🌚 쿼리 분석이란?
쿼리분석(프로파일링)이란 쿼리가 어떻게 실행되는지 분석하는 작업을 의미한다.
쿼리 분석을 위해서는 쿼리 실행계획 (Explain)을 면밀하게 분석할 수 있어야 한다.
쿼리 플래너가 항상 최고의 실행 계획을 작성하는 것은 아니므로, 쿼리 플랜을 분석한 이후 실제 실행된 쿼리의 결과를 검토할 필요성도 있다.
🌝 Redshift 쿼리 실행 플로우
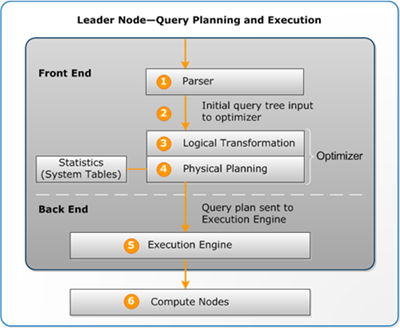
1) Leader Node에서 쿼리를 수신하고 SQL 구문을 분석한다.
2) 리더 노드의 Parser는 쿼리를 파싱해서 쿼리 문법에 문제가 없는지를 분석하고, 이 과정에서 생성된 쿼리 트리를 옵티 마이저에게 전달한다.
3) 옵티마이저가 평가를 거쳐 쿼리 트리를 최적화된 구조로 재구성한다.
4) 옵티마이저가 시스템 테이블의 통계 정보를 이용해서 쿼리 실행 계획을 작성한다.
옵티마이저가 정확한 쿼리 플랜을 생성하기 위해서는 시스템 테이블의 통계 정보가 최신화되는 것이 중요하다. 따라서 테이블 스키마 또는 데이터 변경 시, 테이블의 통계 메타 데이터를 Analyze를 통해 업데이트하는 것이 중요하다. ( [아래사진] Analyze가 실행되지 않은 테이블에 대해 explain 실행한 경우 )

쿼리계획이 조인유형, 조인순서, 집계옵션, 데이터분산 요건 등 실행 옵션을 지정한다.
Explain 구문을 통해 반환되는 값은, 현 단계까지 작성된 쿼리 실행계획이다. 즉, 실제 컴퓨팅 노드에서 실행되는 쿼리가 아닌 리더노드에서 옵티마이저로 작성된 쿼리 실행계획이 결과값으로 반환되는 것이다.
5) 실행 엔진이 쿼리 계획을 스트림,세그먼트,단계로 변환한다.
스트림(Stream) : 세그먼트의 묶음. 쿼리는 하나 이상의 세그먼트로 구성된다.
세그먼트(Segment) : 슬라이스에서 병렬 처리 가능한 스텝의 묶음. 즉 컴퓨팅 노드의 슬라이스에서 실행할 수 있는 가장 작은 컴파일 유닛이다.
단계(Step) : 가장 세밀한 작업 단위. 쿼리 실행 시 필요한 개별 작업을 의미한다.
실행엔진은 스트림,세그먼트,스트림을 기준으로 C++ 컴파일 코드를 작성한다. 컴파일 코드는, 인터프리터 코드보다 실행 속도가 빠르다. 이렇게 작성된 컴파일 코드는 컴퓨팅 노드로 브로드 캐스팅 된다.
또한, 컴파일 코드는 리더 노드의 캐시 메모리에 LRU(least-Recently-Used)방식으로 저장된다.
6) 컴퓨팅 노드의 슬라이스가 쿼리 세그먼트를 병렬 방식으로 실행한다. 이때 한 쿼리 계획 단계(스트림)의 중간 결과를 다음 쿼리 계획 단계(다음 스트림)로 전달하여, 다음 쿼리 실행 속도를 높일 수 있게 한다. 5,6 단계는 각 스트림 단위로 발생한다. 엔진은 스트림 마다 실행 가능한 세그먼트를 생성하여 컴퓨팅 노드로 전달한다.
End) 컴퓨팅 노드에서 작업을 마치면 최종 처리를 위해 쿼리 결과를 다시 리더노드로 보낸다. 리더 노도는 수신되는 데이터를 단일 결과 집합으로 병합하여 필요에 따라 정렬,집계,제한 등을 실행한다. 마지막으로, 결과를 클라이언트에게 보내준다.
🌛 Redshift 쿼리 실행 계획 구성
1. Operator
1.1) 화살표 행은 하나의 오퍼레이터(=연산자)이다.
1.2) XN, LN
- XN (Execution On Computing Node) : 컴퓨팅 노드에서 실행되는 오퍼레이터
- LD (Execution On Leader Node) : 리더 노드에서 실행되는 오퍼레이터
2. Cost, Rows, Width
2.1) Cost(A..B) : 상대적 작업 비용. 여기서 비용이란 계획 내 각 단계의 상대적 실행 시간을 비교하는 척도이다. 따라서, 서로 다른 실행 계획 간 비용 비교는 무의미하며, 동일 계획 내에서 가장 많은 리소스를 사용하는 작업을 구별하는 용도로 사용된다.
비용은, 아래의 작업에서 위 방향으로 누적되는 값이다. 따라서, 갑자기 비용 값이 커지는 구간을 구별하여 해당 구간의 쿼리의 문제점을 파악하는 것이 중요하다.
A : 작업 시작부터 첫 결과를 반환하는데 걸리는 비용
B : 작업시작부터 마지막 결과를 반환하는데 걸리는 비용
2.2) Rows : 오퍼레이터 작업 예상 결과 레코드 수
2.3) Width : 오퍼레이터 작업 예상 결과 평균 레코드 크기 (Byte)
3. 오퍼레이터의 종류
3.1) 스캔 오퍼레이터 (Scan Operator)
- Sequential Scan (Seq Scan) : 테이블의 첫 행부터 끝 행까지 순차적으로 조회하면서 조건절의 필터를 적용하는 것이다. RDBMS의 Full Scan과 유사한 오퍼레이션이다. 테이블 전체를 스캔하기 때문에, disk spill이 발생할 가능성이 높다.
Disk spill이란?
데이터의 크기가 커서 메모리 용량이 부족한 경우, 일부 데이터를 디스크에 저장하여 데이터를 처리하는 기술.
- Subquery Scan : Union을 사용하는 경우 서브 쿼리를 스캔.
- Subplan : In 조건을 사용하는 경우, In 절의 서브 쿼리 스캔
- Multi Scan : Union All을 사용하는 경우 스캔
3.2) 해쉬 오퍼레이터 (Hash Operator) : 해시 테이블을 생성하여 작업하는 오퍼레이터. 해시 테이블의 크기에 따라서 디스크 스필의 가능성이 있다. Hash Join과 Hash Aggregate 오퍼레이터에서 사용된다.
3.3) 조인 오퍼레이터 (Join Operator) : 테이블 속성과 통계정보를 분석하여 조인 오퍼레이터에서 사용할 외부 테이블과 내부 테이블을 정한다. 외부 테이블을 최대한 데이터 이동 없이 작업을 수행할 수 있는 방법을 선택한다. 데이터 이동이란, 병렬 처리를 수행하는 과정에서 디스크 사용 또는 네트워크 전송이 발생하는 것을 의미한다.
내부/외부데이터란?
A Join B의 경우,
A 외부데이터(Outer) : 사이즈가 크고 주로 팩트 테이블
B 내부데이터(Inner) : 사이즈가 작고 주로 디멘션 테이블
쿼리의 From, Join절에 명시된 테이블의 순서로는 내부/외부 데이터를 구분할 수 없다.
- Nested Loop Join: Cross Join 또는, 조인 조건이 생략되었을 때 사용된다. 데이터 양이 큰 경우에는, 지양되어야 하는 조인 방식이다.
- Hash Join : 해쉬 오퍼레이터로 조인 키가 분산 키와 정렬키가 아닌 경우 발생한다. 내부 테이블의 해쉬 테이블을 생성하고 외부 테이블 조인키의 해시 값을 생성한 해시 테이블에서 찾아 조인하다.
조인키,분산키,정렬키란?
조인키 (JOIN KEY) : 조인 조건에서 사용되는 칼럼
분산키 (DIST KEY) : Redshift에서 생성한 테이블의 분산방식이 KEY방식일 때 사용하는 분산키
정렬키 (SORT KEY) : 테이블의 데이터를 정렬하는 키로 사용되는 정렬키(Sortkey)
- Merge Join : 조인 대상 테이블의 조인키가 모두 분산키와 소트키인 경우 각 컴퓨팅 노드에서 두 테이블의 데이터가 조인키를 기준으로 동일한 노드에 저장되는 동시에 (분산키), 정렬된 상태로 저장되기 때문에(정렬키) merge 연산이 가능해진다.
한 번의 테이블 스캔으로 조인이 가능하며 가장 빠른 조인 방식이다. 네트워크 전송이 없고, hash 테이블을 만들 필요도 없다.
3.4) 집계 오퍼레이터 (Aggregation Operator)
- Aggregate : Avg, Sum 과 같은 스칼라 집계 함수에 사용된다.
- Hash Aggregate : Hash 오퍼레이터 이용해, 테이블 생성하고 데이터 집계하는 경우 사용된다. 대상 데이터는 해쉬테이블에서 정렬되지 않는다.
- Group Aggregate : 현재는 사용되지 않는다.
3.5) 정렬 오퍼레이터 (Sort Operator)
- Sort : Order By를 비롯해, Union, Distinct 등 정렬이 필요한 곳에 사용
- Merge : 정렬된 중간 데이터를 병렬로 취합하고, Merge Sort 알고리즘으로 정렬
3.6) Set 오퍼레이터 (Set Operator) : 두 개 이상의 셋 혹은 서브쿼리의 결과를 병합할 때 사용
- Except : Except, minus 쿼리에 사용. Hash 조인을 사용한다.
- Intersect : Intersect 쿼리에 사용. Hash 조인을 사용한다.
- Append : Union 쿼리 또는 Table Append에 사용
3.7) DML 오퍼레이터 (DML Operator) : 데이터를 변경할 때 (Manupulating) 사용되는 오퍼레이터
- Insert
- Delete
- Update
3.8) Network 오퍼레이터 (Network Operator) : 네트워크를 통한 데이터 전송을 위한 오퍼레이터
- 배포(Broadcast) : 데이터 전체를 모든 노드에 전송하는 경우 사용
- 분산(Distribute) : 데이터를 나누어 다른 노드의 슬라이스에 분산하는 경우 사용
- 전송(Send to Leader) : 중간 데이터를 리더 노드에 전송하는 경우 사용
3.9) Materialize 오퍼레이터 (Materialize Operator) : 중첩 조인이나 머지 조인에서 입력 데이터를 디스크에 저장하는 방식.
4. 분산방식
Join Operator에서 조인을 용이하게 하기 위해서 데이터 이동 방식(Network Operator)에 대한 메서드를 지정한다. 즉, Network Operator가 선택하는 데이터 전송 방식이다.
4.1) DS_BCAST_INNER
전체 내부 테이블의 복사본이 모든 컴퓨팅 노드로 브로드캐스팅된다.
4.2) DS_DIST_ALL_NONE
이미 내부 테이블이 DISTSTYLE ALL을 사용하여 모든 노드에 분산되었기 때문에 재분산이 필요 없는 겨우
4.3) DS_DIST_NONE
두 테이블 모두 재분산되지 않는 경우. 해당 조각이 노드 간 데이터 이동 없이 조인되기 때문에 공동 배치되는 조인도 가능하다.
4.4) DS_DIST_INNER
내부 테이블이 재분산되는 경우
4.5) DS_DIST_OUTER
외부 테이블이 재분산되는 경우
4.6) DS_DIST_ALL_INNER
외부 테이블이 DISTSTYLE ALL을 사용하기 때문에 내부 테이블 전체가 단일 조각으로 재분산되는 경우.
4.7) DS_DIST_BOTH
두 테이블 모두 재분산되는 경우.
분산방식의 이상적 순위
테이블의 크기, 디스크 사용 여부 등에 따라서 성능의 차이는 존재하지만 내부테이블의 크기가 외부테이블에 비해 매우 작은 경우와 컴퓨팅 노드의 갯수가 그렇게 많지 않은 경우로 가정했다.
- c.DS_DIST_NONE : MPP Redshift를 가장 이상적으로 사용한 경우
- b.DS_DIST_ALL_NONE : 전체 재분산으로 용량은 많이 차지했지만, JOIN 성능은 빠른 경우
- d.DS_DIST_INNER : 비교적 크기가 작은 내부 테이블만 재분산되는 경우
- a.DS_BCAST_INNER : 비교적 크기가 작은 내부 테이블이 전체 노드로 배포. 내부 테이블의 크기가 작은 경우는 괜찮지만, 크기가 큰 경우에는 클러스터 성능에 영향을 주고 디스크 점유율도 높아진다.
- e.DS_DIST_OUTER : 비교적 크기가 큰 외부 테이블이 재분산되는 경우
- f.DS_DIST_ALL_INNER : 내부 테이블만 전체 배포되지만, 비교적 크기가 큰 외부 테이블이 전체 분산되어 있는 경우로, 이미 차지하는 용량이 큰 경우이다.
- g.DS_DIST_BOTH : 두 테이블이 모두 재분산되는 경우로 가장 비이상적인 경우.
출처
