
그라운드 플립?
땅따먹기 게임에서 아이디어를 얻어 걷기와 게이미피케이션을 결합한 앱이다.
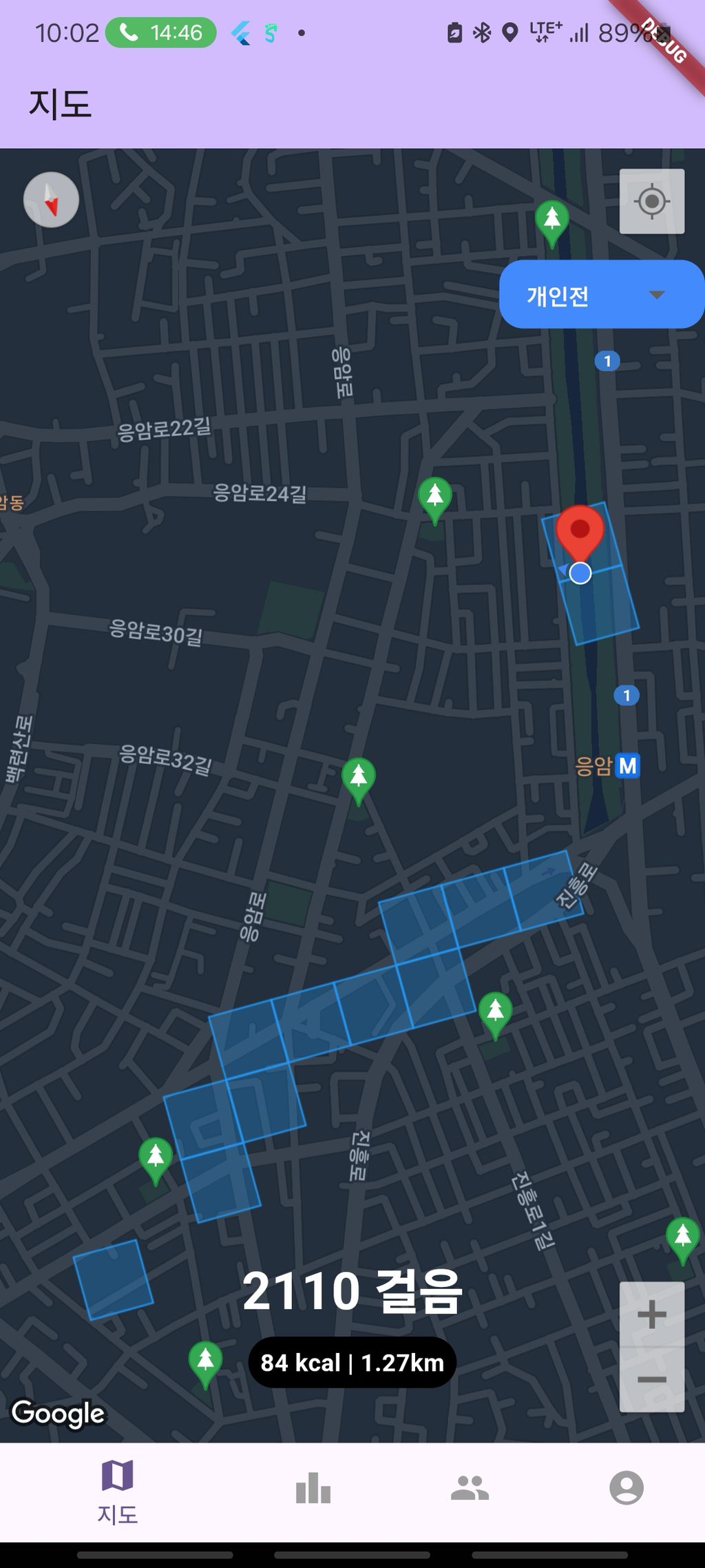
지도를 80m * 80m 크기의 정사각형으로 나누어 ‘픽셀’이라 칭하고 이 픽셀을 차지하며 경쟁하는 시스템을 가지고 있다.
가장 최근에 픽셀을 방문한 사람이 해당 픽셀의 소유자가 된다.
ERD
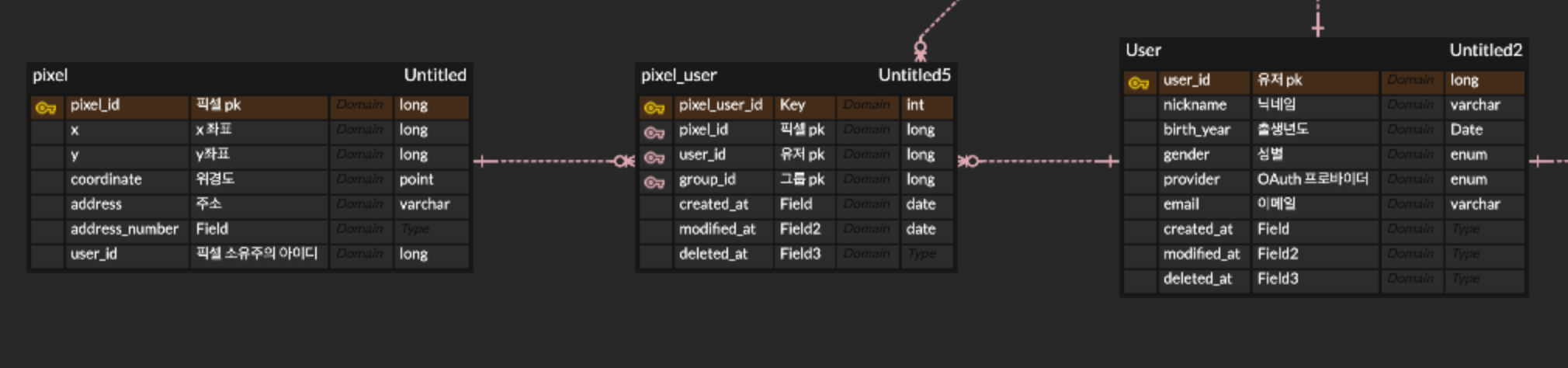
pixel 테이블
대한민국에 존재하는 모든 픽셀들에 대한 메타 데이터(픽셀의 좌표 등)가 들어있는 테이블이다.
특이사항은 아래와 같다.
-
메타데이터를 저장하기 때문에 삽입은 발생하지 않는다.
-
행의 개수는 2900만개이다.
-
현재 픽셀의 소유주를 나타내는 user_id column을 추가하여 역정규화가 진행된 상태이다.
pixel_user 테이블
어떤 사용자가 어떤 픽셀을 언제 방문했는 지 저장하는 테이블이다.
특이 사항은 아래와 같다.
-
로그와 같은 특성을 띄기 때문에 빈번한 삽입이 일어난다.
-
특정 픽셀에 대해 가장 최신의 row의 user_id가 현재 픽셀의 소유주이다.
user 테이블
사용자의 정보를 저장하는 테이블이다.
픽셀을 차지하는 과정은? (코드)
사용자가 픽셀의 경계를 넘어갈 때, 아래의 서버에 요청을 보내 아래의 메소드를 실행하게 된다.
아래 코드와 같이 픽셀을 특정하고 해당 픽셀의 user_id 컬럼을 update 후 pixel_user 테이블에 row를 삽입한다.
@Transactional
public void occupyPixel(PixelOccupyRequest pixelOccupyRequest) {
Pixel targetPixel = pixelRepository.findByXAndY(pixelOccupyRequest.getX(), pixelOccupyRequest.getY())
.orElseThrow(() -> new AppException(ErrorCode.PIXEL_NOT_FOUND));
targetPixel.updateUserId(pixelOccupyRequest.getUserId());
PixelUser pixelUser = PixelUser.builder()
.pixel(targetPixel)
.user(userRepository.getReferenceById(pixelOccupyRequest.getUserId()))
.build();
pixelUserRepository.save(pixelUser);
}랭킹
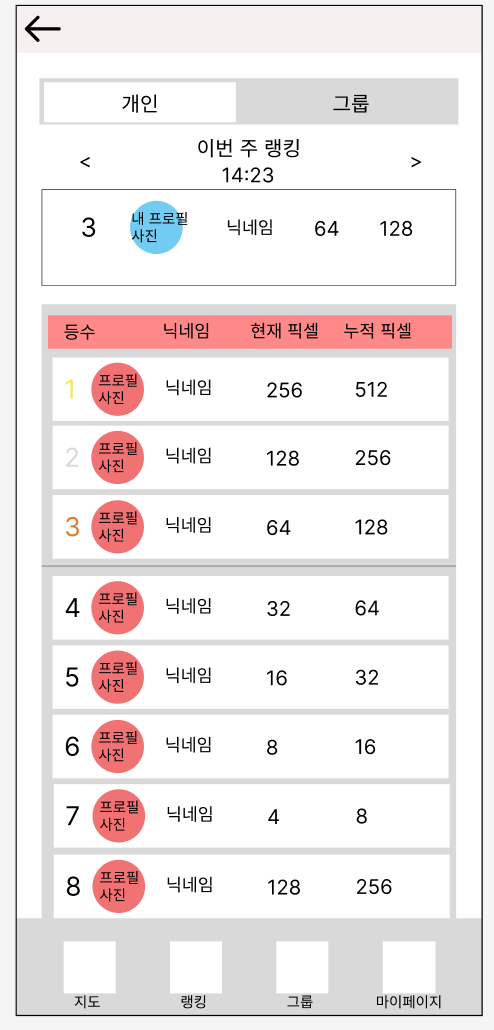
현재 기획 상 랭킹을 보여주는 리더보드를 제공한다.
 요구 사항은 아래와 같다.
요구 사항은 아래와 같다.
-
랭킹의 기준은 '현재 차지하고 있는 픽셀의 수' 이다.
-
화면을 스와이프하면 최신 랭킹을 서버에서 가져올 수 있다.
-
랭킹은 30등까지만 제공하지만, 자신의 순위는 항상 확인할 수 있어야 한다.
위의 요구사항대로 랭킹 시스템을 구현하기 위해 Redis를 도입하려했다.
Sorted Set 자료형을 사용해 아래와 같이 내림차순으로 정렬된 상태를 유지하게끔 설계를 진행했다.
| user-id | currentPixelCount |
|---|---|
| 1 | 80 |
| 5 | 68 |
| 3 | 33 |
이 과정에서 고민이 생겼다.
현재 고민중인 구현 방식은
위의 occupyPixel() 함수가 실행될 때, ‘남의 픽셀을 빼앗는 것’이라면 레디스에 저장된 자신의 현재 픽셀 수를 1 증가하고 이전 픽셀의 소유주의 현재 픽셀을 1 감소시키는 방식이다.
레디스는 싱글 스레드로 작동하기 때문에 레디스만 생각한다면 정합성 이슈가 발생하지 않는다.
또한 Sorted Set의 대부분의 연산이 O(log(n))으로 처리되는 것을 생각하면 성능 또한 문제가 되지 않는다.
(토막 상식 : 멘토님의 말슴에 따르면 레디스가 초당 10만번의 연산을 처리한다고 가정하신다고 함)
그렇다면 기존의 occupyPixel()은 아래와 같이 변경될 것이다.
@Transactional
public void occupyPixel(PixelOccupyRequest pixelOccupyRequest) {
Pixel targetPixel = pixelRepository.findByXAndY(pixelOccupyRequest.getX(), pixelOccupyRequest.getY())
.orElseThrow(() -> new AppException(ErrorCode.PIXEL_NOT_FOUND));
targetPixel.updateUserId(pixelOccupyRequest.getUserId());
// 남의 픽셀을 빼앗는 것이라면 레디스에 저장된 값을을 변경한다.
if(targetPixe.getUserId() != pixelOccupyRequest.getUserId()) {
redisUtil.요청한_유저의_현재_픽셀_수_증가();
redisUtil.이전에_픽셀을_차지했던_유저의_현재_픽셀_수_감소();
}
PixelUser pixelUser = PixelUser.builder()
.pixel(targetPixel)
.user(userRepository.getReferenceById(pixelOccupyRequest.getUserId()))
.build();
pixelUserRepository.save(pixelUser);
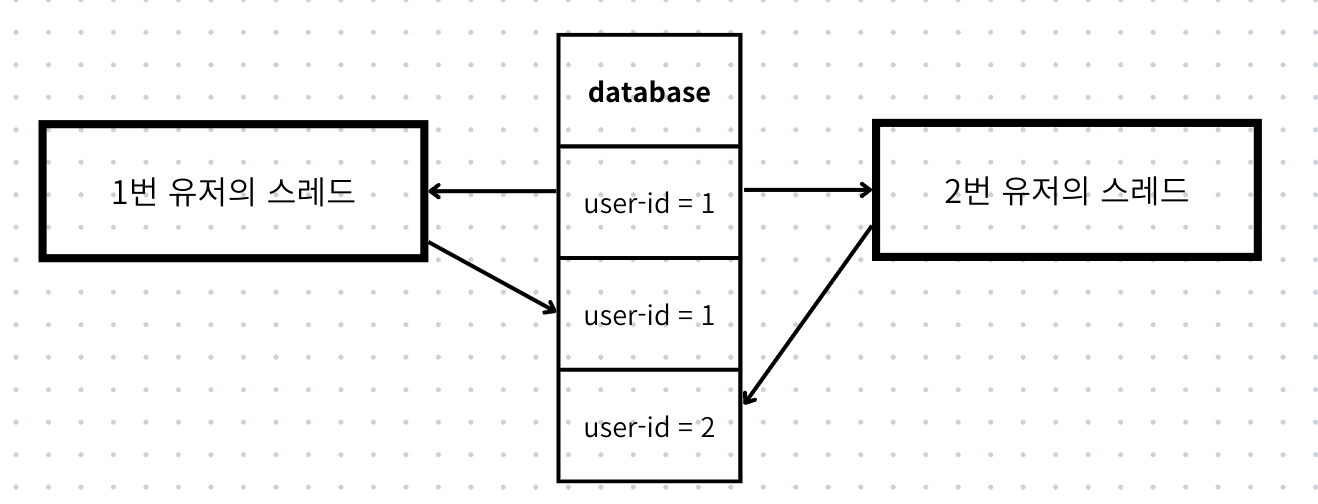
}이 과정에서 충분히 많은 사람들이 거의 동시에 요청을 보내면, db에 저장되어 있는 데이터로 계산할 수 있는 유저들의 현재 픽셀 수와 레디스에 저장된 유저들의 현재 픽셀 수의 정합성이 깨질 것으로 예상이 되는 상태이다.
예를 들면 아래와 같은 상황이 있을 수 있다.
- 1번 픽셀에 대해 1번 유저가 소유권을 가지고 있는 상황
- 1번 유저와 2번 유저가 거의 동시에 1번 픽셀에 진입.
- 1번 유저가 아주 조금 더 늦게 들어와 소유권은 결국 1번 유저가 되어야함.
만약 여기서 2번 유저의 스레드가 더 나중에 db에 write한다면, 레디스 상에선 우리가 의도한 값을 얻을 수 있지만, db 상에서는 다른 결과를 얻게 된다.
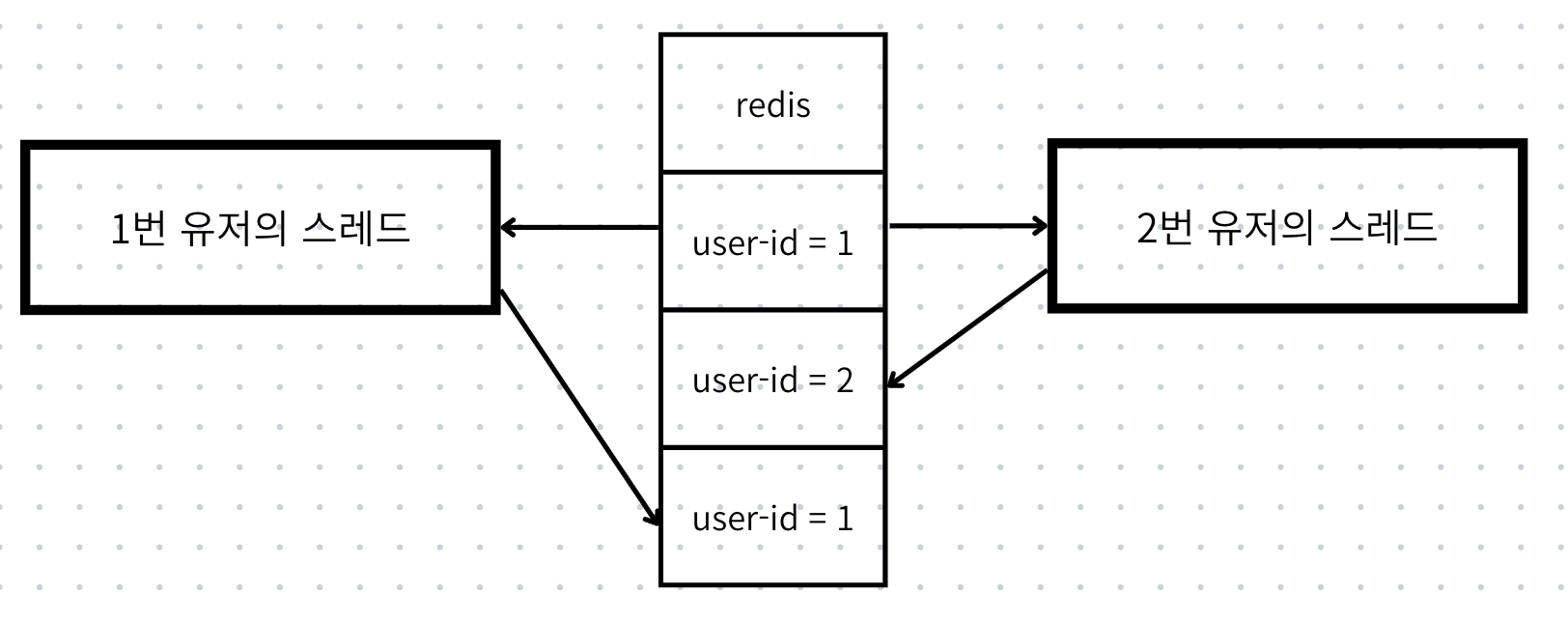
또한 현재는 스프링을 구동하는 EC2 인스턴스를 1개만 사용하고 있지만, 이중화를 목표로 하고 있기에 이런 상황에서도 여러 이슈들이 발생할 것으로 예상된다.
해결책
-
분산락을 사용한다.
DB와 레디스의 쓰기 작업이 하나의 Lock 내에서 이루어지게끔 하여 일종의 atomicity를 보장하는 방법이다.
정확히 우리가 의도한대로 데이터를 처리할 수 있지만, 유동인구가 많은 지역이나 시간대에 성능 이슈가 발생할 수 있다. -
정보의 출처를 레디스로 통일한다.
랭킹 페이지 뿐만 아니라 픽셀 개수를 가져오는 모든 정보의 출처를 레디스로 통일한다.
레디스에 의존성이 생기지만 '게임'이라는 특성 상 성능을 최우선으로 여겨야 하기에 가장 합리적인 선택지로 느껴진다.
