주요 리스트 함수 정리표
| 문법 | 설명 |
|---|---|
| 리스트[시작번호:끝번호] | 리스트의 시작번호 이상부터 끝번호 미만 |
| 리스트[시작번호:] | 리스트의 시작번호부터 끝까지 |
| 리스트[:끝번호] | 리스트의 처음부터 끝번호 미만까지 |
| '구분자'.join(리스트) | 리스트의 요소들을 구분자로 구분해서 출력 |
| 리스트.append(요소명) | 리스트 마지막에 요소명을 추가 |
| 리스트.insert(번호, 요소명) | 리스트의 특정 인덱스 번호에 요소명을 추가 |
| 리스트.extend(요소명들) | 리스트에 여러 개의 요소들을 추가 |
| 리스트.sort() | 리스트의 요소들을 실제로 정렬시킴 |
| sorted(리스트) | 리스트의 요소들을 정렬된 상태로 출력 |
| 리스트.reverse() | 리스트의 요소들을 실제로 역순으로 정렬시킴 |
| reversed(리스트) | 리스트의 요소들을 역순으로 정렬된 상태로 출력 |
| 리스트.count('요소명') | 리스트의 특정 요소명이 몇 건이 존재하는지 출력 |
| 리스트.index('요소명') | 리스트의 특정 요소명의 자리번호(인덱스번호)를 출력 |
| 리스트.remove('요소명') | 리스트의 요소를 요소명으로 삭제 |
| del 리스트[인덱스번호] | 리스트의 요소를 인덱스 번호로 삭제 |
| 리스트.clear() | 리스트의 모든 요소들을 삭제 |
| len(리스트) | 리스트의 요소의 개수를 출력 |
| sum(리스트) | 숫자로 되어있는 리스트의 요소들의 합을 출력 |
| map(함수, 리스트) | 리스트의 요소들의 값들을 순서대로 함수에 대입 |
| filter(함수, 리스트) | 리스트의 요소들을 함수에 적용하여 데이터를 추려냄 |
| zip(리스트1, 리스트2) | 리스트1과 리스트2의 요소들을 순서에 따라 짝지어줌 |
| enumerate(리스트) | 리스트의 요소들을 인덱스 번호와 함께 짝지어줌 |
✔️ 예제83_1. 리스트 슬라이싱
리스트에서 특정 요소들을 추출할 때 사용
예제1. 기본 슬라이싱
다음 a 리스트에서 '바위'를 잘라내서 출력하시오
a = ['낙', '숫', '물', '이', '바', '위', '를', '뚫', '는', '다']
print(a[4:6]) # ['바', '위']문제1. 끝부분 슬라이싱
아래의 a 리스트에서 '뚫는다'를 잘라내시오
a = ['낙', '숫', '물', '이', '바', '위', '를', '뚫', '는', '다']
print(a[-3:]) # ['뚫', '는', '다']✔️ 예제83_2. append 함수
리스트 변수에 맨 끝의 요소로 값을 추가할 때 사용
기본 사용법
a = [1000, 2000, 3000, 4000]
a.append(5000)
print(a)
# [1000, 2000, 3000, 4000, 5000]예제1. 짝수 데이터 추출
아래의 a 리스트에서 짝수 데이터만 b 리스트에 담아내고 출력하시오
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
b = [] # 비어있는 b 리스트를 생성
for i in a:
if i % 2 == 0:
b.append(i)
print(b)문제2. 문자열 정제
아래의 a 리스트의 데이터를 정제해서 b 리스트에 담고 출력하시오
a = ['1.끝내주게 숨쉬기.', '2.간지나게 자기!', '3.작살나게 밥먹기?']
b = []
for i in a:
b.append(i.strip('123.!?'))
print(b)
# ['끝내주게 숨쉬기', '간지나게 자기', '작살나게 밥먹기']문제3. 조건에 맞는 데이터 필터링
아래의 리스트에서 '정상품'만 b 리스트에 담아서 출력하시오
a = ['정상품', '정상품', '불량품', '정상품', '불량품', '정상품', '정상품', '불량품']
b = []
for i in a:
if i == '정상품':
b.append(i)
print(b)
# ['정상품', '정상품', '정상품', '정상품', '정상품']문제4. 문자열 길이 조건
아래의 리스트에서 철자가 3개 이상인 단어만 b 리스트에 담아서 출력하시오
items = ['사과', '연필', '바나나', '지우개', '딸기', '볼펜', '키위', '자', '오렌지']
b = []
for i in items:
if len(i) >= 3:
b.append(i)
print(b)
# ['바나나', '지우개', '오렌지']len(): 문자열 길이
⭐ 문제5. 성적 분석 (예상문제)
아래의 성적 리스트에서 80점 이상인 점수만 high_scores 리스트에 담아 출력하고 평균값을 계산하시오
scores = [65, 78, 92, 83, 45, 95, 72, 88, 61, 84]
high_scores = []
for i in scores:
if i >= 80:
high_scores.append(i)
print(high_scores)
print(sum(high_scores)/len(high_scores))
# [92, 83, 95, 88, 84]
# 88.4문제6. 코딩 테스트 문제1
1부터 100까지의 숫자중에서 짝수 숫자들의 평균값을 출력하시오
b = []
for i in range(1, 101):
if i % 2 == 0:
b.append(i)
print(sum(b)/len(b)) # 51.0
# 또는
import numpy as np
print(np.mean(b)) # 51.0mean(): 평균값
import numpy as np
print(np.mean(b)) # 평균값
print(np.sum(b)) # 총합
print(np.max(b)) # 최댓값
print(np.min(b)) # 최솟값✔️ 예제. insert, extend 함수
🔸리스트에 요소값 추가하는 3가지 함수
append: 리스트 마지막에 요소명을 추가insert: 리스트에 특정 위치에 요소를 추가extend: 리스트에 여러개의 요소들을 한번에 추가
예제1. append 사용법
dice = [1, 2, 3, 4, 5]
dice.append(6)
print(dice) # [1, 2, 3, 4, 5, 6]예제2. insert 사용법
변수명.insert(인덱스번호, 요소명)
dice = [1, 2, 3, 5, 6]
dice.insert(3, 4)
print(dice) # [1, 2, 3, 4, 5, 6]문제1. 특정 위치에 삽입
아래의 동전 리스트에 앞면을 추가하시오
coin = ['뒷면']
coin.insert(0, '앞면')
print(coin) # ['앞면', '뒷면']예제3. extend 사용법
a = [1000, 2000, 3000, 4000]
b = [5000, 6000, 7000, 8000]
a.extend(b) # 또는 print(a+b)
print(a)
# [1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000]문제2. 리스트 확장
다음 animals 리스트의 요소로 mammals 요소들을 추가시키시오
animals = ['dog', 'cat']
mammals = ['tiger', 'elephant']
animals.extend(mammals) # 또는 print(animals+mammals)
print(animals)
# ['dog', 'cat', 'tiger', 'elephant']문제3. 앞쪽에 리스트 추가
animals 리스트의 요소로 mammals 요소들을 앞쪽에 추가하시오
animals = ['dog', 'cat']
mammals = ['tiger', 'elephant']
animals = mammals + animals
print(animals)
# ['tiger', 'elephant', 'dog', 'cat']- 📌 리스트 뒤에 리스트를 추가할때는
extend를 사용하고
리스트 앞에 리스트를 추가할때는+를 사용
문제4. 여러 팀 점수 통합
아래의 3개의 리스트에서 80점 넘는 점수만 high_scores 리스트에 담아 출력하세요
team1_scores = [67, 89, 45, 92]
team2_scores = [76, 54, 88, 65]
team3_scores = [82, 91, 73, 79]
high_scores = []
a = team1_scores + team2_scores + team3_scores
for i in a:
if i > 80:
high_scores.append(i)
print(high_scores) # [89, 92, 88, 82, 91]✔️ 예제. 리스트 요소 정렬
🔸정렬 함수의 종류
리스트.sort(): 리스트의 요소들을 실제로 정렬시킴sorted(리스트명): 리스트의 요소들은 그대로 두고 리스트를 정렬된 상태로 출력리스트.reverse(): 리스트의 요소들을 실제로 역순으로 정렬시킴reversed(리스트): 리스트의 요소들은 그대로 두고 리스트의 요소들을 역순으로 정렬된 상태로 출력
예제1. 오름차순 정렬
a = [2000, 1000, 4000, 5000, 3000]
a.sort()
print(a)예제2. 내림차순 정렬
reverse=True: 내림차순 정렬
a = [2000, 1000, 4000, 5000, 3000]
a.sort(reverse=True)
print(a)예제3. sorted 함수 사용
a = [2000, 1000, 4000, 5000, 3000]
print(sorted(a)) # [1000, 2000, 3000, 4000, 5000]
print(a) # [2000, 1000, 4000, 5000, 3000]문제1. 문자열 정렬
아래의 fruits 리스트의 데이터를 정렬해서 fruits2 리스트를 구성하시오
fruits = ['carrot', 'banana', 'lemon', 'apple', 'guaba']
fruits2 = sorted(fruits)
print(fruits2)예제4. reverse 함수
a = [2000, 1000, 4000, 5000, 3000]
a.reverse()
print(a)문제2. 역순 정렬
b = ['하', '중', '상']
b.reverse()
print(b) # ['상', '중', '하']예제5. reversed 함수
아래의 b 리스트의 요소들은 그냥 그대로 두고
역순으로 정렬된 상태로 출력하시오
b = ['하', '중', '상']
b2 = list(reversed(b))
print(b2)✔️ 예제. 리스트 요소 찾기
🔸검색 함수의 종류
리스트.count('요소명'): 리스트안의 요소명의 갯수를 출력리스트.index('요소명'): 리스트안의 요소명의 인덱스 번호 출력
예제1. count 함수
box = ['정상품', '정상품', '정상품', '불량품', '정상품', '불량품']
print(box.count('정상품')) #4
print(box.count('불량품')) #2예제2. index 함수
box 리스트에 불량품의 자리번호를 출력하시오
box = ['정상품', '정상품', '정상품', '불량품', '정상품', '불량품']
print(box.index('불량품')) # 3예제3. enumerate 함수 활용
모든 불량품의 위치를 찾으려면 enumerate 함수를 사용
box = ['정상품', '정상품', '정상품', '불량품', '정상품', '불량품']
for i, item in enumerate(box):
if item == '불량품':
print(i, end=' ') # 3 5문제3. 중복 제거 - set() 함수
shopping_list의 요소를 중복 제거해서 출력하시오
shopping_list = ['우유', '빵', '사과', '바나나', '초콜릿', '치즈', '사과', '오렌지', '빵', '계란']
set(shopping_list) # {'계란', '바나나', '빵', '사과', '오렌지', '우유', '초콜릿', '치즈'}
list(set(shopping_list)) # ['우유', '사과', '치즈', '바나나', '빵', '초콜릿', '계란', '오렌지']
set(shopping_list)
list(set(shopping_list))⭐문제4. 품목별 수량 계산 (코딩 테스트 문제) - 예상문제2
Counter() 함수
# 문제4. 품목별 수량 계산 (코딩 테스트 문제) # 이수자 평가 예상문제2
shopping_list = ['우유', '빵', '사과', '바나나', '초콜릿', '치즈', '사과', '오렌지', '빵', '계란']
from collections import Counter # from 패키지 import 모듈
# from 모듈 import 함수
# 모듈: 코드의 집합. 함수처럼 쓰임
Counter(shopping_list)
# Counter({'빵': 2,
# '사과': 2,
# '우유': 1,
# '바나나': 1,
# '초콜릿': 1,
# '치즈': 1,
# '오렌지': 1,
# '계란': 1})문제5. 부분 문자열 검색
아래의 리스트에서 이름에 영희가 포함된 학생은 몇명인지 출력하시오
name = ['김인호', '최영희', '안상수', '윤성식', '김영희']
name2 = []
for i in name:
if '영희' in i:
name2.append(i)
print(name2) # ['최영희', '김영희']
print(len(name2)) # 2✔️ 예제. 리스트 요소 지우기
🔸삭제 함수의 종류
리스트.remove('요소명'): 리스트의 요소를 요소명으로 삭제del 리스트[인덱스 번호]: 리스트의 요소를 자리번호로 삭제리스트.clear(): 리스트의 모든 요소들을 다 삭제
문제1. remove 함수
box 리스트에서 불량품을 지우시오
box = ['정상품', '정상품', '정상품', '정상품', '불량품', '정상품', '불량품']
box.remove('불량품')
print(box)
# ['정상품', '정상품', '정상품', '정상품', '정상품', '불량품']remove() 함수는 여러 개의 요소명 중 제일 처음 1개만 지움
문제2. del 함수
del 함수를 이용해서 box 리스트의 맨 뒤에 있는 불량품을 지우시오
box = ['정상품', '정상품', '정상품', '정상품', '불량품', '정상품', '불량품']
del(box[-1])
print(box)
# ['정상품', '정상품', '정상품', '정상품', '불량품', '정상품']문제3. 모든 특정 요소 제거 (난이도 중)
box = ['정상품', '정상품', '정상품', '정상품', '불량품', '정상품', '불량품']
for i, item in enumerate(box):
if item == '불량품':
del(box[i])
print(box)
# ['정상품', '정상품', '정상품', '정상품', '정상품']✔️ 예제83_7. len과 sum 함수
🔸기본 통계 함수
len(리스트): 리스트의 요소들의 갯수를 출력sum(리스트): 리스트의 요소들의 합을 출력
예제1. len 함수
box 리스트의 요소들의 갯수 출력
box = ['정상품', '정상품', '정상품', '정상품', '불량품', '정상품', '불량품']
print(len(box)) # 7예제2. sum 함수
box2 = [1000, 2000, 3000, 4000, 5000]
print(sum(box2)) # 15000문제1. 평균 계산
weight = [72, 81, 90, 78, 84, 65]
print(sum(weight)/len(weight)) # 78.33333333333333문제2. NumPy를 이용한 평균 계산
import numpy as np
weight = [72, 81, 90, 78, 84, 65]
print(np.mean(weight)) # 78.33333333333333✔️ 예제. map과 filter 함수
🔸고급 함수의 종류
map(함수명, 리스트): 리스트의 요소들을 함수에 적용filter(함수명, 리스트): 리스트의 요소들을 함수에 적용하여 조건에 맞는 것만 필터링
예제1. map 함수
몸무게가 80 이상인 사람들은 비만으로 나오고 아니면 정상으로 출력
def f(x): # 입력값 x를 받는 f라는 함수를 정의하겠다
if x >= 80:
return '비만'
else:
return '정상'
weight = [72, 81, 90, 78, 84, 65]
list(map(f, weight))
# ['정상', '비만', '비만', '정상', '비만', '정상']문제1. 아래의 score 리스트를 만들고 다음의 결과가 출력되게 하시오 !
score=[ 78, 92, 23, 54, 67, 88 ]
결과: [ '중', '상', '하', '중', '중', '상' ]
80점이상이면 '상'
50점이상 ~ 80미만이면 '중'
50미만이면 '하'
score = [78, 92, 23, 54, 67, 88]
def f2(x):
if x >= 80:
print('상')
elif x < 80 and x >= 50:
print('중')
else:
print('하')
print(list(map(f2, score)))예제2.filter 함수
다음 weight 리스트에서 요소가 80 이상인것만
별도의 리스트 result 에 담아 출력하시오
weight=[ 72, 81, 90, 78, 84, 65 ]
결과: [ 81, 90, 84 ]
weight=[ 72, 81, 90, 78, 84, 65 ]
def f3(x):
if x >= 80:
return x
else:
return # 아무것도 리턴하지 않음
print(list(map(f3, weight))) # [None, 81, 90, None, 84, None]
print(list(filter(f3, weight))) # [81, 90, 84]⭐ 평가 예상문제 3번
다음의 온도 리스트에서 특정 범위의 온도만 추출하여
새로운 리스트로 반환하는 코드를 작성하시오
- 온도가 28도 이상 33도 이하인 경우에만 추출
temp = [22, 28, 34, 29, 30, 25, 41, 33, 27, 26, 35, 32, 24]
temp2 = []
# def f4(x):
# if x >= 28 and x <= 33:
# return temp2.append(x)
# print(list(map(f4, temp2)))
for i in temp:
if i >= 28 and i <= 33:
temp2.append(i)
print(temp2)
# 결과: [28, 29, 30, 33, 32]✔️ 예제. zip과 enumerate 함수
🔸조합 함수의 종류
zip(리스트1, 리스트2): 리스트1과 리스트2의 요소들의 순서에 따라 짝지어주는 함수enumerate(리스트): 리스트의 요소들을 인덱스 번호와 함께 짝지어주는 함수
예제1. 다음의 2개의 리스트의 요소를 짝지어 출력하시오
weight = [71, 81, 90, 78, 84, 65]
result = ['정상', '과체중', '비만', '정상', '과체중', '정상']
for w, r in zip(weight, result):
print(w, r)
# 71 정상
# 81 과체중
# 90 비만
# 78 정상
# 84 과체중
# 65 정상문제1. 3개 리스트 조합
name = ['김인호', '안상수', '이상식', '오연수', '강인식', '고성인']
weight = [71, 81, 90, 78, 84, 65]
result = ['정상', '과체중', '비만', '정상', '과체중', '정상']
for n, w, r in zip(name, weight, result):
print(n, w, r)
# 김인호 71 정상
# 안상수 81 과체중
# 이상식 90 비만
# 오연수 78 정상
# 강인식 84 과체중
# 고성인 65 정상문제2. 리스트에 데이터 추가
name = ['김인호', '안상수', '이상식', '오연수', '강인식', '고성인']
weight = [71, 81, 90, 78, 84, 65]
result = ['정상', '과체중', '비만', '정상', '과체중', '정상']
all_data = []
for n, w, r in zip(name, weight, result):
all_data.append([n, w, r])
print(all_data)
# [['김인호', 71, '정상'], ['안상수', 81, '과체중'], ['이상식', 90, '비만'], ['오연수', 78, '정상'], ['강인식', 84, '과체중'], ['고성인', 65, '정상']]문제3. 위에서 출력되고 all_data 리스트에 있는 결과를 표 형태로 출력
from tabulate import tabulate
print(tabulate(all_data, headers=['이름', '체중', '척도'], tablefmt='pretty'))예제2. enumerate 함수
enumerate 함수를 이용해서 아래의 name 리스트에 번호를 붙여 출력
name = ['김인호', '안상수', '이상식', '오연수', '강인식', '고성인']
for i, k in enumerate(name, start=1):
print(i, k)
# 1 김인호
# 2 안상수
# 3 이상식
# 4 오연수
# 5 강인식
# 6 고성인문제4. zip과 enumerate 조합
name = ['김인호', '안상수', '이상식', '오연수', '강인식', '고성인']
weight = [71, 81, 90, 78, 84, 65]
result = ['정상', '과체중', '비만', '정상', '과체중', '정상']
for i, (n,w,r) in enumerate(zip(name, weight, result), start=1):
print(i, n, w, r)
# 1 김인호 71 정상
# 2 안상수 81 과체중
# 3 이상식 90 비만
# 4 오연수 78 정상
# 5 강인식 84 과체중
# 6 고성인 65 정상문제5. 학생별 성적 분석 문제
아래의 데이터를 판다스 데이터 프레임으로 생성하시오
성적 분석을 수행하세요
students = ['김영수', '이미나', '박준호', '최지원', '정대현']
korean = [85, 92, 78, 96, 83]
english = [92, 87, 95, 84, 90]
math = [88, 95, 70, 92, 85]
import pandas as pd
df = pd.DataFrame({
'이름' : students,
'국어' : korean,
'영어' : english,
'수학' : math
})
# 문제1. 국어 점수가 90점 이상인 학생들의 이름과 국어 점수를 출력하시오
df.loc[df.국어 >= 90, ['이름', '국어']] # df.loc[행, 열]
# 문제2. 수학 점수가 70점인 학생들의 이름과 영어점수, 수학점수를 출력하시오
df.loc[df.수학 == 70, ['이름', '영어', '수학']]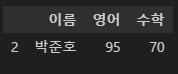
df 데이터프레임의 국어점수를 막대그래프로 시각화하시오
k = df.loc[ :, ['국어']]
n = df.loc[ : , ['이름']]
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Malgun Gothic' # 한글 안깨지게 하는 코드
plt.bar(n['이름'], k['국어'], color='lightblue')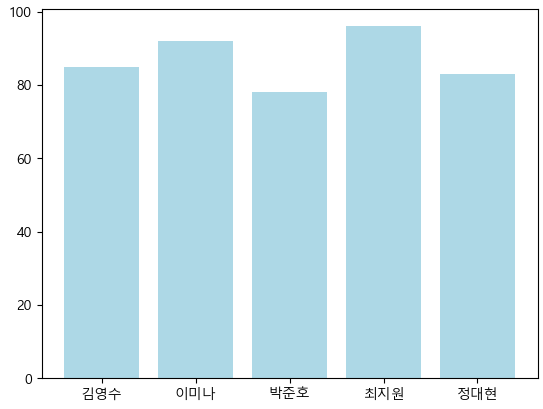
# alert log file에 있는 오라클 에러 메시지와 그 건수를 판다스 데이터프레임으로 생성
from collections import Counter
import pandas as pd
import matplotlib.pyplot as plt
oracle_alert = open("C:\\data\\alert_log.txt", encoding='utf8')
oracle_text=oracle_alert.read()
lines = oracle_text.split()
error_list=[]
for i in lines:
if 'ORA-' in i:
error_list.append(i.strip(':'))
df_error = pd.DataFrame(list(Counter(error_list).items()), columns=['에러번호', '건수'])
df_error
# 문제. df_error 데이터프레임에서 건수가 100건 이상인 에러번호와 건수를 출력하시오
df_error.loc[df_error.건수 >= 100, : ] # : 전부출력
# 문제. 위의 결과를 다시 출력하는데 건수가 높은 것부터 출력하시오
df_sort = df_error.loc[df_error.건수 >= 20, : ].sort_values(by='건수', ascending=False) # 내림차순
# 문제. 위의 결과를 막대 그래프로 시각화 하시오
# x축이 에러번호, y축이 건수
x = df_sort.loc[ :, ['에러번호']]
y = df_sort.loc[ : , ['건수']]
plt.rcParams['font.family'] = 'Malgun Gothic' # 한글 안깨지게 하는 코드
plt.bar(x['에러번호'], y['건수'], color='lightblue')
plt.xticks(rotation=45)
plt.show()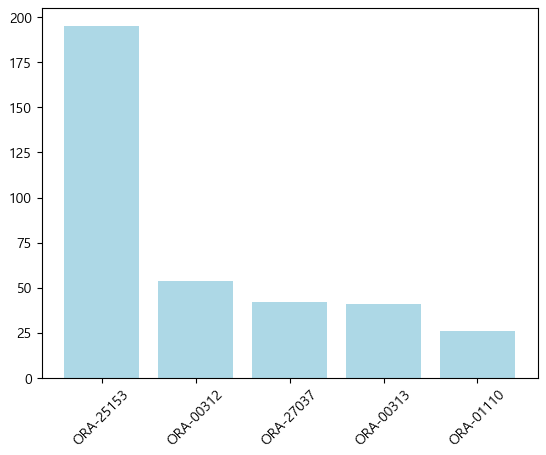
핵심 정리
리스트 함수들은 데이터 처리와 분석에서 핵심적인 역할
- 슬라이싱: 필요한 부분 추출
- 추가 함수:
append, insert, extend로 데이터 확장 - 정렬 함수:
sort, sorted, reverse, reversed로 데이터 정리 - 검색 함수:
count, index, enumerate로 요소 찾기 - 삭제 함수:
remove, del, clear로 불필요한 데이터 제거 - 통계 함수:
len, sum으로 기본 통계 계산 - 고급 함수:
map, filter로 데이터 변환과 필터링 - 조합 함수:
zip, enumerate로 여러 리스트 연결
