🎇 Redshift 데이터 분산이란?
MPP 기반의 DW인 Redshift는 각 컴퓨팅 노드에 데이터가 분산되어 저장된다. 그리고 분산된 데이터는, 동일한 컴퓨팅 노드에서 할당된 작업에 활용되는 것이 가상 이성적이다. 즉, 쿼리 수행에 있어서 Redshift는 로컬리티(locality)를 선호한다. 컴퓨팅 노드에 할당된 작업에서, 다른 컴퓨팅 노드에 저장된 데이터를 가지고 와서 작업을 해야하는 경우에는 리더 노드를 거쳐 다시 컴퓨팅 노드로 데이터가 전달되는 네트워크 비용이 발생한다. 이러한 네트워크 비용을 줄이는 동시에, 리소스 사용은 최소화하는 것이 MPP DW를 효율적으로 활용하는 방법 중의 하나이다.
🎇 Redshift Diststyle
1) ALL (전체분산)
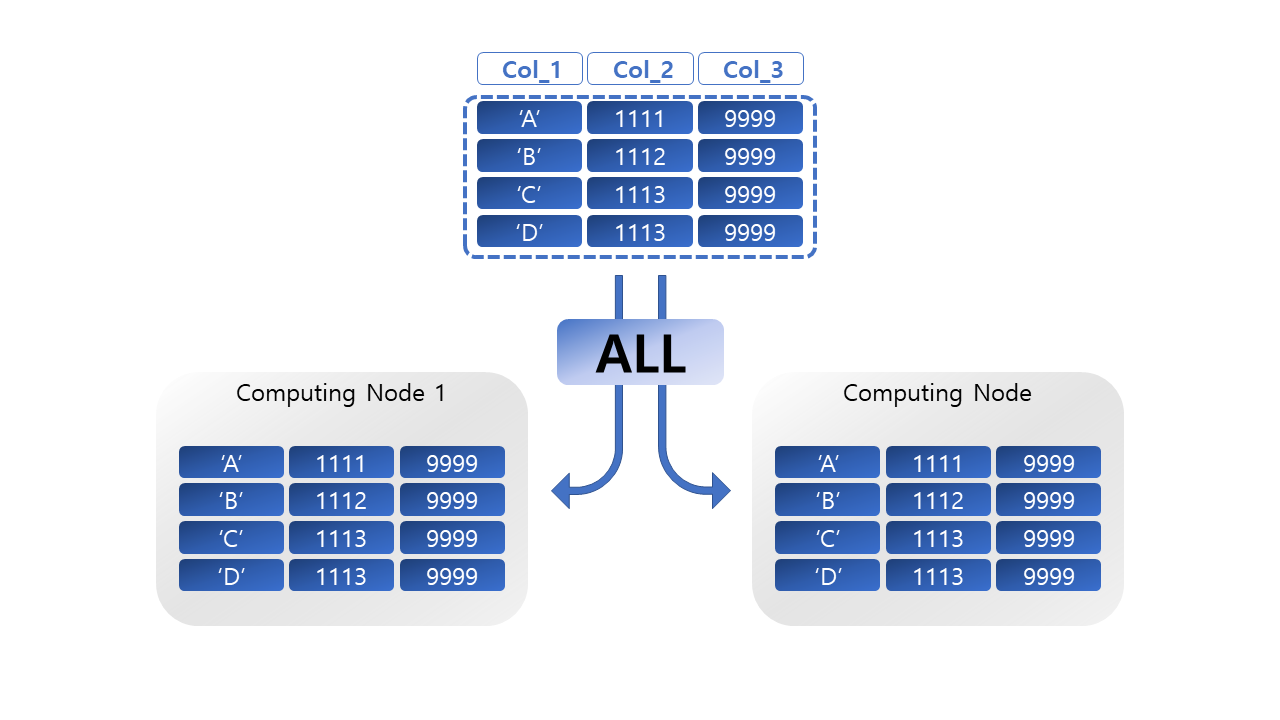
전체 데이터를 모든 컴퓨팅 노드에 복제하는 방식이다. 테이블의 모든 데이터가 모든 컴퓨팅 노드에 존재하므로, 해당 테이블에 대한 쿼리는 네트워크 비용이 발생할 필요가 없다. 하지만, 클러스터의 종류에 따라 컴퓨팅 노드 수가 늘어날 수록 그만큼 많은 디스크 공간을 차지하게 된다.
전체분산을 사용해야 하는 경우는, 테이블의 크기와 변경이 적고 공통으로 Join되어 사용되는 표준공통디멘션에 적합하다. 예를 들어, 달려과, 우편번호 등 쿼리의 성격에 관계 없이 여러 쿼리에서 공통으로 Join해서 사용하는 테이블의 경우 미리 전체 컴퓨팅 노드에 분산하여 네트워크 비용을 줄일 수 있다.
전체분산으로 테이블을 생성하는 방식은 아래와 같다.
CREATE TABLE diststyle_all_dim
(
col_1 varchar,
col_2 int,
col_3 int
)
DISTSTYLE ALL
;2) EVEN(균등분산)
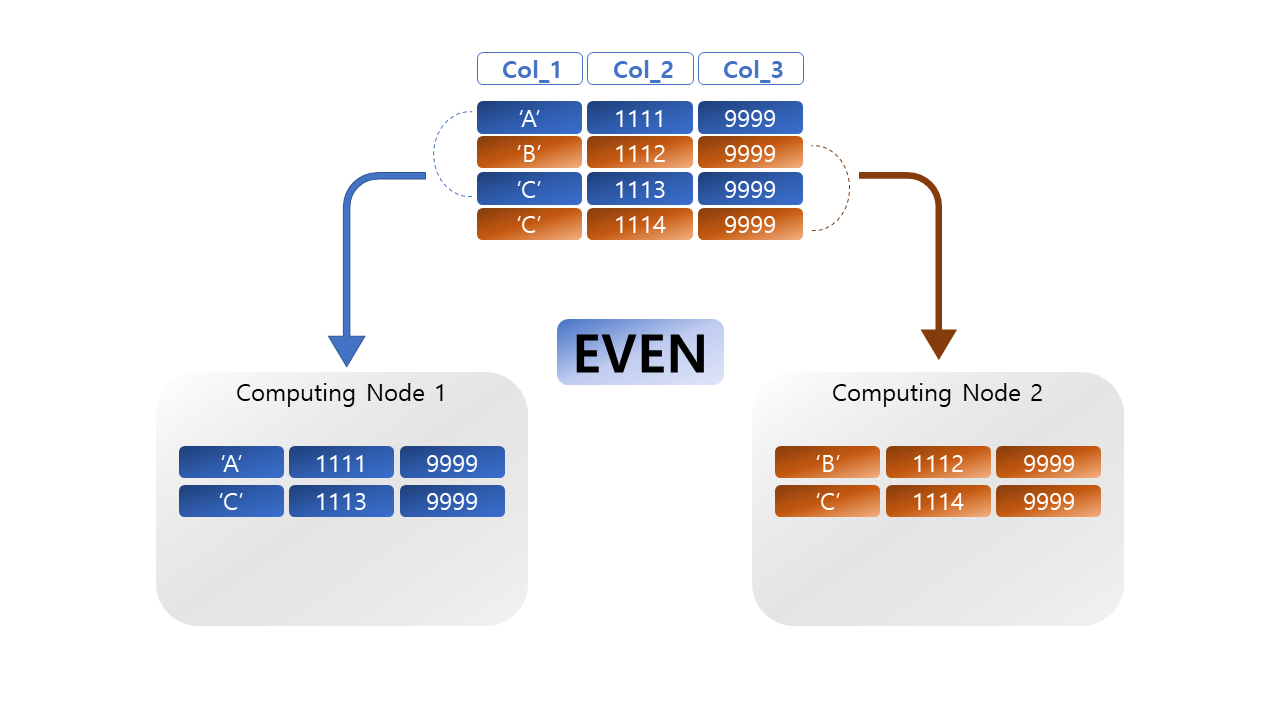
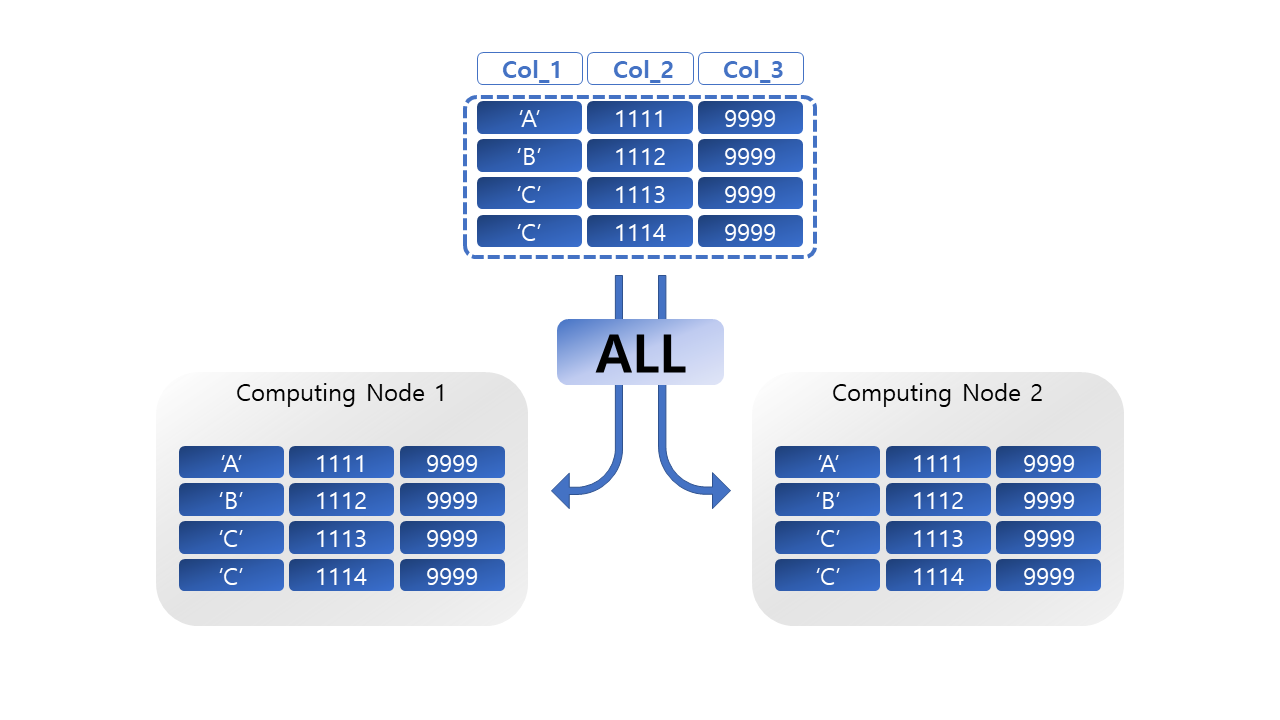
라운드 로빈 방식으로, 데이터를 각 컴퓨팅 노드에 균등하게 저장하는 방식이다. 분산키를 선정하기 어려운 테이블이나, 전체분산을 하기에는 데이터의 크기가 너무 클 때 적용할 수 있는 대안이다. 노드에 순차적으로 데이터가 할당되기 때문에 데이터 스큐 현상은 피할 수 있지만, 조인 쿼리에서 사용할 경우 데이터 재분산 작업이 발생할 확률이 높다.
균등분산으로 테이블 생성하는 방식은 아래와 같다.
CREATE TABLE diststyle_even_dim
(
col_1 varchar,
col_2 int,
col_3 int
)
DISTSTYLE EVEN
;3) KEY (키분산)
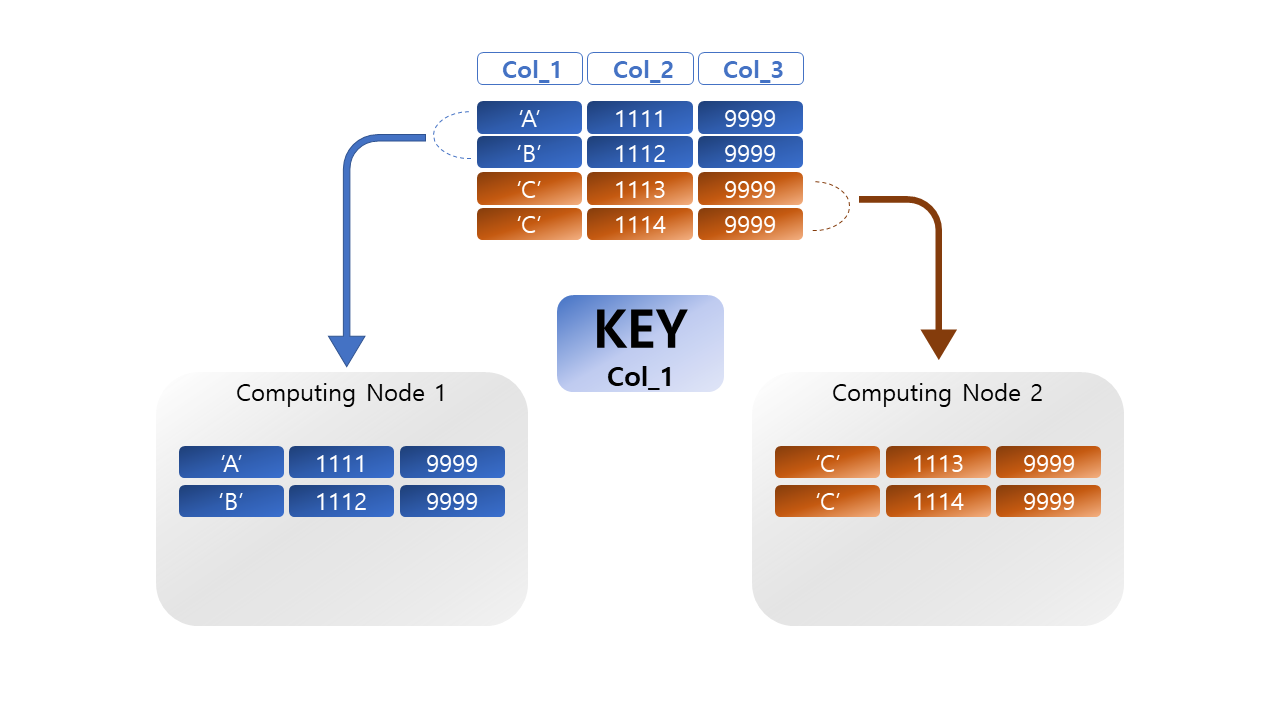
분산키(Distkey)를 활용하여 테이블의 단일의 칼럼 값을 기준으로 데이터를 분산하는 방식이다. 분산키로 설정된 칼럼의 해시 값을 통해 데이터가 저장될 각 컴퓨팅 노드의 슬라이스가 선택된다. 즉 분산키의 같은 값을 가지는 데이터(row)는 같은 슬라이스에 저장되게 된다.
키분산을 사용하는 경우는, 테이블의 크기가 전체분산을 사용하기에는 너무 크고 분산키로 사용할 컬럼이 명확한 경우이다. 특히, 키분산은 join이 자주 일어나는 팩트 테이블과 차원테이블에 적합하다.
여기서, 분산키로 사용하기에 명확한 칼럼은 첫째, Cardinality가 높은 칼럼이어야 하며 둘째, Join에서 자주 사용되는 칼럼이어야 한다. Cardinality가 높지 않으면 데이터 스큐현상이 발생하여 컴퓨팅 노드의 작업량이 균등하게 분배되지 못한다. 또한, Join에서 자주 사용되는 칼럼이 분산키로 사용된다면 네트워크 비용 없이 각 컴퓨팅 노드에서 할당된 작업을 수행할 수 있다. OLTP의 원천 마스터 테이블의 PK (= Naturla Key)가 존재한다면, OLAP의 차원 테이블에서도 분산키로 사용하기 적절하다.
CREATE TABLE diststyle_key_dim
(
col_1 varchar,
col_2 int,
col_3 int
)
DISTSTYLE KEY
DISTKEY col_1
;- AUTO (자동)
분산방식을 지정하지 않고, Redshift에서 자체적으로 분산방식을 지정해주는 방식이다.
