[0] 시작하며 ...
컴퓨터 공학과에서 공부를 하며 3학년때 알고리즘 수업을 처음 들었는데 당시에는 어렵고 필요성을 크게 느끼기 힘든 과목이었다.
하지만 4학년에 들어서서 스타트업 기업에서 백엔드 개발자로 반년넘게 인턴쉽을 해보고 DSC 에서 다양한 프로젝트를 진행하면서 컴퓨터 엔지니어가 되기 위해서는 알고리즘에 대해 진심으로 이해하고 사랑해야 한다는 것을 느꼇다.
컴퓨터 엔지니어는 문제를 컴퓨팅 프로그램을 통해 해결하는 사람이고, 알고리즘은 문제를 컴퓨터가 해결 할 수 있도록 단계별 절차를 세우는 것이다.
알고리즘 공부는 현실의 다양한 문제를 바라보는 시각의, 그 한 틱을 바꾸고 해결방안을 제시한다.
알고리즘이란?
현실의 다양한 (어쩌면 상상속의) 문제를 푸는 독특한 단계별 절차가 있을 수 있다.
문제를 풀어내는 다양한 기법과 적용방법을 이해하고 익혀두면 문제를 쉽게 해결 할 수 있는 케이스별 전략을 세운것이다.
내가 생각하는 알고리즘의 핵심은, 문제를 컴퓨터적으로 바라보고 가능한 다양한 해결 방법을 제시한 뒤 해결 방법간 효율성 비교를 통해 최적의 문제 해결 방법을 찾아내는 것이다.
이를 위해 먼저 알고리즘의 효율성을 판단할 수 있는 중요한 기술인 시간 복잡도 계산에 대해 공부해보았다.
[1] 시간 복잡도 분석
문제를 해결하기 위해 설계한 알고리즘이 얼마나 효율적으로 문제를 풀어내는가에 대한 지표를 제시하고 판단의 근거를 세우기 위해 시간 복잡도 분석을 수행한다.
이는 시간을 수행 기준으로 컴퓨터 성능과 프로그래밍 언어의 차이에 영향 받지 않는 측정법을 적용한 분석법이다.
(CPU 를 포함한 컴퓨터의 성능, 프로그래머의 프로그램 작성 방식, 실행하는 모든 명령문의 개수 등등과 독립적인 측정 방법)
이런 독립적인 시간 복잡도 분석 지표에는 2가지가 있다.
- 입력크기 (input size)
- 단위연산 (basic instruction)
시간복잡도 분석(time complexity analysis)는 입력크기를 기준으로 단위연산을 몇 번 수행하는지 계산하는 것
1. 일정 시간복잡도 (every-case time complexity)
입력값에 상관없이 항상 단위연산의 실행 횟수가 동일한 경우, 을 알고리즘의 일정 시간복잡도라고 한다.
이런 을 구하는 과정을 일정 시간복잡도 분석이라고 한다.
일정 시간복잡도 분석의 개념을 몇가지 예시를 통해 이해해보았다.
배열 원소 모두 더하기
1) 단위연산 : 배열의 원소를 에 더함
2) 입력크기 : 배열의 원소 개수
number sum(int n, const number S[]){
index i;
number result;
result = 0;
for (i=1; i<=n; i++)
result = result + S[i];
return result;이 문제에서 제어에 필요한 명령문 (++)을 제외하고 루프안의 명령문은 원소를 에 더하는 명령문이므로 해당 명령문을 단위연산으로 한다.
따라서 배열의 각 원소의 값에 무관하게 for 루프는 반드시 n 번(배열의 크기) 만큼 실행된다.
이를 일정 시간복잡도로 나타내면
2. 최악 시간복잡도 (worst-case time complexity)
대부분의 알고리즘이 입력값에 상관없이 일정한 시간복잡도를 갖지는 않는다. 따라서 시도 할 수 있는 다양한 계측방법이 존재하는데 그 중 하나가 단위연산을 수행하는 최대 횟수를 계산하는 것이다. 이를 최악 시간복잡도라고 한다.
을 최악 시간복잡도로 표기하고, 만약 이 존재하면 = 이 된다.
순차 검색
1) 단위연산 : 배열의 원소와 와의 비교
2) 입력크기 : 배열의 원소 개수
void seqsearch( int n,
const keytype S[],
keytype x,
index& location){
location = 1;
while (location <= n && S[location] != x)
locaiton ++;
if(location > n)
location = 0;
} 가 배열의 마지막 원소이거나 가 주어진 입력 배열내에 존재하지 않을 경우, 단위연산을 번 수행하고 이것이 가장 많이 단위연산을 수행하는 횟수이다.
따라서, 최악 시간복잡도는 =
3. 평균 시간복잡도 (average-case time complexity)
최악의 경우에 대한 분석으로 알고리즘의 최대 실행시간을 알 수 있지만, 특정 경우에는 평균적으로 얼만큼의 시간이 걸리는지에 대해 측정하는 것이 옳은 경우도 있다.
이를 평균 시간복잡도라고 하며, 으로 표기한다.
이런 평균 시간복잡도를 계산하기 위해서는 입력값에 대해 확률을 부여해야한다. 여기서의 확률은 가용한 모든 정보를 동원하여 부여 할 수록 올바른 평균 시간복잡도 계산이 가능하다.
최악 시간복잡도 측정과 마찬가지로 순차 검색 알고리즘을 통해 평균 시간복잡도에 대해 이해해보았다.
순차 검색
1) 단위연산 : 배열의 원소와 와의 비교
2) 입력크기 : 배열의 원소 개수
void seqsearch( int n,
const keytype S[],
keytype x,
index& location){
location = 1;
while (location <= n && S[location] != x)
locaiton ++;
if(location > n)
location = 0;
}위 알고리즘의 평균 시간복잡도를 계산하기 위한 가정은
1. 에 있는 원소는 모두 다르다.
2. 가 특정 위치에 있을 확률이 다른 위치에 있을 확률보다 높을 이유가 없다.
3. 가 배열에 존재 할 확률은 이다.
위의 가정에 의해 인 모든 에 대해 가 배열의 번째에 위치할 확률은 이다.
따라서
4. 최선 시간복잡도 (best-case time complexity)
마지막 형태의 시간복잡도 분석은 단위연산을 실행하는 최소 횟수를 구하는 계측법이다.
어떤 알고리즘에 대해 을 입력 크기 에 대해 그 알고리즘이 수행되는 단위연산의 최소 횟수로 정의한다.
마찬가지로 순차 검색 알고리즘에 대해 최선 시간복잡도를 계산해보았다.
순차 검색
1) 단위연산 : 배열의 원소와 와의 비교
2) 입력크기 : 배열의 원소 개수
void seqsearch( int n,
const keytype S[],
keytype x,
index& location){
location = 1;
while (location <= n && S[location] != x)
locaiton ++;
if(location > n)
location = 0;
} 이기 때문에, while 루프는 반드시 한번 수행되어야한다.
만약 일 경우 의 크기에 상관없이 루프의 수행 횟수는 1이다.
따라서,
[2] 복잡도 함수와 차수
알고리즘의 분석에서는 이론적으로 궁극적인 증가상태만을 따져 좋고 나쁨 혹은 성능을 판단한다.
따라서 알고리즘의 시간복잡도의 복잡도 함수(complexity function)을 계산하고 복잡도 함수의 궁극적인 증가상태에 따라 어떻게 알고리즘을 구별하고 비교하는지에 대해 이해하는 것이 중요하다.
복잡도 함수란?
양의 정수에서 양의 실수(0 포함!)로 맵핑하는 함수를 말한다.
표준 시간복잡도 분석에서는 이런 복잡도 함수를 표준 함수 표기법을 통해 혹은 으로 표기한다.
차수란?
위에서 설명한 복잡도 함수의 차수를 의미한다.
예를 들어 나 같은 복잡도 함수의 경우 순수 2차 함수 (pure quadratic function) 이라 하고 해당 함수의 차수는 2이다.
과 같이 1차항을 포함하는 2차 함수의 경우 완전 2차 함수 (complete quadratic function) 이라고 하는데, 궁극적으로 증가상태만을 따진다면 최고항이 함수의 결과에 영향을 미침을 알 수 있다.
위에서 설명한 것을 수식으로 표현 할 수 있는데,
어떤 복잡도 함수가 에 속할 때, 의 차수가 k 일 경우 복잡도 함수 의 차수를 k 라고 한다.
이런 서로소 집합을 복잡도 카테고리 (complexity categories) 라고 하는데 이것은 조금더 다양한 개념을 익혀야 이해 할 수 있다.
차수에 대해 더 자세하게 알아보자!
위에서 차수를 더 엄밀하게 정의하고 정확하게 이해하기 위해서는 몇가지 기본 개념을 익혀야 한다구 했다.
그런 개념들을 공부하고 이해해보았다.
[1] 큰 O (big O)
큰 O(big O)
주어진 복잡도 함수 에 대해서 은 정수 이상의 모든 에 대해서 다음 부등식이 성립하는 양의 실수 와 음이 아닌 정수 이 존재하는 복잡도 함수 의 집합이다.
만약 이 에 속하면, "" 라고 말한다.
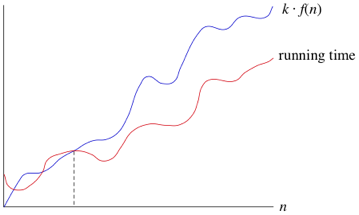
이게 무슨말인지 처음에는 이해가 잘 안되었는데 그래프의 예시를 보고나니 바로 이해 할 수 있었다.
과 running time 는 이후에서 을 만족하게 된다.
따라서, 정수 이상의 모든 에 대해서 위의 부등식이 성립하므로, "" 라고 할 수 있다!
잘 보면, big O 의 성립여부를 판단하기 위해서는 부등식을 만족하는 상수 c와 정수 N을 찾는것이 핵심임을 알 수 있다.
하나더 추가적으로 알 수 있는것은 big O는 결국 함수의 궁극적인 상태만을 고려하고 상한을 표현하는것이라 할 수 있다. 여기서 궁극적인 상태만을 고려한다는 것을 asymptotic(점근적인) 인 성질이라고 하고, 상한을 표현하는 것을 upper bound(상한) 성질이라고 한다. 즉, big O 는 asymptotic upper bound(점근적 상한) 이라고 한다.
여기서 내가 만든 알고리즘의 시간 복잡도 함수가 이고, 이 알고리즘이 에 속한다고 하면, 은 궁극적으로 아래에 놓이게 된다는 것을 알 수 있따. 그래서 상한이라고 한다!
만약 이 라면 은 궁극적으로 그래프 상에서 어떤 순수2차함수 아래에 놓이게 된다. 이 시간복잡도였으면 결국에는 이 알고리즘의 실행시간의 빠르기가 최소한 순수2차함수만큼 된다는 것을 알 수 있다는 것이다.
[2] 오메가 (omega)
오메가 (omega)
주어진 복잡도 함수 에 대해서 은 정수 이상의 모든 에 대해서 다음 부등식이 성립하는 양의 실수 와 음이 아닌 정수 이 존재하는 복잡도 함수 의 집합이다.
만약 이 에 속하면, "" 라고 말한다.
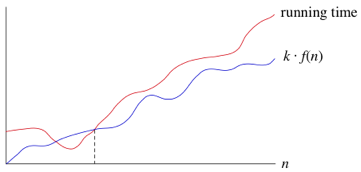
과 running time 는 이후에서 을 만족하게 된다.
따라서, 정수 이상의 모든 에 대해서 위의 부등식이 성립하므로, "" 라고 할 수 있다!
big O 때와 마찬가지로 오메가의 핵심은 의 정의조건을 만족하는 상수 와 이 유일할 필요가 없다는 점이다. 이는 다시 생각하면 의 정의조건을 만족하는 어떤 이후의 에 대해서 은 궁극적으로 위에 놓이게 되므로 이런 , 을 의 asymptotic lower bound(점근적 하한) 이라고 한다.
결론을 내리자면, 만약 이 에 속하면 은 궁극적으로 최소한 만큼은 나쁘다! 라고 할 수 있다.
[3] 세타 (theta)
위에서 배운 big O 와 오메가의 개념을 알고나면 세타, 즉 차수에 대해 정확한 정의를 내릴 수 있다.
세타(theta)
주어진 복잡도 함수 에 대해서 다음과 같이 정의한다.
는 이상의 모든 정수 에 대해서 다음 부등식이 만족하는 양의 실수 와 음이 아닌 정수 이 존재하는 복잡도 함수 의 집합이다.
여기서 차수란?? 위의 조건을 만족하는 즉 이라면, " 은 의 차수(order)이다" 라고 말한다.
[4] 작은 O (small o)
작은 O(small o)
주어진 복잡도 함수 에 대해서 은 모든 양의 실수 에 대해서 을 만족하는 모든 에 대해 다음의 부등식을 만족하는 음이아닌 정수 이 존재하는 모든 복잡도 함수 의 집합이다.
만약 라면 은 의 작은 오 라고 부른다. 위에서 배운 큰 오와 오메가의 정의와는 차이가 분명히 존재한다.
큰 오 와 오메가는 그 범위가 성립하는 "어떤" 양의 실수 가 반드시 존재함을 의미한다. 부등식을 성립시키는 의 존재가 핵심임을 의미한다. 하지만 small o 는 "모든" 양의 실수 에 대해서 그 범위가 성립해야한다.
따라서 분석의 관점에서 다시 이해해본다면, 이 일때 은 같은 함수 보다 궁극적으로 훨씬 좋다고 볼 수 있다.
차수의 특성
-
은 과 서로 필요충분조건 이다.
-
은 과 서로 필요충분조건 이다.
-
이고 이면, 이 성립한다.
이 특성은 모든 대수 복잡도 함수들은 같은 복잡도 함수에 속함을 의미한다. -
이면, 이 성립한다.
-
인 모든 에 대해서 이 성립한다.
-
의 복잡도 카테고리에 대해,
여기서 이고 이다. 만약 복잡도 함수 이 을 포함한 카테고리의 왼쪽에 위치한다면, 이 성립한다.
이 특성은 대수 함수는 모두 다항식 보다 궁극적으로 빠르고, 다항식은 모두 지수 함수보다 궁극적으로 빠르며 지수함수는 모든 계승(factorial) 함수보다 빠름을 의미한다. -
이고 이고 이고 이면, 이 성립한다.
이 특성과 6번의 특성을 반복 적용하여 복잡도 함수의 의 차수는 결국 높은 차수를 따라
극한과 차수
차수를 결정하는데 극한을 사용 할 수 있다!
극한을 사용하면 차수를 쉽게 결정 할 수 있다. 예를들어 위에서 배운 차수의 특성 4번을 극한을 통해 증명하면,
, 따라서 위의 정의에 따라 차수의 특성 4번이 만족함을 알 수 있다.
[3] 마무리하며 ..
알고리즘을 배우며 얘가 얘보다 뭐가 나은지 판단할 기준을 가장 먼저 익히는 것이 맞다고 생각하였다.
위에서 차례로 이해했다고 하지만 복잡한 알고리즘의 경우에는 어떻게 단위연산을 정하고 입력크기를 무엇으로 잡을지에 대한 부분이 어려움에는 변함이 없는 것 같다.
앞으로 분할정복과 탐욕접근법, 되추적 등의 알고리즘 레퍼토리를 공부하고 정리할려 하는데 그때 마다 복잡도를 계산하고 비교해보며 연습하는 과정이 필수적일 것 같다!
