이번시간엔 자연어 처리의 주요 task 중 하나인 대화형 시스템, Conversational Agent(CA)에 대해 다뤄보려고 한다.
대화 시스템이란 사용자가 질문을 하면 그에 대응하는 답변을 내놓는 시스템이다.
CA에는 크게 두가지 범주가 존재한다.
1. chat bot
2. task-oriented agent
chatbot은 일상적인 대화를 위한 시스템이다. open domain의 지식을 갖고 있으며, 같은 질문에도 매번 다른 다양한 대화를 시도한다. 또한 사용자에게 지루하지 않은 답변을 하는 것을 목표로 한다.
task-oriented agent는 문제 해결 혹은 정보 전달을 위한 대화 시스템이다. chatbot에 비해 좁은 도메인의 지식을 가지고 있고, 전문적이고 복잡한 대답을 해야하며, 정보의 정확도가 중요하기 때문에 같은 질문에는 항상 같은 대답을 해줘야 한다. 를들면 의학적 지식에 대한 질문이 들어왔을 때, 올바르지 않은 정보를 전달한다면 이는 큰 문제가 될 수 있다.
구현 방식
챗봇
챗봇의 구현 방식은 크게 3가지가 존재한다.
1. 규칙기반 챗봇
2. 정보 회귀 챗봇
3. 생성형 챗봇
규칙기반 챗봇이란 질문의 패턴마다 미리 지정된 답변이 있어, 정해진 답변을 내놓는 챗봇이다. 이를테면 "do you like ~" 라는 패턴에는 "I like ~" 처럼 패턴마다 정해진 템플릿의 답변을 내놓는다.
정보 회귀 챗봇이란 도메인 코퍼스에서 질문과 가장 유사한 문장을 추출하여 답하는 방식이다. 이때 유사도의 기준은 tf-idf 또는 임베딩 벡터의 유사도 등이 있으며, 이에 대한 설명은 이 포스트를 참고하자.
https://velog.io/@qkdrudwo99/%EB%8B%A8%EC%96%B4%ED%91%9C%ED%98%84
생성형 챗봇이란 딥러닝 기반의 학습을 통해 답변을 내놓는 챗봇을 의미한다. 주로 seq2seq, transformer, gpt등의 모델을 통해 답변을 생성한다. 하지만 이런 방식은 blackbox system으로, 거대한 데이터셋을 통해 학습되었을 뿐이라 그 중간과정을 확인하기 어렵다.
평가 기준
챗봇의 성능을 평가하는것은 매우 모호한 작업이다. 질문에 대응하는 정답이 존재한다면 생성된 문장과 정답 문장의 비교를 통해 챗봇의 성능을 평가할 수 있을것이다. 하지만 그렇지 않은 경우엔 제대로된 대답을 내놓았는지 평가하기 어렵기 때문이다.
또한 평가의 주체도 문제이다.
기계가 채점을 하게된다면 채점을 자동으로 할 수 있어 대규모 데이터에서 평가가 가능하지만 기계의 평가는 사람이 평가하는것과 괴리가 존재할수 있다.
반대로 사람이 직접 평가한다면 사람이 하나하나 평가해야 하기에 비용이 많이 들고, 대량 채점이 힘들지만 더욱 인간 친화적인 평가가 가능할 것이다.
이번 글에선 3가지의 평가 기준에 대해 소개할 예정이다.
첫번째는 기계 레벨에서의 평가 기준인 BLEU 스코어이다. BLEU 스코어는 정답이 존재할 때 생성된 문장의 성능을 평가할 수 있는 지표이다.
두번째는 Perplexity로 정답이 존재하지 않아도 사용할 수 있는 기계 레벨의 평가 기준이다. 문장을 생성했을 때, 모델이 출력한 다른 후보들이 얼마나 적었는가로 점수를 매긴다.
세번째는 SSA라는 지표로 사람이 직접 평가하는 평가 기준이다.
BLEU
기계 레벨의 평가 기준으로 소개할 것은 BLEU이다.
BLEU는 생성된 문장과 정답 문장의 단어들 중 양쪽에 동시에 존재하는 단어들의 비율을 점수로 만든 것이다.(다만 중복되는 문장은 한번만 포함시킨다.)
생성 : Miracles usually happen to the men who believe in themselves
정답 : Miracles happen to only those who believe in them.
이 예제에서 bleu는
len({Miracles, happen, to, who, believe, in}) / len({Miracles, happen, to, only, those, who, believe, in, them}) = 6/9 이다.
하지만 이 방식엔 한가지 문제점이 있는데 바로 단어의 순서가 무시된다는 것이다.
예를들어 생성문장이
"Miracles men happen to the themselves usually who believe in" 처럼 이상한 문장을 생성했더라도 bleu값은 똑같은 6/9가 될 것이다. 이것을 보정하기 위한 방식이 바로 n-gram 방식이다. n개씩단어들을 짝지어 비교한 뒤, 겹치는 단어들의 합으로 bleu 스코어를 구하는 것으로, 이를 통해 순서 정보를 반영할 수 있다.
또한 이것만으론 부족한데 바로 문장이 짧을수록 높은 BLEU 스코어를 받기 쉬워지기 때문이다. 그렇기에 정답 문장보다 짧은 문장에 대해 패널티가 필요한데 이것을 BP(Brevity Penalty)라고 한다.
위의 모든 사항들을 고려한 최종 BLEU 스코어의 공식은 다음과 같다.
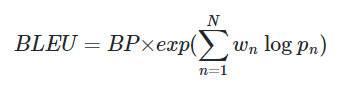
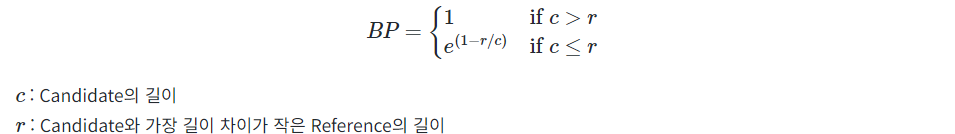
perplexity
이전 포스트에서 소개한바가 있다. 언어모델의 성능 평가 항목을 참고하자.
https://velog.io/@qkdrudwo99/%EC%96%B8%EC%96%B4%EB%AA%A8%EB%8D%B8
SSA(sensibleness and specificity average)
SSA는 인간이 직접 평가하는 기준으로, 구글에서 개발한 챗봇 미나에 대한 논문에서 등장한 평가 지표이다. sensibleness와 specificity 라는 두 점수의 평균으로 이루어져 있다.
sensibleness는 생성된 문장이 얼마나 말이 되는가(make sence in context)를 의미한다.
예를 들면 "밥을 먹었니?" 라는 질문에 "네"라는 답변은 말이 되는 답변이다.
하지만 "나는 오늘 도서관에 갔어" 라는 답변은 말이 되지 않는 답변이다.
다만 sensibleness에는 맹점이 있는데, 바로 지루한 답변을 걸러내지 못한다는 것이다. 예를들면 답변으로 "몰라"나 "응"과 같은 답변은 그 어떤 질문에도 말이 되는 답변이다. 하지만 이런 답변은 그 어떤 정보도 없고, 재미도 없는 지루한 답변이다. 그렇기에 이것을 보완해줄 또다른 지표인 specificity가 존재한다.
specificity는 생성된 문장이 얼마나 질문에 충실한가(specific)를 의미한다. 위의 단점을 보완하기 위한 지표로, 어떤 답변이 sensible하지 않다면 당연히 specific하지도 않다.
SSA는 이 두 지표를 평균을 낸 값이다. 이를통해 인간의 입장에서 모델의 답변이 얼마나 그럴싸한지를 수치화할 수 있다. 한가지 재밌는 사실은 이 SSA 값이 또다른 생성모델의 지표중하나이자 기계가 도출하는 값인 Perplexity와 상당히 높은 상관관계를 보였다는 것이다.
참고문헌
ConversationalAgents:TheoryandApplications MattiasWahdeandMarcoVirgolin
https://arxiv.org/abs/2202.03164
위키독스 자연어처리
https://wikidocs.net/book/2155
TowardsaHuman-likeOpen-DomainChatbot
https://arxiv.org/abs/2001.09977
