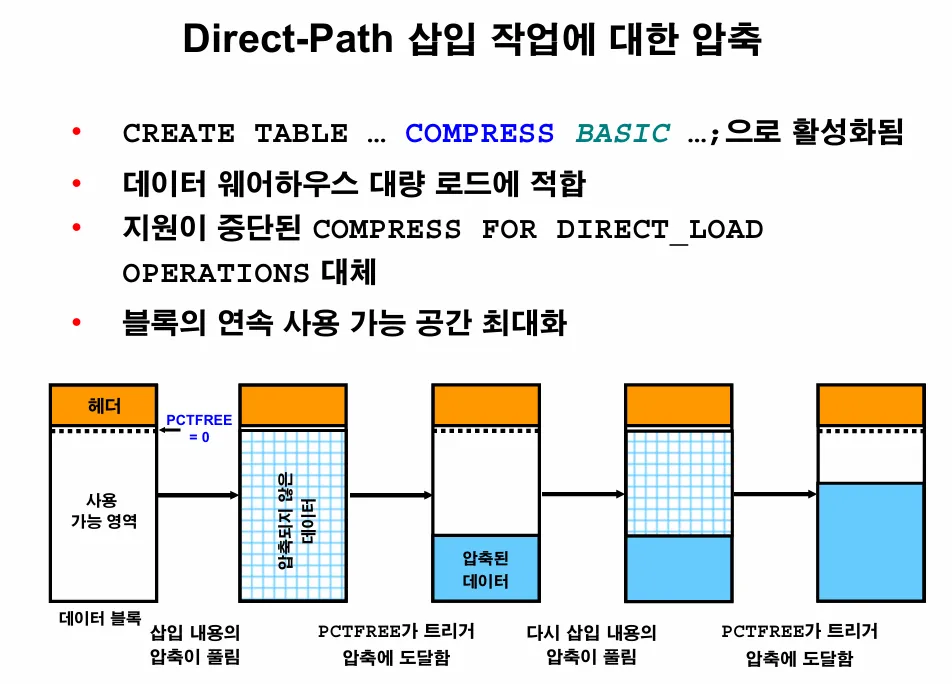
그림 설명:
테이블에 insert를 하면 블럭의 pct free 영역 아래에 데이터가 입력되는데
입력되는 데이터가 pct free에 도달하면 data를 압축함
(계속 저장공간을 확보함)
📌 오라클 압축 방법 2가지
1. basic table compression
insert 시 테이블 압축이 시작되는데
HWM 위에 입력하는 insert문에 대해서만 압축이 수행됨
insert into emp01(empno, ename, sal)
values(1111,'aaa', 3000); -------> 압축 x
insert /*+ append */ into emp01 -------> 압축 o
select *
from emp; 2. oltp table compression
insert 시 테이블이 압축되는데
아래 2개의 insert 문장 모두 압축해주는 기술
1. HWM 아래에 입력하는 insert
insert into emp01(empno, ename, sa) -------> 압축 o
values( 1111,'aaa', 3000);
2. HWM 위에 입력하는 insert -------> 압축 o
insert /*+ append */ into emp01
select *
from emp;💡 압축의 원리
scott analyst 3000 20 5000 10 dallas
allen analyst 3000 20 5000 10 dallas
ford analyst 3000 20 5000 10 dallas
king analyst 3000 20 5000 10 dallas
jones analyst 3000 20 5000 10 dallas
↓ 압축
analyst 3000 20 5000 10 dallas 를 . (점) 하나로 표시
scott . allen . ford . king . jones . 💡 압축 테이블의 장단점
- 장점: 공간이 확보됨
- 단점: insert 속도가 느려짐
[실습1] 압축 테이블 실습 (압축 테이블의 장점을 확인하는 실습)
alter session set nls_Date_format='RR/MM/DD';
drop table emp;
drop table dept;
CREATE TABLE DEPT
(DEPTNO number(10),
DNAME VARCHAR2(14),
LOC VARCHAR2(13) );
INSERT INTO DEPT VALUES (10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO DEPT VALUES (20, 'RESEARCH', 'DALLAS');
INSERT INTO DEPT VALUES (30, 'SALES', 'CHICAGO');
INSERT INTO DEPT VALUES (40, 'OPERATIONS', 'BOSTON');
CREATE TABLE EMP (
EMPNO NUMBER(4) NOT NULL,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4) ,
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2) );
INSERT INTO EMP VALUES (7839,'KING','PRESIDENT',NULL,'81-11-17',5000,NULL,10);
INSERT INTO EMP VALUES (7698,'BLAKE','MANAGER',7839,'81-05-01',2850,NULL,30);
INSERT INTO EMP VALUES (7782,'CLARK','MANAGER',7839,'81-05-09',2450,NULL,10);
INSERT INTO EMP VALUES (7566,'JONES','MANAGER',7839,'81-04-01',2975,NULL,20);
INSERT INTO EMP VALUES (7654,'MARTIN','SALESMAN',7698,'81-09-10',1250,1400,30);
INSERT INTO EMP VALUES (7499,'ALLEN','SALESMAN',7698,'81-02-11',1600,300,30);
INSERT INTO EMP VALUES (7844,'TURNER','SALESMAN',7698,'81-08-21',1500,0,30);
INSERT INTO EMP VALUES (7900,'JAMES','CLERK',7698,'81-12-11',950,NULL,30);
INSERT INTO EMP VALUES (7521,'WARD','SALESMAN',7698,'81-02-23',1250,500,30);
INSERT INTO EMP VALUES (7902,'FORD','ANALYST',7566,'81-12-11',3000,NULL,20);
INSERT INTO EMP VALUES (7369,'SMITH','CLERK',7902,'80-12-09',800,NULL,20);
INSERT INTO EMP VALUES (7788,'SCOTT','ANALYST',7566,'82-12-22',3000,NULL,20);
INSERT INTO EMP VALUES (7876,'ADAMS','CLERK',7788,'83-01-15',1100,NULL,20);
INSERT INTO EMP VALUES (7934,'MILLER','CLERK',7782,'82-01-11',1300,NULL,10);
commit;
select count(*) from emp;
-- 1. 압축되지 않는 테이블 생성
create table normal
as
select * from emp;
select * from normal;
-- 2. 압축된 테이블을 생성한다 (basic)
create table basic
compress
as
select * from emp;
select * from basic;
-- 3. 압축된 테이블을 생성한다 (oltp)
create table oltp
compress for all operations
as
select * from emp;
select * from oltp;
-- 4. 위의 3개의 테이블에 아래의 insert 작업을 시도한다. (10번 수행)
insert /*+ append */ into normal
select *
from normal;
commit;
insert /*+ append */ into basic
select *
from basic;
commit;
insert /*+ append */ into oltp
select *
from oltp;
commit;
-- 중요: 실행할 영역을 드레그하고 ctl + l 을 누룹니다.
-- 5. 3개의 테이블의 건수를 확인한다.
select count(*) from normal;
select count(*) from basic;
select count(*) from oltp;
-- 6. 압축이 잘되어서 공간절약이 되고있는지 비교하시오 !
select count(distinct dbms_rowid.rowid_block_number(rowid) ) as blocks
from normal;
select count(distinct dbms_rowid.rowid_block_number(rowid) ) as blocks
from basic;
select count(distinct dbms_rowid.rowid_block_number(rowid) ) as blocks
from oltp;
-- 일반 테이블에 비해서 7배나 공간이 절약되고 있습니다.문제1. 12c 버젼에서 압축 테이블 관련한 새로운 기능(뉴피쳐)를 실험하시오
create table oltp_advanced
row store compress advanced
as
select * from emp;
설명: row store compress advanced 로 문법이 바뀌면서 oltp 성 테이블에 조금 더
적당하게 DML 작업 속도를 더 원활하게 하면서 압축을 하는 기능이 강화되었습니다.
압축할 때 발생하는 오버헤드를 최소화 했습니다. (OCP 시험문제)
--- 1. 테이블 3개를 만듭니다.
create table dept_normal
as
select * from dept;
create table dept_basic
compress
as
select * from dept;
create table dept_oltp_advanced
row store compress advanced
as
select * from dept;
-- 2. 위의 3개의 테이블에 아래의 insert 작업을 시도한다. (10번 수행)
insert /*+ append */ into dept_normal
select *
from dept_normal;
commit;
insert /*+ append */ into dept_basic
select *
from dept_basic;
commit;
insert /*+ append */ into dept_oltp_advanced
select *
from dept_oltp_advanced;
commit;
-- 중요: 실행할 영역을 드레그하고 ctl + l 을 누룹니다.
-- 5. 3개의 테이블의 건수를 확인한다.
select count(*) from dept_normal;
select count(*) from dept_basic;
select count(*) from dept_oltp_advanced;
-- 6. 압축이 잘되어서 공간절약이 되고있는지 비교하시오 !
select count(distinct dbms_rowid.rowid_block_number(rowid) ) as blocks
from dept_normal;
select count(distinct dbms_rowid.rowid_block_number(rowid) ) as blocks
from dept_basic;
select count(distinct dbms_rowid.rowid_block_number(rowid) ) as blocks
from dept_oltp_advanced;