Beyond Physical Memory : Policies
- Memory pressure로 인해 OS는 페이지를 페이징하여 활발하게 사용되는 페이지의 공간을 확보해야 함
- 어떤 페이지를 퇴출할 지 결정하는 것은 OS의 교체 정책 내에서 캡슐화 됨
Demanding Paging
- Page Fault Rate (0 <= p <= 1.0)
- p = 0이면 no page fault
- p = 1이면 모든 Reference가 fault
- Effective Access Time
- EAT = (1 - p) x memory access time + p x page fault service time
- Example
- Memory access time = 200ns
- Average page fault service = 8ms
- EAT = (1 - p) x 200 + p x 8,000,000 = 200 + p x 7,999,800
- 1000개 중 하나의 access로 인해 page fault가 발생하면 EAT = 8,200ns (40배 정도 둔화된 것)
- page fault rate low 낮게 유지하는 게 중요
: 좋은 page replacement 정책이 필요
Page Replacement
- Page replacement
- 실제로 사용하지 않은 page 찾아내 swap out
- 좋은 page replacement 알고리즘 : page fault 수가 최소화 됨
- Locality of reference
- 동일한 페이지를 여러 번 메모리에 가져올 수 있음
- 실제 대부분의 프로그램에서 관찰되는 현상임
- 일정 시간에 극히 일부 page만 집중적으로 reference 하는 program behavior (Loop)
- Paging system이 성능이 좋게 되는 근거
- Ideal algorithm : page fault율이 가장 낮음
- 알고리즘 평가 요소
- 메모리 참조의 특정 문자열에서 실행 가능 (참조 문자열)
- 해당 문자열의 page fault 수 계산
The Optimal Replacement Policy
- 전체적으로 가장 적은 미스 수로 이어짐
- 미래에 가장 멀리 접근할 페이지를 바꿈
- cache 누락 가능성이 가장 적음
- 미래에 가장 멀리 접근할 페이지를 바꿈
- 최적 알고리즘이 페이지의 하한을 나타냄
- 얼마나 근접했는지 알기 위한 비교 정도로만 쓰셈
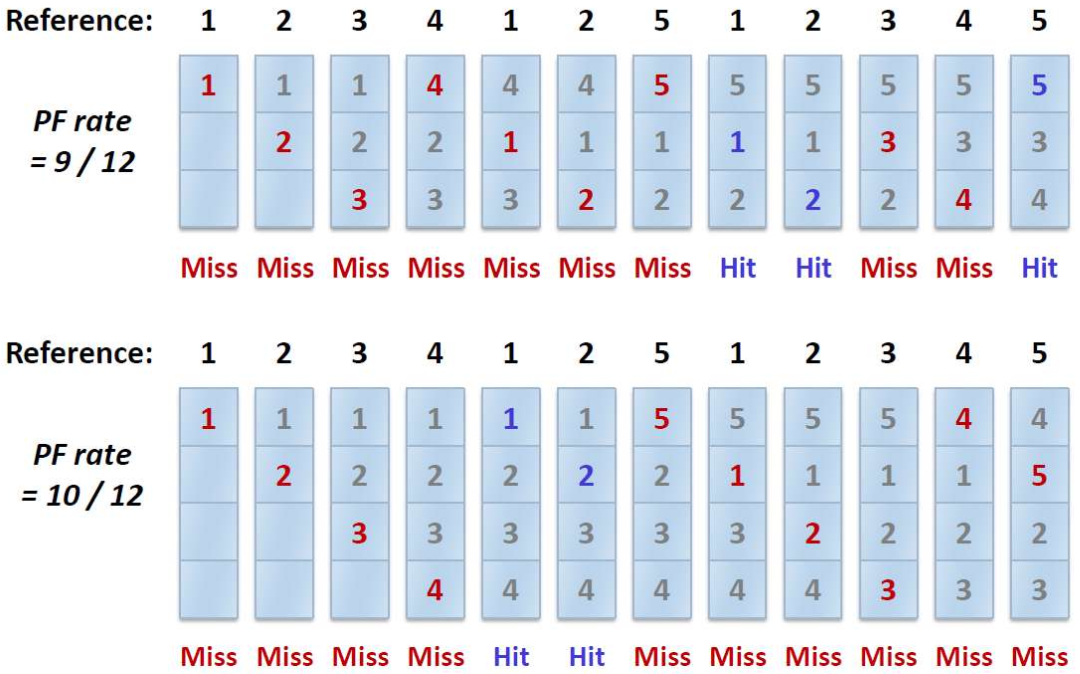
Tracing the Optimal Policy
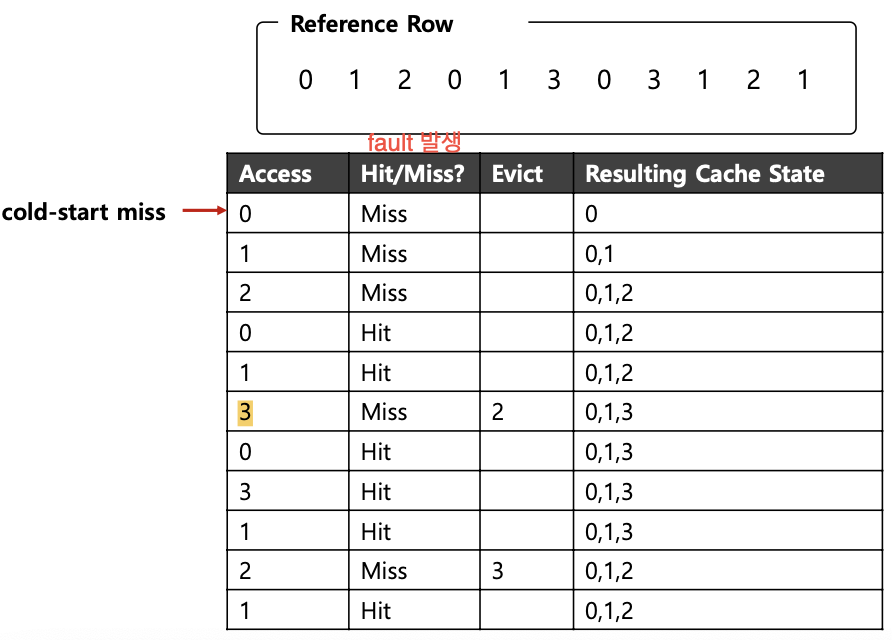
- 미래에 가장 나중에 참조될 page를 evict
- 가장 적은 가능성의 cache miss optimal policy 기준으로 다른 policy
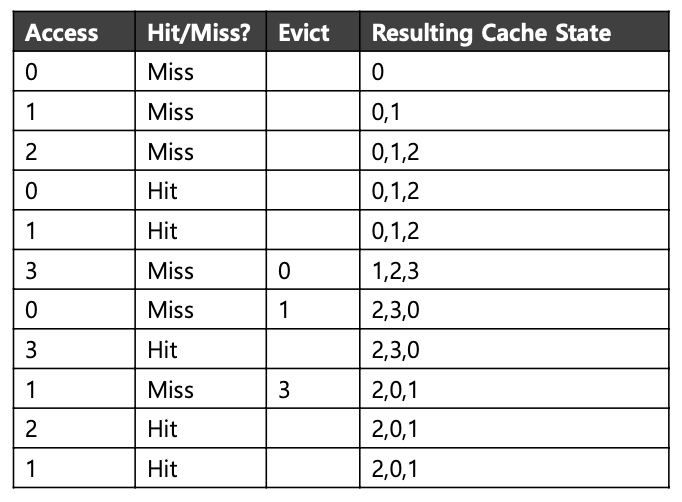
A Simple Policy : FIFO
- 페이지가 시스템에 들어갈 때 대기열에 놓였음
- replacement 발생 시, 대기열 끝에 있는 페이지가 삭제 됨(First in page)
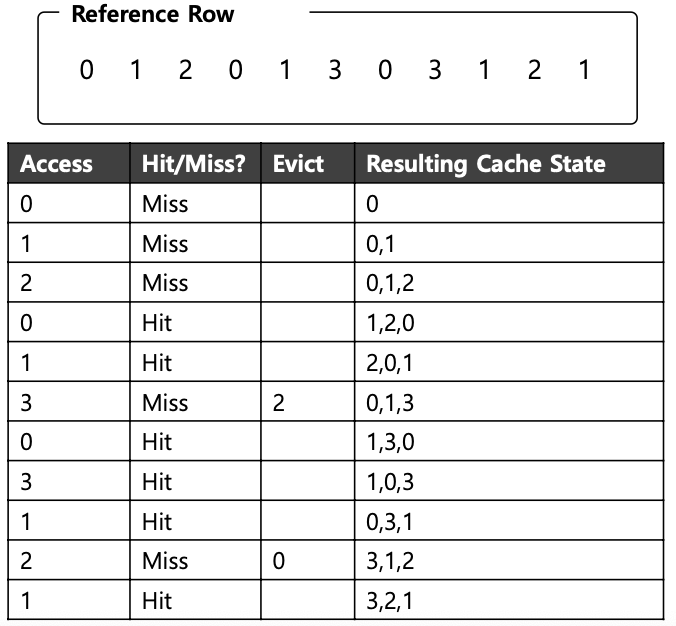
Tracing the FIFO Policy
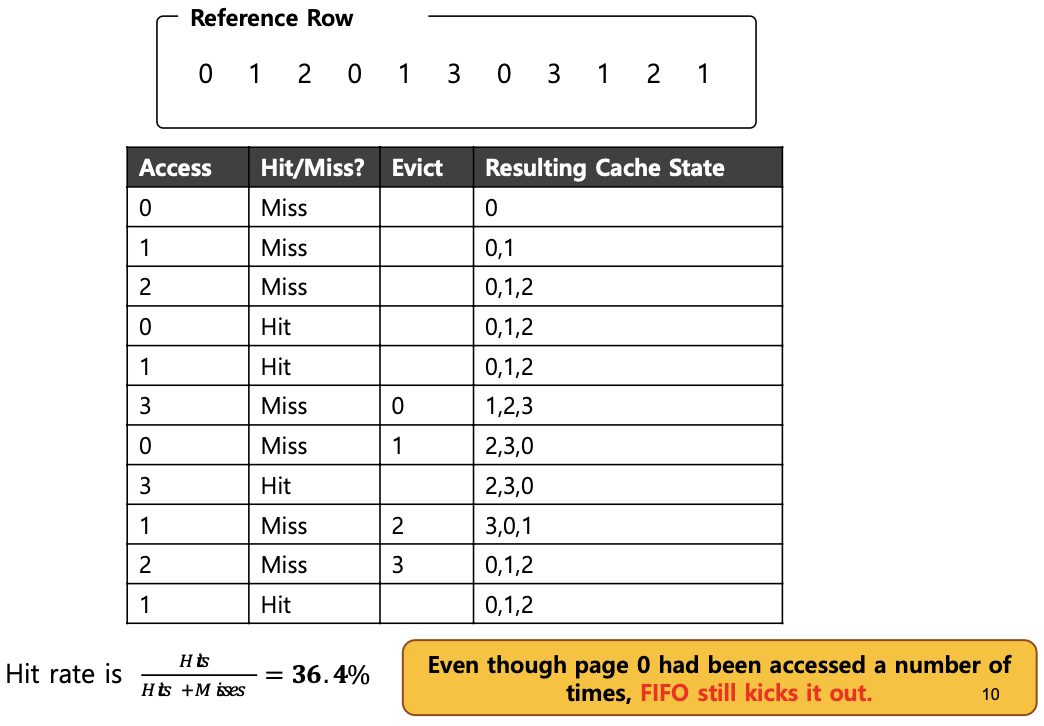
: replacement가 발생하면 첫번째로 들어온 페이지가 evict 됨
BELADY'S ANOMALY
: cache size가 커지면 cache hit 비율이 올라갈거라 생각하지만, FIFO 구조에선 worse해질 수 있음 (cache miss가 오히려 늘어남)
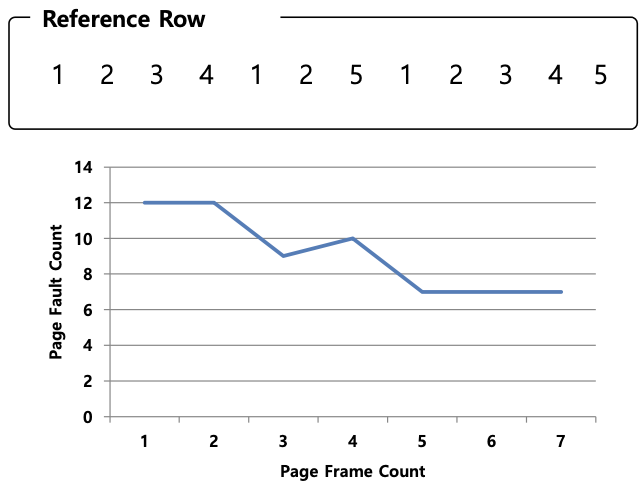
: cache size가 4일 때 cache miss가 더 증가함
Another Simple Policy : Random
- memory pressure로 교체할 random page를 선택
- 어떤 블록을 evict할지 너무 고민할 필요 ㄴ
- random은 전적으로 얼마나 운이 좋으냐에 따라 달려있음
Using History
- 이력을 사용
- recency (최근에 접근한 게 확률 더 ㅇㅇ) : LRU
- frequency (자주 접근한 게 확률 더 ㅇㅇ) : LFU
- LRU : 마지막으로 사용된 시간이 가장 오래된 page를 쫓아내는 방식
- locality 기반으로 한 알고리즘
- Stack 사용한 알고리즘 : Belady's anomaly 없음
- 구현 어려움 (page가 언제 접근되었는지 모두 기록하고 있어야 함)
- 모든 Workload에 유용하지는 않음
Workload Example
- 100개의 page에 랜덤으로 접근하는 상황
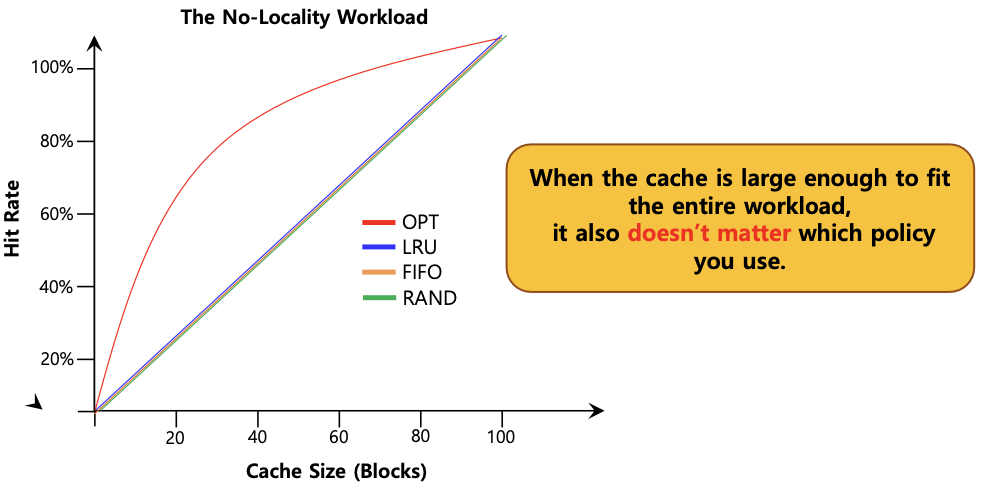
: page의 locality가 적용되지 않아 cache size에 비례해서 page hit rate가 높아짐
- 80-20 Workload
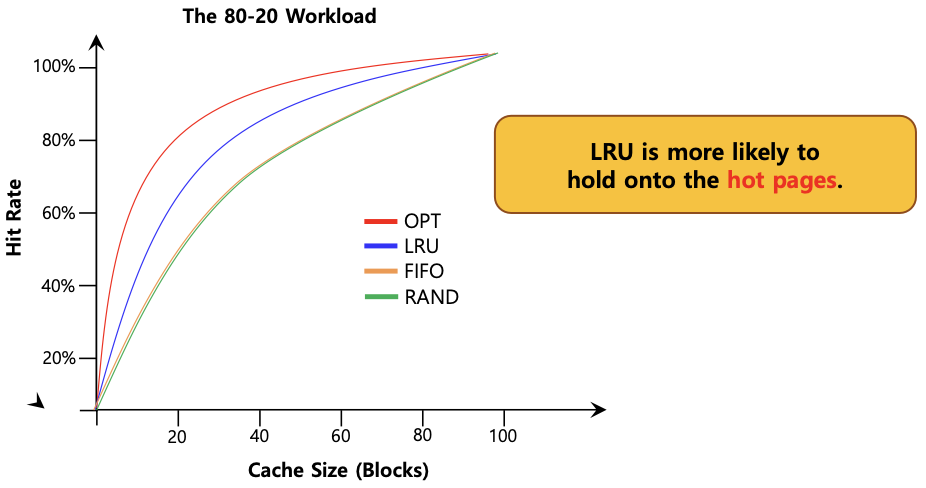
: 80%의 접근 시도가 20개의 페이지에 국한, 20%의 접근 시도가 80개의 페이지에 국한됨
-> 지역성 기반 알고리즘인 LRU가 FIFO나 RAND 알고리즘 보다 효율적임
- Looping Sequential
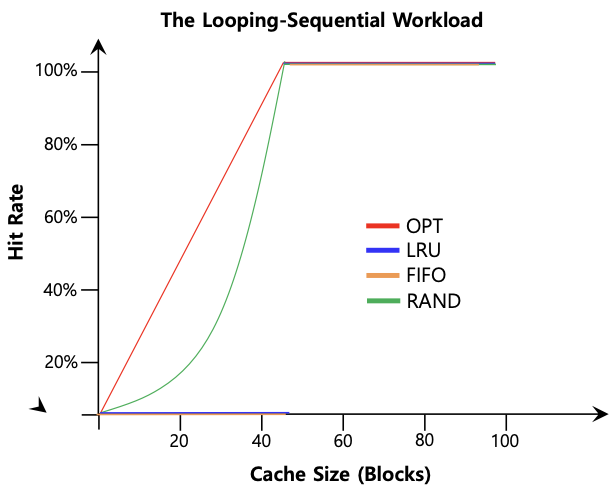
: 50개의 page가 loop를 돌면서 순차적으로 접근
- LRU와 FIFO는 크기가 49까지 모두 cache miss 발생 (cache size가 49page 까지 hit ratio=0, 가장 예전에 접근한 page 쫓아내고 50이 들어올때 0이 쫓겨나감)
Implementing Historical Algorithms
- 가장 최근에 사용된 페이지 추적을 위해 시스템은 모든 메모리 참조에 대해 몇 가지 회계 작업을 수행해야 함
- HW 지원도 조금 추가
Approximating LRU
- 사용 비트 형태의 하드웨어 지원이 필요
- 페이지 참조할 때마다 사용 비트는 하드웨어에 의해 1로 설정
- 하드웨어는 비트를 삭제하지 않음. OS의 책임임
- Clock Algorithm
- 시스템의 모든 페이지가 원형 목록으로 배열
- 시계 바늘은 먼저 특정 페이지를 가르킴

: use bit를 통해서 최근에 접근이 되었는지만 판단 (LRU와 비슷한 동작), page fault 발생 시 손이 가리키는 페이지가 검사됨
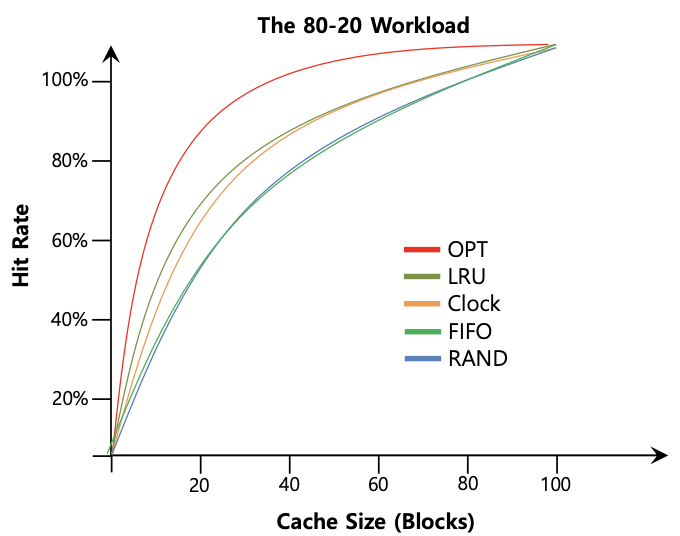
Workload with Clock algorithm
- Clock algorithm은 완벽한 LRU만큼 잘 작동하지 않음. 이전을 전혀 고려하지 않는 접근이 더 나음
Considering Dirty Pages
- HW엔 수정된 비트 포함
- 페이지는 수정되었기 때문에 dirty함. 삭제하려면 디스크에 다시 기록해야 함
- 페이지 수정되지 않았으면 삭제는 그냥 자유
Page Selection Policy
- OS는 페이지를 메모리에 가져올 시기를 결정해야함
- OS에 몇 가지 다른 옵션을 제공
Prefatching
- OS는 페이지가 곧 사용될 것이라고 예측하고, 페이지를 미리 가져옴
Clustering, Grouping
- 보류 중인 여러개의 pending writes를 메모리에 함께 모아서 한 번의 쓰기로 기록
- single large write를 many small ones보다 효율적으로 수행
Thrashing
- 프로세스에 충분한 page frame이 없는 경우, page fault이 매우 높아짐
- Thrashing : 페이지를 주고 받는 중
- 발생 이유 : size of locality의 합이 total memory size보다 크기 때문
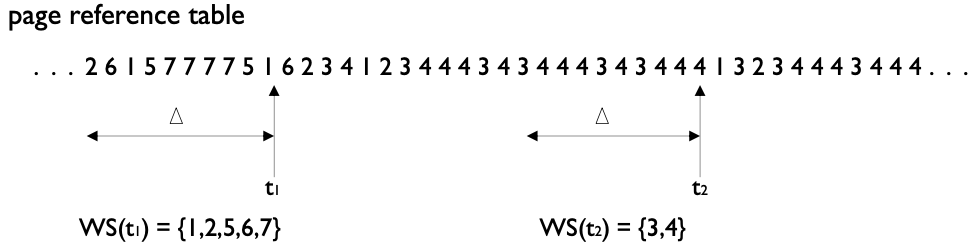
Working-set Model
- Working-set Model
- locality의 assumption에 기반 두고 있음
- working-set window : 고정된 page reference 수
- WSS
- 가장 최근 working-set window에서 참조된 총 page 수
- w.s.w가 작으면 entire locality를 포함하지 않을 것
- w.s.w가 크면 several locality를 아우를 것