📌 오라클의 db object 5개
- table: db에 데이터를 저장하는 행과 열로 이루어진 기본 저장소
- view: 테이블을 바라보는 db 오브젝트 (데이터 저장 x)
- index: 쿼리의 검색속도를 향상시키는 db 오브젝트
- sequence: 번호를 생성하는 db 오브젝트
- synonym: 동의어
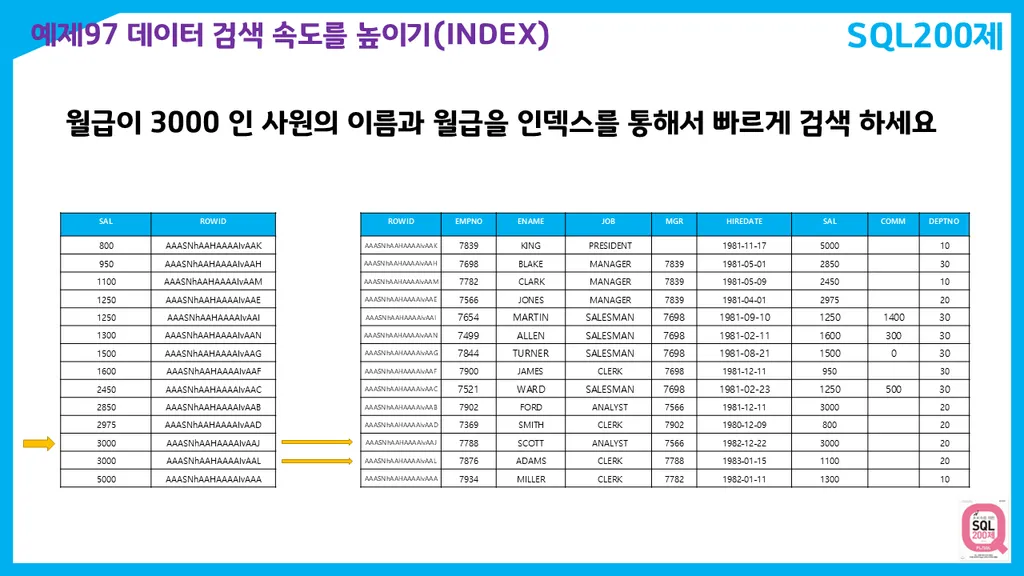
문제1. 사원 테이블에서 rowid 와 empno, ename, sal 를 출력하시오
select rowid, empno, ename, sal
from emp;rowid: 해당 row의 물리적 주소
file번호 + block + row(행) 번호
문제2. 사원 테이블에 sal 에 인덱스를 생성하시오
create index emp_sal
on emp(sal);index는 테이블과는 별개
💡
create index 인덱스_이름 on 테이블명(컬럼명);
문제3. 사원 테이블의 sal 의 인덱스를 drop 하시오
drop index emp_sal;문제4. 월급이 1600인 사원들의 이름과 월급을 출력하시오
select ename, sal
from emp
where sal = 1600;문제5. 위의 SQL의 실행계획을 보시오
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
💡 월급이 1600을 찾기 위해서 EMP 테이블의 SAL을 처음부터 끝까지 다 스캔한게 FULL TABLE SCAN

문제6. 아래의 SQL의 검색속도를 높이기 위해서 인덱스를 생성하시오
select ename, sal
from emp
where sal = 1600;
create index emp_sal
on emp(sal);문제7. 다시 아래의 SQL을 실행하고 실행계획을 보시오
select ename, sal
from emp
where sal = 1600;
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
ㄴ index 사용 후 버퍼 갯수 줄어들음
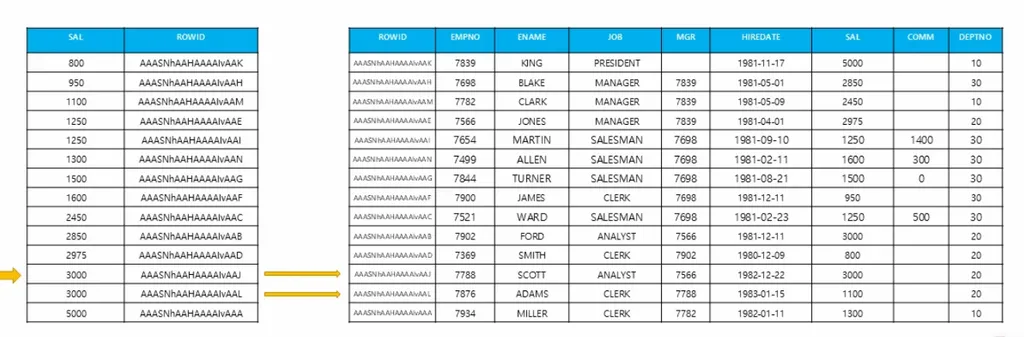
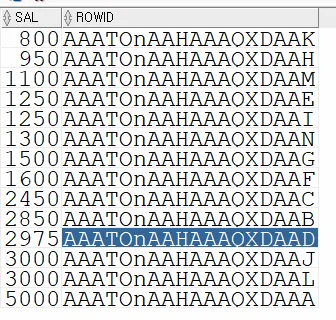
💡 인덱스의 구조는 컬럼값과 ROWID로 되어있음. 컬럼값이 ASCENDING 하게 정렬되어 있으므로 바로 데이터를 찾을 수 있음 --> FULL TABLE SCAN 보다 속도가 빠름
문제8. emp_sal 인덱스의 구조를 확인하시오
select sal, rowid
from emp
where sal >= 0;
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));
문제9. 아래의 SQL의 검색속도를 높이기 위해서 인덱스를 생성하시오
select ename, sal, job
from emp
where ename='SMITH';
create index emp_ename
on emp(ename);문제10. 아래의 SQL의 실행계획을 확인하시오
select ename, sal, job
from emp
where ename='SMITH';
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));ㄴ 버퍼 갯수 줄어들음

문제11. 지금 방금 만든 EMP_ENAME 인덱스의 구조를 확인하시오
select ename, rowid
from emp
where ename > ' ';문제12. 아래의 SQL이 어떻게 인덱스를 통해서 SCOTT 의 데이터를 찾는지 원리를 이해하시오
SELECT ename, sal
from emp
where ename='SCOTT';
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));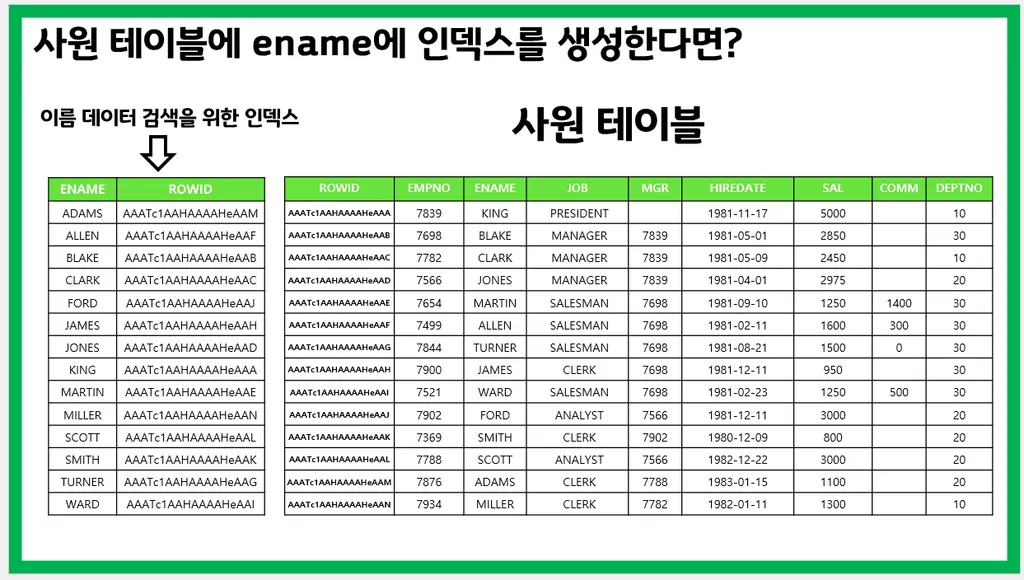
문제13. 아래의 SQL 에 검색속도를 높이기 위해서 인덱스를 생성하시오
select ename, hiredate
from emp
where hiredate = to_date('81/12/11', 'RR/MM/DD');
create index emp_hiredate
on emp(hiredate);문제14. emp_hiredate 인덱스의 구조를 확인하시오
select hiredate, rowid
from emp
where hiredate < to_date('9999/12/31', 'RRRR/MM/DD');문제15. (SQL튜닝) 아래의 SQL을 튜닝하시오
튜닝 전
select ename, sal
from emp
where sal * 12 = 36000; 💡 sal*12 라고 하면 sal 컬럼을 가공하면 인덱스를 엑세스 하지 못하고 full table scan 하게 됨
튜닝 후
select ename, sal
from emp
where sal = 36000/12;
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));문제16. 아래의 SQL에 검색속도를 높이기 위해서 인덱스를 생성하시오
튜닝 전
select ename, job
from emp
where job='SALESMAN';
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));튜닝 후
create index emp_job
on emp(job);
select ename, job
from emp
where job='SALESMAN';
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));문제17. 아래의 SQL을 튜닝하시오
튜닝 전
select ename, job
from emp
where substr(job, 1, 5)='SALES';튜닝 후
select ename, job
from emp
where job like 'SALES%';
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));💡 와일드카드(%) 가 뒤쪽에 있어야 인덱스를 탈 수 있음
문제18. 아래의 SQL을 튜닝하시오
튜닝 전
select ename, hiredate
from emp
where to_char(hiredate, 'RRRR') = '1981';튜닝 후
select ename, hiredate
from emp
where hiredate between to_date('1981/01/01','RRRR/MM/DD')
and to_date('1981/12/31:23:59:59','RRRR/MM/DD:HH24:MI:SS');
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));문제19. 아래의 SQL을 튜닝하시오
튜닝 전
select ename, job, sal
from emp
where job || sal = 'SALESMAN1250'; 튜닝 후
select ename, job, sal
from emp
where job ='SALESMAN' and sal = 1250;
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));문제20. 아래의 SQL을 튜닝하시오 (order by 절 쓰지 않게 작성하세요)
튜닝 전
select ename, sal
from emp
order by sal asc;
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));💡 대량의 데이터를 order by 하면 그 SQL도 느려지고 다른 sql도 다같이 느려짐
튜닝 후
select ename, sal
from emp
where sal >= 0;
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));문제21. 아래의 SQL을 튜닝하시오
튜닝 전
select ename, sal
from emp
order by sal desc; 튜닝 후
select /*+ index_desc(emp emp_sal) */ename, sal
from emp
where sal >= 0;💡
select /*+ 힌트 */: 힌트는 실행계획을 제어하는 명령어
/+ index_desc(테이블 인덱스이름) /
- index_asc 힌트: 인덱스를 ascending 하게 스캔
- index_desc 힌트: 인덱스를 descending 하게 스캔
문제22. 아래의 SQL을 튜닝하시오. order by 절을 사용하지 말고 수행
튜닝 전
select ename, hiredate
from emp
order by hiredate desc; 튜닝 후
select /*+ index_desc(emp emp_hiredate) */ ename, hiredate
from emp
where hiredate <= to_date('9999/12/31','RRRR/MM/DD');문제23. 아래의 SQL을 튜닝하시오
튜닝 전
select ename, hiredate
from emp
where hiredate = (select max(hiredate)
from emp );
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST'));튜닝 후
select /*+ index_desc(emp emp_hiredate) */ ename, hiredate
from emp
where hiredate <= to_date('9999/12/31','RRRR/MM/DD') and rownum = 1;
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST')) ;문제24. 아래의 SQL을 튜닝하시오
튜닝 전
select ename, sal
from emp
where sal = ( select min(sal)
from emp );
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST')); 튜닝 후
select /*+ index_asc(emp emp_sal ) */ ename, sal
from emp
where sal >= 0 and rownum = 1;
SELECT * FROM table(dbms_xplan.display_cursor(null, null, 'ALLSTATS LAST')); 💡 emp 테이블을 2번 엑세스 하지 않고 한번에 결과를 출력하는 SQL튜닝 방법
문제25. 아래의 SQL의 속도를 높이기 위한 가장 좋은 인덱스를 생성하시오
인덱스를 아래의 2개의 컬럼중에 1개에만 생성해야함
select ename, age, telecom
from emp21
where telecom = 'SKT' and ename='000'; 💡 telecom 보다는 ename 에 인덱스를 거는게 더 성능이 좋음. telecom의 skt는 10건이고 ename의 000은 1건이므로, ename에 인덱스가 있다면 000 1건만 찾으면 끝남
create index emp21_ename
on emp21(ename); 문제26. 아래에 가장 적절한 인덱스 1개를 생성하시오
튜닝 전
select ename, age, address
from emp21
where age = 27 and address like '서울%' ;튜닝 후
select count(*)
from emp21
where age = 27;
select count(*)
from emp21
where address like '서울%';
select ename, age, address
from emp21
where 1=1
and age = 27 -- 2건
and address like '서울%'; -- 12건
create index emp21_age
on emp21(age);- 여기서
where 1=1을 쓰는 이유
: where 1=1은 큰 의미는 없지만 and의 정렬을 위해 쓴 것
문제27. 아래의 가장 적절한 단일 컬럼 인덱스 하나를 생성하시오
cmd 창에서 @demo 한번 돌리기
튜닝 전
select ename, sal, job, deptno
from emp
where ename ='SCOTT' and deptno = 20;튜닝 후
select ename, sal, job, deptno
from emp
where 1=1
and ename ='SCOTT' -- 1건
and deptno = 20; -- 5건
select count(*)
from emp
where ename='SCOTT'; -- 1
select count(*)
from emp
where deptno = 20; -- 5
create index emp_ename
on emp(ename);문제28. demo 스크립트를 수행하고 아래의 SQL에 가장 적절한 인덱스를 생성하시오
튜닝 전
select ename, sal, job, deptno, hiredate
from emp
where job='SALESMAN' and deptno = 30; 튜닝 후
select ename, sal, job, deptno, hiredate
from emp
where 1=1
and job='SALESMAN' -- 4건
and deptno = 30; -- 6건
select count(*)
from emp
where job='SALESMAN';
select count(*)
from emp
where deptno = 30;
create index emp_job
on emp(job);마지막 문제1. 아래의 SQL을 튜닝하시오
튜닝 전
select ename, age
from emp21
where age = (select max(age)
from emp21);튜닝 후
select /*+ index_desc(emp21 emp21_age) */ ename, age
from emp21
where age >= 0 and rownum = 1;
create index emp21_age
on emp21(age);마지막 문제2. 아래의 SQL을 튜닝하시오
튜닝 전
select deptno, null as job, sum(sal)
from emp
group by deptno
union all
select null as deptno, job, sum(sal)
from emp
group by job
union all
select null as deptno, null as job, sum(sal)
from emp
order by deptno, job;튜닝 후
select deptno, job, sum(sal)
from emp
group by grouping sets(deptno, job, ());문제29. 가지고 있는 인덱스를 모두 삭제하시오
💡 인덱스를 무조건 많이 만든다고 좋은 것인가?
1. 필요한 컬럼에만 인덱스를 생성해줘야됨
2. 인덱스가 많아지면 역효과로 테이블에 입력작업이 느려짐
3. 테이블의 데이터를 지우면 테이블의 데이터는 지워지지만, 인덱스는 바로 지워지지 않음. 나중에 dba 가 db reorg 작업을 하면서 불필요한 leaf들을 정리해줘야 함
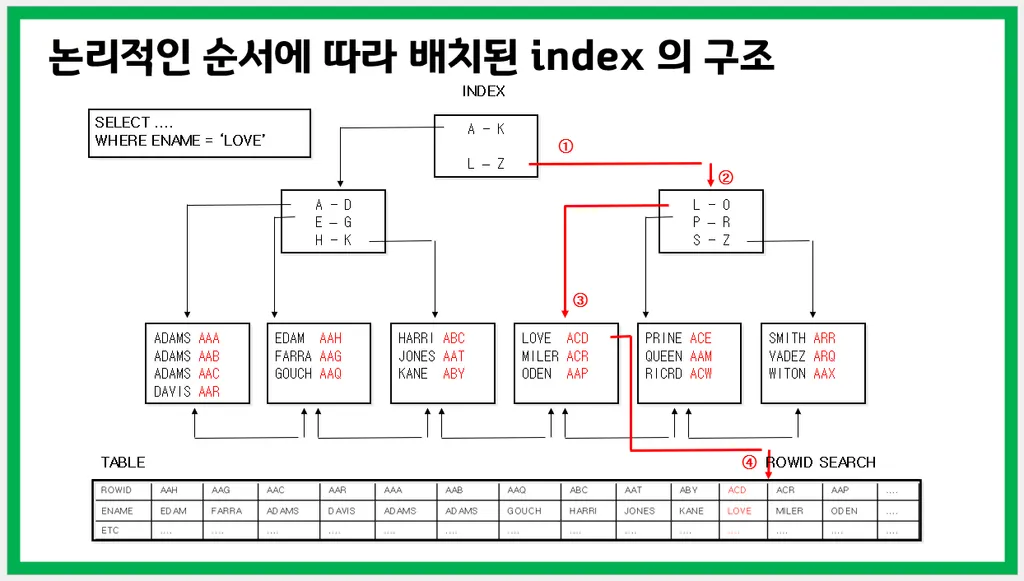
🔸 인덱스 구조
root - branch - leaf
인덱스 모두 조회
select * from user_indexes;한꺼번에 drop 하는법
select 'drop index ' || index_name || ';'
from user_indexes;인덱스 삭제
drop index EMP21_ENAME;
drop index EMP_ENAME;
drop index EMP21_AGE;
drop index EMP_JOB;
drop index EMP_SAL;
drop index EMP_HIREDATE;primary key 걸려있는 인덱스 삭제
alter table EMP_KIND2
drop constraint PK_EMP_KIND2;
alter table members
drop constraint SYS_C008577 cascade;