
포스팅에 앞서.... 그라운드 플립은 스토어에서 다운 받을 수 있습니다!!🔥🔥
[iOS] : 앱스토어
[Android] : Play 스토어
서론
그라운드 플립에는 "주간 랭킹 초기화" 기능이 존재한다.
이를 위해 매주 월요일 오전 12시, 레디스에 존재하는 사용자들의 점수와 데이터베이스에서 픽셀의 소유권을 나타내는 컬럼을 모두 null로 만들어야한다.
하지만 이 데이터베이스를 초기화하는 과정에서 큰 장벽에 부딪혔다.
약 2900만개의 컬럼을 UPDATE하니 무려 20분이 넘게 걸리는 문제가 발생했다.
분명 우리와 의도는 달랐기에,,, 결국 다른 방법으로 구현하긴 했지만 궁금증이 생겼다.
의문
인덱스에 대해 공부하다보면 거의 모든 자료에서 이렇게 말한다.
인덱스를 사용하면 읽기 작업의 성능을 높일 수 있지만 인덱스 재정렬 등의 오버헤드로 인해 삭제, 수정, 삽입 성능이 떨어집니다.
위에서 언급한 UPDATE가 실행되는 테이블도 읽기 성능을 높이기 위한 온갖 인덱스가 걸려있었다.
따라서, 우리도 단순히 아~ 인덱스가 너무 많아서 UPDATE가 느려졌었구나~ 라고 생각했다.
하지만 문득 이런 의문이 들었다.
인덱스를 걸면 UPDATE할 쿼리를 빨리 탐색할 수 있으니 더 빠를 수도 있지 않을까?
관련된 키워드로 구글링하던 중 이 글을 발견했다.

요악하자면,
update mytable set mycolumn = 4711와 같이 전체 컬럼을 UPDATE하는 쿼리는 일반적으로 알려진 것처럼 인덱스 재정렬 등을 이유로 속도가 느려진다.
하지만,
update mytable set mycolumn = 4711 where mycolumn = 123같이 컬럼을 특정해 UPDATE하는 쿼리는 테이블을 풀스캔하지 않기 때문에 빠르다고 한다.
단순한 직관으로 접근한 아이디어인데 실제로 그렇다니 꽤나 놀라웠다.
하지만 눈으로 직접 보기 전까진 믿을 수 없는 법.
실험을 해보기로 했다.
실험1
실험 시나리오는 아래와 같다.
- AWS RDS t3.micro
- 데이터 개수는 500만 개
- 테이블 두 개를 생성 후 한 쪽에만 인덱스 생성
- 단건 업데이트와 전체 업데이트를 실행 후 각각 비교
- 테이블 생성
우선 아래 스크립트를 사용해서 테이블을 생성한다.
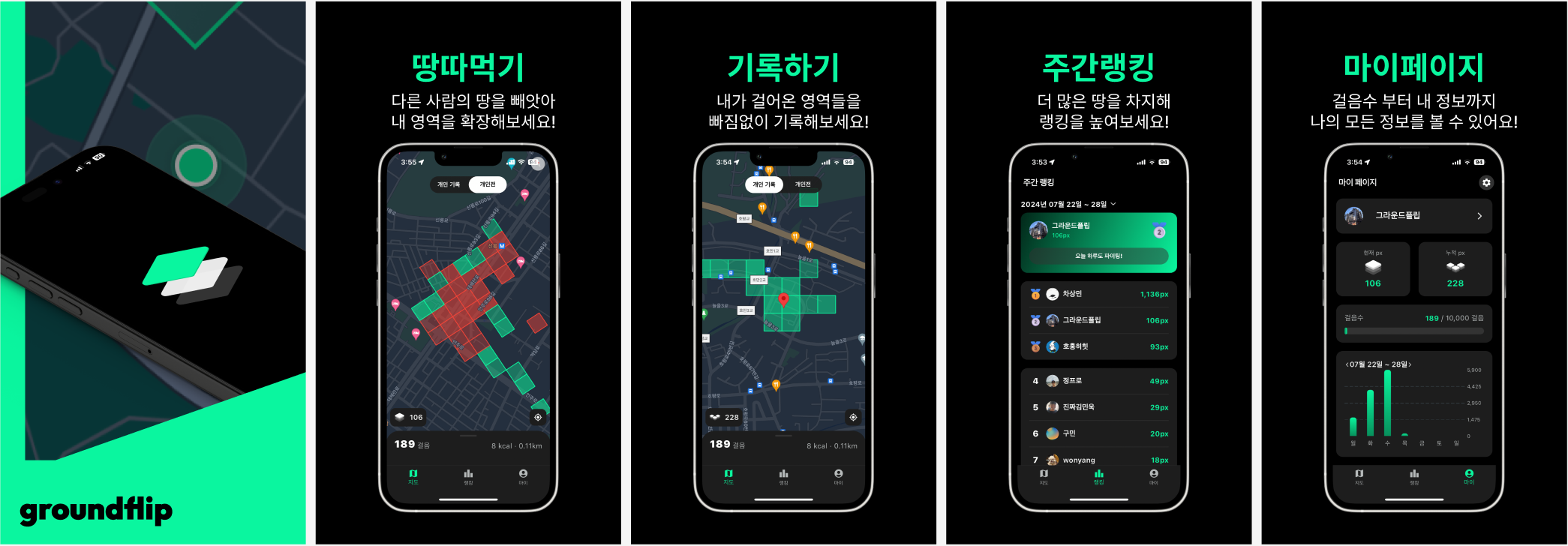
동일한 테이블 두 개를 생성하지만, 한 쪽에만username컬럼에 인덱스를 생성한다.
-- 인덱스가 있는 테이블
CREATE TABLE users_with_index (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
age INT,
last_login TIMESTAMP
) ENGINE=InnoDB;
-- 인덱스가 없는 테이블
CREATE TABLE users_without_index (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
age INT,
last_login TIMESTAMP
) ENGINE=InnoDB;
-- 인덱스 추가 (username에 인덱스 추가)
CREATE INDEX idx_username ON users_with_index(username);- 데이터 삽입
이후 데이터 500만 개를 순차적으로 삽입한다.
useraname 을user1, user2, user3...과 같은 형식으로 삽입한다.
DELIMITER $$
CREATE PROCEDURE insert_users()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 5000000 DO
INSERT INTO users_with_index (username, email, age, last_login)
VALUES (CONCAT('user', i), CONCAT('user', i, '@example.com'), FLOOR(RAND() * 50 + 20), NOW());
INSERT INTO users_without_index (username, email, age, last_login)
VALUES (CONCAT('user', i), CONCAT('user', i, '@example.com'), FLOOR(RAND() * 50 + 20), NOW());
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL insert_users();
500만 건이 전부 삽입된 것을 확인할 수 있다.
-
UPDATE 쿼리 실행
1부터 500만까지의 중 무작위 숫자를 뽑아 UPDATE 쿼리 20개를 실행한 후 각 쿼리의 실행시간을 시각화 해보기로 했다.아래와 같이 간단한 파이썬 코드를 통해 실험을 진행한다.
import pymysql
import random
import time
import matplotlib.pyplot as plt
# MySQL 연결 설정
connection = pymysql.connect(
host='',
user='', # MySQL 사용자명
password='', # MySQL 비밀번호
db='', # 사용할 데이터베이스 이름
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
# 무작위로 생성할 쿼리 회차 설정
num_queries = 20
execution_times_with_index = []
execution_times_without_index = []
def execute_update_query(table_name, connection):
with connection.cursor() as cursor:
# 무작위 id 설정
random_user_id = random.randint(1, 5000000)
# 쿼리 실행 시간 측정 시작
start_time = time.time()
# UPDATE 쿼리 실행
update_query = f"""
UPDATE {table_name}
SET last_login = NOW()
WHERE id = '{random_user_id}';
"""
cursor.execute(update_query)
connection.commit()
end_time = time.time()
execution_time = end_time - start_time
return execution_time
# 테이블별 100번의 쿼리 실행 및 소요 시간 기록
for i in range(num_queries):
# 인덱스가 있는 테이블에서 실행
time_with_index = execute_update_query("users_with_index", connection)
execution_times_with_index.append(time_with_index)
# 인덱스가 없는 테이블에서 실행
time_without_index = execute_update_query("users_without_index", connection)
execution_times_without_index.append(time_without_index)
# MySQL 연결 종료
connection.close()
# 소요 시간 시각화
plt.figure(figsize=(12, 6))
# 인덱스가 있는 테이블의 소요 시간 그래프
plt.plot(execution_times_with_index, label="With Index", color="blue", marker='o')
# 인덱스가 없는 테이블의 소요 시간 그래프
plt.plot(execution_times_without_index, label="Without Index", color="red", marker='x')
# 그래프 설정
plt.title("쿼리 실행 시간 비교")
plt.xlabel("Query Execution #")
plt.ylabel("Execution Time (seconds)")
plt.legend()
plt.show()코드를 실행하기 전 Workbench를 사용해 실행 계획으로 결과를 예상해보았다.
인덱스가 걸린 테이블의 실행 계획
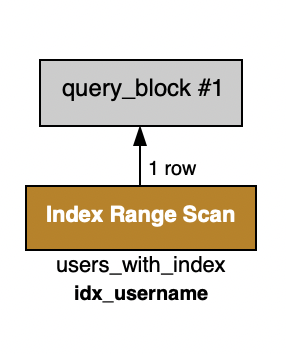
인덱스가 걸려있지 않은 테이블의 실행 계획
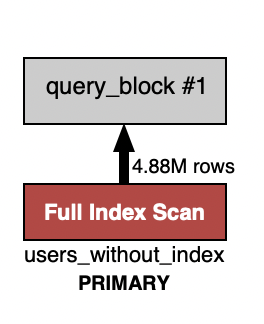
풀 테이블 스캔으로 인해 인덱스가 걸려있는 테이블이 더 빠를 것이라 예상된다.
-
결과
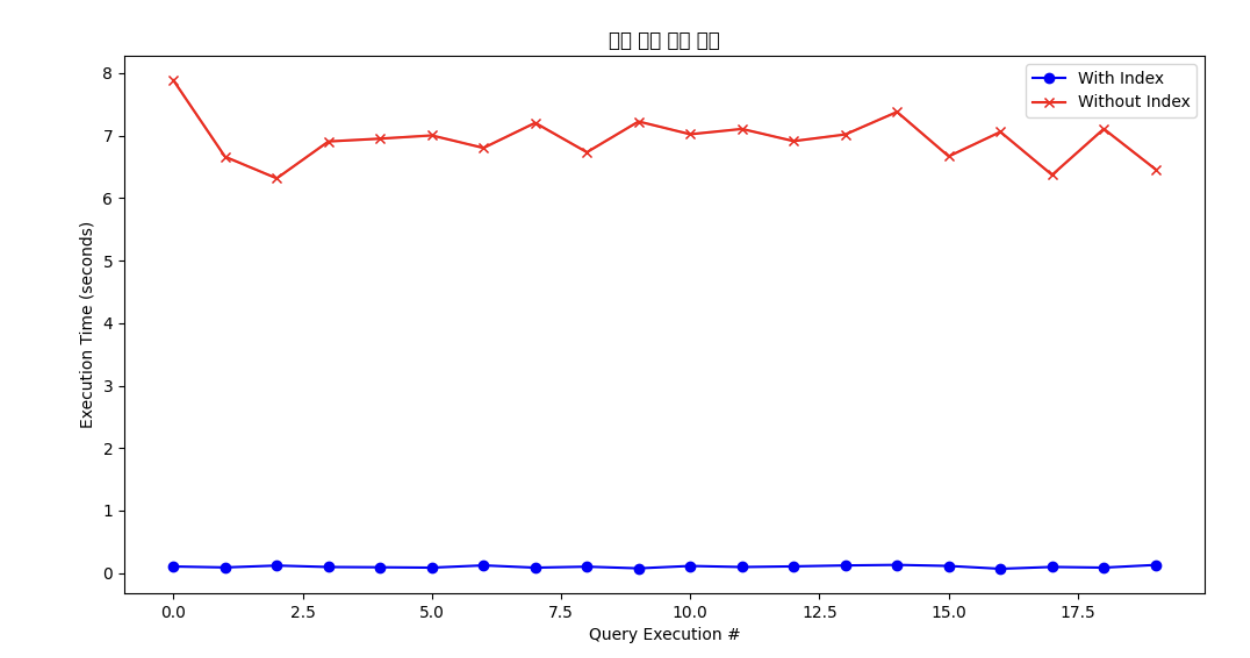
처음 세운 가설대로 결과가 나왔다.
인덱스가 걸린 테이블의 경우, 대부분의 쿼리가 1초 이내로 실행됐지만
인덱스가 걸려있지 않은 테이블의 경우 6~8초가 소요됐다.즉, 단 건 업데이트는 row를 찾아가기 위해 인덱스를 사용하기 때문하기 때문에, 인덱스를 사용하는 것이 더 빠르다
실험2
그렇다면 모든 행을 UPDATE하는 작업은 어떨까?
테이블 drop-create를 반복하며 데이터 개수 10개부터 100만까지 증가시키며 전체 update를 반복했다.
import pymysql
import time
import matplotlib.pyplot as plt
# MySQL 연결 설정
connection = pymysql.connect(
host='',
user='', # MySQL 사용자명
password='', # MySQL 비밀번호
db='', # 사용할 데이터베이스 이름
cursorclass=pymysql.cursors.DictCursor
)
# 테이블 생성 (인덱스가 있는 테이블과 없는 테이블)
def create_tables(connection):
with connection.cursor() as cursor:
# 인덱스가 있는 테이블 생성
cursor.execute("""
CREATE TABLE IF NOT EXISTS users_with_index (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
age INT,
last_login TIMESTAMP
);
""")
# 인덱스가 없는 테이블 생성
cursor.execute("""
CREATE TABLE IF NOT EXISTS users_without_index (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
age INT,
last_login TIMESTAMP
);
""")
# 인덱스 추가 (username에 인덱스 추가)
cursor.execute("""
CREATE INDEX idx_username ON users_with_index(username);
""")
connection.commit()
# 데이터 삽입 함수
def insert_data(connection, num_records, batch_size=5000):
with connection.cursor() as cursor:
# Batch Insert를 위한 리스트
users_with_index_values = []
users_without_index_values = []
for i in range(num_records):
username = f'user{i+1}'
email = f'user{i+1}@example.com'
age = 20 + (i % 50) # 20 ~ 69 사이의 나이
last_login = '2024-01-01 00:00:00'
# 데이터 추가 (Batch로 모아서 한 번에 삽입)
users_with_index_values.append((username, email, age, last_login))
users_without_index_values.append((username, email, age, last_login))
# batch_size 단위로 INSERT 실행
if len(users_with_index_values) >= batch_size:
# 인덱스가 있는 테이블에 데이터 삽입
cursor.executemany("""
INSERT INTO users_with_index (username, email, age, last_login)
VALUES (%s, %s, %s, %s);
""", users_with_index_values)
# 인덱스가 없는 테이블에 데이터 삽입
cursor.executemany("""
INSERT INTO users_without_index (username, email, age, last_login)
VALUES (%s, %s, %s, %s);
""", users_without_index_values)
# 커밋
connection.commit()
# 리스트 초기화
users_with_index_values.clear()
users_without_index_values.clear()
# 남아있는 데이터를 삽입
if users_with_index_values:
cursor.executemany("""
INSERT INTO users_with_index (username, email, age, last_login)
VALUES (%s, %s, %s, %s);
""", users_with_index_values)
cursor.executemany("""
INSERT INTO users_without_index (username, email, age, last_login)
VALUES (%s, %s, %s, %s);
""", users_without_index_values)
# 커밋
connection.commit()
# 모든 행을 업데이트하는 함수
def update_all_rows(table_name, connection):
with connection.cursor() as cursor:
start_time = time.time()
cursor.execute(f"UPDATE {table_name} SET last_login = NOW();")
connection.commit()
end_time = time.time()
return end_time - start_time
# 각 데이터 양별로 성능 측정
def measure_performance(connection, record_counts):
execution_times_with_index = []
execution_times_without_index = []
for count in record_counts:
print(f"\n{count} records:")
# 기존 데이터 삭제
with connection.cursor() as cursor:
cursor.execute("DROP TABLE users_with_index;")
cursor.execute("DROP TABLE users_without_index;")
connection.commit()
# 새로운 테이블 생성
create_tables(connection)
# 데이터 삽입
insert_data(connection, count)
# 인덱스가 있는 테이블에서 업데이트
time_with_index = update_all_rows("users_with_index", connection)
execution_times_with_index.append(time_with_index)
print(f"With Index: {time_with_index} seconds")
# 인덱스가 없는 테이블에서 업데이트
time_without_index = update_all_rows("users_without_index", connection)
execution_times_without_index.append(time_without_index)
print(f"Without Index: {time_without_index} seconds")
return execution_times_with_index, execution_times_without_index
# 데이터 양별로 성능을 시각화
def visualize_performance(record_counts, times_with_index, times_without_index):
plt.figure(figsize=(10, 6))
plt.plot(record_counts, times_with_index, label="With Index", color="blue", marker='o')
plt.plot(record_counts, times_without_index, label="Without Index", color="red", marker='x')
plt.title("Execution Time Comparison (With vs Without Index)")
plt.xlabel("Number of Records")
plt.ylabel("Execution Time (seconds)")
plt.legend()
plt.grid(True)
plt.show()
# 메인 실행 함수
def main():
record_counts = [10, 100, 1000, 10000, 30000, 50000, 100000, 200000, 500000, 1000000] # 실험할 데이터 양
# 성능 측정
times_with_index, times_without_index = measure_performance(connection, record_counts)
# 성능 시각화
visualize_performance(record_counts, times_with_index, times_without_index)
# MySQL 연결 종료
connection.close()
if __name__ == "__main__":
main()
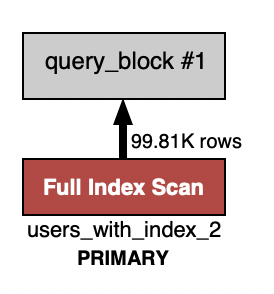
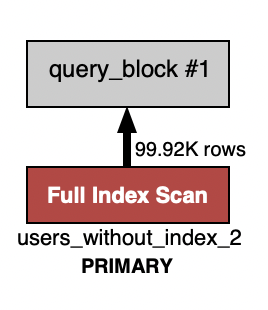
인덱스의 여부 상관 없이 풀 테이블 스캔이 발생한다.
결과
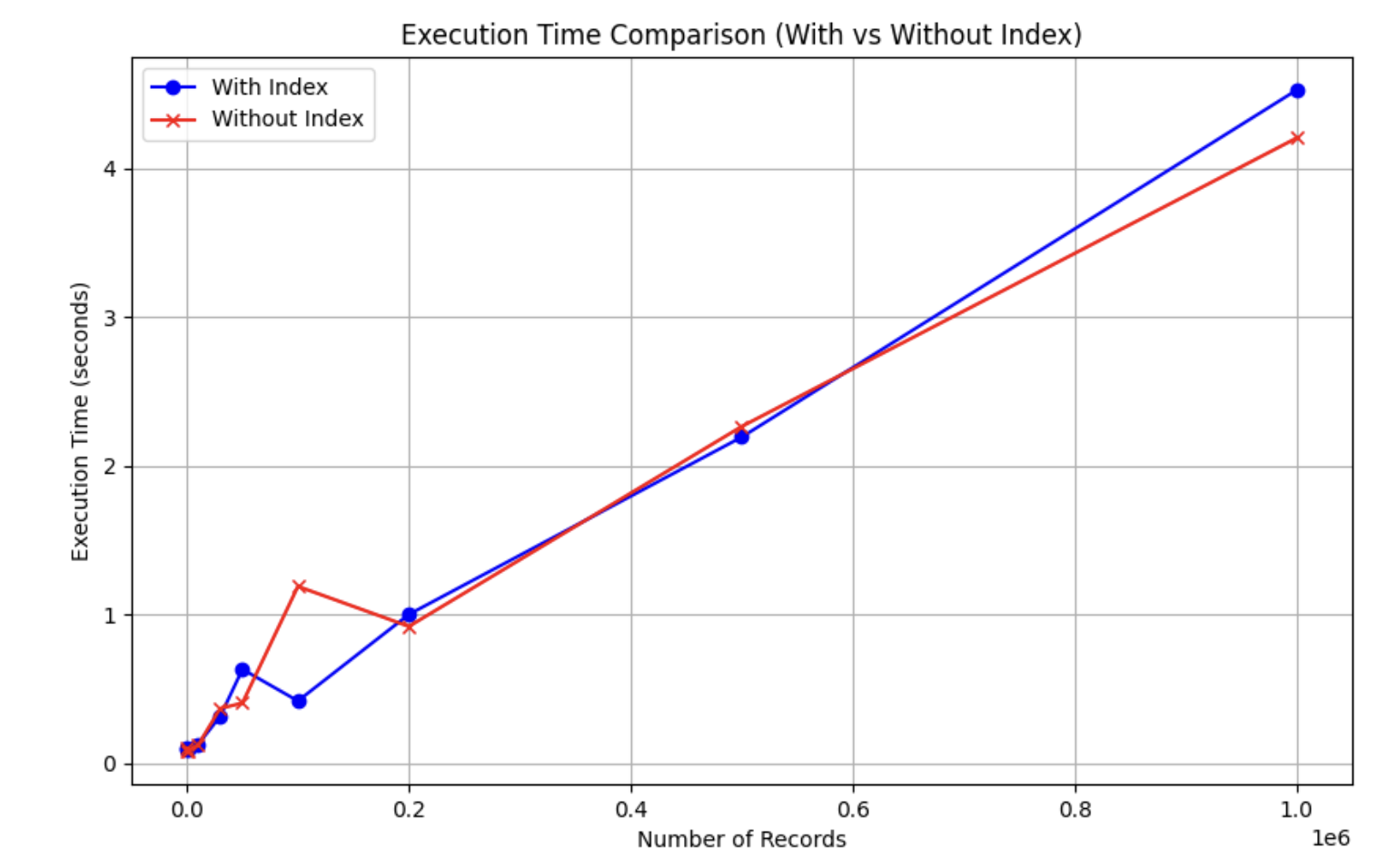
데이터가 증가할 수록 인덱스가 걸린 쪽이 더 느려지는 것을 확인할 수 있다.
결론
처음 데이터베이스를 배울 때, 인덱스를 사용하면 수정, 삭제, 삽입 작업이 느려진다고 배웠다.
하지만 항상 그런 것은 아니라는 것을 알게 되었다.
물론 읽기 성능을 높이기 위해 모든 컬럼에 맹목적으로 인덱스를 거는 것은 올바른 접근이 아니다.
그렇다고 해서 단순히 UPDATE가 발생한다는 이유만으로 인덱스를 포기하기보다는, 여러 조건을 고려해 읽기 성능에서의 이점을 최대한 활용하는 것이 중요하다고 생각한다.
참고 글
https://stackoverflow.com/questions/6769941/do-mysql-update-queries-benefit-from-an-index
https://stackoverflow.com/questions/21900894/do-indexes-make-db-updates-slower

글 잘봤습니다.
실험에서는 인덱스는 username 컬럼에 걸려 있는데, 업데이트는 last_login에 하는게 맞을까요?
첫번째 실행이 빨랐던 이유는 단지 WHERE문의 조건이 "인덱스 레인지 스캔"으로 빠르게 찾아졌기 때문에 빠른 것이고,
두번째 실험의 경우, 전체 업데이트이기 때문에 인덱스를 탈 필요가 없어서 username 인덱스가 있던 없던 상관없었던 비교군 같습니다.
그러니까 풀 테이블 스캔이 걸리는 것 같습니다. 또 인덱스가 있더라도 카티널리티 기준 조회 예상 값이 25%를 넘으면 풀테이블 스캔을 합니다.
고려해봐야 할게,
인덱스가 걸리지 않은 컬럼 업데이트는 인덱스 수정을 유발하지 않고
유니크 인덱스가 아닌 경우는 인덱스 변경이 지연 처리 되기 때문에 (MySql 기준) 그렇게 처리 되지 않을것 같네요