Repository Pattern
Repository Pattern 이란?
정의
리포지토리는 데이터 원본에 액세스하는 데 필요한 논리를 캡슐화하는 클래스 또는 구성 요소입니다. 리포지토리는 공통 데이터 액세스 기능에 집중해 더 나은 유지관리를 제공하고 도메인 모델 계층에서 데이터베이스에 액세스하는 데 사용되는 기술이나 인프라를 분리합니다. Entity Framework와 같은 ORM(개체 관계 매핑)을 사용하는 경우 LINQ 및 강력한 형식화 덕분에 구현해야 할 코드가 간소화됩니다. 이렇게 하면 데이터 액세스 내부 작업보다 데이터 지 속성 논리에 더 집중하게 합니다.
위의 말에서 중요한 부분은 “데이터 원본에 액세스 하는데 필요한 논리를 캡슐화 하는 클래스 혹은 구성 요소” 이다. 캡슐화란 data field 와 methods 를 묶어 실제 구현 내용을 감추는 것으로, 나는 이 문장을 다시 해석하면 “데이터 원본을 가져오거나 저장하는 등의 속성 및 행위를 특정 클래스에 위임하는 것" 이라고 생각한다.
캡슐화의 목적을 이해한다면 Repository Pattern 이 무엇을 하기 위함인지 이해 하기가 쉬울 것 같다. 캡슐화를 객체지향적 관점 중 “상태와 행위의 캡슐화” 측면에서 이해했을 때 데이터 원본에 대한 액세스를 캡슐화함으로서 데이터 원본 액세스의 모든 가능한 행위 중 필요한 특정 행위에 대해 인터페이스를 제공하고, 이는 곧 비즈니스 로직과 데이터 액세스 로직의 분리를 의미한다.
비즈니스 로직이 어떤식으로 데이터 원본 저장소에 엑세스하는지, 세부 로직이 어떻게 구성되어야 하는지 알 필요가 없다. 따라서 비즈니스 로직에서는 전달하고자 하는 데이터를 가공, 처리하는데 집중 할 수 있다.
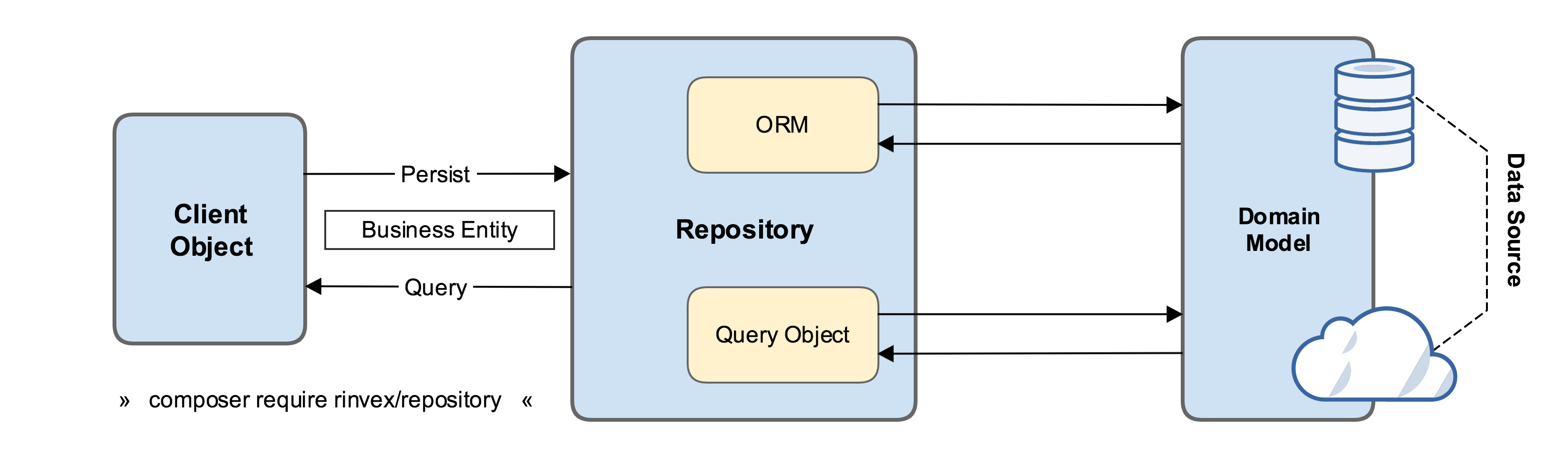
도식으로 보기
Simple Repository Pattern

출처 : https://stackoverflow.com/questions/38818916/repository-pattern-with-laravel-5
좌측의 비즈니스 로직은 클라이언트로부터 받은 요청을 처리하기 위해 데이터베이스 레이어에 접근해야 한다. 위에서 언급한 데이터 원본에 액세스 해야 하는 것이다.
Repository 가 없었다면 비즈니스 로직에서 직접 DB Context 를 처리하여 데이터 원본에 액세스해 요청을 처리 했을 것이다. 하지만 Repository 가 존재하면 위의 도식처럼 비즈니스 로직과 레파지토리간의 정해진 데이터 요청이 오가고 레파지토리리는 해당 시점에 정해진 도메인에 대해 원본 데이터를 처리해 다시 비즈니스 로직에게 반환한다.
추상화와 캡슐화는 구조적으로 많은 이점을 가져다준다. 수정사항이 전반적인 시스템에 미치는 영향을 제한하기 때문이다. 마찬가지로 비즈니스 로직과 데이터 원본 사이에 위치해 데이터 원본 액세스 레이어를 캡슐화하고 구현해야 할 액세스 로직을 추상화 함으로서 DB 구현에 대한 관심사를 분리 할 수 있다.
정리
| 정의 | 데이터 원본에 액세스 하는데 필요한 논리를 캡슐화 하는 클래스 혹은 구성 요소 |
|---|---|
| 장점 | 1. 비즈니스 로직에 대한 집중 (관심사의 분리) 2. 데이터의 일관성 유지 (repository → interface ← business logic) 3. 데이터 원본이 레파지토리를 통해 캡슐화 되어 있으므로 단위 테스트 용이 |
| --- | ------------------------------------------------------------------- |
| 단점 | 1. business logic → repository ← data source 인데 추상화 단계가 중간에 추가되었으므로 코드 및 파일의 수가 증가 |
Repository Pattern 의 구현
Nest.js 로 구현하기 위한 사전 준비
- pakage.json
"@nestjs/typeorm": "8.1.3"
"typeorm": "0.3.6"@nestjs/typeorm 의 버전이 8 로 넘어가며 @EntityRepository 가 사라지고 기존 Repository 를 상속하여 구현하는 것으로 변경되어 실제 구현에도 큰 차이가 있다. 버전에 유의해야 한다.
- tsconfig.json
{
"experimentalDecorators": true,
...
}우리가 구현할 커스텀 레파지토리의 메타 데이터를 설정하기 위해 필요하다. 기본적으로 Nestjs 프로젝트에서는 True 로 설정되어 있지만 확인해야 할 필요가 있다.
Nest.js 로의 구현
Nestjs 는 TypeORM 을 지원한다. TypeORM 은 레파지토리를 통해 데이터베이스에 엑세스하므로 기본적으로 TypeORM 을 사용할 경우 레파지토리 패턴을 사용한다고 할 수 있다.
하지만 이번에 구현할 사항은 구조적으로 비즈니스 로직인 example.service.ts 와 example-entity.repository.ts 를 분리하여 온전히 비즈니스 로직은 데이터의 처리에 집중하고 레파지토리는 데이터 엑세스 및 조회를 수행하도록 해본다.
Nestjs 의 레파지토리 구현의 핵심은 아래 5개의 구현에 있다.
-
example.module.ts
밀접한 기능상 연관이 있는 부분들이 조립된 코드, @Module 데코레이터를 통해 애플리케이션 구조 구성에 필요한 메타 데이터를 가진 클래스
-
example.service.ts
복잡한 비즈니스 로직 처리를 담당하는 코드, @Injectable 데코레이터를 통해 종속성으로 타 클래스에 주입 가능한 클래스
-
example.entity.ts
실체, 객체로 TypeORM 을 통해 데이터베이스 테이블에 매핑되는 클래스로 @Entity 데코레이터와 함꼐 정의 된다.
-
example.repository.ts
TypeORM 의 Repository 를 상속하여 구현하며 데이터 원본 액세스 로직을 묶은 클래스이다.
-
custom-repository.provider.ts
기타 필요한 메타데이터와 Entity class 를 가져와 Repository Class 를 특정 모듈에 주입하기 위한 Provider 를 제공하는 클래스이다.
위의 구현사항은 이리 저리 코딩을 하다 Nestjs + TypeORM + Repository Pattern 을 구현하기 가장 적합한 구조라고 생각되어 현재 사용중인 구현 방법이다.
하나씩 간단한 샘플 코드를 보며 어떤식으로 Nest.js 에서 실제로 구현 할 수 있는지 알아보자!
- car.entity.ts
typeORM 공식 사이트에서 제공하는 레퍼런스대로 필요한 테이블을 Entity Class 로 정의하고 데이터를 맵핑한다.@Entity('car') export class Car { @PrimaryColumn() car_id: number; @Column() price: number; @Column() name: string; ... }
- car.service.ts
Repository Pattern 은 조금 더 크고 복잡한 비즈니스 로직에 적합하지만, 여기서는 구조에 대한 설명을 위해 nestjs/cli 로 생성한 리소스 패키지를 기준으로 생성했다.import { Inject, Injectable } from '@nestjs/common'; import { CreateCarDto } from './dto/create-car.dto'; import { UpdateCarDto } from './dto/update-car.dto'; import { CarRepository } from './repositories/car.repository'; @Injectable() export class CarService { constructor( @Inject(Symbol(,,,) private readonly carRepository: CarRepositoryIntf ) ){} create(createCarDto: CreateCarDto) { return 'This action adds a new car'; } findAll() { return `This action returns all car`; } findOne(id: number) { return `This action returns a #${id} car`; } update(id: number, updateCarDto: UpdateCarDto) { return `This action updates a #${id} car`; } remove(id: number) { return `This action removes a #${id} car`; } }
- car.repository.ts
데이터베이스 엑세스를 하고자 하는 동작에 대해 정의한다. 기본적으로 상속받은 Repository 클래스에서 다양한 쿼리 빌더 메소드를 제공한다. 하지만 비즈니스 로직의 데이터 원본 엑세스를 레파지토리 클래스로 제한하기 위해 필요한 부분만 인터페이스로 노출하여 제공하도록 한다.@UsingRepository(Car, Symbol('car-repository')) export class CarRepository implements CarRepsoitoryIntf extends Repository<Car> { async createCar(createCar: CreateCar) { ... } }
- custom-repository.provider.ts
원래는 커스텀 데코레이터로 메타 데이터를 잘 설정하지는 않는다. 단순히 코드만 보았을 때 해당 객체에 어떤 메타 데이터가 숨어있는지 한눈에 파악하고 다음 로직을 설계하기가 쉽지 않아서 였다. 하지만 이번에 Repository 를 범용적으로 주입 할 수 있는 제공자 클래스를 만들며 데코레이터가 오히려 구조적인 측면에서 코드의 가독성을 높여준다는 것을 알게되었다. 앞으로 종종 사용 할 것 같다. 어쨋든, 엔터티 타입, 레파지토리 클래스를 주입할때 사용할 Symbol 등을 데코레이터로부터 뽑아오고 이것을 기반으로 레파지토리 클래스를 구성한다. 여기서 데이터베이스 엑세스 로직을 구성하는데, inject 한 getDataSourceToken 을 사용해 도메인을 갈아 끼울 수 있다.export const CustomRepositoryProvider = <T extends new (...args: any[]) => any>( datasourceOptions: DataSourceOptions, repository: T, ): Provider => { const entity = Reflect.getMetadata('entity', repository) as EntityTarget<T>; const repositoryToken = Reflect.getMetadata('token', repository) as symbol; return { inject: [getDataSourceToken(datasourceOptions)], provide: repositoryToken, // inject 한 TypeORM DataSource 를 가져와 사용한다. useFactory: (dataSource: DataSource) => { // dataSource 로 부터 Repository 를 가져온다. // 여기서 주의 할 점은, TypeORM Module 이 루트 모듈에 등록되어있다는 것을 상정한다는 점 const baseRepository = dataSource.getRepository<T>(entity); // 가져온 baseRepository 에서 entity Target, query Manager, query Runner 를 // Provider 의 인자로 받은 레파지토리로 넣어준다. (super) const customRepsoitory = new repository( baseRepository.target, baseRepository.manager, baseRepository.queryRunner, ); ... return customRepsoitory; }, }; };
- car.module.ts
모듈에서 위에서 만든 Provider 로 등록하여 주입한다.@Module({ imports: [...], controllers: [CarController], providers: [ { provide: CAR_SERVICE_TOKEN, useClass: CarService }, CustomRepositoryProvider(MYSQL_LOCAL_DB_OPTIONS, CarRepository), ], }) export class CarModule {}
마치며
구현한 Custom Repository 에 대한 생각 …
위에서 구현한 예시는 TypeORM 의 Repository 를 상속하여 custom repository 를 주입하여 사용하는 형태이다. 기존에는 Entity 파일로 테이블을 맵핑하고 @InjectRepository 데코레이터를 통해 service class 에서 주입 받아 사용했는데 사실 이렇게 구현하는 것도 Repository Pattern 을 적용한 것이다.
그럼에도 위와 같이 구현할 경우 체감되는 장점은 DB 액세스 쿼리들이 비즈니스 로직에서 노출되지 않는다는 점이다. 이로 인해 DB 엑세스에 대해 조금 더 독립적인, 자유로운 로직을 작성하게 된다.
그러다보니 비즈니스 로직에 대한 단위 테스트 코드를 작성 하기도 수월하고 (mock 하기가 쉬워짐) service.ts 클래스 내에는 오직 적절한 데이터 처리에 관한 로직만 포함되다 보니 가독성이 올라간다.
(기존에는 기초적인 CRUD 메소드들이 포함되어 있었다)
사실 단점도 동일한 이유에서 발생한다. 실제로 사용하면서 조금 과하게 분리하지는 않았나 하는 생각이 들었다. 사실은 기존 Repository 를 주입받아 사용하는 방식에서도 Repository pattern 으로 하고자 하는 목적은 이룰 수 있다. DB Context 는 노출되지 않으며 데이터 원본 엑세스가 캡슐화 되어 있으므로 쉽게 DB Layer 를 교체할 수 있도록 구조를 설계 할 수 있다. 위에서는 언급하지 않았지만, custom repository 가 구현해야할 메소드 인터페이스, 각 각의 메소드가 받는 인자에 대한 인터페이스, 커스텀 데코레이터 등등 추가적으로 생성해야 할 파일이나 코드의 양이 늘어난다.
실제로 위와 같이 구조를 만들어보고 관련 내용에 대해 공부하고 고민한 결과, 굳이 Custom Repository 로 분리를 한다면 이유는 관심사의 분리, 가독성면일 것 같다. 이 부분을 잘 활용하기 위해서는 꼭 Repsoitory 가 구현해야 할 대상에 대해 인터페이스로 정의하고 Repository 와 비즈니스 로직 모두 해당 인터페이스를 참조하는 형태로 구성을 해야 한다.
