1차 네트워킹 과제로 부원들에게 16개의 데이터를 담고있는 엑셀 파일을 파싱해 DB에 넣는 과제를 내줬다.
다들 큰 어려움없이 코드를 작성하여 제출해줬지만 개발자는 항상 극단적으로 생각해야 하는 법.
만약 16개가 아니라 수십만개라면...?
지금 그 코드로 잘 돌아갈까요...?
라는 의문을 가질 수 있도록 데이터 20만개를 삽입하면서 코드를 개선하는 과제를 내줬다.
https://github.com/IT-Cotato/9th-BE-Networking-3
해당 과제를 직접 수행하며 얻은 지식들을 기록하고자 한다.
1. 기존 코드
@Transactional
public String insertPropertyTestData(String path) throws InvalidFormatException, IOException {
// 엑셀 관련 코드
List<Property> propertyList = new ArrayList<Property>();
for (int i = 1; i < n; i++) {
if (i % 10000 == 0) {
System.out.println(i + "번째 삽입");
}
Row row = sheet.getRow(i);
// 문자열 관련 연산
propertyList.add(Property.builder()
.zipCode(zipCode)
.roadNameAddress(roadNameAddress)
.landLotNameAddress(landLotNameAddress)
.build());
}
propertyRepository.saveAll(propertyList);
workbook.close();
opcPackage.close();
return "Success";
}https://sjparkk-dev1og.tistory.com/232
save() vs saveAll() 에 대한 글
평범하게 saveAll()을 사용한 코드이다.
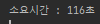
소요시간은 116초가 걸렸다.
2. Batch Insert (실패)
SQL엔 Batch Insert라는 개념이 있다고 한다.
예를 들면 세 건의 데이터를 넣을 때, saveAll()을 사용한다면 아래와 같이 세 개의 쿼리가 각각 실행될 것이다.
왜냐하면 saveAll()도 결국엔 내부적으론 save()를 순차적으로 호출하기 때문이다.
INSERT INTO table (col1, col2) VALUES (val1, val11);
INSERT INTO table (col1, col2) VALUES (val2, val22);
INSERT INTO table (col1, col2) VALUES (val3, val33);하지만 Batch Inert를 사용하면 아래와 같이 Multi-Row Insert 쿼리가 나간다.
INSERT INTO table (col1, col2) VALUES
(val1, val11),
(val2, val22),
(val3, val33);이는 성능면에서 상당한 이점을 가지는데, 보통 개별 인서트의 경우 쿼리를 실행하고 응답을 받은 후에 다음 쿼리를 전달한다.
하지만 Batch Insert의 경우 위와 같이 여러 개의 row를 하나의 쿼리에 담기 때문에 이러한 과정을 거치지 않아 성능이 뛰어나다.
하지만 일반적인 방법으론 Batch Insert가 불가능했다.
우리가 주로 사용하는 JPA + MYSQL 조합에서는 @GeneratedValue(strategy = GenerationType.IDENTITY)와 같이 Identity 전략을 사용한다.
이렇게 되면 MySQL에서는 auto_increment를 통해 키 값을 자동으로 증가시켜 준다.
따라서 우리는 엔티티를 저장할 때 아래와 같이 pk를 명시하지 않아도 된다.
propertyList.add(Property.builder()
.zipCode(zipCode)
.roadNameAddress(roadNameAddress)
.landLotNameAddress(landLotNameAddress)
.build());
propertyRepository.saveAll(propertyList);
하지만 이 방식을 사용하면 JPA의 구현체인 Hibernate는 다음으로 할당될 키 값을 미리 알 수 없고, Hibernate가 채택한 flush 방식인 'Transactional Write Behind'와 충돌이 발생해 Batch Insert를 사용할 수 없다. (참고)
3. JdbcTemplate 사용하기
다행히 Jdbc에서는 batch insert를 사용할 수 있었다.
우선 DB URL 뒤에 rewriteBatchedStatement=true를 추가해준다.
jdbc:mysql://{DB_HOST}:3306/networking?rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger해당 파라미터를 추가함으로서, 위에 설명한 Multi-Row Insert를 가능하게 한다.
profileSQL과 logger 파라미터는 log를 출력하기 위해 추가한 파라미터이다.
이제 적절한 Repository Class를 만들어준다.
@Repository
@RequiredArgsConstructor
public class PropertyBulkRepository {
private final JdbcTemplate jdbcTemplate;
@Transactional
public void saveAll(List<Property> propertyList) {
String sql = "INSERT INTO property (zip_code, road_name_address, land_lot_name_address) " +
"VALUES (?, ?, ?)";
jdbcTemplate.batchUpdate(sql,
propertyList,
propertyList.size(),
(PreparedStatement ps, Property property) -> {
ps.setString(1, property.getZipCode());
ps.setString(2, property.getRoadNameAddress());
ps.setString(3, property.getLandLotNameAddress());
});
}
}데이터 10개를 테스트로 insert 해보면 아래와 같이 로그가 출력된다.
[QUERY] INSERT INTO property (zip_code, road_name_address, land_lot_name_address) VALUES
('06306', '서울특별시 강남구 개포로25길 13-4', '서울특별시 강남구 개포동 1255-7'),
('06303', '서울특별시 강남구 개포로17길 9-3', '서울특별시 강남구 개포동 1245-5'),
('06309', '서울특별시 강남구 개포로36길 6-0', '서울특별시 강남구 개포동 1210-0')
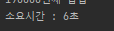
.... 이하 생략 그렇다면 해당 코드로 20만건 삽입 시간을 측정해보니 약 6초가 소요됐다.
4. Key Generation 전략을 바꾸기
아까 위에서 서술했다시피 IDENTITY 전략으론 JPA의 Batch Insert를 사용할 수 없다.
그렇다면 해당 전략을 TABLE이나 SEQUENCE로 바꾼다면 어떨까?
우선 MySQL에선 SEQUENCE 전략을 지원하지 않기에 TABLE 전략을 통해 SEQUENCE를 흉내내야한다.
TABLE 전략이란?
다음 pk값을 저장하는 테이블을 만들고, 이 테이블에서 PK를 가져온 후 다음 pk 값을 update하는 방식이다.
- 우선 엔티티를 아래와 같이 바꿔줬다.
@Entity
@Builder
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
@Getter
@TableGenerator(
name = "PROPERTY_GENERATOR", //식별자 생성기 이름
table = "sequence_table", //키 생성 테이블명
pkColumnName = "sequence_name", //시퀀스 컬럼명
valueColumnName = "next_val", //시퀀스 값 컬럼명
initialValue = 1, //초기 값
allocationSize = 200000
)
public class Property {
@Id
@GeneratedValue(
strategy = GenerationType.TABLE
, generator = "PROPERTY_GENERATOR"
)
@Column(name = "property_id")
private Long id;이 때 주의깊게 봐야할 부분은 allocationSize이다.
allocationSize란?
한 번에 증가시키는 시퀀스 값을 의미한다.
예를 들어, 현재 sequencce 값이 5이고 allocationSize가 50이라면, JPA는 sequence 값을 55로 증가시키고 5~54를 메모리에 할당한다.
이를 통해 매번 sequence 값을 가져오기 위해 sequence 테이블에 접근하지 않아도 되는 이점을 가진다.
또한, 채번 작업을 미리 해두기 때문에 여러 스프링 프로세스가 한 DB에 접근하더라도 키 값 충돌이 발생하지 않는다.
단점은 없을까?
첫 번째, 중간에 서버가 다운된다면 메모리에 할당된 시퀀스 값은 사라지기 때문에 pk 값이 비게 되지만, 일반적인 상황에서 큰 문제는 아니라고 생각한다.
지금부터 서술된 내용은 주관적인 생각이 포함되어 있습니다
두 번째, 위에서 말한 여러 스프링 프로세스가 한 DB를 사용한다고 가정하자.
A Process가 1~50, B Process가 51~100까지의 sequence 값을 각각 가져간다.
그렇다면 두 프로세스는 해당 값들에 대해 독립적으로 삽입을 수행하므로, pk 값의 증가가 데이터 삽입의 순서를 반영하지는 않게된다.
따라서, pk값이 크면 더 나중에 삽입됐을 거란 추측을 하고 query를 작성하게 됐을 때 의도하지 않은 결과가 반환될 수 있다.
5. 결론
그렇다면 이 방법들 중 무엇을 써야할까?
작년 진행했던 한이음 프로젝트에선 지하철 관련 엑셀 파일을 삽입해야했었는데, 만약 그 프로젝트를 다시 진행한다면 나는 JdbcTemplate를 사용할 것 같다.
- 초기 엑셀 데이터 삽입은 그렇게 자주 일어나지 않는다.
- 따라서 해당 작업을 위해 sequence table을 만들고 유지보수하는 것의 overhead가 크다고 판단된다.
- 하지만 jdbcTemplate는 Spring Data JPA 의존성에 기본적으로 내장되어 있으므로 별도의 설정 없이 바로 사용할 수 있다.
