SNS를 돌아다니다 보면서 프로그래밍 언어들의 순위를 보여주는 영상을 본적이 있다.
처음 자바를 공부할때만 해도 자바가 그리 빠른 언어가 아니라고 알고 있었는데 이렇게 두고 보니 엄청 빠르긴 한 편인거로 생각된다. 하지만 이정도면 거의 C언어와 같은 저수준 언어와 속도가 비슷한것으로 보여진다. 따지고 보면 C언어는 추상화의 수준이 상당히 낮은 편이라 그렇다 쳐도 JVM 위에서 동작하는 Java, 심지어 동일한 JVM 위에서 동작하는 Kotlin도 이와 비슷한 수준을 보인다. 그래서 JVM이 어떻게 C언어와 비슷한 수준으로 동작할 수 있게 된건지를 알아보고 이 과정에서 사용된 기법을 어떻게 활용해볼 수 있을지 고민해보는 시간을 가지려 한다.
Interpreter vs Compiler
프로그래밍 언어로 작성된 프로그램을 실행 가능한 형태로 만드는 데에는 두 가지 방식이 있다.
첫 번째는 컴파일(compile) 방식이다. 이는 프로그램을 다른 목표 언어로 번역하는 과정이다. 컴파일은 고급 언어를 저수준 언어로 바꾸는 과정이 복잡해 시간이 걸린다. 하지만 한 번 번역을 끝내면 실행 속도는 매우 빠르다. 전통적으로 컴파일러가 생성하는 목표 언어는 기계어이며, 이는 CPU가 바로 실행할 수 있다.
이는 두 번째 실행 방식인 인터프리테이션의 대비되는 접근이다. 인터프리터는 프로그램을 읽고, 그 안의 명령을 순서대로 해석하여 실행한다.
결국 모든 프로그램은 컴파일된 프로그램이라도 최종적으로는 하드웨어 또는 소프트웨어에 의해 해석(interpret)된다. 컴파일러는 단지 번역만 하는 도구일 뿐이다.
인터프리터를 사용하는 장점은 다음과 같다.
- 프로그램을 즉시 실행할 수 있다.
- 컴파일 시간을 기다릴 필요가 없다.
- 이식성이 좋다.
- 프로그램은 인터프리터가 실행 가능한 어떤 환경에서든 실행될 수 있다.
단점은 명확하다. 인터프리터는 기계어 실행보다 '수십~수백 배' 느리다.
예를 들어, 두 숫자를 더하는 기계어 명령은 단 한 사이클로 끝나지만, 소프트웨어 인터프리터는 무엇을 해야 하는지 판단하기 위해 매우 많은 연산을 거친다.
Interpreter designs
인터프리터에는 여러 종류가 있다.
AST based interpreter
- 가장 단순한 형태다.
- AST를 재귀적으로 순회하며 실행한다.
- 속도는 매우 느리다.
Bytecode interpreter
- 속도를 위해 많이 사용되는 형태.
- 소스를 먼저 바이트코드(bytecode)라는 중간 코드로 컴파일하고, 이를 인터프리터가 실행한다.
- Java, Python, C#, OCaml, Smalltalk 등이 이 방식을 사용한다.
- Java의 bytecode 언어가 바로 JVM bytecode이다.
Threaded interpreter
여기서 말하는 "threaded"는 동시성의 스레드와 무관하다.
코드는 트리 구조를 이루며, 리프 노드는 기계어이고, 내부 노드는 포인터 배열로 구성된다.
실행은 짧고 효율적인 루프를 통해 트리를 순회하며 이루어진다.
- 바이트코드 인터프리터보다 빠르지만 코드 크기는 더 크다.
- FORTH 언어가 대표적이며, 임베디드 장치에서 자주 사용된다.
JVM의 Compile Time 동작 원리
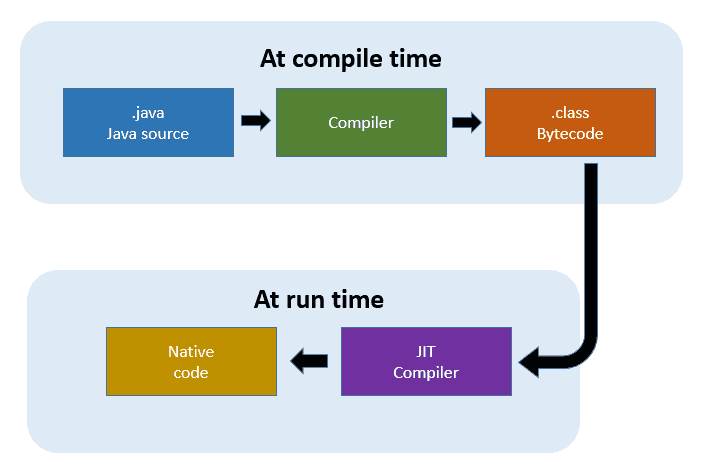
Java는 컴파일 + 인터프리팅 두 가지 전략을 모두 사용한다.
소스 코드는 먼저 JVM bytecode로 컴파일되며, 이 bytecode는 즉시 JVM 인터프리터에 의해 실행될 수 있다.
JVM 인터프리터는 실행 중 각 코드 조각이 얼마나 자주 실행되는지(프로파일링)을 추적한다. 그리고 자주 실행되는 코드(핫스팟, hotspot)는 JIT(Just-In-Time) 컴파일러로 넘긴다. JIT 컴파일러는 해당 bytecode를 실제 기계어로 변환한다. JIT는 다음 정보를 알고 있기 때문에 일반적인 오프라인 컴파일러보다 더 최적화된 코드를 만들 수 있다.
프로그램에서 어떤 코드가 실제로 자주 실행되는지, 어떤 클래스들이 실제로 로드되어 있는지, 즉 JVM은 모든 기계에서 이식성을 유지하면서도, 자주 실행되는 코드만 특별히 최적화하여 매우 빠르게 실행할 수 있다.
Class Loader
JVM 바이트코드는 .class 파일에 저장된다. 이 안에는 다음 정보가 포함된다.
- 메서드별 bytecode
- 문자열 상수 및 기타 상수를 담은 constant pool(
String포함) - 각종 attributes
javap -c <클래스명>을 실행하면 컴파일된 bytecode를 확인할 수 있다.
바이트코드는 대강 다음과 같은 방식으로 사용된다.
-
iload_3 -> 지역 변수 3을 스택에 push
-
ifeq -> 스택 top 값이 0이면 분기
-
iconst_1 -> 숫자 1 push
-
iadd -> 스택에서 두 값을 pop 후 더한 값을 push
-
istore 4 -> 스택에서 값을 pop하여 지역 변수 4에 저장
JVM 바이트코드는 크기 최적화를 위해 작은 값과 자주 쓰이는 연산에 대해 별도의 단축 명령을 갖는다.
JVM에서 .class 파일은 실행되기 전 반드시 class loading 과정을 거친다. 이 과정은 크게 Loading -> Verification -> Preparation -> Resolution -> Initialization 단계로 나뉜다.
class loader는 계층적으로 구성되어 .class를 로딩하는 과정에서 발생할 수 있는 보안 문제를 사전에 방지하고 일관적인 클래스 로딩을 할 수 있게 된다.
- Bootstrap ClassLoader
- JVM이 제공하는 최상위 로더이며, JRE 내부의 핵심 클래스(
java.lang.*,java.util.*)를 로드한다. 자바 코드로 구현되어 있지 않고, JVM 내부(C/C++)에 내장돼 있다.
- Extension ClassLoader (Platform ClassLoader in Java 9+)
JAVA_HOME/lib/ext에 있는 클래스나 모듈을 로드한다. Java 9부터는 Platform ClassLoader로 대체되어 모듈 시스템의 일부로 동작한다.
- Application ClassLoader (System ClassLoader)
- classpath에 지정된 사용자 클래스와 라이브러리를 로딩한다.
Bytecode Verification
바이트코드 검증은 JVM이 .class 파일을 메모리에 로딩한 직후 수행하는 정적 타입 검증 과정이다. 이 검증은 클래스가 실행되기 전에 단 한 번 수행되며, JVM의 안정성과 보안을 보장하는 핵심 절차다.
이 과정을 통해 JVM은 다음을 보장한다.
- 잘못된 명령어, 잘못된 메모리 접근 등으로부터 안전한 실행
- 런타임 타입 체크 감소로 인한 성능 최적화
검증 단계에서는 다음과 같은 항목이 점검된다:
- 명령어가 JVM 명세에 부합하는지
- 피연산자 스택의 사용이 일관적인지
- 로컬 변수의 타입이 정확히 일치하는지
- 메서드 호출 대상 객체의 타입이 유효한지
예를 들어, 호출 대상이 toString()을 가진 타입이 아닌데 toString()을 호출하려는 경우는 이 단계에서 검출된다. 이러한 정적 검사를 통과하지 못하면 클래스는 로딩되지 않으며, 보안상 안전하지 않은 바이트코드의 실행을 방지할 수 있다. 이 덕분에 JVM은 네트워크로 전송된 .class 파일조차도 검증 후 안전하게 실행할 수 있다.
이러한 검증의 기반에는 타입 시스템과 제네릭 소거(type erasure)가 있다. Java의 제네릭은 컴파일 타임에만 존재하고, 바이트코드에는 모든 타입 파라미터가 Object로 치환된다. 예를 들어 T[]는 JVM 상에서 Object[]로 변환되며, 이는 JVM의 검증과 실행 모델이 구체적인 제네릭 타입 정보를 알 필요 없이 동작할 수 있음을 의미한다. 이는 타입 안정성과 바이트코드 간결성을 동시에 확보할 수 있는 구조이지만, 반면 new T[n] 같은 표현이 금지되는 이유이기도 하다.
또한 JVM은 런타임 코드 생성도 지원한다. javax.tools.ToolProvider를 통해 Java 컴파일러에 접근하고, 소스를 동적으로 생성해 컴파일한 후 ClassLoader로 적재하여 실행할 수 있다. 이렇게 만들어진 클래스의 메서드는 Reflection으로 호출 가능하며, 이 코드가 반복 실행된다면 JIT 컴파일러가 최적화를 수행한다. 직접 바이트코드를 생성하는 방법도 있지만, 복잡성에 비해 얻는 이점이 적기 때문에 대부분은 Java 소스 생성 후 컴파일 방식이 사용된다.
이렇게 검증을 마친 바이트코드는 곧 Method Dispatch 로직에 따라 실행된다. 이는 JVM이 어떤 메서드를 실제로 호출할 것인지를 결정하는 과정으로, 호출 방식에 따라 정적 디스패치와 동적 디스패치로 구분된다.
Method dispatch
JVM에서 메서드 디스패치는 어떤 메서드를 실제로 호출할지를 결정하는 과정이다. 자바는 정적 타입 언어지만, 런타임에 다형성을 지원하기 때문에 호출 대상 메서드를 실행 중에 결정하는 경우가 많다. 이때 JVM은 호출 방식에 따라 정적인 방법과 동적인 방법을 다르게 처리한다.
Static Dispatch
정적 디스패치는 컴파일 타임에 호출 대상이 확정되는 방식이다. static 메서드, private 메서드, 생성자 등은 오버라이딩될 수 없기 때문에 컴파일 시점에 어떤 메서드가 호출될지가 명확하다. JVM은 이 경우 invokestatic, invokespecial 같은 명령어를 사용해 해당 메서드를 바로 호출한다. 메서드 테이블 탐색 같은 런타임 디스패치 과정을 생략할 수 있어 가장 빠르다.
Virtual Dispatch
인스턴스 메서드 호출 시 사용되는 방식으로, 런타임에 객체의 실제 타입에 따라 호출할 메서드가 결정된다. 예를 들어 부모 클래스의 참조형 변수로 자식 클래스 객체를 가리키고 있을 때, 오버라이딩된 메서드가 있다면 자식 쪽 구현이 호출된다. JVM은 invokevirtual 명령어를 통해 실행하며, 이 과정에서 가상 메서드 테이블(virtual method table, vtable)을 사용해 최적 경로로 실제 구현을 찾아낸다.
Interface Dispatch
인터페이스 타입을 통해 메서드를 호출할 때 사용된다. 인터페이스는 다중 구현이 가능하므로 어떤 클래스의 메서드를 호출할지는 런타임에만 알 수 있다. JVM은 invokeinterface 명령어를 사용하며, 일반적인 virtual dispatch보다 더 복잡한 디스패치 로직을 따른다. 하지만 현대 JVM에서는 이 부분도 프로파일링을 통해 빠르게 최적화된다.
Dynamic Dispatch (invokedynamic)
JVM 7부터 도입된 새로운 호출 방식으로, 동적인 메서드 바인딩을 수행할 수 있다. 주로 람다식, 메서드 핸들, 동적 언어 연동(JRuby, Nashorn 등)에 활용된다. invokedynamic 명령어는 처음 실행 시점에 바인딩을 설정하고 이후엔 캐시된 호출 경로를 사용해 실행 성능을 유지한다. 이 방식은 런타임에 메서드 호출 규칙을 유연하게 구성할 수 있어, JIT 컴파일러나 GraalVM의 최적화 대상이 되기도 한다. 이부분에 대해서는 후술하겠다.
Preparation
Preparation 단계는 클래스 로딩이 끝나고, 바이트코드 검증과 같은 안전성 확인이 완료된 이후 수행된다. 이 단계의 핵심 역할은 static 변수(static field)에 대한 메모리 공간을 할당하고, 해당 공간을 JVM 명세에 따라 default value 으로 초기화하는 것이다.
예를 들어 static int a = 42; 같은 필드가 있다면, 이 시점에서는 a에 42가 들어가지 않는다. 단순히 int 타입의 공간이 만들어지고, 여기에 기본값인 0이 들어가는 수준이다. 즉, 이후 클래스 초기화 메서드가 호출되기 전까지는 static 필드에 우리가 작성한 값은 반영되지 않는다.
이 과정은 다음을 보장한다.
- 모든
static필드는 초기화 전에 기본값을 가진다. - 클래스 초기화 단계에서 참조되는 필드는 반드시 메모리에 존재한다.
- JVM 메모리 모델에 따라 class 영역에 필요한 구조가 준비된다.
결과적으로 Preparation 단계는 실행 가능한 클래스 객체를 만들기 위한 메모리 준비 작업이다. 바이트코드가 문제 없는지 확인한 뒤, 실제 값 할당 전 기본 메모리 구조를 세우는 것이다.
Resolution
Resolution 단계는 JVM 클래스 로딩 프로세스의 일부로, 클래스 내부에 선언된 symbolic reference를 실제 메모리에 로딩된 구체적인 클래스, 필드, 메서드로 연결하는 과정이다. 이 단계는 클래스가 필요한 시점에 지연되어 수행될 수도 있고, 초기화 전에 한꺼번에 수행될 수도 있다.
예를 들어 SomeClass.someMethod() 같은 호출이 있을 때, 컴파일된 바이트코드는 "SomeClass라는 이름의 클래스에 정의된 someMethod라는 메서드"에 대한 심볼릭 참조를 포함한다. Resolution 단계는 이 심볼을 메모리에 로딩된 진짜 SomeClass 클래스의 someMethod 메서드에 바인딩한다.
Resolution이 수행되는 대상은 다음과 같다.
- 클래스/인터페이스: 심볼릭 이름을 실제 Class 객체로 바인딩
- 필드: 클래스 내의 필드 참조를 실제 Field 구조로 바인딩
- 메서드: 메서드 호출을 실제 Method 구조체로 연결
이 과정에서 알아두어야 할것은
- 지연 수행(lazy resolution): JVM은 성능 향상을 위해 이 과정을 실제 사용 시점까지 미루는 경우가 많다.
- 런타임 예외 발생 가능: 대상 클래스나 메서드, 필드가 없거나 접근 권한이 없으면
NoClassDefFoundError,NoSuchMethodError,IllegalAccessError등이 발생한다.
class A {
void hello() {
System.out.println("hello");
}
}
class B {
void callHello(A a) {
a.hello(); // 이 시점에서 A와 hello()에 대한 resolution이 발생함
}
}
Initialization
Initialization 단계는 JVM 클래스 로딩의 마지막 단계로, 클래스의 정적 초기화 코드(static initializer)와 static 필드에 명시된 값 할당이 이 시점에 수행된다. 즉, static int x = 10; 또는 static { ... } 블록에 작성된 코드가 여기서 실행된다.
이 과정은 다음과 같은 순서로 진행된다.
-
클래스의 super class가 먼저 초기화
- JVM은 클래스의 초기화를 시작하기 전에 그 부모 클래스가 아직 초기화되지 않았다면 먼저 초기화시킨다. 이는 상속 계층에서 부모 -> 자식 순으로 초기화가 일어나도록 보장한다.
-
static 필드 값 할당 및 static block 실행
- 앞선 Preparation 단계에서 할당된
static필드 메모리에, 실제 코드에서 정의한 값들이 대입된다. - static 초기화 블록(
static { ... })이 있다면 이 블록이 실행된다.
- 앞선 Preparation 단계에서 할당된
-
클래스 초기화는 단 한 번만 수행됨
- JVM은 클래스별로
<clinit>메서드를 생성해 초기화 코드를 담고, 이를 한 번만 실행한다. - 초기화가 완료되면 해당 클래스는 "initialized" 상태로 표시되며, 이후 같은 클래스에 대한 요청이 들어와도 다시 초기화되지 않는다.
- JVM은 클래스별로
-
초기화 트리거 조건
- 클래스에 접근하는 시점에서 다음과 같은 경우 초기화가 트리거된다:
static필드나 메서드에 최초 접근Class.forName()호출- 새 인스턴스 생성
- 리플렉션 API를 통한 접근
이 단계는 Java 클래스가 실제 동작 가능한 상태로 전환되는 마지막 관문이며, 프로그램 실행 중 부작용(side-effect)을 일으킬 수 있는 유일한 클래스 로딩 단계이기도 하다. 초기화 시점과 순서를 명확히 이해하는 것은 예측 가능한 실행 흐름을 설계하는 데 중요하다.
JIT Compiler
JIT(Just In Time) Compiler는 바이트코드 분석을 매번 인터프리터를 사용하는 것이 아닌 자주 사용되는 hotspot을 네이티브 코드로 변환하여 인터프리터 언어보다 컴파일 언어에 가까운 성능을 내게 해주는 JVM 실행 속도 일등 공신이다. 실제 실행 경로를 기반으로 적극적인 최적화를 수행한다.
JVM에서 인터프리터가 JIT으로 전환되는 조건은 hotspot 감지에 기반한다. 자바 프로그램은 처음 실행될 때 인터프리터 방식으로 시작하지만, 특정 코드가 반복적으로 많이 실행되면, JVM은 그 부분을 hotspot으로 간주하고 JIT 컴파일러에 넘겨 네이티브 코드로 변환한다(여기서 언급되는 네이티브 코드가 Host 시스템의 native method와 다르니 주의하자).
그럼 어떤 기준으로 hotspot을 지정할까? 컴파일 임계치를 넘었을 때 hotspot으로 지정되는데 이때 임계치는 아래의 조건을 따른다.
-
메서드 호출 횟수 (Invocation Counter)
- 각 메서드에는 호출 횟수를 추적하는 카운터가 있다. 기본적으로 10,000회 호출되면 JIT 컴파일 대상이 된다 (HotSpot JVM 기준, Tiered Compilation에서는 더 낮을 수도 있음). 이 임계값은 -XX:CompileThreshold 옵션으로 조정 가능하다.
-
루프 반복 횟수 (Backedge Counter)
- 루프 내부 코드가 자주 실행되는 경우도 별도로 추적한다.
- 메서드 전체가 아닌 루프만 핫스팟이 될 수 있기 때문에 루프 진입 횟수 기준으로도 JIT 트리거가 발생한다.
임계치를 넘긴 경우에는 바이트 코드를 JIT 컴파일러에 넘기고 런타임 프로파일링 정보를 바탕으로 네이티브 코드를 최적화해 런타임에 호출하면 빠르게 코드캐시 내부로 이동해 빠르게 호출된다.
HotSpot JVM 구조
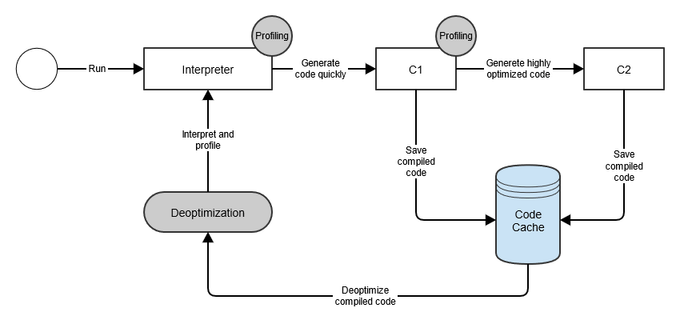
HotSpot JVM은 두 개의 JIT 컴파일러를 제공한다.
-
C1 (Client Compiler)
- 빠른 컴파일 속도에 중점을 둔 경량 컴파일러
- 애플리케이션의 초기 실행 속도 향상에 기여
- 단순한 최적화만 수행
-
C2 (Server Compiler)
- 컴파일 속도는 느리지만 고급 최적화 수행
- 장시간 실행되는 서버 애플리케이션에 적합
- Escape Analysis, Loop Unrolling 등 고급 기법 사용
두 컴파일러는 Tiered Compilation 모드에서 함께 사용될 수 있다. 즉, C1으로 빠르게 시작하고 프로파일링 데이터가 충분히 쌓이면 C2가 다시 최적화된 네이티브 코드를 생성한다.
Method Inlining
메서드 인라이닝은 호출되는 메서드의 코드를 호출 지점에 직접 삽입함으로써 호출 오버헤드를 없애고, 이후 추가적인 최적화를 가능하게 하는 기술이다.
예를 들어, 반복문 안에서 짧은 메서드를 반복적으로 호출하는 경우, 호출 오버헤드가 누적되며 성능 저하로 이어질 수 있다. 하지만 이 메서드가 인라인되면 루프 내부의 코드가 단순화되고, JVM은 loop unrolling이나 constant propagation와 같은 고급 최적화도 함께 적용할 수 있게 된다.
JVM은 메서드가 항상 인라인 가능한지 여부를 실행 중에 판단한다. 이 과정에서 가장 중요한 것은 call site에 대한 프로파일링 정보이다. JVM은 다음과 같은 기준으로 인라이닝을 결정한다:
- Monomorphic Call Site: 호출되는 메서드가 항상 동일한 클래스의 구현인 경우로 인라이닝 가능성이 높다.
- Polymorphic Call Site: 호출되는 메서드가 두세 개의 구현을 오가는 경우로 일부 인라인되거나 guard 조건을 붙여 최적화될 수 있다.
- Megamorphic Call Site: 다양한 타입의 구현이 섞여 있는 경우로 인라이닝이 거의 불가능하며 일반적인 virtual dispatch로 처리된다.
또한 메서드의 크기도 중요한 기준이다. 너무 큰 메서드는 인라이닝 대상에서 제외되며, JIT 컴파일러는 Inlining budget이라는 개념을 사용해 인라인할 코드량을 제한한다.
이처럼 메서드 디스패치 이후에 JVM이 메서드를 어떻게 다루는지는 실행 성능에 큰 영향을 미친다. 특히 인라이닝은 JIT의 다른 최적화와 함께 결합되어 전체적인 실행 경로를 크게 단순화시키고, CPU 캐시에 잘 맞는 기계어 코드를 생성하는 데에도 기여한다.
이 외에도 C1에서 상수 접기, null 체크 제거, 루프 단순화, 명령어 최적화등을 진행한다.
Escape Analysis
Escape Analysis는 JIT 컴파일러가 수행하는 대표적인 런타임 최적화 기법 중 하나로, 객체의 생명 주기와 접근 범위를 분석하여 불필요한 객체 생성을 줄이거나, 동기화 비용을 제거하는 데 사용된다. 객체가 현재 스레드의 메서드 범위 밖으로 탈출하는지 검사하고 탈축하지 않는다면 다음 최적화를 적용할 수 있다.
- Stack Allocation
- 일반적으로 객체는 힙에 할당되지만, escape하지 않는 객체는 스택에 할당할 수 있다. -> GC의 대상이 아니므로 GC 부하 감소, 할당/해제 비용 절감.
- 단, 메서드가 끝나면 스택도 함께 사라지기 때문에 외부 참조가 없어야 함.
- Scalar Replacement
- 객체 자체를 생성하지 않고, 객체 내부 필드들을 개별 변수로 분리해 사용한다.
- 객체 생성 비용을 최소화한다.
- Lock Elision
- 객체가 escape하지 않으면 해당 객체에 대한 synchronized 블록은 스레드 간 경쟁이 없다고 판단해 락을 제거할 수 있다.
다만 Escape Analysis는 런타임 프로파일링 기반이므로 항상 적용되는 것이 아니다.
이 외에도 C2에서 반복문 펼치기, 희소 코드를 합치고, 불필요한 배열 범위 검사를 제거해 실행 속도를 높힌다.
JIT이 선호하는 코드 구조 비교
JIT 컴파일러는 런타임에 수집한 프로파일링 정보를 기반으로 최적화를 수행한다. 이 때문에 코드 구조에 따라 최적화 효율이 달라질 수 있다. 아래는 대표적인 코드 구조 유형과 JIT 최적화 관점에서의 선호도 비교다.
1. 절차적 덩어리 코드
- 큰 함수 하나에 로직이 몰려있는 형태
- 함수 호출 오버헤드가 없기 때문에 호출 비용은 적음
- 하지만 코드가 커질수록 인라이닝 및 루프 최적화 등의 단위 최적화가 어려움
- control flow가 복잡할 경우 JIT이 효율적으로 프로파일링하기 어려움
JIT은 일정 크기를 넘는 메서드에 대해 인라이닝을 제한한다. 따라서 지나치게 커다란 함수는 최적화 단위를 잘게 나누기 어렵고, 이는 escape analysis, loop unrolling 등의 고급 최적화를 방해하게 된다.
2. 메서드 분리 기반 코드
- 작은 메서드로 기능을 분리한 구조
- 메서드 호출 빈도와 인라이닝 여부를 JIT이 정밀하게 조절할 수 있음
- monomorphic call site가 많아질 가능성이 높음 → aggressive inlining 유리
- 메서드 내부 최적화 및 인라이닝 후 loop 기반 최적화까지 적용 가능
적절히 잘게 쪼갠 메서드는 JIT이 인라이닝을 적극 활용할 수 있게 하며, 그 결과로 성능이 더 좋아진다. 특히 반복문 안에서 짧은 유틸리티 메서드가 자주 호출되는 구조는 인라이닝 → loop unrolling → scalar replacement 등 일련의 고급 최적화 흐름을 유도할 수 있다.
3. OOP 기반 구조
- 다형성 및 인터페이스 기반의 추상화가 많음
- call site가 polymorphic/megamorphic인 경우 인라이닝 어려움
- 메서드 디스패치 비용 증가 (
invokevirtual,invokeinterface) - 단일한 구현체만 존재하거나 대부분 특정 구현체일 경우에는 JIT이 guard 조건을 붙여 최적화 가능
객체지향 구조는 추상화로 인해 메서드 호출 분기가 복잡해질 수 있으나, JIT은 runtime profiling을 통해 monomorphic call site로 판단되면 인라이닝을 수행한다. 하지만 여러 구현체가 뒤섞이는 megamorphic call site에서는 최적화가 제한되며 일반적인 virtual dispatch 방식이 유지된다.
| 구조 유형 | 최적화 효율 | 대표 최적화 기법 |
|---|---|---|
| 절차적 덩어리 코드 | 낮음 | 제한적 인라이닝 |
| 메서드 분리 기반 코드 | 높음 | aggressive inlining, loop unrolling, scalar replacement |
| OOP 기반 구조 | 중간~낮음 | guard inlining (제한적), virtual dispatch 최적화 |
JIT 컴파일러는 적절히 잘게 쪼개진 코드와 monomorphic call 지점을 가장 잘 최적화할 수 있다. 따라서 지나치게 커다란 함수나 과도한 추상화는 성능 저하로 이어질 수 있으며, 호출 구조를 JIT이 분석하기 좋은 형태로 유지하는 것이 build time에서 불리할 수 있다. 다만 실제 개발에서는 build time 최적화 보다는 run time이 훨씬 중요하니 그리 집중되지 않는다. 이정도만 있다 정도로 알아두면 되지 않을까.
