스프링 DB접근
폴더 만들기
본격적으로 프로젝트를 만들어 보자
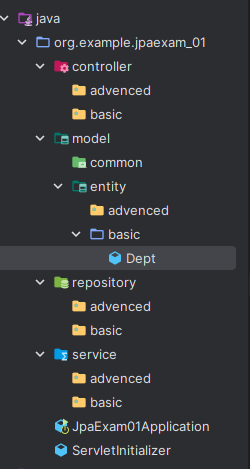 폴더를 다음과 같이 만들면 된다.
폴더를 다음과 같이 만들면 된다.
model 만들기
JPA에서는 model을 entity라고 한다. 여기선 어노테이션을 사용하여 테이블과 속성들의 getter,setter,생성자 옵션등을 만들수 있다.
@Entity //- 대상 클래스를 참고하여 DB에 물리 테이블을 생성함
@Table(name="TB_DEPT") //- 자동 생성 시 물리 테이블명으로 생성됨
@SequenceGenerator( //- Oracle DB 시퀀스 생성시 사용할 속성들
name = "SQ_DEPT_GENERATOR"
, sequenceName = "SQ_DEPT"
, initialValue = 1
, allocationSize = 1
)
@DynamicInsert //- insert 시 null 인 컬럼 제외해서 sql 문 자동 생성함
@DynamicUpdate // - update 시 null 인 컬럼 제외해서 sql 문 자동 생성함
@Setter
@Getter
@NoArgsConstructor // 기본 생성자
@AllArgsConstructor // 모든 속성 생성자
@ToString
public class Dept {
@Id // 기본키를 지정해주는 어노테이션
@GeneratedValue(strategy = GenerationType.SEQUENCE
, generator = "SQ_DEPT_GENERATOR"
)
@Column(columnDefinition = "NUMBER")
private Integer dno; // 부서번호
@Column(columnDefinition = "VARCHAR2(255)")
private String dname; // 부서명
@Column(columnDefinition = "VARCHAR2(255)")
private String loc; // 부서위치
}테이블 만들기
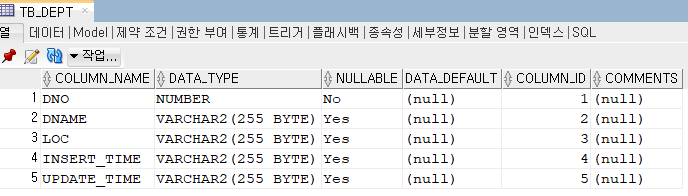 예전에는 insert time과 updatetime이 없었다. 이것은 테이터가 저장 되었거나 수정 되었을시 그때의 시간을 입력되게 할 때 사용할 수 있다.
예전에는 insert time과 updatetime이 없었다. 이것은 테이터가 저장 되었거나 수정 되었을시 그때의 시간을 입력되게 할 때 사용할 수 있다.
그런데 이건 다른 테이블에도 공통적으로 다 존재하기에 자바를 코딩 할 때는 상속을 이용하여 공유하자.
공통 클래스 만들기
공통으로 사용할 클래스를 만드는 곳에 nsert time과 updatetime 속성을 만들 것이다.
@Getter
@MappedSuperclass
@EntityListeners(AudioFileFormat.class)
public class BaseTimeEntity {
private String insertTime;
private String updateTime;
}@MappedSuperclass
@EntityListeners(AudioFileFormat.class) 이 두 클래스는 jpa가 ㅑinsert, update sql문을 생성할때 아래 공통 컬럼을 추가해서 생성시켜주는 어노테이션이다.
예를들어
insert into tb_dept(dno, dname, loc) values (1,'sales','부산');
=> 붙이면 :
insert into tb_dept(dno, dname, loc, insert_time, update_time)
values (1,'sales','부산', '2024/03/19...', '2024/03/19...');이렇게 sql문이 자동으로 변하는 것이다.
MappedSuperclass
@MappedSuperclass는 JPA(Java Persistence API)에서 사용되는 어노테이션입니다. 이 어노테이션을 사용하여 엔티티 클래스들 간에 코드를 공유하고, 공통 필드 및 매핑 정보를 상속할 수 있습니다.
일반적으로, 여러 엔티티 클래스들이 공통적인 속성을 가질 때 @MappedSuperclass를 사용합니다. 이런 경우, 해당 공통 속성을 가진 추상 클래스를 만들고, 이 추상 클래스에 @MappedSuperclass를 적용합니다. 그러면 이 추상 클래스의 속성들이 하위 엔티티 클래스에 상속됩니다.
이러한 상속 관계는 데이터베이스 테이블에도 반영됩니다. 즉, @MappedSuperclass를 사용하여 매핑된 슈퍼 클래스의 필드들은 하위 엔티티 클래스들의 테이블에 컬럼으로 추가됩니다
EntityListeners(AudioFileFormat.class)
@EntityListeners는 JPA(Java Persistence API)에서 사용되는 어노테이션 중 하나입니다. 이 어노테이션은 엔티티의 라이프사이클 이벤트에 대한 리스너 클래스를 지정할 때 사용됩니다.
Repository 만들기
CRUD함수 즉 DML문들이 있는 클래스이다.
Repository 인터페이스 만들기
레퍼지토리 클래스는 인터페이스로 만들어야한다. mybatis를 사용할거면 class를 만들면 되지만 jpa에서는 인터페이스를 사용한다.
인터페이스만 만들어도 함수들은 jpa가 알아서 다 만들어 주었기 때문에 만들지 않아도 된다.
@Repository
public interface DeptRepository extends JpaRepository<Dept, Integer> {
}jpa에서 자동으로 함수를 만들어 주어야하기때문에 JpaRepository<엔티티 명, 기본키속성자료형>를 사용해야한다. 이걸 상속받지 않으면 함수를 사용할 수없다. 여기서 제공하는 함수를 사용하는 것이다.
엔티티 명에는 DB와 연결될 엔티티 이름을 넣어주면 되고, 기본키속성자료형은 그 엔티티의 기본키의 자료형을 넣어주면 된다.
jpa Repository 기본 제공 함수
findAll() : 전체 조회 , 자동 sql 문 생성
- findById(기본키) : 상세 조회(1건), 자동 sql 문 생성
- save(객체) : 저장/수정을 알아서 실행함
저장 : 기본키가 없으면 insert
수정 : 기본키가 있으면 update - deleteById(기본키): 삭제 , 자동 sql 문 생성
Service 클래스 만들기
@Service
public class DeptService {
private final DeptRepository deptRepository;
@Autowired
public DeptService(DeptRepository deptRepository) {
this.deptRepository = deptRepository;
}
public List<Dept> findAll(){
List<Dept> list = deptRepository.findAll();
return list;
}
}여기선 기존에 하던거랑 다른것이 많이 없다.
Controller 클래스 만들기
@Slf4j
@Controller
@RequestMapping("/basic")
public class DeptController {
private final DeptService deptService;
@Autowired
public DeptController(DeptService deptService) {
this.deptService = deptService;
}
@GetMapping("/dept")
public String getDeptAll(Model model){
List<Dept> list = deptService.findAll();
return "/basic/dept/dept_all.jsp";
}
}여기도 크게 바뀌는 것이 없어 언급할 것이 없다.
dept_all JPA 만들기
JPQL
JPA는 SQL문을 함수를 사용하기만 하면 알아서 짜주는 기능을 제공해주었다. 그런데 JPA에서 제공하지 않는 SQL문을 짜야할 때가 있다. 이럴때는 JPQL문을 사용해야한다.
JPQL문은 2 종류가 있다. 하나는 @Query어노테이션을 이용해 개발자가 직접 쿼리를 짤수 있게 해주는 기능이다.
두번째는 쿼리메소드라는 방법으로 함수이름을 개발자가 JPA가 인식할 수 있게 만들어주어 함수이름으로 쿼리를 짜는 방법이다.
@Query 방법
@Query(value = "SELECT D.* FROM TB_DEPT D\n" +
"WHERE D.DNAME LIKE '%'|| :dname ||'%'"
,countQuery ="SELECT COUNT(*) FROM TB_DEPT D\n" +
"WHERE D.DNAME LIKE '%'|| :dname ||'%'"
,nativeQuery = true) // oracle 쿼리문을 사용가능하게 해준다. false일 경우 객체 sql(JPQL)을 사용해야한다. oracle에서만 특정으로 사용하는 쿼리문을 사용할때 필수적으로 켜야하는 기능이다.
public Page<Dept> findAllByDnameContaining (@Param("dname") String dname, Pageable pageable);dname함수를 변수로 받아서 dname을 포함하는 값을 찾을때 사용하는 쿼리문이다.
-
@Query어노테이션에 value값에 사용할 쿼리를 사용하면된다.
-
결과의 갯수가 필요한 경우를 위해 countQuery를 만들어준다.
-
변수를 사용할때에는 함수의 매개변수에 @Param을 사용해 사용할 변수를 넣어주고, 이걸 쿼리문에 '%'||변수||'%'와 같은 방법으로 사용하면된다.
쿼리 메소드 방법
이건 아직 자세하게 배우지 않아 다음에 추가하도록 하자.
페이지 넘버 구현
화면에 출력하는 데이터가 비약적으로 많다면 성능이 매우 떨어진다. 이를 해결하기위해 몇 건씩 끊어서 보여주어 화면 로딩시간과 조회 속도를 높일 수 있다.
설계
- 목적 : 전체 데이터를 화면에 출력하면 데이터 비약적으로 많다면 성능이 매우 떨어지므로 몇건씩 끊어서 보여주어 화면 로딩시간과 조회 속도를 높이는 것
- 페이징 대표 변수 :
1) page = 현재페이지,
2) size = 1 페이지 당 보여줄 데이터 수
- 페이징 대표 객체 :
1) 매개변수 페이징 객체 : Pageable
2) 리턴될 페이징 객체 : Page<객체자료형>
- 클라이언트로 전송할 데이터 : Map 자료구조를 이용- 전체 조회 select 쿼리를 자동으로 만들어 주는 함수
- paging 처리시 매개변수로 Pageable 객체를 포함해야 페이징 처리가 됨
- 결과는 Page 객체로 리턴됨
1) Page 객체의 일부 데이터만 Map 자료구조에 넣어 클라이언트로 전송함
2) Page 객체 주요 getter 함수
- getContent() : 쿼리 결과 배열 가져오기
- getNumber() : 현재 페이지 번호 가져오기
- getTotalElements() : 전체 페이지 번호 가져오기
- getTotalPages() : 전체 페이지 개수 가져오기
3) 페이징 처리 공식 : 블럭시작페이지번호 , 블럭끝페이지번호 구하기
- 예) [이전] 0 1 2 [다음] => 1블럭
[이전] 3 4 5 [다음] => 2블럭
[이전] 6 7 8 [다음] => 3블럭
- 1블럭 : 0(블럭시작페이지번호) ~ 2(블럭끝페이지번호) , 2블럭 : 3(블럭시작페이지번호) ~ 5(블럭끝페이지번호), 3블럭 : 6(블럭시작페이지번호) ~ 8(블럭끝페이지번호)
- 공식 : 블럭시작페이지번호 = (Math.floor(현재페이지번호/1페이지당개수)) * 1페이지당개수
1) 현재페이지 2, 1페이지당 개수 3 이라면 계산 => Math.floor(2/3) * 3 = 0 (블럭시작페이지번호)
2) 현재페이지 5, 1페이지당 개수 3 이라면 계산 => Math.floor(5/3) * 3 = 3 (블럭시작페이지번호)
- 공식 : 블럭 끝페이지 번호 = 블럭 시작페이지번호 + 1페이자당개수 - 1
(0부터 시작하므로 1 빼기)페이지 구현 Repository
jpa는 명령문만 내리면 알아서 sql문을 짜준다.
@Repository
public interface DeptRepository extends JpaRepository<Dept,Integer> {
// todo 페이징 처리 like 검색어
// like 검색 sql문 작성 :
// 사용법 : @Query(value="sql", nativeQuery=true)
@Query(value = "SELECT D.* FROM TB_DEPT D\n" +
"WHERE D.DNAME LIKE '%'|| :dname ||'%'"
,countQuery ="SELECT COUNT(*) FROM TB_DEPT D\n" +
"WHERE D.DNAME LIKE '%'|| :dname ||'%'"
,nativeQuery = true) // oracle 쿼리문을 사용가능하게 해준다. false일 경우 객체 sql(JPQL)을 사용해야한다.oracle에서만 특정으로 사용하는 쿼리문을 사용할때 필수적으로 켜야하는 기능이다.
Page<Dept> findAllByDnameContaining (@Param("dname") String dname, Pageable pageable);
// Page<엔티티>객체 : 페이징된 결과값을 저장할 객체(함수의 리턴값으로 사용)
// - 예) 속성 : 현재페이지번호, 전체페이지건수 등
// Pageable 객체 : 페이징하기 위한 객체(함수의 매개변수로 사용)
}-
reposirory에서는 원래 findAll함수는 List타입을 가지고 이것을 리턴했다. 그런데 페이지 형식으로 바꾸려면 Page타입을 사용해야만 한다.
-
pageable은 블럭이 가지는 페이지의 개수와 현재 페이지 등을 변수로 받아, 이것을 Page객체에 전해주는 역할을 한다. 그래서 Page타입의 함수는 pageable을 변수로 가져야한다.
-
나중에 검색기능을 위한 매개변수 @Param("dname") String dname을 준비했다. dname을 검색하면 결과가 나오게 만들 것이다.
페이지 구현 Service
@Service
public class DeptService {
// DB CRUD 클래스 받기 : JPA 제공 함수 사용 가능
@Autowired
DeptRepository deptRepository;
/**
* 전체 조회 : 페이징 없음
* @return 부서배열
*/
public List<Dept> findAll() {
// JPA 전체조회 함수 실행 : select 문 자동 작성
List<Dept> list = deptRepository.findAll();
return list;
}
/**
* 전체 조회 : 페이징 처리
* @param dname
* @param pageable
* @return 부서배열
*/
// DB like 검색함수 실행 : 페이징 처리
public Page<Dept> findAllByDnameContaning(String dname, Pageable pageable){
Page<Dept> page = deptRepository.findAllByDnameContaining(dname, pageable);
return page;
}
}findAllByDnameContaning함수를 만들었다. repository함수를 리턴해주는 함수이다. 크게 언급할 것은 없다.
페이지 구현 Controller
@Slf4j
@Controller
@RequestMapping("/basic")
public class DeptController {
// 서비스 클래스 가져오기
@Autowired
DeptService deptService;
// 전체 조회 + like 검색 + 페이징 처리
@GetMapping("/dept")
public String getDeptAll(
@RequestParam(defaultValue = "") String dname,
@RequestParam(defaultValue = "0") int page,
@RequestParam(defaultValue = "3") int size,
Model model) {
Pageable pageable = PageRequest.of(page,size);
// DB 전체 조회 서비스 함수 실행
Page<Dept> pageRes = deptService.findAllByDnameContaning(dname, pageable);
// 결과를 jsp 전송
// page객체에는 여러 함수가 많아서 다 보낼 필요없고 사용할 6가지 정보 것만 보내자.
model.addAttribute("dept",pageRes.getContent()); // 1. 부서정보 - 페이지 반복문 돌릴때 사용할 데이터
model.addAttribute("currentPage",pageRes.getNumber()); // 2. 현재페이지 번호
model.addAttribute("totalItems",pageRes.getTotalElements()); // 3. 전체 행 건수
model.addAttribute("totalPages",pageRes.getTotalPages()); // 4. 전체 페이지 개수
// 공식 : 블럭 시작페이지 번호 = (Math.floor(현재페이지번호/1페이지당개수)) * 1페이지당개수
long blockStartPage = (long) Math.floor((double) pageRes.getNumber()/size)*size; // 5. 블럭 시작페이지번호
// 공식 : 블럭 끝페이지 번호 = 블럭 시작페이지번호 + 1페이지당개수 - 1
model.addAttribute("startPage", blockStartPage);
long blockEndPage = blockStartPage + size -1; // 6. 블럭 끝페이지 번호
// 블럭 끝 페이지 번호가 전체페이지 번호와 다르게 될 수가 있다. 그래서 같게 보정해야함
// 여기서 size를 더해주기 때문에 blockEndPage가 전체 페이지를 넘길 수 있다. 예를 들어 0부터 53까지의 페이지가 있다고하자. size는 5개로 설정
// 그럼 마지막 블락의 blockStartPage는 50이 된다. 그런 blockEndPage 는 50 + 5 -1 = 54가 되어 더 커지게 된다.
// -1을 해주는 이유는 우리가 원하는 값은 0부터 시작하는 get함수의 값이다. 그런데 이들과 달리 size는 1부터 시작하는 값이기 때문
blockEndPage = (blockEndPage >= pageRes.getTotalPages())? pageRes.getTotalPages()-1 : blockEndPage; // 이 가능성이 나오는 경우는 젤 마지막 블록밖에 없기 때문에 이때만 전체(55) -1해주면 된다.
model.addAttribute("endPage", blockEndPage);
return "basic/dept/dept_all.jsp";
}
}-
여기서도 변수는 3개 받아야한다. dname은 검색을 위한 변수이고, page와 size는 Page객체가 사용할 변수이다. 이때 PathVariable말고 RequestParam을 사용하여야 부트스트랩의 요소와 호환이 된다.
-
Pageable타입의 변수에 PageRequest함수를 넣어주어야한다. 이때 받은 매개변수 page와 size를 넣어주자. 여기서 page는 현재 페이지를 나타낼 변수이고, size는 블럭당 들어갈 페이지의 갯수이다.
-
pageable을 pageRes에 넣고 page객체가 제공하는 함수들을 이용해서
1) 페이지에서 나타낼 내용 - getContent()로 나중에 반복문에 어떤 내용을 내보낼지 알릴때 사용
2) 현재페이지 번호 - getNumber()로 현재 페이지를 나타냄
3) 전체 행 갯수 - getTotalElements()로 한페이지에 행이 몇개인지를 나타냄
4) 전페 페이지 갯수 - getTotalPages() 전체가 몇 페이지인지를 나타냄 -
위의 것들을 이용해 blockStartPage,blockEndPage를 만들었다. 이 과정은 위의 코드의 주석 참고.
JSP
<table class="table">
<thead>
<tr>
<th scope="col">dno</th>
<th scope="col">dname</th>
<th scope="col">loc</th>
<th scope="col">insertTime</th>
<th scope="col">updateTime</th>
</tr>
</thead>
<tbody>
<c:forEach var="data" items="${dept}">
<tr>
<td><a href="/basic/dept/edition/${data.dno}">${data.dno}</a></td>
<td>${data.dname}</td>
<td>${data.loc}</td>
<td>${data.insertTime}</td>
<td>${data.updateTime}</td>
</tr>
</c:forEach>
</tbody>
</table>
<%-- TODO: 페이지번호 --%>
<div class="d-flex justify-content-center"> <%--중앙정령 해주는 클래스 속성--%>
<ul class="pagination">
<li class="page-item ${(startPage+1==1)? 'disabled' : ''}">
<a href="/basic/dept?page=${startPage-1}&size=${3}" class="page-link">Previous</a><%--dname도 RequestParam으로 받았지만 두개만 사용하는 것도 가능--%>
</li>
<%--todo 반복문 실행--%>
<c:forEach var="data" begin="${startPage}" end="${endPage}">%-- 단순 반복일 경우 (요소를 반복해서 보여주는 것이 아닐경우) begin과 end가 필요하다.--%>
<li class="page-item"><a class="page-link" href="/basic/dept?page=${data}&size=${3}">${data+1}</a>
</li><%-- 클릭하면 해당 페이지의 데이터가 뜨게 링크 걸어줘야함--%>
</c:forEach>
<li class="page-item ${(endPage+1==totalPages)? 'disabled' : ''}">
<a href="/basic/dept?page=${endPage+1}&size=${3}" class="page-link" >Next</a>
</li>
</ul>
</div>-
table에서 td에 반복문을 사용해서 요소들을 나열했다. items는 list에서 getContent()인 dept로 바꿔주었다.
-
Previous버튼을 첫 블럭에는 disable시키기 위해 "${(startPage+1==1)? 'disabled' : ''}"을 걸어주었다. 또한 클릭을 했을때 이동할 블럭의 링크 href="/basic/dept?page=${startPage-1}&size=${3}"를 걸어주었다.
-
반복문을 이용하여 페이지 숫자를 나열 해주었다. 이때 요소를 나열하는 것이 아닌 단순 반복일 경우 (요소를 반복해서 보여주는 것이 아닐경우) begin과 end가 필요하다. 그리고 페이지를 클릭할 시 나타낼 페이지도 링크로 걸어 주었다.href="/basic/dept?page=${data}&size=${3}"
-
Next버튼도 마찬가지로 마지막 블럭에는 disable시키기 위해 "${(endPage+1==totalPages+1)? 'disabled' : ''}"을 걸어주었다.
버튼을 눌렀을 경우 이동할 페이지 href="/basic/dept?page=${endPage+1}\&size=${3}"도 연결해주었다.
